伯克利 RISE 实验室大牛也在关注的深度学习库评测
雷锋网 (公众号:雷锋网) 按:本文转自微信公众号:医AI (med-ai), 来源:arXiv.org, 论文作者:Shaohuai Shi, Qiang Wang, Pengfei Xu, Xiaowen Chu,译者:吴博, Elaine, Melody
在 2016 年推出深度学习工具评测的褚晓文团队,赶在猴年最后一天,在 arXiv.org 上发布了最新的评测版本。这份评测的初版,通过国内AI自媒体的传播,在国内业界影响很大。在学术界,其反响更是非同一般。褚晓文教授在1月5日的朋友圈说David Patterson发邮件咨询他文章细节,感慨老人家论文看得仔细。
论文作者强调这是一个开源项目,所有配置文件和实验数据均在 http: //www.comp.hkbu.edu.hk/∼chxw/dlbench.html 公开。
David Patterson在体系结构领域的名声如雷贯耳,RISC之父。不熟悉的吃瓜群众可能留意到1月25日蚂蚁金服宣布跟伯克利大学前身为AmpLab,更名为RISE实验室合作的新闻。David Patterson就是RISE实验室的顶梁大佬之一。
褚晓文教授最新版本的论文对Caffe、CNTK、MXNet、TensorFlow、Torch进行比较评测。在两个CPU平台、三个GPU平台下,比较这五个深度学习库在三类流行深度神经网络(FCN、CNN、RNN)上的性能表现。并对它们在单机多GPU卡环境下分布式版本进行了比较。相比以前的评测,最新的评测添加了对多GPU卡的测试,把MXNet纳入评比范围,还测试了MNIST和Cifar10这两个真实数据集。
 简介
简介
在过去十年中,深度学习已成功应用到不同领域,包括计算机视觉、语音识别和自然语言处理等。深度学习的成功,归因于许多层人工神经元对输入数据的高表征能力。而GPU通过显著缩短训练时间,在深度学习的成功中扮演着重要的角色。为了提高开发深度学习方法的效率,有很多开源的深度学习工具包,包括伯克利大学的Caffe,微软的CNTK,谷歌的TensorFlow,还有Torch,MXNet,Theano,百度的 PaddlePaddle等。这些工具都支持多核CPU和超多核GPU。
深度学习的主要任务之一,是学习网络的每一层的权重,这可以通过向量或矩阵运算来实现。TensorFlow使用 Eigen作为矩阵加速库,而 Caffe、CNTK、MXNet和Torch采用OpenBLAS、Intel MKL 或 cuBLAS 来加快相关矩阵运算。所有这些工具包都引入了cuDNN,这是一个为神经网络计算进行GPU加速的深度学习库。但是,由于优化方法的差异,加上不同类型的网络或使用不同类型的硬件,上述工具包的性能差异很大。
鉴于深度学习软件工具及其底层硬件平台的多样化,终端用户难以选择合适的平台来执行深度学习任务。在此论文中,作者用三种最主要的深度神经网络(全连接神经网络FCN,卷积神经网络CNN,以及循环神经网络RNN)来基准评测当下最先进的基于GPU加速的深度学习工具(包括Caffe,CNTK, MXNet, TensorFlow 和Torch),比较它们在CPU和GPU上的运行时间性能。
