深度学习第一课
近几年深度学习的概念非常火,我们很幸运赶上并见证了这一波大潮的兴起。记得2012年之前提及深度学习,大部分人并不熟悉,而之后一段时间里,也有些人仍旧持怀疑的态度,觉得这一波浪潮或许与之前sparse coding类似,或许能持续火个两三年,但终究要被某个新技术新方法所取代,再后来,无论是学术界还是工业界,总有些研究者为自己没有在第一时间跟进这波浪潮感到后悔莫及。确实,从2012年AlexNet取得ImageNet的冠军开始,五年过去了,深度学习的方法仍旧占领着人工智能这片领域。
随着这波浪潮,有些人作为弄潮儿,兴起一波波巨浪,引领各个领域从传统方法到深度学习方法的转变,并希望能够通过了解其他领域的方法改进自己所从事的领域;有些人辛勤地工作,利用深度学习的方法为公司提高业绩,希望实时跟进并实现最新的技术;有些校园中的研究僧,一方面需要了解最新技术及其背后原理,另一方面还有发文章和找工作的压力;有些相关从业者,如编辑、记者,经常报道AI领域新闻,却从没有时间仔细研究深度学习;还有些非技术人员,总会在这些新闻后惊恐地询问“天网是否能在有生之年建成?”或是“AI对人类的威胁到了什么程度?”。
仅仅通过一节课程,或是一本书来解决以上所有问题明显是不可能的。鉴于国内机器学习资料还是偏少,而且大多是理论性质,并没有实践模块,我们从去年年底开始着手写一本深度学习相关的tutorial,并希望通过一章章真实的案例来带大家熟悉深度学习、掌握深度学习。这个tutorial中每一章内容都围绕着一个真实问题,从背景介绍到使用PaddlePaddle平台进行代码实验,完整地让大家了解整个问题如何用深度学习来解决,从此告别纸上谈兵。参加本次活动之前,没有想到这次报名人数之多。看了下报名群中的同学不乏一些高端用户,于是我知道本篇课程必然要要一些同学失望了,因为这一讲作为第一讲,只能考虑到大多数用户,设计成难度适中的课程,为大家提供一些深度学习最基本的概念,以便更轻松地入门深度学习。如果您是高端用户(能自己run起来深度学习模型或做过一些常识),建议您可以直接移步 tutorial 自学,当然如果感兴趣,欢迎继续关注我们系列的后续课程。
首先,对这个系列的后续深度学习课程做一个预告。在这份 tutorial 中,我们将覆盖如下内容:
- 新手入门
- 识别数字
- 图像分类
- 词向量
- 情感分析
- 文本序列标注
- 机器翻译
- 个性化推荐
- 图像自动生成
本节课程中,我们主要带大家了解深度学习,通过它的一些有用或有趣的应用了解深度学习的基本原理和工作方式。
一、深度学习是什么
传统的机器学习中,我们要为每种任务定义其特定的解决方案。对于图像,曾经人们耗费大量精力设计各种描述子进行图像特征描述;对于文本,单单一个机器翻译任务就动辄多个模型的设计:如词语对齐、分词或符号化(tokenization)、规则抽取、句法分析等,每一步的错误都会积累到下一步,导致整个翻译结果不可信,且要追查一个错误会非常复杂。 深度学习的优势,就是可以弥补以上问题,一方面减少了对大量手工特征的依赖,对于图像文本等领域可以直接从原数据进行建模;另一方面通过端到端的网络模型(即一个网络直接从输入到输出建模,而不需要中间步骤)减少了多步骤中错误累积的问题。
