机器学习小白入门指引,开年也要规划好小目标
雷锋网 (公众号:雷锋网) 按:本文为Cookie Engineer写就,主要对机器学习进行了简单的介绍,雷锋网编译,未经许可不得转载。
经常有人问我如何开始学习机器学习,他们面临的最大困难就是机器学习背后的数学原理。我承认其实我也不喜欢数学。数学是对事物的一种抽象描述,用数学来描述机器学习,会过于抽象,且不容易理解。因此在这个系列的文章中,我尝试使用伪代码或者JavaScript来描述我所讲述的内容。
我在GitHub上创建了项目仓库,我会将一些实验代码同步到代码库中,以便您可以跟随我的步骤,或者在这些实验代码之上实现自己的东西。这些代码运行时可能会时不时报错,所以我称之为实验代码 J
你必须知道的第一个事情是同一个问题会有不同的解决方案。同一个问题可能会有3个解决方案,当你已经学会基本概念后,我会深入探讨更复杂的解决方案。我也试图将描述的内容尽量与语言无关、和框架无关。本文将介绍的第一个解决方案是遗传编程和进化算法。
0.神经网络的基础
神经网络不是很难理解。对新手来说比较难描述。因为每个人都在使用数学来解释神经网络,那我想在这里会用不同的方法来描述它。下面我们谈论一个简单的神经网络,它的结构包括三个不同的“类别”:输入层,隐藏层和输出层。
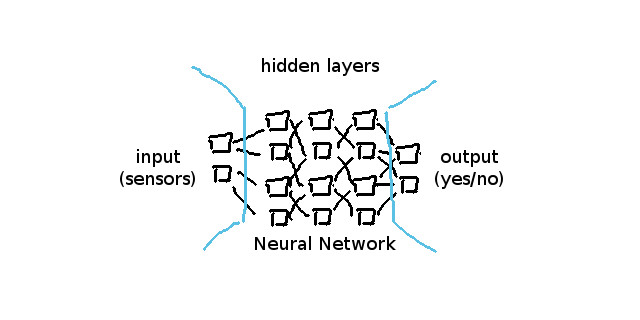
图1 神经网络基本架构
输入层通常代表传感器,其中输入数组的每个值的范围是从0.0到1.0。输出层代表对问题的解,取值可能为真假二值,也可能是位置矢量(例如游戏中,操作对象的x/y/z坐标值)。
神经网络可以用来拟合复杂函数,已经复杂的分类决策问题(达到Bayesian解决方案的限制,但以后会出现)。神经网络是无知的,他们只能理解从0.0到1.0的值,这意味着我们必须为其编写适配器,以便它能够理解它的含义,适配器在现实世界中通常称为“策略”,它除了将值转换为0和1之外,不会做其他事情。例如,当我们想要在乒乓球游戏中预测桨的移动位置时,我们可以使用这样的代码:
let input = [ 0, 0, 0 ]; // x,y,z
input[0] = entity.position.x / screen.width;
input[1] = entity.position.y / screen.height;
input[2] = 0; // we don't have a z position, have we?
let answer = neural_network.compute(input);
if (answer[0] > 0.5) {
entity.moveUpwards();
} else {
entity.moveDownwards();
}
现在我们知道一个神经网络可以计算输入,输出是/否离散结果,或者连续值。神经网络每层包含多个神经元。简单的前馈网络以每个神经元与前一层中的每个神经元(从左到右走)相连接的方式建立。
这些连接使用用来描述数据流的流向,每个连接线对应一个权重。这里的重要部分是输入神经元没有连接到上一层,因此compute( )函数必须对输入神经元做出反馈,根据输入数组的值直接获得结果。所谓的激活函数,是用来描述前后两层中,互相联系的神经元的转换关系。这里激活函数的概念有点模糊,因为每个人都有自己的见解。当然,你需要知道的是,它只是一个简单的函数,其响应形式如下:
