Twitter 背后的基础设施架构:规模
点击上方蓝色“ 网路冷眼” 可以订阅哦!
Twitter 基础设施舰队概述
Twitter 诞生自企业供应商的硬件物理上限制了数据中心发展的时代。从那时起,为了提供最好的体验,我们不断地设计和升级我们的基础设施舰队,以利用在技术和硬件效率方面最新的开放标准。
我们目前的硬件分布如下图所示:
网络流量
我们在 2010 年初开始从第三方托管迁移到内部基础设施,这意味着我们必须学习如何在内部构建和运行基础设施,并且在对核心基础设施需求的了解有限的情况下,我们开始以迭代方式尝试各种网络设计方案、硬件和供应商。
到 2010 年底,我们完成了第一个网络架构,旨在解决我们在托管colo遇到的规模和服务问题。我们使用深度的缓冲区 ToR 以支持突发业务流量和运营商级核心交换机,在该层没有超额预订。通过一些显著的工程成就支持了早期版本的Twitter发展,如我们在《天空中城堡》发布和 2014 年世界杯举办期间打破了TPS记录。
快速发展几年之后,我们在五大洲运营一个拥有POPs的网络,和拥有数十万台服务器的数据中心。在2015年初,由于不断变化的服务架构和增加的容量需求,最终达到数据中心的物理上可扩展性的上限,当全网状拓扑不支持添加新机架所需的额外硬件时,我们开始遭受成长的痛苦。此外,由于这种增加的路由规模和拓扑复杂性,开始让我们现有的数据中心 IGP表现异常。
为了解决这个问题,我们开始将现有的数据中心转换为Clos拓扑+ BGP - 这是一个必须在现场网络上完成的转换,但是尽管相当复杂,我们还是在相对较短的时间内完成了转换,将服务的影响降低到最小。网络现在看起来像这样:

新方法的亮点:
-
单个设备故障的扩散的半径更小。
-
水平带宽缩放功能。
-
降低路由引擎对CPU开销;更有效的处理路由更新。
-
由于较低的CPU开销,所以路由容量更大。
-
在每个设备和链路基础上对路由策略进行更细粒度的控制。
-
不再暴露于以前的主要事件的几个已知根本原因:增加的协议重新收敛时间,路由流失问题和与固有OSPF复杂性带来意想不到的问题。
-
启用非影响式机架迁移。
后面将进一步介绍我们的网络基础设施。
数据中心流量
挑战
我们的第一个数据中心是通过对colo中已知系统的容量和流量分布进行建模而构建的。但仅仅几年后,我们现在的数据中心需求量比原始设计大了400%。目前,随着我们的应用程序堆栈的发展和Twitter已经变得更加分散,流量剖面也发生了变化。指导我们早期网络设计的原始假设已经不再成立。
我们的流量增长速度超过了我们重新对整个数据中心进行架构设计的速度,因此建立一个高度可扩展的架构非常重要,这将允许增量式扩容而不是分叉式迁移。