深度学习采用多层神经网络的方法,依赖大数据和强硬件。
-
大数据
在这个数据爆发的时代,普遍的认知是,大数据并不是问题。但实际上也不完全是这样。从领域角度,图像的通用分类和语言模型的训练或许可以从搜索引擎中获取大量样本,但对于细粒度图像分类(如不同类型的花的分类)或是 专业领域的对话数据(如法律咨询类)的数据就比较稀缺;从应用方法角度,图像、文本和语音都方便获取,但如果希望进行有监督训练,就必须有对应的标记(label),如标明一段语音对应的人,或是一段语音对应的文本,这就是个大工程了。这就需要我们利用已有资源,最简单的方法比如可以先利用大量无标记数据学习数据的特征,就可以减少数据标注规模。
-
强硬件
由于深度学习需要强计算处理能力,因此需要GPU显卡进行并行加速,拼硬件已经成为学界和工业界在研究深度学习网络时的一大共识。在2016年期间,英伟达和AMD的股票价格都实现了飞涨,如下图是GPU制造商英伟达(NVIDIA)公司今年的股价趋势。可以说这种跳跃式增长得益于GPU芯片在游戏、虚拟现实、自动驾驶、数据中心等各个高性能计算需求领域的应用。
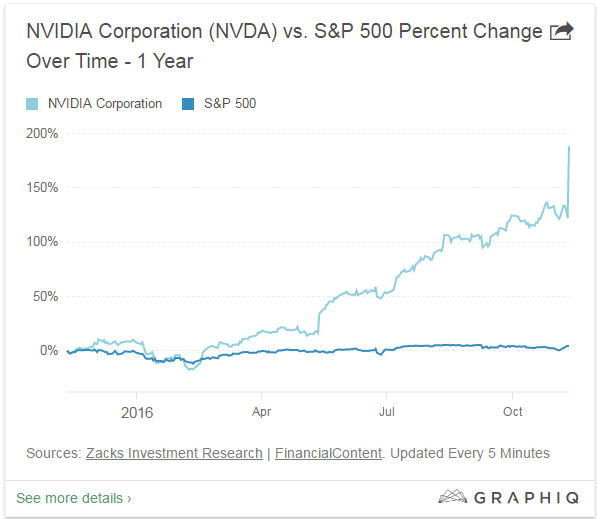
GPU的每个显卡具有多个(通常是几十个)多处理器(Streaming Multiprocessors, SMs),每个多处理器中有上百个CUDA核。一个多线程程序的一个kernel实例在一个SM上执行,一个kernel实例上的操作会分配到不同cuda核中独立执行。所以只要程序分配得当,GPU中的处理器越多执行越快。如Titan X(GM100)显卡拥有24个多处理器,每个多处理器拥有128个CUDA核,整个显卡有3072个CUDA核, 其相对16核Xeon E5 CPU处理器要加速5.3~6.7倍[1],这对于实时性要求较高的应用意义非凡。
二、深度学习的应用
深度学习可以涵盖很多应用范围,我们这里可以先以几个有意思的应用,给大家一个基本概念, 工业界常用的例子会在后续课程中详细地举例。
极简版无人车
无人车概念近几年很火,从传统领域到互联网企业都多少有这个方向的研究者。对于初步接触神经网络的同学,我们先引入一个小任务。如下图所示为一个可遥控小车在车道上的运行轨迹,小车上方搭载GoPro摄像头。图中蓝线表示垂直基准线,红线表示每一时刻小车应驶方向。我们的目标是,基于人为操控小车的行驶方向和当前图像数据,给出其驾驶方案。

这里,可以用神经网络指定网络的输入输出分别是当前图像和应走的方向,整体作为一个回归问题来处理,其中输入图像用多层卷积神经网络来解析。这里可能有朋友会说,其实我只需要用基本图像处理技术(比如二值化图像后再检测连通域)找出来左右两条车道,再向前方车道线中点位置方向走不就行了吗?确实是可以这么干的,我们这里只是为了说明深度学习的端到端训练,举例个最简版的无人车,有清晰的车道线,并且没有红绿灯、障碍物等干扰。实际情况中,需要考虑跟踪前车、车道保持、障碍物检测、红绿灯检测等多种情况,因此需要多模型的设计和集成。单就最简单情况下车道检测的这个事情来说, 确实可以仅通过图像处理+人工策略达成目的,也不需要什么训练数据,但这就要求程序员每遇到一个badcase都需要人工修改策略,这样等下一位程序员接手这段代码的时候,就只能呜呜呜了。