几个工具的性能评估既针对合成数据,也针对真实数据。评测的硬件平台包括两种CPU(台式机级别的英特尔i7-3820 CPU,服务器级别的英特尔Xeon E5-2630 CPU)和三种Nvidia GPU (GTX 980、GTX 1080、Telsa K80,分别是Maxwell、Pascal和Kepler 架构)。作者也用两个Telsa K80卡(总共4个GK210 GPU)来评估多GPU卡并行的性能。每种神经网络类型均选择了一个小型网络和大型网络。
该评测的主要发现可概括如下:
-
总体上,多核CPU的性能并无很好的可扩展性。在很多实验结果中,使用16核CPU的性能仅比使用4核或8核稍好。TensorFlow在CPU环境有相对较好的可扩展性。
-
仅用一块GPU卡的话,FCN上Caffe、CNTK和Torch比MXNet和TensorFlow表现更好;CNN上MXNet表现出色,尤其是在大型网络时;而Caffe和CNTK在小型CNN上同样表现不俗;对于带LSTM的RNN,CNTK速度最快,比其他工具好上5到10倍。
-
通过将训练数据并行化,这些支持多GPU卡的深度学习工具,都有可观的吞吐量提升,同时收敛速度也提高了。多GPU卡环境下,CNTK平台在FCN和AlexNet上的可扩展性更好,而MXNet和Torch在CNN上相当出色。
-
比起多核CPU,GPU平台效率更高。所有的工具都能通过使用GPU达到显著的加速。
-
在三个GPU平台中,GTX1080由于其计算能力最高,在大多数实验结果中性能最出色。
-
某种程度上而言,性能也受配置文件的影响。例如,CNTK允许用户调整系统配置文件,在运算效率和GPU内存间取舍,而MXNet则能让用户对cuDNN库的自动设置进行调整。
背景及相关知识
随着深度学习技术的快速发展,人们针对不同的应用场合开发出各类深度神经网络,包括全连接神经网络(FCN)、卷积神经网络(CNN)、循环神经网络(RNN)、局限型波兹曼机(RBM)。此论文着重分析三种神经网络(FCN、CNN和RNN)的运行性能(或时间速度)及收敛速度。
FCN的历史可追溯到上世纪80年代,反向传播算法(backpropagation)发明之时。而CNN和RNN,一直以来分别在图像识别和自然语言处理应用上展现出优异的效果。
FCN是一个前向神经网络,由Yann LeCun等人在1989年成功应用于邮编识别。为了减少每一层的参数数量,CNN通过使用一组核(kernel),建立了一个卷积层,每个核的参数在整个域(例如:一个彩色图像的通道)共享。CNN能减轻全连接层容易导致需要学习大量参数的问题。从LeNet架构开始,CNN已经实现很多成果,包括ImageNet分类、人脸识别和目标检测。
RNN允许网络单元的循环连接。RNN可以将整个历史输入序列跟每个输出相连,找到输入的上下文特性和输出之间的关系。有了这个特性,RNN可以保留之前输入的信息,类似于样本训练时的记忆功能。此外,长短时记忆(LSTM)通过适当地记录和丢弃信息,能解决RNN训练时梯度消失和爆炸的难题。含LSTM单元的RNN被证实是处理语音辨识和自然语言处理任务最有效的方法之一。
