github热度最高的语言是什么,用wordcloud制作流程解析(上)
【51CTO.com快译】 本篇文章意在对 github 仓库里不同编程语言中的高频词进行可视化展现。
数据源自 2016 年年中至年末期间,约 300 万套开源 GitHub 库。其结果以文本词云的形式展示如下:
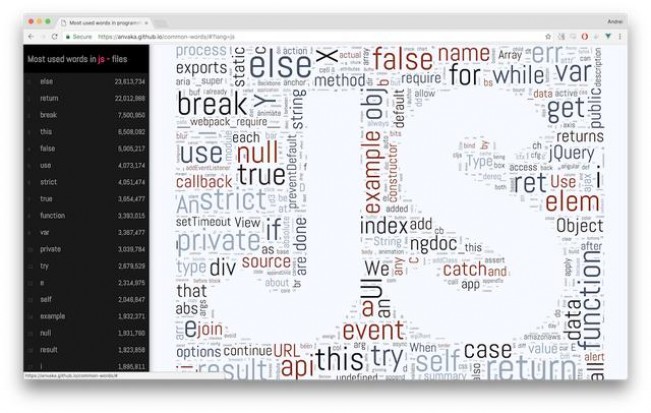
相关趣闻
- 这里保存了来自各套代码库中不同编程语言的对应常用词。 GitHub 的语言识别功能将这套库的大部分内容视为 C++ 。这样的结果不无道理,毕竟其中相当一部分语言的诞生是受到 C/C++ 的启发:

- 许可文本一般位于每种编程语言的注释当中。 在全部语言内, Java 代码以显著优势胜出,其在全部 966 个来自许可文本的词中占据 127 个 :

Java 的优势太过明显,因此对许可文本进行过滤。
- Lua 是惟一一款在前 1000 条常用词中 包含一个脏话的编程语言 ——感兴趣的朋友可以来找找看。
- 在 Go 语言中, err 的使用频率与 return 一样。
下面,将这些数据是如何产生的。
如何归纳 ?
利用 BigQuery 从 github_repos 数据集中提取单个词汇。每个词汇在提取时,都会伴随其出现时所在的前十行代码。
在保存各个词之前,使用以下几项限制条件:
- 此词汇出现的行应不超过 120 个字符。这能帮助我们过滤掉那些并非人为编写的代码,例如经过精简的 JavaScript 代码。
- 忽略掉了标点符号 (, ; : .) 、运算符 (+ - * ...) 与数字。因此如果该代内容为 a+b+42 ,那么过滤后的内容仅为: a 与 b 。
- 忽略掉了那些包含 “许可标记”的行——即那些出现在许可文本内的词汇(例如 license 、 noninfringement 等)。许可文本在代码中非常常见,虽然初看起来确实非常有趣,但通过归纳结果可以发现其内容数量太多,因此决定将其过滤掉。
- 对各词的大小写状态进行了区分: This 与 this 被视为两个独立的词。
数据是如何进行收集的?
在这部分内容中,我们将深入了解词汇提取方式。如果大家不感兴趣,也可直接跳转至词云算法部分。
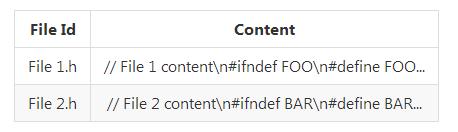
来自 GitHub 公共数据集内的数据由 BigQuery 负责索引 :github_repos
BigQuery 以明文形式在一套表中存储各索引文件的具体内容,相当于 key-value 的形式:
要建立这样一套词汇云,需要使用权重以进行词汇扩展。而要获取权重值,可以将各文本拆分为独立词汇(分词)

