李飞飞团队新论文:通过迭代式信息传递的场景图生成

理解一个视觉场景(visual scene)不只是要理解单独的一个个物体。物体之间的关系也能提供丰富的有关这个场景的语义信息(semantic information)。在我们这项工作中,我们使用场景图(scene graphs)明确地对物体及其关系进行了建模。我们提出了一种全新的端到端模型,其可以从输入图像中生成这种结构化的场景表征(scene representation)。该模型可以使用标准 RNN 解决场景图推理问题(scene graph inference problem)以及通过消息传递(message passing)学习迭代式地提升其预测能力。我们的联合推理模型可以利用语境线索(contextual cues)来更好地预测物体及其关系。我们的实验表明我们的模型在使用 Visual Genome 数据集生成场景图和使用 NYU Depth v2 数据集推理支持关系(support relations)上的表现显著超越了之前的方法。
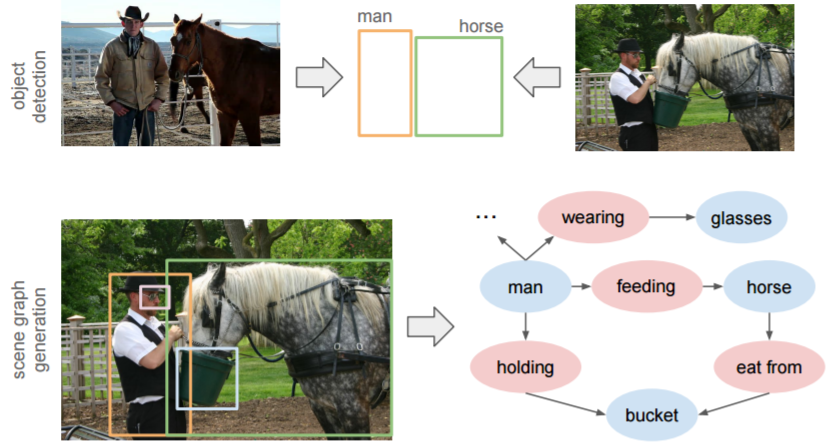
图 1:目标检测器通过关注单个的物体来感知一个场景。这使得即使是一个完美的检测器也会在两个语义上有明显区别的图像上得到相似的输出(第一行)。我们提出了一种场景图生成模型,其以图像作为输入,然后可以生成基于视觉的(visually-grounded)场景图(第二行右图),该场景图捕获到了图像中的物体(蓝色节点)以及它们之间配对的关系(红色节点)。

图 2:我们的模型的架构概览。给定一张图像作为输入,该模型首先使用一个 Region Proposal Network (RPN) [32] 产出一个目标提议(object proposals)集合,然后将从目标区域提取出来的特征传递给我们全新的图推理模块(graph inference module)。该模型的输出是一个场景图 [18],其包含一个本地化的目标集合、每个目标的类别以及每个目标对之间的关系类型。
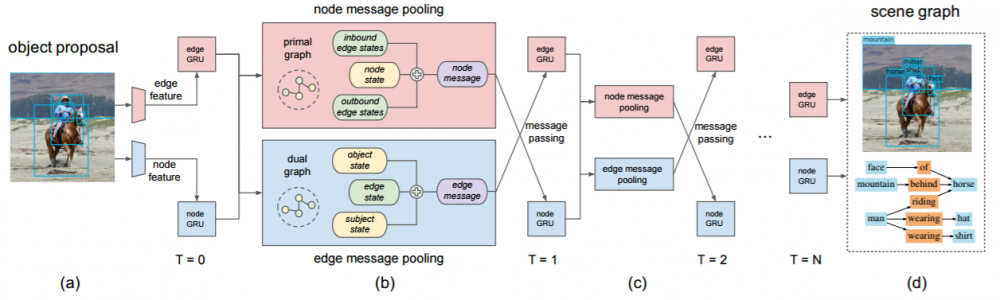
图 3:我们模型的架构图示。该模型首先会从目标提议集合中提取出节点和边(edge)的视觉特征,然后边 GRU 和节点 GRU 将这些视觉特征作为初始输入并得出一个隐藏状态的集合 (a)。然后一个节点消息池化函数(node message pooling function)在下一次迭代中计算从隐藏状态传递到节点 GRU 的消息。类似地,一个边消息池化函数(edge message pooling function)也会计算传递到边 GRU 的消息和推送 (b)。⊕ 符号表示学习到的加权和。该模型可以迭代式地更新 GRU 的隐藏状态 (c)。在最后一个迭代步骤,该 GRU 的隐藏状态可以被用于预测目标类别、bounding box offsets 和关系类别 (d)。

图 6:我们的模型在 NYU Depth v2 数据集 [28] 上的支撑关系预测(support relation predictions)样本。尖头箭头表示从下面支撑,圆头箭头表示从旁边支撑。红色的箭头表示不正确的预测。我们还给不同的代码结构类涂上了不同的颜色:地面是蓝色的、结构是绿色的、家具是黄色的、工具是红色。紫色表示缺失的结构类别。注意分割掩码(segmentation masks)在这里仅用作可视化的目的。我们的模型使用了目标边界框作为输入,而不是这些掩码。
原文 http://www.jiqizhixin.com/article/2191正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