高扇出微服务需要一个高度可靠的网络,可以处理各种流量。我们的流量涵盖从长寿命TCP连接到临时MapReduce作业到令人难以置信的短突发事件等范围。我们对这些不同流量模式的初步回答是部署具有深度数据包缓冲区的网络设备,但是这带来了一系列问题:更高的成本和更高的硬件复杂性。后来的设计使用更多的标准缓冲区大小和直通交换功能,以及更好的TCP堆栈服务器端,以更优雅地处理微突发事件。
经验教训
多年来,通过这些改进,我们学到了一些值得一提的东西:
-
如果流量趋势朝着你的设计能力的上端发展,那么架构师应当超越原来的规格和要求,并做出快速和大胆的变化决策。
-
依靠数据和度量来做出正确的技术设计决策,并确保这些度量可为网络运营商所理解 -- 这在托管和云环境中尤为重要。
-
并不存在作为临时改变或解决方法这样的事情:在大多数情况下,解决方法是技术债务。
骨干网流量
挑战
我们的骨干网流量年复一年显著增长 - 在数据中心之间移动流量时,我们仍然可以看到突发流量是正常流量的3-4倍。这对从未设计为处理这种情况的历史协议(例如MPLSRSVP协议)产生了独一无二的挑战,其中它采取某种形式的逐渐上升,而不是突发。我们不得不花费大量的时间调整这些协议,以获得最快的响应时间。此外,为了处理流量峰值(特别是存储复制),我们实现了优先级流量调度。虽然我们需要始终保证客户流量的交付,但我们可以延迟交付具有长达SLA天的低优先级存储复制作业。这样,我们的网络使用所有可用容量,并尽可能高效地使用资源。客户流量总是比低优先级后端流量更重要。此外,为了解决 RSVP 自动带宽带来的二进制打包问题,我们实现了TE ++,当流量增加时,创建额外的 LSP 并在流量下降时删除它们。这使我们能够有效地管理链路之间的流量,同时减少维护大量LSP的CPU负担。
虽然最初的骨干网没有任何形式的流量工程化调度,添加它以帮助我们根据我们的增长而扩展。为了帮助我们,我们完成了角色的分离,以便具有分别专用于核心和边缘路由的分离的路由器。这也使我们能够以高效成本的方式扩展,因为我们不必购买具有复杂边缘功能的路由器。
在边缘,这意味着我们有一个核心,连接一切,并能够以水平的方式(即每个站点有许多、许多路由器,而不是只有一对路由器,因为我们有一个核心层以互连所有东西)伸缩。
为了在路由器中扩展 RIB ,我们不得不引入路由反射来满足我们的规模需求,但是如此做,并且转向层次化设计,我们构建了路由反射器自己的路由反射器客户端。
经验教训
在过去一年中,我们已将设备配置迁移到模板中,现在正在定期审核它们的效果。
边缘流量
Twitter的全球网络与遍布全球众多数据中心中的3000多个独特网络直接互连。直接互联是我们的首要任务。我们将60%的流量通过我们的全球骨干网连接到互连点和POP,在此有本地前端服务器终止客户端会话,以尽可能靠近客户。
挑战