随着深度学习日益成功,诞生了许多受欢迎的开源GPU加速工具包。其中,Caffe、CNTK、MXNet、TensorFlow和Torch是最活跃、最受欢迎的例子。
Caffe由伯克利视觉和学习中心(BVLC)开发,自2014成为开源项目。作者声称Caffe可以借助NVIDIA K40或Titan GP卡,每天用GPU加速版本处理4000万图像。结合cuDNN之后,还可以加速约1.3倍。
CNTK是一个由微软研究院开发的工具包,支持大部分流行的神经网络。在2015年2月,官方报道了一个基准性能测试结果,针对一个4层全连接神经网络,CNTK与Caffe、TensorFlow、Theano和Torch对比,速度要快上1.5倍。
MXNet是一个支持多种语言的深度学习框架,旨在提供更灵活有效的编程接口,以提升生产效率。
TensorFlow由谷歌开发,它使用数据流图集成了深度学习框架中最常见的单元。它支持许多最新的网络如CNN,以及带不同设置的RNN。TensorFlow是为超凡的灵活性、轻便性和高效率而设计的。
Torch是一个科学计算框架,它为机器学习里最为有用的元件——如多维张量——提供数据结构。

(a) 全连接神经网络 (b) 卷积神经网络(AlexNet) (c) 循环神经网络
图1:深度学习模型的例子
为了加快深度神经网络的训练速度,有的使用CPU SSE技术和浮点SIMD模型来实现深度学习算法,相比浮点优化的版本能实现3倍加速。Andre Viebke等人利用多线程及SIMD并行化在英特尔Xeon Phi处理器上加速CNN。针对多GPU卡的并行化,Jeffrey Dean等人提出了一种大规模分布式深度网络,开发了两种算法(Downpour SGD和Sandblaster L-BFGS),可以在混有GPU机器的集群上运行。
加快训练方法的另一种方式是减少要学习的参数数量,Song Han等人使用修剪冗余连接的方法,在不失去网络表征能力下减少参数,这可以减少670万到6100万的AlexNet参数。Bahrampour等人也做了类似的性能评测工作,但他们仅用了一个GPU架构(NVIDIA Maxwell Titan X)和旧版的软件(cuDNN v2, v3)。
本文作者早前工作也探讨了单个GPU上跑旧版软件的基准测试结果。此文针对三版主要的GPU架构和一些最新的网络(如:ResNet-50)和软件(如:cuDNN v5)进行基准评测,并深入到工具包代码分析性能。此外,本文也比较了单台机器里多个GPU卡的性能。
因为单个GPU卡内存相对较少,限制了神经网络规模,训练的可伸缩性对于深度学习框架至关重要。在如今的深度学习工具中,支持多GPU卡成为了一个标准功能。为了利用多个GPU卡,分布式同步随机梯度下降法(SDG)使用很广泛,实现了很好的扩展性能。
在可扩展性方面,本文作者着重评估处理时间,以及数据同步方法的收敛速度。在数据并行模型里,针对N个worker,把有M个样本的一个mini-batch分成N份,每份M/N个样本,每个worker用相同的模型独立向前向后处理所分配的样本。当所有worker完成后,把梯度聚合,更新模型。