拍摄照片油画化
2015年的一篇文章[5],将艺术家梵高和深度学习联系在了一起,文中实现了将艺术画style附体于日常拍摄照片,从而得到“艺术照”的效果。其做法是设计一个神经网络,定义该网络的损失函数为Diff(拍摄照片,生成作品) 与 Diff(艺术画,生成作品)这两个Diff的加权和。其中Diff表示两幅图片的差异。但如果通过每个像素的差异来计算这个Diff的话,显然不合理,对于拍摄照片和生成作品而言,像素值必然已经大变,而对于艺术画和生成作品而言,可能色调相似,但靠单个像素值去比就肯定是相差甚远了。所以我们其实想要的只是一个抽象的概念,如下图的例子,我们只需要生成的图包含“猫”,且画风和中间的艺术照相似。于是采用了神经网络的隐层作为度量他们Diff的空间。

机器翻译
刚才的两个例子都是深度学习在图像中的应用,其在文本中同样意义重大。和图像不同的是,文本作为一个序列化信息,深度神经网络对这样数据的的处理和图像不太相同,但除此之外的基本思路就可以相互迁移了。比如已经了解了通过深度学习进行图像分类的方法,那么文本分类只是变化一下,将一短文本映射成特征向量从而进行分类,这可以通过将理解图片的卷积神经网络改为处理序列信息的循环神经网络完成。类似地,机器翻译(用计算机来进行不同语言之间的翻译)也可以通过类似的方法。以通过深度学习进行中译英为例,首先通过一个循环神经网络理解一句汉语(映射为文本语义信息,可以是一个向量,也可以是一个时序信息),称此过程为“编码”,再将这个文本语义信息通过另一个循环神经网络,每个时刻输出一个英语单词,称此过程为“解码”,通过这样的编码-解码结构即完成了机器翻译。我这里只是白话说出了机器翻译的大概思想,感兴趣的同学可以参考 机器翻译一章的tutorial 或追踪后续课程。
为你写诗
看完以上内容,如果想让你根据一个词创作一首诗,你想能怎么做呢?恐怕已经有同学想到了:用翻译的做法写诗。不错,机器翻译其实可以用到很多地方,只需要修改数据集就ok,如果我们想根据一个词,让机器“创作”一首诗,只需要将翻译模型的输入设置为这个词,而输出是诗句即可。不过,通常这么做是有问题的,因为这样做导致输入序列很短而输出很长,其间的依赖并不能充分发挥出来,硬将这样的两个序列绑在一起可能导致机器强硬地“背”下来如输入语料而没有真正理解语义。因此,有的工作中用短语生成第一句诗词,用第一句去生成第二句……;或者可以用前n-1句生成第n句诗词。感兴趣的同学可以自己试一下,也可以试用一下度秘里面写诗模块。
商品推荐
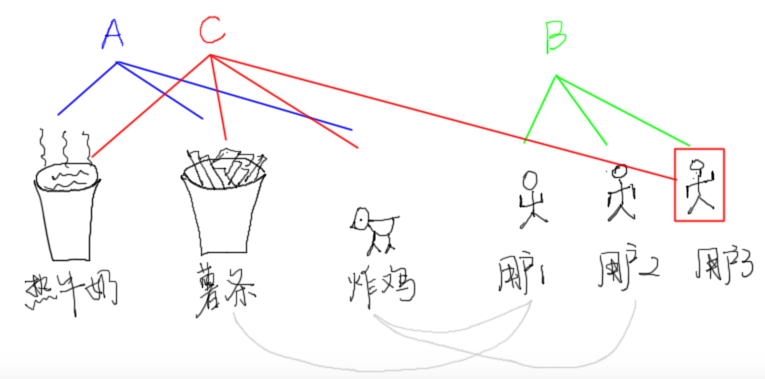
商品推荐是电商和新闻客户端们的关注热点,他们都关注用户兴趣的把控,其推荐系统的好坏往往会对用户留存和购买情况有较大影响。这里我们可以想见,最基本的推荐策略是爆款推荐(全民热点),和已浏览或是购买/收藏了的项目。对于大量用户没有过浏览记录的项目,传统推荐方法一般采用协同过滤,即推荐给用户相似用户的兴趣项,另一种方法是通过基于内容过滤推荐,即推荐给用户浏览项目的相似项,这其中就涉及到用户相似度和产品/项目相似度的获取。一方面,我们可以利用深度学习进行其相似度的建模,另一方面,我们还可以将用户特征和产品/项目特征映射到一个相同的空间进行特征比较,也就是将下图A(协同过滤)和B(基于内容过滤)策略改为C。
