Flink运行时之TaskManager执行Task
当一个任务被JobManager部署到TaskManager之后,它将会被执行。本篇我们将分析任务的执行细节。
submitTask方法分析
一个任务实例被部署所产生的实际影响就是JobManager会将一个TaskDeploymentDescriptor对象封装在SubmitTask消息中发送给TaskManager。而处理该消息的入口方法是submitTask方法,它是TaskManager接收任务部署并启动任务执行的入口方法,值得我们关注一下它的实现细节。
submitTask方法中的第一个关键点是它先构建一个Task对象:
val task = new Task(
tdd,
memoryManager,
ioManager,
network,
bcVarManager,
selfGateway,
jobManagerGateway,
config.timeout,
libCache,
fileCache,
runtimeInfo,
taskMetricGroup)
该Task封装了其在TaskManager中执行时需要的一些关键对象。task对象将会被加入TaskManager中的一个ExecutionAttemptID与Task的Map中,如果发现该ExecutionAttemptID所对应的Task对象已存在于Map中,则将原先的Task实例重新放回到Map中,同时抛出异常:
val execId = tdd.getExecutionId
val prevTask = runningTasks.put(execId, task)
if (prevTask != null) {
runningTasks.put(execId, prevTask)
throw new IllegalStateException("TaskManager already contains a task for id " + execId)
}
如果一切正常,接下来就启动线程并执行任务,接着发送应答消息进行回复:
task.startTaskThread() sender ! decorateMessage(Acknowledge)
submitTask方法比起JobManager的submitJob方法,逻辑和代码量都相对简单。我们会进一步分析两个过程:
- Task对象的构造方法
- Task作为一个线程,其run方法的实现
首先关注的是Task的构造方法,Task作为TaskManager的启动对象,其需要的参数基本都跟其执行有关,参数如下:
public Task(TaskDeploymentDescriptor tdd, //任务描述符
MemoryManager memManager, //内存管理器
IOManager ioManager, //IO管理器
NetworkEnvironment networkEnvironment, //网络环境对象,处理网络请求
BroadcastVariableManager bcVarManager, //广播变量管理器
ActorGateway taskManagerActor, //TaskManager对应的actor通信网关
ActorGateway jobManagerActor, //JobManager对应的actor通信网关
FiniteDuration actorAskTimeout, //actor响应超时时间
LibraryCacheManager libraryCache, //用户程序的Jar、类库缓存
FileCache fileCache, //用户定义的文件缓存,执行时需要
TaskManagerRuntimeInfo taskManagerConfig //TaskManager运行时配置
)
构造方法的第一段代码是将TaskDeploymentDescriptor封装的大量信息“转交”给Task对象。
接下来会根据结果分区部署描述符ResultPartitionDeploymentDescriptor和输入网关部署描述符InputGateDeploymentDescriptor来初始化结果分区以及输入网关,其中结果分区是当前的task实例产生的,而输入网关是用来从网络上消费前一个任务的结果分区。首先看一下结果分区的初始化:
this.producedPartitions = new ResultPartition[partitions.size()];
this.writers = new ResultPartitionWriter[partitions.size()];
for (int i = 0; i < this.producedPartitions.length; i++) {
ResultPartitionDeploymentDescriptor desc = partitions.get(i);
ResultPartitionID partitionId = new ResultPartitionID(desc.getPartitionId(), executionId);
this.producedPartitions[i] = new ResultPartition(
taskNameWithSubtaskAndId,
jobId,
partitionId,
desc.getPartitionType(),
desc.getEagerlyDeployConsumers(),
desc.getNumberOfSubpartitions(),
networkEnvironment.getPartitionManager(),
networkEnvironment.getPartitionConsumableNotifier(),
ioManager,
networkEnvironment.getDefaultIOMode());
this.writers[i] = new ResultPartitionWriter(this.producedPartitions[i]);
}