实际上,不同工具实现同步SGD算法的方式各有不同。
-
Caffe:采用删减树策略减少GPU间的数据通信。例如,假设有4个标记为0,1,2,3的GPU。首先,GPU 0和GPU 1交换梯度,GPU 2和GPU 3交换梯度,然后GPU 0和GPU 2交换梯度。之后,GPU 0会计算更新的模型,再将更新的模型传输到GPU 2中;接着GPU 0把模型传输到GPU 1,同时GPU 2把模型传输到GPU 3。
-
CNTK:使用MPI作为GPU之间的数据通信方法。CNTK支持4种类型的并行SGD算法(即:DataParallelSGD,BlockMomentumSGD,ModelAveragingSGD,DataParallelASGD)。对于本文关心的 data parallel SGD,CNTK把每个minibatch分摊到N个worker上。每次mini-batch后将梯度进行交换和聚合。
-
MXNet:同样将mini-batch样本分配到所有GPU中,每个GPU向前后执行一批规模为M/N的任务,然后在更新模型之前,将梯度汇总。
-
TensorFlow:在每个GPU上放置一份复制模型。也将mini-batch分到所有GPU。
-
Torch:其数据并行机制类似于MXNet,把梯度聚合的操作放在GPU端,减少了PCI-e卡槽的数据传输。
评测方法
处理时间(ProCESsing time)及收敛速度(Convergence rate)是用户训练深度学习模型时最看重的两个因素。因此该实验主要通过测量这两个指标以评估这几种深度学习工具。
一方面,评估处理时长有一种高效且主流的方法,就是测出对一个mini-batch所输入数据一次迭代的时长。在实际操作中,经历多轮迭代或收敛以后,深度学习的训练过程会终止。因此,对于每种神经网络,该实验使用不同大小的mini-batch来评测各个深度学习软件工具。作者针对每种大小的mini-batch都多次迭代,最后评估其平均运行速度。另一方面,由于数据并行化可能影响收敛速度,该评测还在多GPU卡的情况下比较了收敛速度。
评测使用合成数据集和真实数据集。合成数据集主要用于评估运行时间,真实数据集用于测量收敛速度。每种工具的时间测量方法如下:
-
Caffe:使用“caffe train”命令训练所指定网络,随之计算两次连续迭代过程间的平均时间差。
-
CNTK:与Caffe类似,但排除包含磁盘I / O时间的首个epoch。
-
MXNet:使用内部定时功能,输出每个epoch和迭代的具体时间。
-
TensorFlow:在源脚本里使用计时功能,计算平均迭代时间。
-
Torch:和TensorFlow一样。
这几种工具均提供非常灵活的编程API或用于性能优化的配置选项。例如CNTK中可以在配置文件中指定“maxTempMemSizeIn-SamplesForCNN”选项,以控制CNN使用的临时内存的大小,虽然可能导致效率略微降低,但是内存需求更小了。
