将MySQL去重操作优化到极致之三弹连发
将MySQL去重操作优化到极致之三弹连发(一):巧用索引与变量
http://blog.csdn.net/wzy0623/article/details/54377986
实验准备:
MySQL 5.6.14
-
create table t_source
-
(
-
item_id int,
-
created_time datetime,
-
modified_time datetime,
-
item_name varchar(20),
-
other varchar(20)
-
);
-
-
create table t_target like t_source;
-
-
delimiter //
-
create procedure sp_generate_data()
-
begin
-
set @i := 1;
-
-
while @i<=500000 do
-
set @created_time := date_add('2017-01-01',interval @i second);
-
set @modified_time := @created_time;
-
set @item_name := concat('a',@i);
-
insert into t_source
-
values (@i,@created_time,@modified_time,@item_name,'other');
-
set @i:=@i+1;
-
end while;
-
commit;
-
-
set @last_insert_id := 500000;
-
insert into t_source
-
select item_id + @last_insert_id,
-
created_time,
-
date_add(modified_time,interval @last_insert_id second),
-
item_name,
-
'other'
-
from t_source;
-
commit;
-
end
-
//
-
delimiter ;
-
-
call sp_generate_data();
-
-
insert into t_source
-
select * from t_source where item_id=1;
-
commit;
-
- select count(*),count(distinct created_time,item_name) from t_source;
-
truncate t_target;
-
insert into t_target
-
select distinct t1.* from t_source t1,
-
(select min(item_id) item_id,created_time,item_name from t_source t3 group by created_time,item_name) t2
-
where t1.item_id = t2.item_id;
- commit;
执行计划如下:
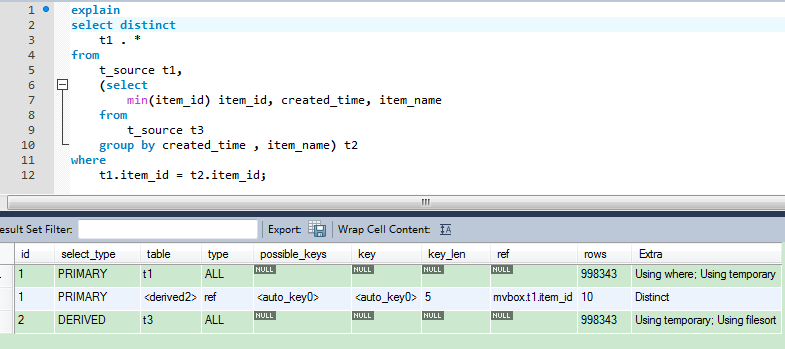
可以看到MySQL 给 t1表的item_id自动创建了一个索引.
2.使用MySQL特性
-
truncate t_target;
-
insert into t_target
-
select min(item_id),created_time,modified_time,item_name,other
-
from t_source
-
group by created_time,item_name;
- commit;
效率尚可,省时省力.
3.使用自定义变量
-
set @a:='0000-00-00 00:00:00';
-
set @b:=' ';
-
set @f:=0;
-
truncate t_target;
-
insert into t_target
-
select
-
item_id, created_time, modified_time, item_name, other
-
from
-
(
-
select
-
t0 . *,
-
if(@a = created_time and @b = item_name, @f:=0, @f:=1) f,
-
@a:=created_time,
-
@b:=item_name
-
from
-
(
-
select
-
*
-
from
-
t_source
-
order by created_time , item_name
-
) t0
-
) t1
-
where
-
f = 1;
- commit;
执行计划如下:

以上都是没有添加任何索引的情况.
添加索引如下:
create index idx_sort on t_source(created_time,item_name,item_id);
analyze table t_source;
创建索引之后,
使用表连接查询方式耗时11s,小幅提升.
使用MySQL特性的方式,耗时11-12s,反而更慢.
使用MySQL自定义变量的方式,耗时还是18s.
很显然,MySQL自定义变量的方式,其实没有利用索引.
最终改进SQL
-
set @a:='0000-00-00 00:00:00';
-
set @b:=' ';
-
truncate t_target;
-
insert into t_target
-
select * from t_source force index (idx_sort)
-
where (@a!=created_time or @b!=item_name) and (@a:=created_time) is not null and (@b:=item_name) is not null
-
order by created_time,item_name;
- commit;

耗时11s.
该语句具有以下特点。
(1)消除了嵌套子查询,只需要对t_source表进行一次全索引扫描,查询计划已达最优。
(2)无需distinct二次查重。
(3)变量判断与赋值只出现在where子句中。
(4)利用索引消除了filesort。
强制通过索引idx_sort查找数据行 -> 应用where筛选器 -> 处理select列表 -> 应用order by子句。
索引同时保证了created_time,item_name的顺序,避免了文件排序。force index (idx_sort)提示和order by子句缺一不可,索引idx_sort在这里可谓恰到好处、一举两得。
查询语句开始前,先给变量初始化为数据中不可能出现的值,然后进入where子句从左向右判断。先比较变量和字段的值,再将本行created_time和item_name的值赋给变量,按created_time,item_name的顺序逐行处理。item_name是字符串类型,(@b:=item_name)不是有效的布尔表达式,因此要写成(@b:=item_name) is not null。
“insert into t_target select * from t_source group by created_time,item_name;”的写法,它受“sql_mode='ONLY_FULL_GROUP_BY'”的限制。
运行耗时和原文有出入,可能是因为我的环境是SSD的缘故.
另外,避免回表的开销,可以增加索引的字段
drop index idx_sort on t_source;
create index idx_sort on t_source(created_time,item_name,item_id,modified_time,other);
analyze table t_source;
使用上述索引,终极改进的SQL 耗时可以降到 9.5s
参考:
http://blog.csdn.net/wzy0623/article/details/54378367
http://blog.csdn.net/wzy0623/article/details/54378575
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