不可能预测的世界事件导致同样不可预测的突发流量。在大型活动(如体育,选举,自然灾害和其他新闻事件)期间,这些突发事件冲击我们的网络基础设施(特别是照片和视频),几乎没有预兆。我们为这些活动提供能力,并规划大型利用率峰值 - 当一个地区开展重大活动时,通常为正常峰值的3-10倍。由于我们一年多的流量增长,跟上容量变化可是一个真正的挑战!
虽然我们与所有的客户网络尽可能地同行,这仍然面临挑战。令人惊讶的是,网络或提供商更喜欢与本地市场互连,或者由于其路由策略,导致流量到达市场外的POP。虽然Twitter公开与所有主要眼球(客户)网络同行,我们看到流量,而不是所有的ISP。我们花了大量时间优化我们的路由策略,尽可能直接地为用户提供流量。
经验教训
历史上,当有人请求“www.twitter.com”时,根据其DNS服务器的位置,我们将传递他们不同的区域IP以将它们映射到特定服务器群集。这种“GeoDNS”方法是部分不准确的,因为我们不能依赖用户映射到正确的DNS服务器,或者我们能够检测DNS服务器在世界上的物理位置。此外,互联网的拓扑结构并不总是匹配地理位置。
为了解决这个问题,我们采用了“BGP Anycast”模式,我们从所有位置发布相同的路由,并优化路由,以获取从客户到我们的POP的最佳路径。通过这样做,我们在互联网的拓扑的约束内获得最好的性能,并且不必依赖于有关DNS服务器的不可预测的假设存在。
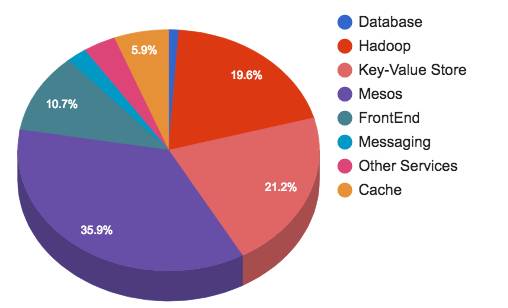
存储
每天发推数以亿计。 它们被处理,存储,缓存,服务和分析。 有了这么多的内容,我们需要一个后续的基础设施。 存储和消息传递占Twitter基础设施足迹的45%。
存储和消息传递小组提供以下服务:
-
运行计算和HDFS的Hadoop集群
-
曼哈顿集群为我们所有的低延迟键值存储
-
图存储分片MySQL簇
-
所有大对象(视频,图片,二进制文件...)的Blobstore集群
-
缓存集群
-
消息集群
-
关系型存储(MySQL,PostgreSQL和Vertica)
挑战
虽然在这个规模有很多不同的挑战,多租户是我们必须克服的更艰难的挑战。通常客户有角落会影响现有租户,迫使我们建立专用集群。更多专用集群增加了操作工作负载,以保持运行。
我们的基础设施虽然没有惊喜,但有一些有趣的点如下:
-
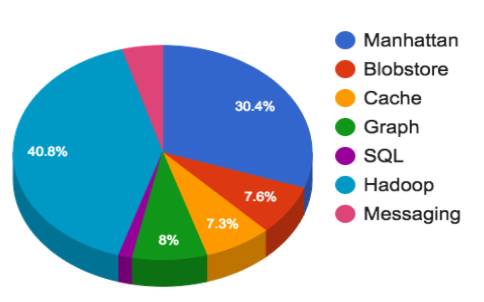
Hadoop:我们有多个集群存储超过500 PB数据,分为四组(实时,处理,数据仓库和冷存储)。我们最大的集群超过10k个节点。我们运行15万个应用程序,每天启动 130M 个容器。
-
曼哈顿(Tweets,Direct Messages,Twitter帐户等的后端):在重度写/重度读流量模式下,我们为不同的用例运行几个集群,例如大型多租户,较小的非常见,只读,读/写。只读集群处理10万QPS,而读/写集群处理1000万QPS以下。最高性能的集群,我们的可观测性集群,在每个数据中心吞吐,处理超过3000万次写入。