MXNet、TensorFlow和Torch也有丰富的API,在用于计算任务时供用户选择。换句话说,可能存在不同API以执行相同的操作。因此本评测结果仅仅是基于作者对这些工具用法的理解,不保证是最佳配置下的结果。
评测中的深度学习软件版本和相关库如表1所示。

表1:用于评测的深度学习软件
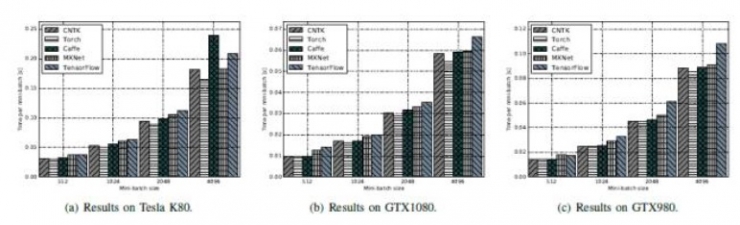
神经网络和数据集:对于合成数据的测试,实验采用具有约5500万个参数的大型神经网络(FCN-S)来评估FCN的性能。同时选择ImageNet所选的AlexNet和ResNet-50作为CNN的代表。
对于真实数据的测试,为MNIST数据集构建的FCN(FCN-R)较小;针对Cifar10数据集则使用名为AlexNet-R和ResNet-56的AlexNet架构。对于RNN,考虑到主要计算复杂度与输入序列长度有关,作者选择2个LSTM层进行测试,输入长度为32。每个网络的详细配置信息如表2和表3所示。
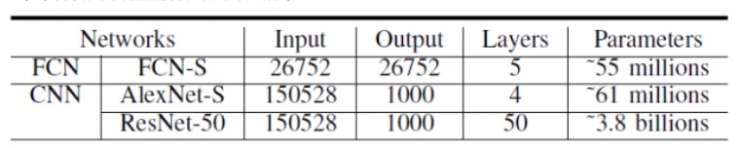
表2:合成数据的神经网络设置。注意:FCN-S有4层隐藏层,每层2048个节点;并且AlexNet-S中排除了batch normalization操作和dropout操作;为了测试CNN,输入数据是来自ImageNet数据库的彩色图像(维度224×224×3),输出维度是ImageNet数据的类别数量。 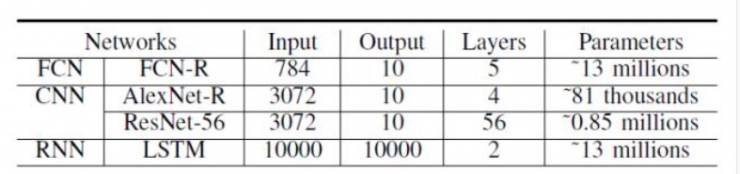
表3:真实数据的神经网络设置。注:FCN-R有3个隐藏层,节点数分别为2048、4096和1024。AlexNet-R的架构与原始出处里Cifar10所用的AlexNet相同,但不包括本地响应规范化(LRN)操作(CNTK不支持)。对于ResNet-56,作者沿用了最原始文件里的架构。
硬件平台:评测使用两种类型的多核CPU,其中包括一个4核台式机级CPU(Intel i7-3820 CPU @ 3.60GHz)和两个8核服务器级CPU(Intel XeonCPU E5-2630 v3 @ 2.40GHz),测试不同线程数下各个工具的性能。另外还用三代不同的GPU卡,分别是采用Maxwell架构的NVIDIA GTX 980 @ 1127MHz,采用Pascal架构的GTX 1080 @1607MHz,以及采用Kepler架构的Telsa K80 @ 562MHz。
评测只使用K80 GPU两个GK210芯片中的一个进行单GPU比较,同时,为了使得结果可重复,已禁用GPU自动超频功能。为了避免神经网络大小对主机内存的依赖,两台测试机分别配备64g+B内存和128GB内存。硬件配置的详细信息如表4所示。
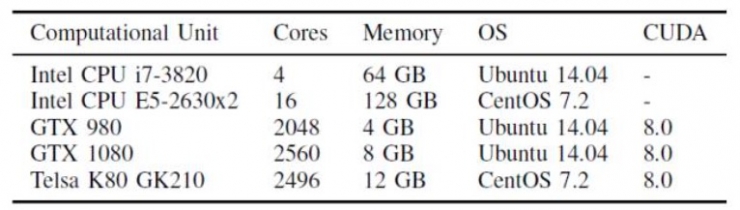
表4:本评测的硬件设置。注:K80卡上有2个GK210 GPU,但为了比较测试单GPU性能仅使用一个GPU。
数据并行化评测则在两个Tesla K80卡上进行,这样共有4个GK210 GPU。对于多GPU卡实验,系统配置如表5所示。

表5:数据并行性的评测硬件设置。注:K80卡上有两个GK210 GPU,因此进行双GPU并行评测时使用一个K80卡,进行四GPU并行评测时使用两个K80卡。