三、深度学习的缺陷
说过了神经网络的牛逼之处,我们再来看看它的一些缺陷,至少是目前难以解决的问题。
特斯拉事件
关注特斯拉的同学应该都有注意到,去年一位23岁的中国男青年,在驾驶特斯拉电动汽车沿京港澳高速河北邯郸段公路行驶时,前车躲避障碍物后,该男子躲闪不及撞上了道路清扫车,发生严重车祸导致死亡。
特斯拉官方并没有公布过其内部算法,我们只知道特斯拉的自动驾驶系统Autopolit中曾有以色列Mobileye公司提供的技术。Mobileye是一家基于视觉帮助减少交通事故的公司,其研发多年的高级驾驶辅助系统(ADAS)处于业内领先,主要基于单目摄像头传回的图像,通过深度神经网络进行车辆检测、车道识别等[3]。但Mobileye自己也表示曾经提醒过特斯拉公司,他们的这套系统只能起辅助作用, 并不完善,也不能完全保障车主。虽然特斯拉官方声明由于车主家属不愿提供更多信息,导致具体Autopolit错误原因无从定位,但原因或是因为中国独有的道路清扫车不曾出现在单目视觉的训练数据集,或是因为光照等特殊因素导致的图像质量问题,都说明无法仅通过视觉技术保障自动驾驶的安全性。我们不能将这起事故归结于是深度学习的缺陷,但在实际系统中, 我们目前确实难从一个端到端的系统中完全定位并解决问题,大家还可以看下面的例子进一步理解。

可解释性
在之前的“深度学习是什么”这一节中,我们讲到深度学习可以利用端到端的学习避免一些多步骤积累错误导致的问题,然而这其实也是一种缺陷。我们无从定位问题出在哪里。下面就以图像分类的一个badcase为例进行说明。
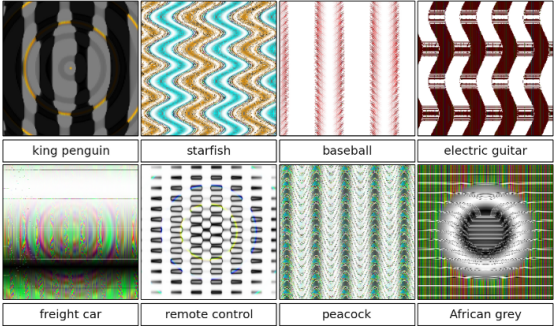
ImageNet竞赛2012年冠军工作AlexNet的作者Krizhevsky 曾提出,虽然AlexNet效果很棒,但为了最优化该数据集上的效果,不得不建立这样一个含有非常多参数的深度神经网络,而这样的网络非常容易过拟合。在15年的CVPR会议中,Anh Nguyen提出了一种生成样本的方法,该方法生成的样本可以“愚弄” 用于图像识别的深度神经网络[4],如下图所示的8幅图下面标注的文字分别为ImageNet竞赛数据集上效果最好的网络对该图的识别结果(置信度高于99.6%), 该网络将我们认为的这些波纹分别识别成了王企鹅、海星、棒球、电吉他、火车车厢、遥控器、孔雀、非洲灰鹦鹉。这种很容易“愚弄”神经网络的样本,被称为对抗样本。
深度学习希望模拟人脑中的神经元,通过一个神经网络进行参数拟合,但学习的过程不尽相同。事实上,当人去学习知识的时候,是“哪里不会点哪里”、“哪里错了改哪里”,即局部调整,而深度学习通常都是通过所有样本来决定整个网络的全部参数,希望在所有样本上获得全局最优解;当人们学习什么是“企鹅”的时候,既不会刻意地通过某几个的特征(如颜色、体态)去捕捉,也不需要看上千八百张图片才了解到这样一种模式,我们就知道如下三幅图,都是一个物种, 而神经网络想学到这样一个概念并不容易,往往需要企鹅的各个品种、各种pose的图片。