-
图:我们的传统Gizzard / MySQL基于分片集群来存储我们的图表。 Flock,我们的社交图,可以处理超过900万QPS的峰值,我们的MySQL服务器平均到30k - 45k QPS。
-
Blobstore:我们的图象、视频和大文件存储,存储了数百亿个对象。
-
缓存:我们的Redis和Memcache集群:缓存我们的用户,时间表,tweet等数据。
-
SQL:这包括MySQL,PostgreSQL和Vertica。 MySQL / PosgreSQL用于需要强一致性的场合,管理广告活动,广告交换以及内部工具的地方。 Vertica是一个列存储数据库,通常用作Tableau后端以支持销售和用户组织。
Hadoop/ HDFS也是我们基于Scribe的日志管道的后端,但是我们目前正在测试Apache Flume作为替代,以解决诸如缺少限制/限制选择性客户端到聚合器的限制,缺少类别的传递保证,并解决内存损坏问题。我们在压缩之后和复制之前每天处理数亿条消息,速度为6-8 GB/s,所有这些被处理消息超过500多个类别,并选择性地复制到所有集群中。
按时间顺序演变
Twitter是建立在MySQL之上,最初所有的数据都存储在它上面。我们从一个小型数据库实例到一个大型数据库实例,最后是许多大型数据库集群。在MySQL实例上手动移动数据需要大量的时间来完成工作,因此在2010年4月,我们推出了Gizzard - 一个用于创建分布式数据存储的框架。
当时的生态系统是:
-
复制MySQL集群
-
基于Gizzard的分片MySQL集群
Gizzard在2010年5月发布后,我们推出了GlockDB,一个Gizzard和MySQL基础上的图存储解决方案,并在2010年6月,Snowflake成为我们的唯一标识符服务。 2010年也是我们投资Hadoop时。最初打算存储MySQL备份,它现在被大量用于分析。
2010年左右,我们还添加了Cassandra作为存储解决方案,虽然它没有完全替换MySQL,因为它缺乏自动递增功能,它作为一个指标存储获得了采纳。随着流量呈指数增长,我们需要增长集群,并且在2014年4月,我们启动了曼哈顿:我们的实时,多租户分布式数据库。自此,曼哈顿已成为我们最常见的存储层之一,Cassandra已被弃用。
2012年12月,Twitter发布了一项功能,允许本地照片上传。在后台,这是由一个新的存储解决方案Blobstore让此成为可能。
经验教训
多年来,随着我们将数据从MySQL迁移到曼哈顿,利用更好的可用性,更低的延迟和更容易的开发,我们还采用了额外的存储引擎(LSM,b + tree ...)更好地服务于我们流量模式。此外,我们从事件中学习并开始通过发送反压信号并启用查询过滤来防止我们的存储层遭到滥用。