以上代码主要的逻辑是循环初始化结果分区对象数组producedPartitions以及结果分区写入器数组writers。结果分区对象初始化时,会根据ResultPartitionType的类型来判断是创建阻塞式的子分区还是创建管道式的子分区,这涉及到数据传输的方式。ResultPartitionWriter是面向结果分区的运行时结果写入器对象。
下面的代码用于输入网关的初始化:
this.inputGates = new SingleInputGate[consumedPartitions.size()];
this.inputGatesById = new HashMap<IntermediateDataSetID, SingleInputGate>();
for (int i = 0; i < this.inputGates.length; i++) {
SingleInputGate gate = SingleInputGate.create(
taskNameWithSubtaskAndId, jobId, executionId, consumedPartitions.get(i), networkEnvironment);
this.inputGates[i] = gate; inputGatesById.put(gate.getConsumedResultId(), gate);
}
输入网关的初始化则是根据上游task产生的结果分区来进行挨个初始化。
最终它会为该任务的执行创建一个线程:
executingThread = new Thread(TASK_THREADS_GROUP, this, taskNameWithSubtask);
其实Task类实现了Runnable接口,它的实例本身就可以被线程执行,然后它又在内部实例化了一个线程对象并保存了执行它自身的线程引用,进而获得了对该线程的完全控制。比如,用startTaskThread方法来启动执行Task的线程。Task线程的执行细节,我们将会在接下来进行分析。
从这里我们也能看到,每个任务的部署会产生一个Task对象,而一个Task对象恰好对应一个执行它的线程实例。
Task线程的执行
Task实现了Runnable接口,那么毫无疑问其run方法承载了Task被执行的核心逻辑。而之前,我们将会分析Task线程的执行流程。
首先,第一步先对Task的执行状态进行转换:
while (true) {
ExecutionState current = this.executionState;
//如果当前的执行状态为CREATED,则对其应用CAS操作,将其设置为DEPLOYING状态,如果设置成功,将退出while无限循环
if (current == ExecutionState.CREATED) {
if (STATE_UPDATER.compareAndSet(this, ExecutionState.CREATED, ExecutionState.DEPLOYING)) {
// success, we can start our work
break;
}
}
//如果当前执行状态为FAILED,则发出最终状态的通知消息,并退出run方法的执行
else if (current == ExecutionState.FAILED) {
notifyFinalState();
return;
}
//如果当前执行状态为CANCELING,则对其应用cas操作,并将其修改为CANCELED状态,如果修改成功则发出最终状态通知消息,
//同时退出run方法的执行
else if (current == ExecutionState.CANCELING) {
if (STATE_UPDATER.compareAndSet(this, ExecutionState.CANCELING, ExecutionState.CANCELED)) {
notifyFinalState();
return;
}
}
//如果当前的执行状态为其他状态,则抛出异常
else {
throw new IllegalStateException("Invalid state for beginning of task operation");
}
}
接下来,是对用户代码所打成的jar包的加载并生成对应的类加载器,同时获取到程序的执行配置ExecutionConfig。根据类加载器以及用户的可执行体在Flink中所对应的具体的实现类名来加载该类:
invokable = loadAndInstantiateInvokable(userCodeClassLoader, nameOfInvokableClass);
Flink中所有类型的操作都有特定的可执行体,它们无一例外都是对AbstractInvokable类的扩展。每个的可执行体的名称在生产JobGraph时就已确定。
紧接着的一个关键操作就是向网络栈注册该任务对象:
network.registerTask(this);
这个操作是为了让Task之间可以基于网络互相进行数据交换,包含了分配网络缓冲、结果分区注册等一系列内部操作,并且有可能会由于系统无足够的内存而发生失败。
然后会把各种配置、管理对象都打包到Task在执行时的统一环境对象Environment中,并将该环境对象赋予可执行体:
invokable.setEnvironment(env);
在此之后,对于有状态的任务,如果它们的状态不为空,则会对这些有状态的任务进行状态初始化:
SerializedValue<StateHandle<?>> operatorState = this.operatorState;
if (operatorState != null) {
if (invokable instanceof StatefulTask) {
try {
StateHandle<?> state = operatorState.deserializeValue(userCodeClassLoader);
StatefulTask<?> op = (StatefulTask<?>) invokable;
StateUtils.setOperatorState(op, state);
}
catch (Exception e) {
throw new RuntimeException("Failed to deserialize state handle and "