同样,当神经网络的结果有误时,我们无法像人脑学习一样局部修改部分参数,即便可以,对于端到端的神经网络,调整哪一块参数、如何调整也是无从下手。这就是深度学习可解释性方面的局限。
感谢
感谢大家订阅这一期GitChat活动,开篇提到的tutorial作为我们对PaddlePaddle深度学习平台的再一次易用性扩展,欢迎大家关注学习并提出宝贵意见。同样感谢这份tutorial中诸多志愿者同学们的共同努力,国内做开源不易,做撰写tutorial&demo的文档更难,希望有兴趣的小伙伴 加入我们 ,共同推动有意思的tutorial能够在开源社区进行分享。
参考文献:
- https://www.nvidia.com/content/tegra/embedded-systems/pdf/jetson_tx1_whitepaper.pdf
- https://www.quora.com/What-is-the-difference-between-Teslas-Autopilot-system-and-Googles-driver-less-car
- http://wccftech.com/tesla-autopilot-story-in-depth-technology/4/
- Nguyen A, Yosinski J, Clune J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 427-436.
- Gatys L A, Ecker A S, Bethge M. A neural algorithm of artistic style[J]. arXiv preprint arXiv:1508.06576, 2015.
Chat实录
分享人简介:张睿卿,paddle官方开发组成员,毕业于浙江大学计算机学院。专注于深度学习领域,目前研究方向为对话、图文问答。微博: Rachel____Zhang。
问:深度学习看到的案例大部分是在图像处理上,语音识别等方面的。对普通数据类似回归分析的预测,用DeepLearning有有优势吗?比如电商某款商品的销量预测?
答:DeepLearning相对于最基础的线性回归的优势在于,随着模型go deeper,会有更多的参数,另外加入了非线性提高模型理解能力。至于是否可以做销量预测,其实看你的数据了。
- 对于数据量小的产品(大多其实数据量都小),就算加了很多参数也是徒劳,因为会overfitting;
- 输入特征选的对不对,如果你考虑这是一款有周期性的产品(比如爆竹),那你用16年1月数据训练,17年1月数据预测是ok的,但如果用16年3月的数据预测就肯定要跪了。
问:为你写诗的第一句诗是seq to seq 用一个或者几个词生成的么?
答:是的。关键词(一个或几个)生成第一句,第i句生成第i+1句(或者前i句生成第i+1句);这是一种普遍的方法。
问:做中文序列标注的时候,使用Bi_LSTM+CRF,如何加入已经验证过比较好的人工特征,例如"词的后缀"?
