英语流利说前端工程化实践

关于工程化,我有个很简单的理解,就是将工程师开发中会遇到的一般问题进行抽象并使用合适的工具,框架和规范,让工程师把精力投入在业务和一些相对有难度的问题上,围绕工程化,我们在 2016 年做了以下一些尝试:
基础库
页面的前端基础架构是 webpack + React,关于 React 的优缺点网上有足够多的文章讨论,在实际应用后我们发现,React 给我们带来了确实的好处,可以清晰地编写可复用的组件逻辑,丰富的第三方库的支持。在如今看来 React 的体积已经比较庞大了,同类产品存在无论库体积还是渲染性能都明显优于 React 的选择,通过较小的代价实现底层基础库的升级会是 2017 年很重要的目标。
面向C端的组件化之路
抽象常用页面组件
在面向C端的 wap 项目中,我们抽象了一些常用页面组件和方法,例如 Modal,Toast,请求时的锁屏动画,页面初始化的 loading 动画等,以及一些移动端开发中特有问题的解决方案,包括对 jsbridge 接口的定义和抽象以及页面适配等,这些通用的逻辑在面向C端的各个项目中被引用。
内部工具的组件化之路
流利说有着比较多且功能复杂的后端工具,包含核心课程的录入,常见的运营需求支持,学员管理,数据报表的展示,而且随着产品线的扩展,后端工具体量和数量都还会快速增加,我们遇到的问题是
1). 内部工具前期是后端工程师兼职开发工程技术栈不同,而且每个工程都有各自的设计思路和假设,导致同时维护的时候上下文需要频繁切换
2). 组件抽象不够,旧的项目中常见组件不少是从最基本的 dom 进行编写,能够支持的表现能力比较有限,且不易扩展。
我们当前的解决方案是,统一代码风格(eslint),同时使用了 antd + mobx
1). antd 所提供的组件库基本涵盖了一个内部工具 9 成以上业务逻辑
2). mobx 提供的双向绑定机制在处理表单的逻辑中直观了很多,也非常便于代码复用,而且团队内部成员相对于函数式编程更习惯面向对象的编程模型,因此上手速度相对面向函数式的 redux 会更快些。
开发辅助工具
mock 数据自动生成
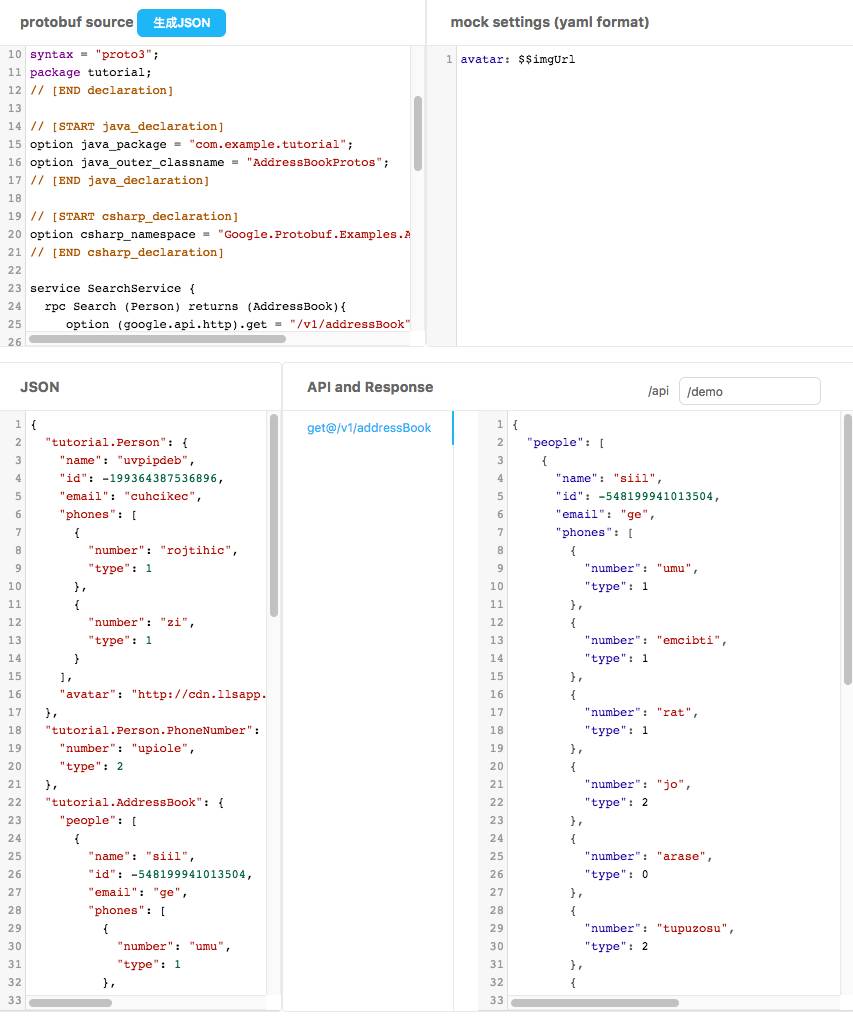
实现前后端分离之后,好处之一是两端可以各自开发,理论上约定好文档后,前端可以自行编写 mock api,直接独立于后端开发到可以提测的状态,而且基于 mock api,前端更容易覆盖各种 case 但是,每次编写 mock data 的过程重复繁琐,有时工期比较紧,前端开发也就直接跳过 mock api。 面对这一情况,我们自己开发了一个 mock data 生成工具,当前正在试用中,该工具可以根据满足 Protocal Buffer 标准的接口文档生成对应的 mock 数据,帮我们省下了 mock 数据的时间,也让前端更愿意 mock 数据。
单元测试
对于前端项目来说,尤其创业团队,单元测试都不太看重。因为网页端的项目迭代速度很快,当前正确的业务逻辑可能在下一周就被颠覆,所以单元测试带来了额外的维护和开发成本。关于这点已经有很多的文章进行讨论,基于实际开发过程的体验,我们认为至少有两部分内容是非常适合写测试的,常用的控件和一些重要页面的核心状态管理
1). 对于常用页面组件,单元测试可以确保页面组件的行为边界,方便持续集成,同时也提供了文档的功能。