遗憾的是,这种简单的方法得出的结果并不理想 ——因为人们无法理解各个词出现的具体上下文。
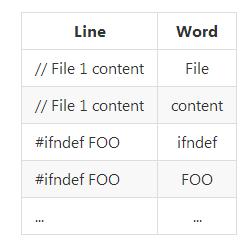
目标是希望能够避免这种问题,并保证人们能够查看各个词及其出现的实际语境:
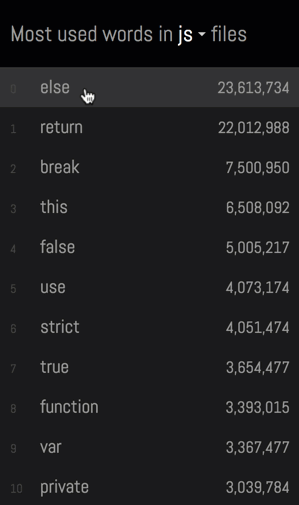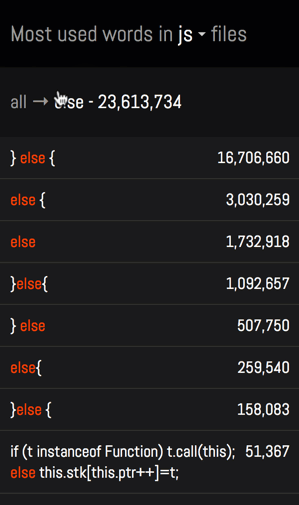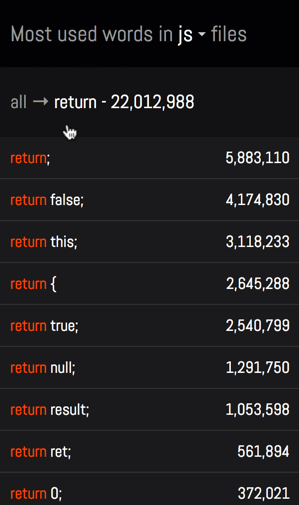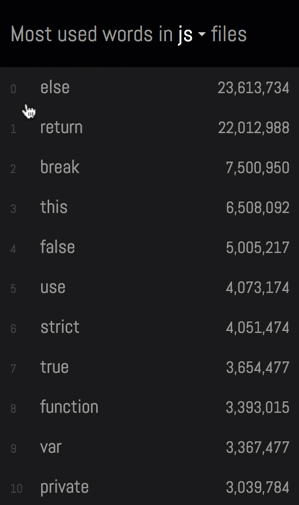
为了实现这一目标,创建了一套临时表,而非直接计算各行中词汇的出现次数:

这不仅让我得以将每个词汇与其 “上下文”配合起来,同时也将整体数据量由数 TB 缩减至约 12 GB 。
为了从这份表中获得出现频率最高的词汇,我们可以采用之前提到的方法,即将内容拆分成具体词汇,而后利用表对每个词进行分组。如果我们将原始行保留在中间表内,亦可获取各词汇的对应上下文:
通过这种中间表示方式,我们可以使用 SQL 窗口函数对各词汇进行分组,并获得各个词的前十行(更多细节信息,请参阅:为每个分类选定前十条记录,英文原文)。
现在大家可以在此查看提取到的代码: extract_words.sql 。
备注一 : 作者的 SQL 水平不高,所以如果大家其中的错误或者更理想的数据获取方式,请在评论中指出。另外,虽然目前的脚本能够正常起效,但其中某些结果可能略有偏差。
备注二 : BigQuery 的表现非常出色。其强大、灵活且速度极快。在这里,要向能够玩转它的朋友表达十二分的敬意。
如何进行词汇云渲染?
词汇云的核心部分,使用的其实是一条非常简单的算法:
for each word `w`: repeat: place word `w` at random point (x, y) until `w` does not intersect any other word
为了避免发生内部无限循环,可以尝试限定次数数量并 / 或去掉那些字体大小不符合要求的词汇。
从抽象的角度来讲,可以用矩形来表达这个问题:对于每个矩形,尝试将其放在画布上,直到其任何像素皆不与其它图形相交。
很明显,当画布被大量占用时,为新的矩形找到放置点将变得非常困难甚至完全不可能。
我们可以通过多种方法对已占用空间进行索引,从而加速此项算法:
- 使用区域求和表以快速通过 O(1) 次计算判断新矩形是否与其下矩形相交。这种方法的弊端在于,每一次画布进行更新时,整套表也需要进行一次更新,这会导致 O ( N2 )性能 ;
- 使用 R-Tree 来维护排序可以快速判断某一新的候选矩形是否与其下任何矩形相交。利用这种方法,像素相交查找速度要比区域求和表的效果更慢,但索引的维护速度则更快。
作者认为这两种方法都存在一种重要弊端,即很可能在找到适合新矩形的空间之前浪费大量尝试次数,这对于性能保障非常不利。
作者希望尝试一些不同的实现方式。建立一套索引,利用其快速选择一个足够大的矩形来匹配我新加入的矩形。这意味着为空余空间构建索引,而非对占用空间构建索引。
这里,选择了四叉树作为索引方案。其中每一个非旁枝节点都包含有可用于其下子枝的空余像素信息。从基础层面来讲,这就能够快速回答我们的问题: “是否还有足够的空间来容纳 M 个像素?”如果四叉树中的可用像素空间低于 M ,则不再需要进一步查询其子分枝。
至此,完成了具体算法的选择。在本系列文章的下一部分内容中,将一同来看其实际效果以及最终得到的不同编程语言中高频词汇的分析结论。
原文标题:Common Words
原文作者:anvaka
文章审核人:老曹 译者:核子可乐
老曹专栏文章链接: http://www.58pic.com/fuzhuang/15166791.html
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】
【责任编辑:张书情 TEL:(010)68476606】
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