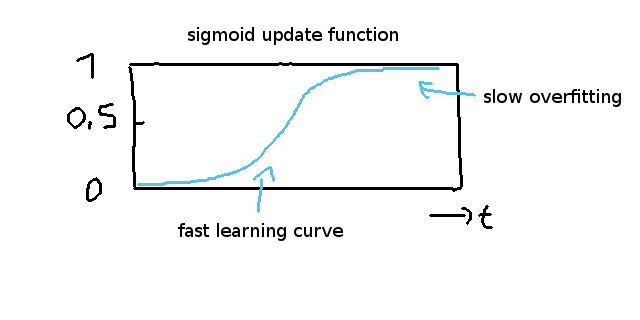
图2激活函数Sigmoid的响应
const _sigmoid = function(value) {
return (1 / (1 + Math.exp((-1 * value) / 1)));
};
总之,你只需要知道激活函数是模拟神经元如何工作的一种方法。激活函数在现实中只是取一个值并将其转换为另一个值。它的行为方式类似于动画世界中的每一帧之间的转换。
快速进步首先意味着神经元可以快速学习,缓慢步进意味着神经元过度拟合收敛更慢。过度拟合和讨论是一个更复杂的话题,但我直截了当地忽略它,以节省时间和混乱。
1.遗传编程和进化
遗传编程的核心思想是使用基因组的形式来表示网络结构。遗传编程的巨大优势是,当遗传编程与进化算法相结合时,它可以非常快地获得很好的网络结构。一个基本的进化算法总是包含三个不同的周期:训练、评价、繁殖,重复以上过程。
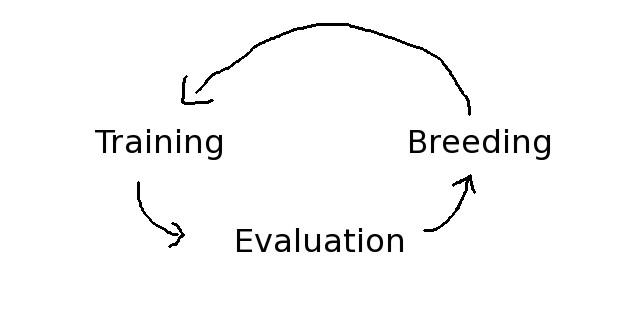
图3 进化算法过程
进化算法的执行过程如下:
STEP1 种群初始化:对种群的个体赋随机值,这样您就可以快速获得一个结果。当然,使用随机值来求最优解是有点漫无目的。
STEP2 适应度评价:适应度是评估循环过程中每个个体过程值,用来评估个体接近最优解的程度。例如,在超级马里奥游戏中,与左的距离、分数、杀敌数等可以用作适应度。
STEP3 个体选择,种群中适应度高的个体被选入交配池,获得与其他适应度高的个体交叉繁殖的机会,从而产生新的个体,加入子代种群。交叉算子的操作类似于人类繁殖的过程,父、母两条染色体相互交换基因片段,当然“儿子”个体会更像父亲,而“女儿”个体更像母亲。变异算子的主要作用是保持种群的多样性,防止种群陷入局部最优,所以其一般被设计为一种随机变换。
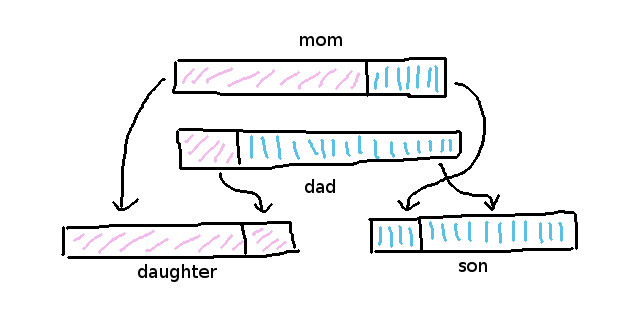
图4 个体交叉示意图
STEP4 判断是否达到最大迭代次数,若否,则跳至STEP2。
交叉算法通常在两个基因的截断点处进行交换,子个体各获得一部分,如女儿获得父母基因的比例分别为70% / 30%,儿子获得父母基因的比例分别是30% /70%。
let dna_split = (Math.random() * mum_genome.length) | 0;
let daughter = new Genome();
let son = new Genome();for (let d = 0; d < mum_genome.length; d < dl; d++) {
if (d > dna_split) {
son[d] = mum_genome[d];
daughter[d] = dad_genome[d];
} else {
daughter[d] = mum_genome[d];
son[d] = dad_genome[d];
}}
我们可以用1个基因的取值代表神经网络权重的值。这意味着神经网络的权重中的每个可能的取值可以看做是对等的基因个体。

图5用基因来表示神经网络中神经元的权重
进化算法的典型问题是,当在时间尺度上进行观察时,会出现即使迭代时间再长,求解的结果并不会改善太多,趋近于饱和状态。这主要是因为突变率太高,无法求得最优解。高变异率虽然可以让收敛速度更快,然而,迭代时间长了之后,高变异率可能会导致丢失全局最优解。