+ " setup initial operator state.", e);
}
}
else {
throw new IllegalStateException("Found operator state for a non-stateful task invokable");
}
}
通常什么情况下任务会有初始状态呢?当任务并不是首次运行,比如之前发生过失败从某个检查点恢复时会从检查点中获取当前任务的状态,在执行之前先进行初始化。
接下来,会将任务的执行状态变更为RUNNING,并向观察者以及TaskManager发送通知:
if (!STATE_UPDATER.compareAndSet(this, ExecutionState.DEPLOYING, ExecutionState.RUNNING)) {
throw new CancelTaskException();
}
notifyObservers(ExecutionState.RUNNING, null);
taskManager.tell(new UpdateTaskExecutionState(
new TaskExecutionState(jobId, executionId, ExecutionState.RUNNING)));
然后将执行线程的类加载器设置为用户代码的类加载器,然后调用可执行体的invoke方法,invoke方法实现了每个可执行体所要执行的核心逻辑。
executingThread.setContextClassLoader(userCodeClassLoader); invokable.invoke();
invoke方法的执行是个分界点,在执行之前用户逻辑还没有被触发执行;而该方法被执行之后,说明用户逻辑已被执行完成。
然后对当前任务所生产的所有结果分区调用finish方法进行资源释放:
for (ResultPartition partition : producedPartitions) {
if (partition != null) {
partition.finish();
}
}
最后将任务的执行状态修改为FINISHED,并发出通知:
if (STATE_UPDATER.compareAndSet(this, ExecutionState.RUNNING, ExecutionState.FINISHED)) {
notifyObservers(ExecutionState.FINISHED, null);
}
else {
throw new CancelTaskException();
}
接下来在finally块里进行一系列资源释放操作。
最终的可执行体
Task是在TaskManager中执行任务的统一抽象,它的核心仍然是如何执行,而不是如何表述。比如,批处理任务和流处理任务,它们有很大的差别,但我们需要一种表述层面上的抽象,使得它们最终都能被Task所接收,然后得到执行。而该表述层面上的抽象即为AbstractInvokable。它是所有在TaskManager中真正被执行的主体。其类图如下:
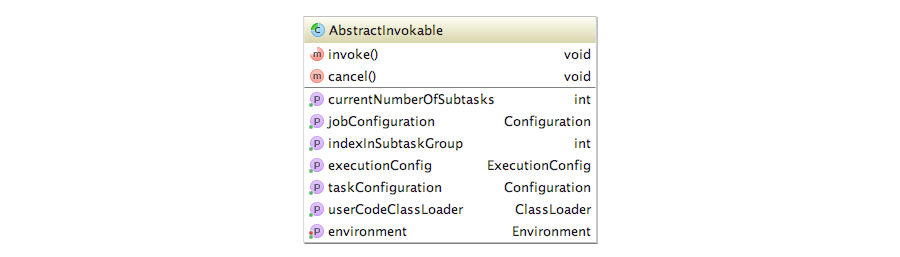
AbstractInvokable定义了一系列的“上下文”对象,同时提供了核心两个方法:
- invoke:该抽象方法是描述用户逻辑的核心方法,最终在Task线程中被执行的就是该方法;
- cancel:取消执行用户逻辑的方法,提供了默认为空的实现,用户取消执行或者执行失败会触发该方法的调用;
跟Flink提供了流处理和批处理的API一致,AbstractInvokable也相应的具有两个派生类:
- StreamTask:所有流处理任务的基类,实现位于flink-streaming-java模块中;
- BatchTask:所有批处理任务的基类,实现位于runtime模块中;
无论是哪种形式的任务,在生成JobGraph阶段就已经被确定并加入到JobVertex中:
public void setInvokableClass(Class<? extends AbstractInvokable> invokable) {
Preconditions.checkNotNull(invokable);
this.invokableClassName = invokable.getName();
this.isStoppable = StoppableTask.class.isAssignableFrom(invokable);
}
随后被一直携带到Task类中,并通过反射的机制从特定的类加载器中创建其实例,最终调用其invoke方法执行:
private AbstractInvokable loadAndInstantiateInvokable(ClassLoader classLoader, String className)
throws Exception {
Class<? extends AbstractInvokable> invokableClass;
try {
invokableClass = Class.forName(className, true, classLoader)
.asSubclass(AbstractInvokable.class);
} catch (Throwable t) {
throw new Exception("Could not load the task's invokable class.", t);
}
try {
return invokableClass.newInstance();
} catch (Throwable t) {
throw new Exception("Could not instantiate the task's invokable class.", t);
}
}
关于更多用户逻辑的执行细节,我们后续会进行分析。
微信扫码关注公众号:Apache_Flink

QQ扫码关注QQ群:Apache Flink学习交流群(123414680)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