答:关于后缀的加入,将输入设置成word embedding; suffix embedding就可以了,另外其实不建议你直接加后缀特征。
Learning Character-level Representations for Part-of-Speech Tagging。比如这篇文章,就证明了不需要手工加后缀。word-level embedding可以捕捉语义信息,char-level embedding可以捕捉包含后缀信息在内的形态学信息,可以直接用char-level embedding的,也方便。
问:我是做Fintech领域的,想请教两个问题。 一是在DeepLearning这块,如果只是把TensorFlow PaddlePaddle当做近似黑盒的去用,主要基于现有模型做细微修改,产生的作用大概能有多少的效果。 另一个是在Fintech这块,目前看到了有人基于dl做对冲基金,那根据您的判断,在金融领域是否可能有更多的建树。在难以解释性上很多时候很犹豫。
答:关于基于DeepLearning做对冲基金是否靠谱这个问题,我只能说,从时序信号的角度,这个是可以做成的,也确实有公司说(至少号称)用了DeepLearning进行投资建模,然而他们也并不会公开其算法。
个人认为,做对冲基金最大的问题是克服数据噪声。以自然信号(真实图像、语音)来说,其内部噪声是比较小的,甚至我可以精准地给噪声建模,然而金融数据,尤其是国内的金融数据,噪声还是占比挺大的。
我用到过金融数据做量化投资者分类,其实已经挺难了,不过你这个如果做趋势预测啥的更难。也就是说,如果真的想做好,就要考虑很多因素,将全局新闻(降息降准)、人为情绪(年前资金紧张)、个股新闻(两个大股东离婚分家)还有历史走势全都融入模型,倒是可以一试。
问:请问可以将传统的图像处理方法与深度学习结合起来使用吗?如果可以,能不能举个例子,比如用于图像分割?谢谢,目前深度学习还未入门,所以有此一问,请作者解答。
答:对于结合,我的理解是,比如对于图像分类,手工求特征之后可以把SVM替代成其他分类器。比如神经网络分类器,FCN for segmentation(Fully Convolutional Networks for Semantic Segmentation)这篇文章比较经典,输入为图像,目标输出为groundtruth segmentation,用一个全卷积网络进行拟合。有个问题是一般图像识别网络输出为各个类别权重(无空间信息)。这通过将全连接层视作一个全图范围的卷积得到。
问:文章着重于DeepLearning的应用及其PaddlePaddle的实现,能不能多讲些PaddlePaddle这个框架的实现?
答:收到需求,等系列里安排吧,下次专开一个课题。
问:当前很多应用都是监督学习,无监督学习当前有哪些可能的方向取得实质性进展?
答:无监督学习的一大成功应用是聚类,或者降维。之前的工作(比如PCA和K-Means)在深度学习中可以也有相应的competitive 方法,比如基于信号重建的autoencoder。另外已经有一些比较成熟的paper都是基于无监督学习的。我们这里给的例子还都是有监督的。Unsupervised Learning of Invariant Feature Hierarchies with Applications to Object Recognition,Unsupervised feature learning for audio classification using convolutional deep belief networks,比如这两篇,比较老了,现在大部分还是有监督学习的。
一类无监督学习是生成模型,包括最近比较火的GAN,还有VAE,可以无监督地生成图片,并训练模型,使其生成的图片像训练集中的图片,我们也会在tutorial二期加入该内容,敬请留意。tutorial地址: https://github.com/paddlepaddle/book 。
问:深度学习的基本功都有哪些?
答:不太理解说基本功能的意思,如果要下定义的话,其实就是帮助数据更好地表达,比如原本需要手工定义的很多特征,现在输入原始数据即可(文中举了相应的图像和文本的例子)。基本功其实最最基本的就是编程能力,我觉得其他的都好说。数学开始不难的。后续,具体问题具体分析,我的建议是,不用一开始把基本概率论都读完的。
问:请教一个问题,深度学习在写诗,图像生成,新闻编写等领域都有应用,是否在音乐创作领域也有相关应用?现在大约到什么水平?能否推荐些相关论文?
答:在google直接搜索“RNN-RBM”, 第二个结果是我曾经总结这篇的 博客 。另外这里有 6个例子 ,做DeepLearning生成音乐的。
问:目前我在做文本中的热点问题分析,用的是关联分析算法。我们遇到的难点: 1. apriori算法出来的是词组,如何转换成实际的问题。我们目前都是人去看、去定位问题,人工量很大,有什么机器学习的方法吗? 2. 除了关联分析算法,还是什么算法建议? 3. 我们之后要做长文本,关联分析算法是否合适?有什么算法建议吗?
答:了解了,那其实可以转换成一个文本分类问题,你的输入是长文本吧,无监督很难,不过还要看你要求的精度吧。直接进行文本分类,详见 GitHub ,这个是有监督的,无监督的,可以试下利用相邻短句之间的关系。
问:我有一些宏观上的问题,诸多机器学习算法中,什么场景深度学习适用,什么时候不适用,这是一个;第二个什么时候适用现在已有的框架,什么时候自研算法;第三,你们是否基于GPU优化算法和程序?