如果你想做一个简单的基于进化算法的人工智能演示,你可以用流行的浏览器打开下面的链接,是一个叫 Flappy Plane 演示程序。
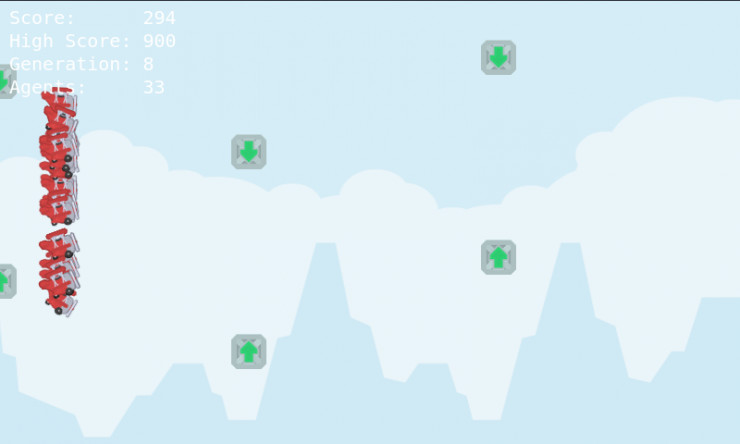
图6 Flappy Plane演示程序
正如你可能看到的,总会有一个时间点,进化算法会收敛,适应度趋于饱和,神经网络不会再进化到一个更完美的状态。没有反向传播法的话,单纯靠随机化序列是无法得到最优解的,除非有足够多的时间来迭代,可能至死我们也无法得到最优解。
NEAT(基于增强拓扑神经网络)和HyperNEAT解决这个问题的思路是通过迭代过程中,通过分析网络的表现和突变来改变网络。例如,每个基因组可以自我评估适应度,只有“更好”的基因组存活,而较差适应度的基因会被记下来,用于随机化。
2.NEAT
NEAT是一个利器,很难用一种简单的方式解释。如果你看过 SethBling的Mari/o演示 ,你可能已经知道了这个概念。我可以推荐现在观看这段视频,以便您能更好地理解我在下面的解释。
需要了解的基本概念是:NEAT是一个用来观察神经网络的性能和分析他们的行为的算法。如果行为分析认为该神经网络的表现更好,那么该基因被选择,进入交配池。如果表现不好的话,基因(或基因组)将被标记为失活。
NEAT更多应用用于ANNS(自适应神经网络),而不是典型的神经网络,因为ANNS能在外部信息的基础上改变内部结构。ANN的思路是白手起家,从0个神经元开始,让算法找到神经网络的完美结构,由于神经元的连接可以被随机去除和创建,所以通过观察网络表现,我们可以得知在哪里产生神经元,会加快便我们获得最优解的速度。

图7 自适应神经网络示意图
NEAT使用CPPN (组成模式生成网络) 作为行为评估模块,它基本上是一个(可能是加强的)神经网络,学习输入和神经网络性能的关系,它的优点是可以记住ANN的结构,在给定足够时间的条件下,总能找到解。
行为分析可以减少不必要的随机化结构,我们能更好地自动猜测未来“最可能的”值。
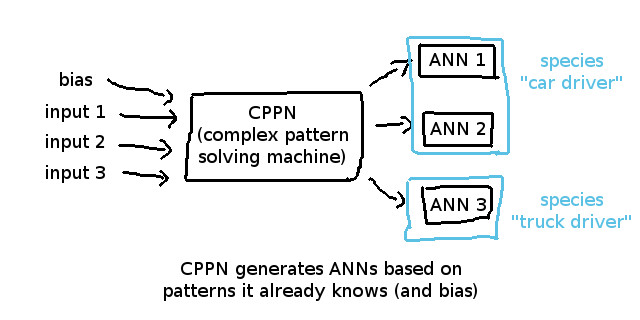
图8 CPPN分析神经网络/个体,并将行为类似的分为一类
在典型的NEAT场景中,交配池由代表网络结构的基因个体组成,它是一个多个体的概念。这些个体总是相互竞争,总是试图用“适者生存”的规则来选选择子代的个体,让他们的DNA能延续,成为神经网络权重。
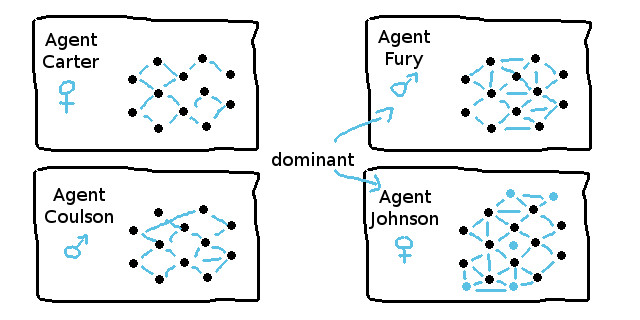
图9 多个体系统通过适应度排序代理,并确定优势个体
多个体系统中的优势个体是可以进入交配池,以填充下一个进化循环的种群。下一个循环的交配池通常包含以下三种类型:
1. 20%幸存者(最高适应度个体的交叉繁育得到的子代);
2. 20%突变体(在原个体基础上随机突变神经网络);
3. 60%子代个体(最高适应度的个体与其他个体的交配繁育得到的子代);
下一步
下一篇文章可能会介绍反向传播和增强学习,以及将这两种算法与进化算法进行比较。请记住:它们不是独立互斥的概念,进化算法是可以结合增强型神经网络一起使用。
via Machine Learning for Dummies: Part 1 ,雷锋网编译
雷锋网版权文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