各神经网络,软件工具和硬件的组合结果如表6所示。
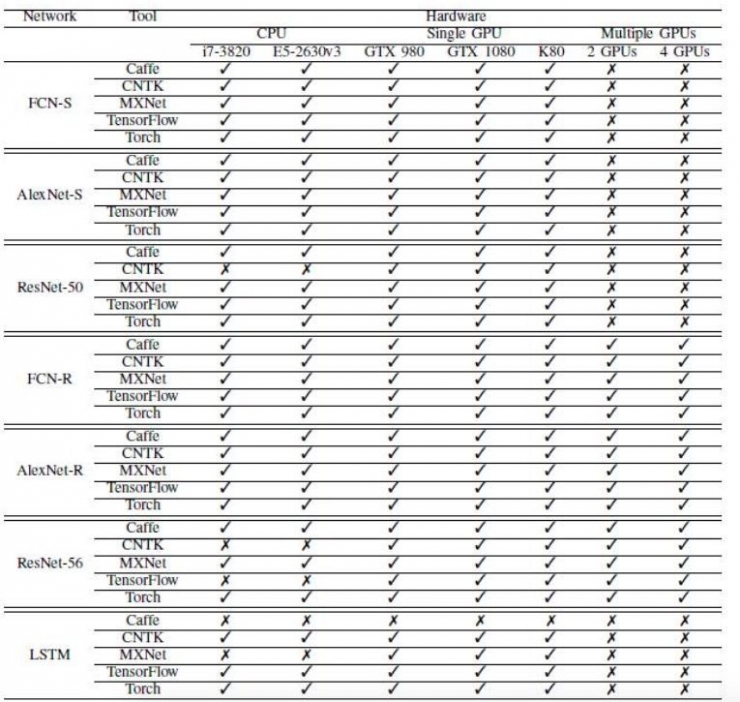
表6:各神经网络、软件工具和硬件的组合结果
评测结果
评测结果分别在三个子部分呈现:CPU结果,单GPU结果和多GPU结果。对于CPU结果和单GPU结果,主要关注运行时长;对于多GPU还提出了关于收敛速度的比较。不同平台上的主要评测结果参见表7及表8。
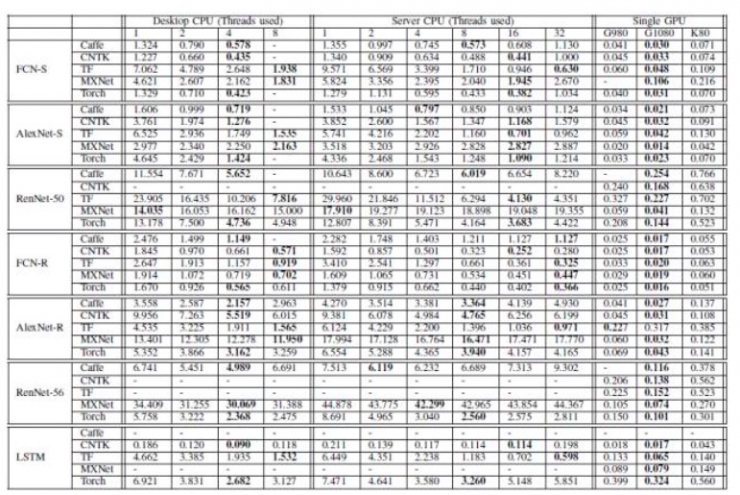
表7:评测对比结果(每个mini-batch的运算时间,单位:秒)。注:FCN-S,AlexNet-S,ResNet-50,FCN-R,AlexNet-R,ResNet-56和LSTM的mini-batch大小分别为64,16,16,1024,1024,128,128。
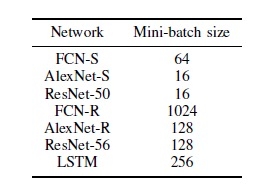
表8:单GPU与多GPU间的比对结果(每个mini-batch的运算时间,单位:秒)。注:FCN-R,AlexNet-R和ResNet-56的mini-batch大小分别为4096,1024和128。
4.1. CPU评测结果
具体参见表7及原文。
4.2. 单GPU卡评测结果
在单GPU的比较上,该评测还展示了不同mini-batch大小的结果,以展示mini-batch大小对性能的影响。(译者注:原论文结论中详细描述了不同mini-batch大小下各学习工具的性能,具体见图表)
4.2.1. 合成数据(Synthetic Data)

FCN-S:Caffe最佳,其次是CNTK和Torch,最后是TensorFlow及MXNet。
AlexNet-S:MXNet性能最佳,其次是Torch。
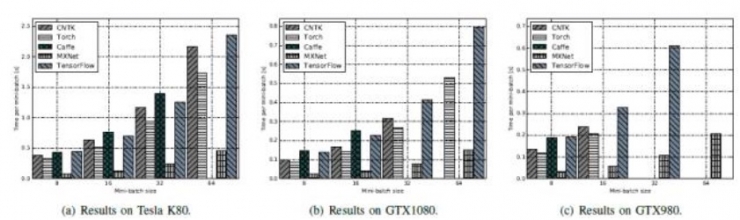
ResNet-50:MXNet性能远远高于其他工具,尤其是mini-batch大小比较大的时候。其次是CNTK和TensorFlow,Caffe相对较差。
4.2.2. 真实数据(Real Data)
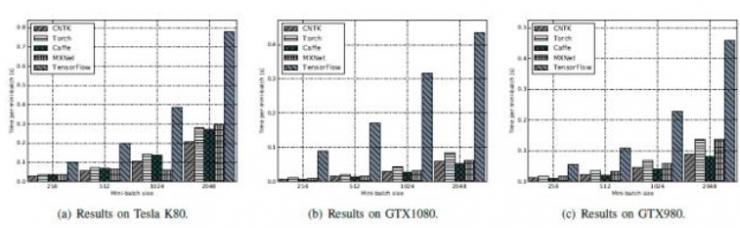
FCN-R:Torch最佳,Caffe、CNTK及MXNet三个工具次之,TensorFlow最差。
AlexNet-R:K80 平台上CNTK表现最佳,Caffe和Torch次之,然后是MXNet。TensorFlow处理时间最长。

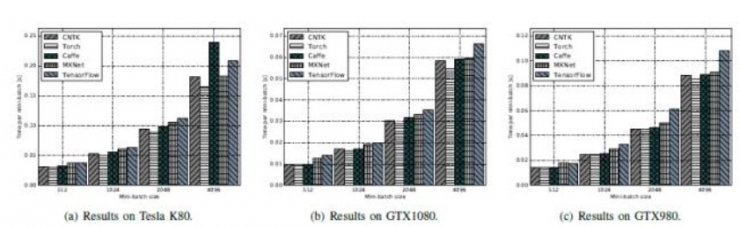
ResNet-56:MXNet最优,其次是Caffe、CNTK 和Torch,这三个接近。最后是TensorFlow。

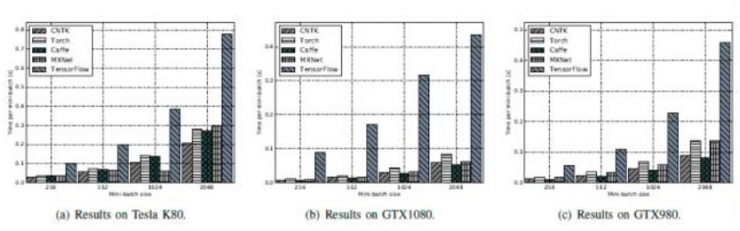
LSTM:CNTK全面超越其他工具。
4.3.多GPU卡评测结果
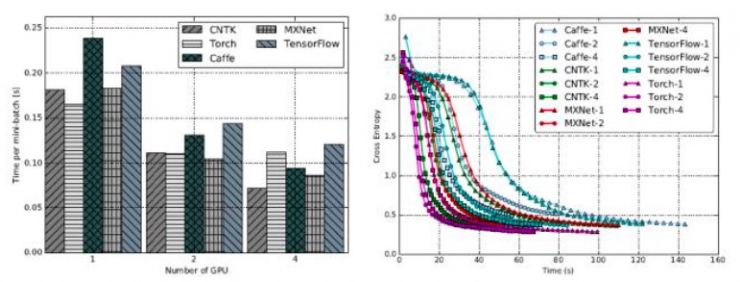