答:是可以用文本相似度做聚类,也可以利用相邻句语义相关的假设,如我文中所说,一般情况下深度学习只适用于大数据,如果数据量小而由于深度学习参数多会导致overfitting,所以小数据建议用规则,或者想办法减少参数。第二个问题,现在框架太多了,建议不重复造轮子。第三个问题,是的,PaddlePaddle中神经网络各层分别有CPU和GPU的实现。
问:PaddlePaddle和google 的TensorFlow 比优势有哪些?
答:内部人员说了不算,这里是 caffe作者jiayangqing对PaddlePaddle的评价 。总结一下:
- 高质量GPU代码;
- 非常好的RNN设计;
- 设计很干净,没有太多abstraction;
- 我再补充一些:支持CPU/GPU单机和多机分布式计算;
- 对新手非常友好,不同于tensorflow对使用人员对神经网络了解要求较高;
- 外层封装了多种主流模型,有一些在我们的tutorial中已经有讲到。
问:我在这块一个完全的新手,现在是前端,目前在看线性代数和python. 自己是做好花很长时间入门的准备,但是对具体的学习路线,不知道有什么好的建议。另外是先学好python然后就尝试基于框架来入手,还是打好基础学好线代,统计学,然后在看看神经网络相关知识。
答:建议边学Python边入手,DeepLearning需要大量实践经验,建议边学边干,也有助于你对神经网络的理解。
问:程序员学习数学从何开始?如何更快应用于人工智能? 普通程序员在新一轮的人工智能浪潮里要如何定位?
答:程序员学习数学从何开始?你是要学啥?数学很泛泛……
如何更快应用于人工智能? 今天晚上就把PaddlePaddle的代码clone下来,然后明天run起来,然后后天开始把tutorial过一遍,用一个月。(搭建开发环境的话,docker秒搭)从源代码编译要慢一些可能。。反正还是看工程经验了,总之,编译的时候没什么坑,而且有问题可以提issue。
普通程序员在新一轮的人工智能浪潮里要如何定位? 做你擅长的。
问:想请教一下,在现有的网络效果不理想的时候,除了改进特征以外,怎么样可以快速找到其他改进效果的突破口?
答:个人觉得改特征/数据是最快的。其他,还是具体问题具体分析,改网络的话,需要具体分析是过拟合了、还是前拟合。看看要不要增加减少网络层,要不要加trick(比如dropout)什么的。
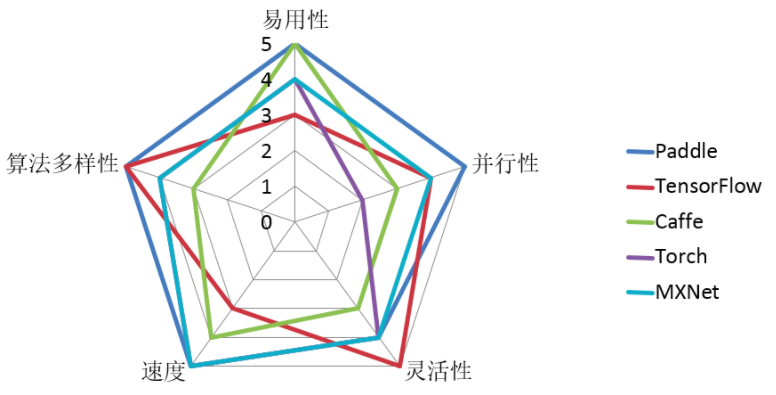
问:PaddlePaddle中是否有autograd功能,如果没有的话是否会开发这个功能?目前PaddlePaddle文档中写着如果要增加一个新层需要把前向后向的计算都手工写出来。而theano/TensorFlow/mxnet有autograd功能就可以只写前向。
答:我了解到暂时没有要开发,TensorFlow是有autograd,但是TensorFlow和theano都比较慢,有一张表示PaddlePaddle和其他几个平台效率的benchmark。
问:在使用DeepLearning算法的时候,训练数据量要求是不是很大,之前在不了解的基础上做的测试,数据量太少效果很差,这个训练数据的量要如何把握?
