Quora 第一个开放数据集:相似问题对构建语义理解
Quora开放了第一个数据集,希望通过这40万行的问题对整合相同提问成同一页面,促进自然语言的语义理解,自动识别与整合,加强知识共享平台的建设。
今天我们很高兴地宣布过去计划发布的一系列公开数据集中的第一个成功开放。我们开放的数据集将面向与 Quora 相关的各种问题,并且旨在帮助在机器学习、自然语言处理、神经网络科学等领域的研究人员能够自行构建可扩展性的在线知识分享平台。我们第一个数据集与识别重复性问题相关。
Quora 一个重要的产品原则,即每一个逻辑独立的问题应该只需要一个单独的问题页面。简单地说,如询问「美国哪一个州人口最多?」和「在美国人最多的州是哪个?」,这两个问题不应该在 Quora 单独地存在,因为两个问题所要表达的意图是完全相同的。如果每一个页面都是一个逻辑独立的问题,那么就能在很多方面上让知识分享更加地高效。如知识查询者可以在一个位置查看问题的所有答案,并且如果读者群体因为不同的页面而分割,那么回答问题的作者可以获得更高的阅读量。
为了大规模减少低效的重复问题页面,我们需要一种自动化的方式来检测问题文本实际上是不是在语义上和其他问题相等。这在机器学习和自然语言处理上是很具挑战性的问题,并且也是我们一直在寻找更好解决方案的问题。
我们今天发布的数据集将让任何人可以根据实际的 Quora 数据来训练和测试语义等价模型。我们希望看到是解决这个问题的多样性方法。
我们数据集所包含的潜在重复问题对(duplicate pairs)超过 40 万行。每一行包含问题对的问题 ID 编号、完整文本以及一个表明这一行是否真正含有重复问题对的二进制值。以下这张图是我们数据集中一些行的示例:
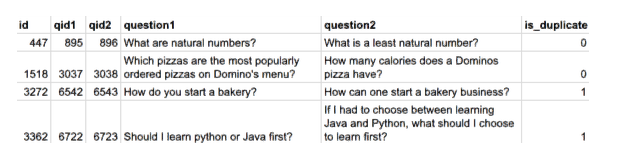
关于这个数据集的必知要点说明:
-
我们初始采样方法得到的是一个不均衡的数据集,即数据集中重复问题对(二进制值为真)的数量远远多于非重复问题对的数量。因此,我们补充了数据集中非重复问题对(二进制值为假)的数量。非重复问题对的一个来源是构建相关问题对,相关问题对中的问题尽管是属于相似的主题,但在语义上并不是完全等价的。
-
数据集中问题的分布情况并不能代表 Quora 里所问问题的分布情况。部分是因为抽样过程的系统性操作和运用了一些数据清洗方式(sanitization measures)来完成最终数据集的构建(例如:去除了包含细节描述的极长问题)
-
真值标签(ground-truth labels)含有一定量的数据噪点:并不能保证所有的标注都完美无错。
我们的数据集在 S3 上托管,只允许非商业使用且使用条件取决于我们的服务条款规定。你可以通过这个链接下载数据集:
http://qim.ec.quoracdn.net/quora_duplicate_questions.tsv
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