FCN-R:单GPU的情况下,Caffe、CNTK及MXNet接近,TensorFlow和Torch稍差。GPU数量翻番时,CNTK和MXNet的可扩展性最佳,均实现了约35%的提速,caffe实现了大约28%的提速,而Torch和TensorFlow只有约10%。GPU数量变为4个时,TensorFlow和Torch没有实现进一步的提速。
而收敛速度往往随着GPU数量的增加而增快。单个GPU时,Torch的训练融合速度最快,其次是Caffe、CNTK和MXNet,TensorFlow最慢。当GPU的数量增加到4时,CNTK和MXNet的收敛速度率接近Torch,而Caffe和TensorFlow收敛相对较慢。

AlexNet-R:单个GPU时,CNTK,MXNet和Torch性能接近,且比Caffe和TensorFlow快得多。随着GPU数量的增长,全部工具均实现高达40%的提速,而TensorFlow只有30%。
至于收敛速度,MXNet和Torch最快,CNTK稍慢,但也比Caffe和TensorFlow快得多。
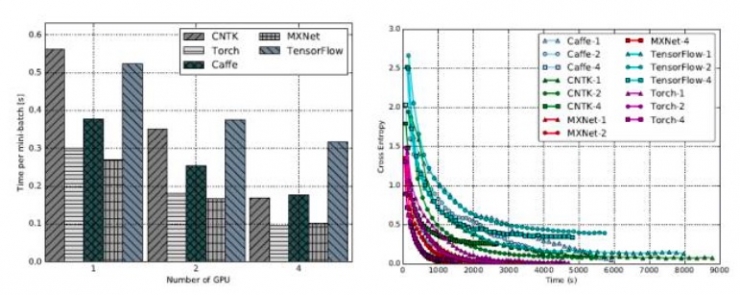
ResNet-56:单GPU时,Torch用时最少。多个GPU时,MXNet往往更高效。
至于收敛速度,整体来说MXNet和Torch比其他三个工具更好,而Caffe最慢。
讨论
对于CPU并行,建议线程数不大于物理CPU内核数。因为在计算过程中需要额外的CPU资源来进行线程调度,如果CPU资源全部用于计算则难以实现高性能。然而,借助于Eigen的BLAS库(BLAS library),因其为了SIMD指令优化过,因此随着CPU内核数的增长,TensorFlow的性能能更好。
在FCN神经网络上,如果只用一个GPU卡,那么Caffe、CNTK和Torch的性能要比MXNet和TensorFlow略好。
通常来说,训练一个网络包含两阶计算(即前馈和后向传播)。在前馈阶段,矩阵乘法是最耗时的操作,评测的四个工具全部采用cuBLAS API:cublasSgemm。如果想要把矩阵A乘以矩阵B的转置,可以将cublasSgemm API的第二个参数设置为CUBLAS_OP_T,即应用in-place矩阵转置。但这就导致与没有转置的矩阵乘法相比,性能减慢3倍(例如,C = A×B^T,其中 A∈R^1024×26752 ,B∈R^2048×26752)。这是因为in-place矩阵转置非常耗时。CNTK和TensorFlow构造自己的数据结构,从而用的是cublasSgemm的CUBLAS_OP_N,而Caffe和Torch使用CUBLAS_OP_T。
在后向传播的阶段,则需要使用矩阵乘法来计算梯度,并使用element-wise矩阵运算来计算参数。如果通过调用cuBLAS来将A乘以B的转置,效率低时,可先转置B(如果GPU具有足够的内存,则采用out-place)再应用矩阵乘法可能会效果更好。
此外,cublasSgemm API完全支持后向传播,因为它在矩阵乘法后添加了一个缩放的矩阵。因此,如果将梯度计算和更新操作合并到单个GPU核中,则可以提高计算效率。为了优化FCN的效率,还可以在不转置的情况下使用cublasSgemm API,并同时使用cublasSgemm来计算梯度及执行更新操作。