答:看训练曲线,是否过拟合。
问:训练数据因为一些原因,不能完全保证特征的一个较为合理的分布比例,在DL使用中人工不参与特征前提下会不会导致效果相对其他机器学习算法更差?
答:有可能,所以前面有建议,数据量太小的话用规则。
问:什么样的机器学习任务适合用DL来做?或者说什么样的ML任务不适合用DL来做?
答:就是还得在训练数据上做改进,或者是至少保证电影的embedding是好的。
问:第一个作为入门者,如何去使用TensorFlow等来源人工智能软件?第二个是在什么场合下用监督学习?在什么场合下用无监督学习?还是要混合用?
答:其实上官网都有详细下载,编译说明。监督学习——有label,且label充足。无监督——没label。混用——有label的样本不足,需要先用无监督训了feature,初始化模型再用有label的做监督学习。
问:如何发现深度学习可以应用的领域?或者说:通常的研究者,是如何聊着、聊着,就发现某个领域的问题,可以用某种DL算法来试试?但是,某一种领域的问题,早早的就能断定,别试了。
答:多看paper吧,看看conclusion里有啥要解决的问题,还有别的paper是怎么喷其他paper的,就会发现待解决的问题,或者别人的一些思路。其实最好不建议泛泛地讲,还是先有一个目标问题。然后查查paper有没有解决,
最好的判断是对应该方案的数据集是否充足。
问:1)普通的java程序员入门深度学习的话需要预备些什么方面的基础知识,请推荐几本薄的入门书籍。2)大数据(如mr spark)方面的程序员进入机器学习领域的话 需要补充什么方面的知识,比较简便的发展路径是什么。3)深度学习的实际应用的完整项目结构是什么样的,需要哪些方面人员?
答:1)基础知识,其实感觉我们的在线教程真的就可以,很好入手。入门书籍,想了下其实还是国外博士论文最薄最好,可以参考周志华老师的《机器学习》西瓜书,对,Andrew Ng的课程也是蛮好的。2)同上。3)1. 处理数据;2. 设计网络;3. 调参/调整网络;4. 如果有功能PaddlePaddle等框架中没有实现,自己开发。基本是这样的迭代过程。
问:那对于特征分布的问题除了改训练数据有没有好的建议?主要是训练数据中对应的类别的特征分布是存在问题的,不是理想的状态,比如对于一些情感分类来说,属性应该在每个类别分布均匀,影响的是情感词。具体来说,比如对于一些情感分类来说,属性应该在每个类别分布均匀,影响的是情感词,但是实际的训练数据中很多情况下,属性分布不均匀,相似的特征分布有很多,这样导致了利用特征结果会有偏差。
答:就是说特征没有判别性,比如“这场电影很好看”vs“这场电影不好看”,一字之差,如果不能判别,说明模型没训好。
这个还是电影的embedding训得不好,比如传统方法是会有这个问题的,但DL用时序模型,进行语义理解,理论上是不会这样的,除非说,你的数据非常不均衡,比如你收集到的电影评价都为负……那只能造假数据。
在此感谢人民邮电出版社,为本场Chat的获奖读者赠送了《科学的极致:漫谈人工智能》一书。



正文到此结束
- 本文标签: 代码 HTML 开发 统计 汽车 自动生成 https 资金 UI GitHub 程序员 参数 src 互联网企业 Action git 互联网 基金 Google App 快的 投资 python 处理器 分布式 ip 压力 金融 多线程 智能 软件 企业 Word 无人车 id 质量 线程 安全 FIT 空间 Docker 微博 关键词 神经网络 希望 测试 事故 apr 大数据 色调 实例 开源 博客 2015 IO 翻译 搜索引擎 时间 parse 语音识别 http 下载 图片 编译 突破 cat IDE 需求 解析 总结 DDL 文章 深度学习 java 投资者 产品 数据
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