我们继续专注于为工作提供正确的工具,但这意味着合理地了解所有可能的用例。 “一个尺寸适合所有”解决方案很少工作 - 避免为角落建立快捷方式,因为没有什么比临时解决方案更永久。最后,不要超过一个解决方案。一切都有利有弊,需要采用现实主义方式来解决问题。
缓存
虽然Cache只占我们的基础设施的〜3%,它对Twitter至关重要。它保护我们的后备存储库免受大量读取流量,并允许存储具有重水合成本的对象。我们使用了一些缓存技术,如Redis和Twemcache,规模庞大。更具体地说,我们有专用和多租户Twitter memcached(twemcache)集群以及Nighthawk(分片Redis)集群的混合。我们已将几乎所有的主要缓存迁移到Mesos,从裸机到降低运营成本。
挑战
规模和性能是Cache的主要挑战。我们运行数百个集群,总数据包速率为320M包/秒,为我们的客户提供超过120GB/ s,我们的目标是,即使在事件尖峰时,每个响应延迟约束到99.9和99.99百分位数。
为了满足我们的高吞吐量和低延迟服务级别目标(SLO),我们需要不断地测量系统的性能并寻求效率优化。为了帮助我们这样做,我们写了rpc-perf来更好地了解我们的缓存系统的性能。这在我们从专用机器迁移到目前的Mesos基础设施时,在容量规划方面至关重要。作为这些优化努力的结果,我们的每个机器吞吐量增加了一倍以上,延迟没有变化。我们仍然认为有大的优化增益空间。
经验教训
移动到Mesos是一个巨大的运营胜利。我们编写了我们的配置,可以缓慢部署以保持命中率,避免对持久存储造成伤害,以及以更高的信心增长和扩展此层。
每个twemcache实例有数千个连接,任何进程重新启动,网络抖动和其他问题都可能触发对缓存层的DDoS攻击。随着我们的扩展,这已经成为一个问题,通过基准测试,我们已经实施了吸收规则,单独调节每个缓存的连接,当高重新连接速率否则会导致我们违反我们的SLO。
我们通过用户,Tweets,时间线等逻辑分区我们的缓存,一般来说,每个缓存集群都是为特定需要而调整的。基于集群的类型,它们处理10M到50M QPS之间,并运行在几百到几千个实例之间。
Haplo
让我们介绍一下Haplo。 它是 Tweet 时间线的主要缓存,并由Redis的定制版本(实现HybridList)支持。 Haplo是只读的从时间轴服务和写入到时间轴服务和Fanout服务。 它也是我们几个缓存服务之一,我们还没有迁移到Mesos。
-
聚合命令在每秒40M到100M之间
-
网络IO每个主机100Mbps
-
聚合服务请求每秒800K
深入阅读
多年来,Yao Yue(@thinkingfish)已经做了几个关于缓存的演讲和论文,包括使用Redis,以及新的Pelikan代码库。 欢迎观看视频和最近的博客文章。
运行大规模Puppet