2). 对于重要页面的核心状态,例如一个购买页面,内部包含不少根据用户的状态计算需要展示的页面控件,以及页面组件需要的用到的数据,如果不写单元测试,那么新增或更改一个计算规则,就可能需要手动修改 mock 数据去覆盖之前的各种逻辑,才能确保这次修改的正确性。而书写单元测试实际等价于每个测试用例描述一次后反复使用,考虑到调试和验证成本,单元测试是节约生产成本的。
异常监控
前端由于运行环境的不确定性,即使在自家的 QA 这边表现良好,也无法保证在用户那边能够显示正常,而当用户端发生问题时我们需要知道。当前我们选择了 Sentry 作为我们的异常监控工具(当时看了 the-fine-art-of-javascript-error-tracking 后),我们实际用下来感受到的优点如下:
1). 清晰的异常描述和相关信息展示(原本认为是 by default 的,但是发现国内的几家异常监控连对于 user agent 的判断都做的不好)
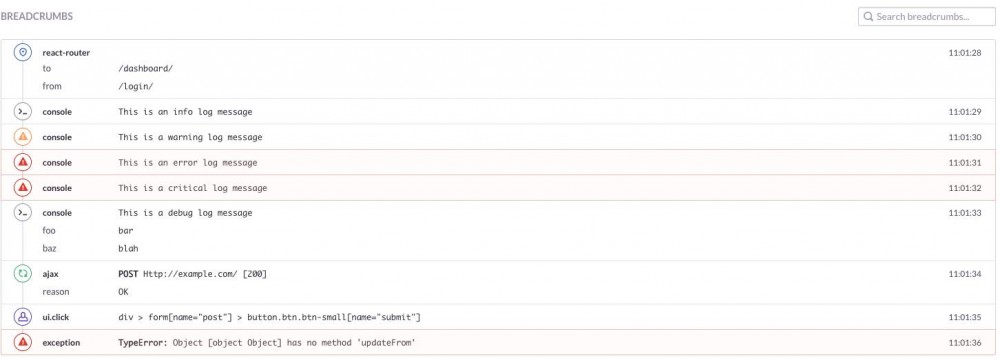
2). Breadcrumbs,收集到的出错前的一些用户行为和网络请求结果。
3). 完善的邮件以及集成 Slack 的报警机制
4). 价格不贵(相比较 New Relic)
5). 支持 sourcemap。
部署发布
我们使用 shipit-deploy 作为我们的发布工具,shipit 基本相当于 js 端的 Capistrano。对于了解 Capistrano 的发布的同学,基本就是换个语法来写,其他基本一样,覆盖发布所需要的常见需求,例如任务出错时的发布终止,或者手动回滚版本等。 shipit 的任务流是基于 orchestrator,因此如果希望定制任务流,例如插入一个任务,或者改写发布流程,都可以基于 promise 的这套策略进行重写。
我们曾经某次升级了一下某个第三方库版本,当时认为是个小改动,加上测试资源的紧张,我们覆盖了身边的手机后就发布产品,很快 Slack 的前端异常 channel 就开始报警,我们立马通过 shipit-deploy 一键回滚到正确版本,回滚后开始分析 sentry 的异常信息,很快发现在 Android 低版本中大量抛出 Object.assign is not a function,从出错代码的上下文判断应该是第三方库的代码,通过搜索很快定位到第三方库最新代码里的确直接使用了 Object.assign 这样的函数写法,且并没有做该方法调用的降级处理,于是在代码中引入相应的 polyfill,在 QA 配合下覆盖了更多机型后再次上线。 这个案例中告诫我们对于通用逻辑的修改在测试环节中还需要更谨慎。但是 sentry 报警让我们在犯错时避免了大规模的损失,准确的错误描述让我们节约了定位问题的时间,为我们发现和处理 web 端线上问题提供了很帮助。
总结和展望
过去的一年,我们在实际开发过程中归纳并落实了一些普适性的实践。在代码的生产效率,构建发布,异常监控我们都有了一些还不错的实践,在新的一年中我们会进一步强化好的实践,除此以外,我们还有一些新的目标:
1). 更好地查看线上的页面渲染性能,为页面加载性能优化提供可量化数据的数据指标。
2). 加强单元测试的覆盖力度,为频繁修改发布的前端提供更好的健壮性。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

