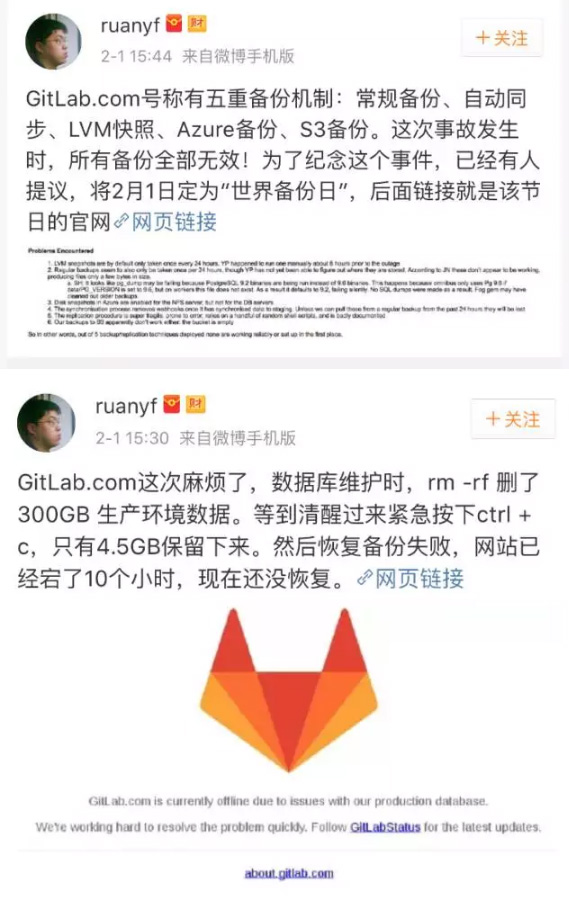
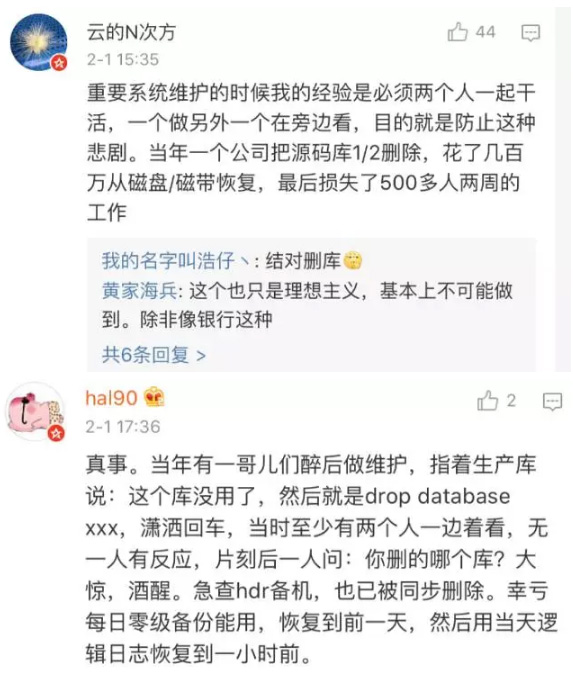
GitLab.com崩溃,rm -rf 删了300GB 数据;要命的是,备份偏偏失效

这家后起之秀声称发展势头迅猛,其云已跟不上形势,现在五个恢复工具已全部失效。
源代码托管中心GitLab.com在数据遭遇丢失后崩溃,而数据丢失归咎于它突然发现备份的内容是无效的。
太平洋时间周二晚上,这家初创公司发布了一系列令人不安的推特消息,我们在下面列了出来。幕后原因是,一名疲惫不堪的系统管理员在荷兰工作到深夜,他在令人沮丧的数据库复制过程中不小心删除了一台不该删除的服务器上的目录:他彻底删除了一个含有300GB活动生产数据的文件夹,而这些数据还没有完全复制过来。

等到他取消rm -rf命令时,已只剩下了区区4.5GB数据。上一套可能切实可行的备份是在事先六个小时所做的。
我们正在执行紧急数据库维护,https://t.co/r11UmmDLDE将处于离线状态。
— GitLab.com状态(@gitlabstatus)2017年1月31日
我们的生产数据库遇到了问题,正在努力恢复。
— GitLab.com状态(@gitlabstatus)2017年2月1日
我们不小心删除了生产数据,可能不得不从备份系统来恢复。带活动说明(live note)的Google Doc https://t.co/EVRbHzYlk8
— GitLab.com状态(@gitlabstatus)2017年2月1日
在最后一则推特消息说明中提到了那个Google Doc:“这起事件影响了数据库(包括问题和合并请求),但是没有影响git代码库(代码库和维基)。”
所以对用户来说多少有点安慰,因为并非所有数据全部丢失。但是文档在结尾处是这样写道:
所以换句话说,在部署的5套备份/复制方法中,没有一套在可靠运行或当初设置正确。
此话一出,网上炸开了锅。为了概述所犯的错误,这家初创公司坦率地作了如下详述:
- LVM快照在默认情况下每24小时做一次。在故障发生前大概6小时,YP正好手动运行了一次。
- 常规备份似乎也是每24小时做一次,不过YP还未能查清楚它们存储在何处。据JN声称,这些似乎未奏效,只生成了几个字节大小的文件。
- SH:pg_dump似乎失效了,原因是运行的是PostgreSQL 9.2二进制代码,而不是9.6二进制代码。之所以会出现这种情况,是由于如果data/PG_VERSION被设成9.6,omnibus只使用Pg 9.6,但是在worker节点上,该文件并不存在。因而,它在默认情况下运行9.2,悄然失效。因而没有SQL转储出现。Fog gem可能清除掉了早些时候的备份。
- 已为NFS服务器启用了Azure中的磁盘快照,但是没有为数据库服务器启用Azure中的磁盘快照。
- 一旦将数据同步到试运行环境,同步过程就消除Web勾子(webhook)。除非我们可以在过去的24小时内从常规备份中获取这些数据,否则它们将丢失殆尽。
- 复制程序很不可靠,容易出错,依赖几个随机性的外壳脚本,而且缺少完备的说明文档。
- 我们备份到S3的内容显然也没有奏效:存储桶(bucket)空空如也。
雪上加霜的是这个事实:GitLab去年声称其业务发展势头迅猛,其云跟不上需求,将构建和运行自己的Ceph集群。GitLab的基础设施主管帕布罗·卡兰扎(PabloCarranza)表示,决定部署自己的基础设施“会让GitLab更高效、更稳定、更可靠,因为我们对整个基础设施将拥有更大的控制权。”
它此后收回了这个决定,通过推特消息告诉我们下列信息:
@TheRegister @gitlab将致力于让应用系统拥有更高的性能,并在考虑选择其他的云托管提供商。
— Connor Shea(@connorjshea)2017年2月1日
截至本文截稿时,GitLab表示它并没有估计多久后恢复如初,但是正在努力从一台试运行服务器来恢复,这台试运行服务器可能“没有Web勾子”,却是“唯一可用的快照。”该源代码是6小时前创建的,所以肯定丢失了部分数据。
去年,创办于2014年的GitLab筹集到了2000万美元的风投资金。眼下,那些投资者可能比用户来得更抓狂一点。
如果获得更多的信息,TheRegister会在第一时间更新本文。那位误删除活动数据的系统管理员认为“现在他最好别再使用超级用户权限来运行任何命令了。
英语原文: GitLab.com melts down after wrong directory deleted, backups fail
本文由云头条翻译,来自云头条微信公众号
End.
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