我们运行一系列核心基础设施服务,如Kerberos,Puppet,Postfix,Bastions,Repositories和Egress代理。我们专注于扩展,构建工具,管理这些服务,以及支持数据中心和存在点(POP)扩展。在过去的一年中,我们将POP基础设施大幅扩展到许多新的地理位置,这需要我们如何计划,引导和发布新位置的完整重建架构。
我们使用Puppet进行所有配置管理和postkickstart包安装我们的系统。本节详细介绍了我们克服的一些挑战,以及我们的配置管理基础架构。
挑战
为了满足用户的需求,我们迅速超越了标准的工具和实践。我们每月有超过100个提交者,超过500个模块和超过1000个角色。最后,我们已经能够减少角色,模块和代码行数,同时提高我们的代码库的质量。
分支
我们有三个分支,Puppet指的是环境。这些使我们能够正确地测试,加强,并最终推动我们的生产环境的变化。我们也允许自定义分支,为更多的孤立测试。
将更改从测试到生产目前需要一些手动控制,但我们正在朝着一个具有自动化集成/退出流程的更自动化的CI系统。
代码库
我们的Puppet仓库只是Puppet代码就包含超过100万行代码,每个分支超过100,000行代码。我们最近经历了大量的努力来清理我们的代码库,减少死亡和重复的代码。
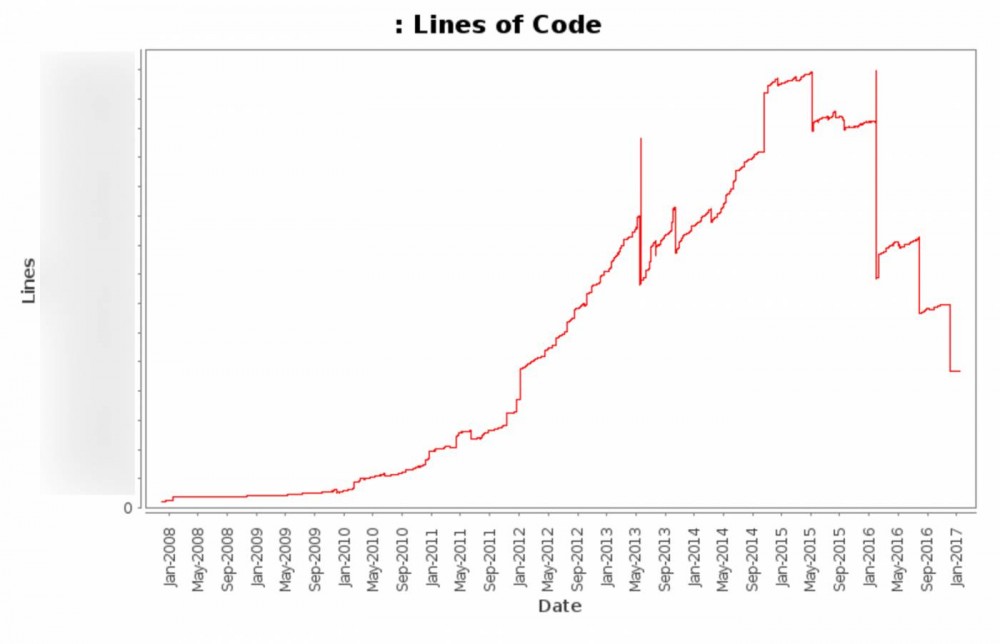
此图显示从2008年到今天的我们的总代码行(不包括各种自动更新的文件)。
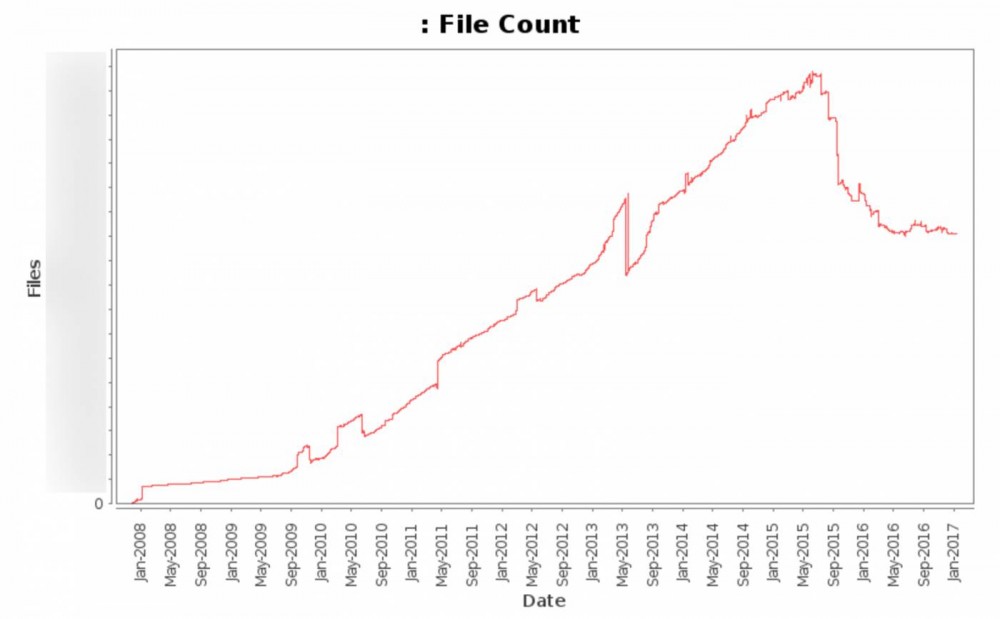
此图表显示从2008到今天的总文件数(不包括各种自动更新的文件)。
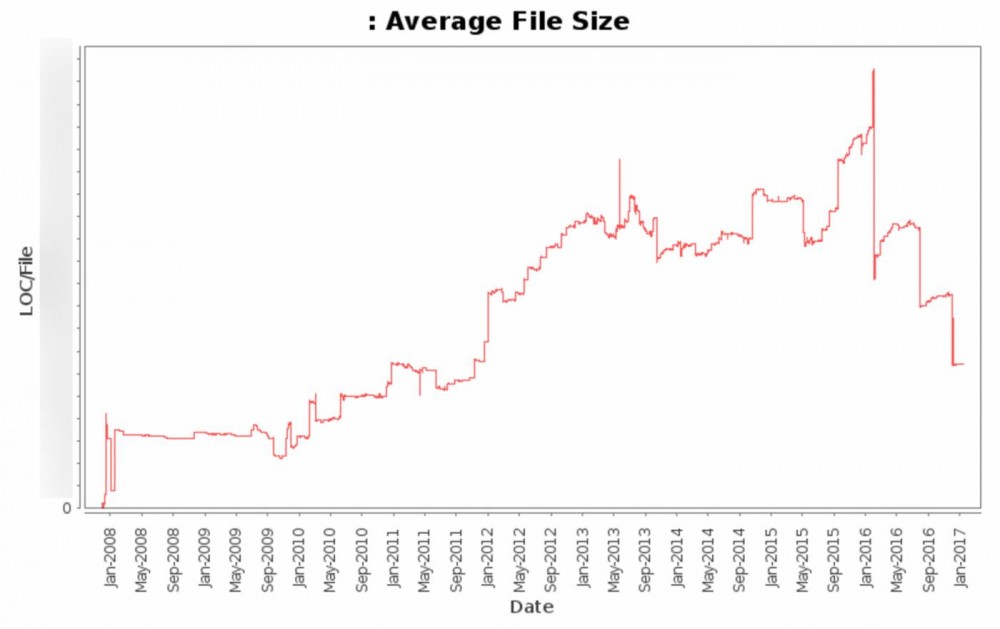
此图表显示从2008到今天的平均文件大小(不包括各种自动更新的文件)。
大胜
我们的代码库最大的优势是代码linting,风格检查钩,记录了我们的最佳实践,并保持正常办公时间。
使用棉绒工具(木偶棉绒),我们能够符合常见的社区棉绒标准。我们在我们的代码库中减少了我们的linting错误和警告数十万行,并触及了超过20%的代码库。
在初始清理之后,现在更容易在代码库中进行较小的更改,并且将自动样式检查作为版本控制钩包含在我们的代码库中,大大减少了样式错误。
在整个组织中超过 100 个 Puppet 提交者,记录内部和社区最佳实践,让我们力量倍增。使用单个文档来引用可以提高代码的质量和速度。
持有常规办公时间提供帮助(有时通过邀请)允许1:1帮助,其中门票和聊天频道不提供足够高的通信带宽或没有传达想要完成的更大的图片。因此,大多数提交者通过了解社区、最佳实践以及如何最佳地应用更改,提高了他们的代码质量和速度。
监控
系统度量通常不是有用的(参见 Caite McCaffrey 在 Monitorama 2016 上的讨论),但确实为我们发现有用的度量提供了额外的场景。
