基于Twitter的Snowflake算法实现发号器
在微服务架构的系统中,ID号的生成是一个需要考虑的问题。通常单体系统会依赖RDB的自增字段(例如MySQL)或者序列(例如PostgreSQL等)来产生业务序号。在微服务架构的系统中也使用类似的方式时就会出现一些问题。
在单体系统中,我们可能会使用自增字段,或者序列,它们通常依赖于关系型数据库插入动作时产生的ID。不过由于ID是在持久化到数据库时才产生,所以我们无法提前获取一个ID号。对于单体系统而言并没有什么问题,但当存在多个系统协作时,我们可能希望提前生成业务的ID号,以保证业务可以以幂等的方式进行操作。为了解决这个问题,ID生成可以先独立出单独的模块,每次产生一个新的ID号供业务方使用。
不过利用RDB的序列(MySQL可以模拟一个序列)来进行发号,通常存在性能瓶颈。因为业务操作必须先在RDB操作后,才能取得新的ID号。一旦RDB是单点系统,那么所有业务的可用性都会受到影响。另外连续的ID号可能会暴露业务的信息,通过ID号可以间接地刺探到业务的规模,也更容易受到攻击,一旦存在权限验证不严的系统,攻击者可以轻而易举的枚举全部的信息访问。
UUID是一种专门设计用来在分布式系统中生成ID的工具。它可以产生一个128bit的ID号。目前常见的版本是v1和v4,其中v1版本使用时间戳、MAC地址、随机数来生成一个ID号,v4版本使用随机数来产生ID号。但是UUID通常情况下过于冗长,存储为一个32+4个字符串,作为业务ID使用并不方便,另外UUID依然存在冲突的可能性,只不过这种可能系非常低。
使用UUID用做分布式系统的ID生成器是一种选择,但是更多时候我们希望ID号可以:
- 生成高效,可分布式并行发号
- 大致时间顺序(对于数据分片、排序友好)
- 稀疏不连续
- 可以使用64bit整型存储
- 可预见的时间范围内不重复
Twitter开源了他们的ID生成器,被称作snowflake,项目地址在 https://github.com/twitter/snowflake 。不过目前Twitter已经完全重写了他们的发号器,因此这个项目现在处于关闭状态,参考源代码只能查看2010年的初始tag,目前也不再维护这个项目了。
不过Snowflake却成为了现在常见发号器实现的重要思路:
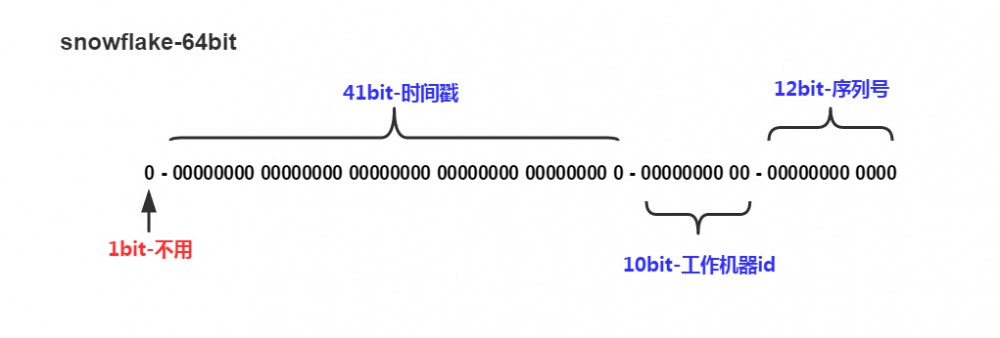
图片来自 Twitter-Snowflake,64位自增ID算法详解
一个Snowflake算法生成的ID号包括
- 41bit的时间戳
- 10bit的工作机器ID
- 12bit的序列号
在实际使用中,为了让时间戳保有更大的容量,通常取现在的毫秒时间戳,减去一个基准时间的时间戳。41bit的时间戳可以容纳差不多70年的毫秒数,对于大多数系统来讲是足够了;10bit的工作实例ID,可以容纳1023台机器同时发号;12bit的顺序号,每个相同的毫秒可以发出4095个不同的ID号。ID号中的10bit的工作实例ID可以通过分布式协调程序来实现自动分配(例如使用ZooKeeper、Consul等)。
附上使用Java一个参考实现:
package com.starlight36.service.showcase.sequence;
import com.starlight36.service.showcase.sequence.exception.InvalidStateException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.util.Date;
import java.util.concurrent.atomic.AtomicReference;
@Service
public class SnowflakeIdGenerator implements IdGenerator {
private class Sequence {
private final int value;
private final long timestamp;
Sequence(int value, long timestamp) {
this.value = value;
this.timestamp = timestamp;
}
int getValue() {
return value;
}
long getTimestamp() {
return timestamp;
}
long getId() {
return ((timestamp - TWEPOCH) << TIMESTAMP_SHIFT) | (instanceId << INSTANCE_ID_SHIFT) | value;
}
}
private final long TWEPOCH = 1483200000000L;
private final int INSTANCE_ID_BITS = 6;
private final int SEQUENCE_BITS = 10;
private final int INSTANCE_ID_SHIFT = SEQUENCE_BITS;
private final int TIMESTAMP_SHIFT = SEQUENCE_BITS + INSTANCE_ID_BITS;
private final int SEQUENCE_MASK = ~(-1 << SEQUENCE_BITS);
private final AtomicReference<Sequence> sequence = new AtomicReference<>();
private Integer instanceId;
@PostConstruct
public void init() {
// 写死了实例ID为0,可通过Consul来自动分配实例号
instanceId = 0;
}
@Override
public Long next() {
SequencecurrentSequence, nextSequence;
do {
currentSequence = sequence.get();
long currentTimestamp = currentTimestamp();
if (currentSequence == null || currentSequence.getTimestamp() < currentTimestamp) {
nextSequence = new Sequence(0, currentTimestamp);
} else if (currentSequence.getTimestamp() == currentTimestamp) {
int nextValue = (currentSequence.getValue()) + 1 & SEQUENCE_MASK;
if (nextValue == 0) {
currentTimestamp = waitForNextTimestamp();
}
nextSequence = new Sequence(nextValue, currentTimestamp);
} else {
throw new InvalidStateException(String.format(
"Clock is moving backwards. Rejecting requests for %d milliseconds.",
currentSequence.getTimestamp() - currentTimestamp));
}
} while(!sequence.compareAndSet(currentSequence, nextSequence));
return nextSequence.getId();
}
private long currentTimestamp() {
return new Date().getTime();
}
private long waitForNextTimestamp() {
while (currentTimestamp() <= sequence.get().getTimestamp()) {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
}
return currentTimestamp();
}
}
这里选取了6bit的实例ID号,可容纳31个实例同时发号,10bit的顺序号,每个毫秒可发号1023个ID。简单的计算一下就可以得出此发号器理论每秒可发出的最大ID数量,基本可以满足一般业务的需要了。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