在CNN上,所有工具包均使用cuDNN库进行卷积运算。尽管API调用相同,但是参数可能导致GPU内核不同。相关研究发现,在许多情况下,与直接执行卷积运算相比,FFT是更合适的解决方案。在矩阵的FFT之后,卷积计算可以被转换为更快速的内积运算(inner product operation)。
对于使用多个GPU卡的数据并行性,运算的扩展性受到梯度聚合处理的极大影响,因为其需要通过PCI-e传输数据。在本评测的测试平台中,Telsa K80的PCIe 3.0的最高吞吐量约为8GB/秒,这意味着在FCN-R情况下需要0.0256秒的时间将GPU的梯度转移到CPU。但是一个mini-batch的计算时间只有大约100毫秒。因此,减少GPU和CPU之间传输数据的成本将变得极为关键。
不同软件工具的性能表现各异,且与并行设计的策略相关。在Caffe中,梯度更新在GPU端执行,但它使用了树减少策略(tree reduction strategy)。如果说有4个GPU用于训练,则两对GPU将首先各自交换梯度(即GPU 0与GPU 1交换,GPU 2与GPU 3交换),然后GPU 0与GPU 2交换。之后,GPU 0负责计算更新的模型,再将模型传送到GPU 1,然后0将模型传送到1,2传送模型到3,这是一个并行过程。
因此,Caffe的可扩展性(scalability)的性能在很大程度上取决于系统的PCI-e拓扑。CNTK的作者在框架中添加了1比特的随机梯度下降(1-bit stochastic gradient descent),这意味着PCI-e交换梯度的时间可大大缩短。因此,即使使用大型网络,CNTK的可伸缩性也依旧表现良好。
在这类网络上,MXNet也表现出良好的可扩展性,因为它是在GPU上进行梯度聚合,这不仅减少了经常传输梯度数据的PCI-e时间,并能利用GPU资源来进行并行计算。
然而,TensorFlow在CPU端进行梯度聚合和模型更新,这不仅需要很多时间通过PCI-e传输梯度,而且还使用单个CPU更新串行算法中的模型。因此TensorFlow的伸缩性不如其他工具。
对于多个GPU,Torch在扩展性上与TensorFlow类似。其梯度聚合和更新都在CPU端执行,但Torch使用了并行算法来利用所有空闲的CPU资源。因此,其伸缩性要略好于TensorFlow,但仍然比不上Caffe、CNTK和MXNet。
总的来说,因为有了GPU计算资源,上述所有深度学习工具的速度与CPU的版本相比,都有了极大提高。这并不出奇,因为在GPU上的矩阵乘法以及FFT的性能要明显优于CPU。
未来作者还将评测更多的深度学习工具(比如百度的Paddle),也会把 AMD的GPU等也加入评测。并在高性能GPU集群上进行评测。
雷锋网注:以下为原论文链接 雷锋网
https://arxiv.org/pdf/1608.07249v6
雷锋网版权文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