我们警告的一些最有用的度量和图表是:
-
运行失败:运行不成功Puppet的数量。
-
运行持续时间:Puppet客户端运行完成所需的时间。
-
不运行:Puppet运行的数量,不是在我们预期的时间间隔发生。
-
目录大小:目录的大小(MB)。
-
目录编译时间:编译目录需要的时间(秒)。
-
目录编译:每个主站编译的目录数。
-
文件资源:正在获取的文件数。
-
每个主机收集每个度量,并按角色进行聚合。这允许在特定角色,角色集合或更广泛的影响事件中存在问题时进行即时警报和识别。
影响
通过从Puppet 2迁移到Puppet3并升级Passenger(两个职位的另一个时间),我们能够将我们的Mesos集群上的平均Puppet运行时间从30分钟降到5分钟以下。
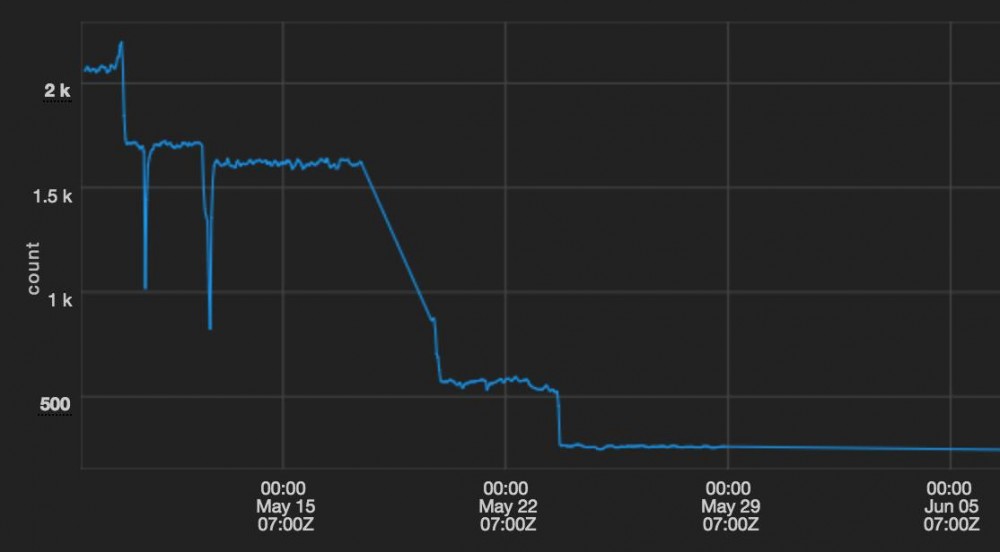
此图表显示了我们在Mesos集群上的平均Puppet运行时间(秒)。
如果你有兴趣帮助我们的Puppet基础设施,我们正在招聘!
如果您对更一般的系统配置过程,元数据数据库(Audubon)和生命周期管理(Wilson)感兴趣,Provisioning Engineering团队最近在我们的#Compute活动中介绍了这一点,并记录在这里。
如果没有Twitter工程的每个人的辛勤工作和奉献,我们就无法实现这一目标。感谢建立和贡献的可靠性的所有目前和以前在 Twitter 的工程师们!
特别感谢Brian Martin,ChrisWoodfield,David Barr,DrewRothstein,Matt Getty,PascalBorghino,Rafal Waligora,ScottEngstrom,Tim Hoffman和Yogi Sharma对本文的贡献。
原文:https://blog.twitter.com/2017/the-infrastructure-behind-twitter-scale
长按二维码可以关注“网路冷眼”

正文到此结束
- 本文标签: 配置 Twitter 目录 TCP Hadoop https 开发 HDFS 生命 管理 id 服务器 自动化 list 数据库 运营 安装 message 云 时间 测试 awk 解决方法 集群 博客 redis IO 站点 实例 db tar src map 2015 mysql 需求 定制 struct 快的 互联网 删除 数据 图片 备份 Cassandra db2 投资 sql 招聘 代码 协议 ip 二维码 进程 http UI cache apache 空间 tab DNS 企业 apr 文章 可观测性 分布式 编译 质量 组织 广告 主机
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

