Advancing Research on Video Understanding with the YouTube-BoundingBoxes Dataset
Posted by Esteban Real, Vincent Vanhoucke, Jonathon Shlens, Google Brain team and
Stefano Mazzocchi, Google Research
One of the most challenging research areas in machine learning today is enabling computers to understand what a scene is about. For example, while humans know that a ball that disappears behind a wall only to reappear a moment later is very likely the same object, this is not at all obvious to an algorithm. Understanding this requires not only a global picture of what objects are contained in each frame of a video, but also where those objects are located within the frame and their locations over time . Just last year we published YouTube-8M , a dataset consisting of automatically labelled YouTube videos. And while this helps further progress in the field, it is only one piece to the puzzle.
Today, in order to facilitate progress in video understanding research, we are introducing YouTube-BoundingBoxes , a dataset consisting of 5 million bounding boxes spanning 23 object categories, densely labeling segments from 210,000 YouTube videos. To date, this is the largest manually annotated video dataset containing bounding boxes, which track objects in temporally contiguous frames. The dataset is designed to be large enough to train large-scale models, and be representative of videos captured in natural settings. Importantly, the human-labelled annotations contain objects as they appear in the real world with partial occlusions, motion blur and natural lighting.
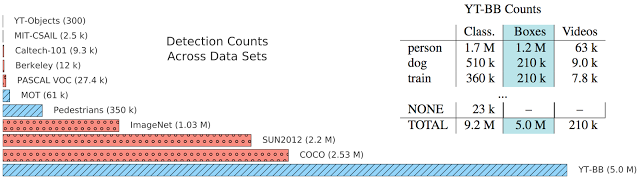 |
| Summary of dataset statistics. Bar Chart: Relative number of detections in existing image (red) and video (blue) data sets. The YouTube BoundingBoxes dataset (YT-BB) is at the bottom, is at the bottom. Table: The three columns are counts for: classification annotations, bounding boxes, and unique videos with bounding boxes. Full details on the dataset can be found in the preprint . |
A key feature of this dataset is that bounding box annotations are provided for entire video segments. These bounding box annotations may be used to train models that explicitly leverage this temporal information to identify , localize and track objects over time. In a video, individual annotated objects might become entirely occluded and later return in subsequent frames. These annotations of individual objects are sometimes not recognizable from individual frames, but can be understood and recognized in the context of the video if the objects are localized and tracked accurately.
 |
| Three video segments, sampled at 1 frame per second. The final frame of each example shows how it is visually challenging to recognize the bounded object, due to blur or occlusion (train example, blue arrow). However, temporally-related frames, where the object has been more clearly identified, can allow object classes to be inferred. Note how only visible parts are included in the box: the orange arrow in the bear example (middle row) points to the hidden head. The dog example illustrates tight bounding boxes that track the tail (orange arrows) and foot (blue arrows). The airplane example illustrates how partial objects are annotated (first frame) tracked across changes in perspective, occlusions and camera cuts. |
We hope that this dataset might ultimately aid the computer vision and machine learning community and lead to new methods for analyzing and understanding real world vision problems. You can learn more about the dataset in this associated preprint .
Acknowledgements
The work was greatly helped along by Xin Pan and Thomas Silva, as well as support and advice from Manfred Georg, Sami Abu-El-Haija, Susanna Ricco and George Toderici.
Source: Advancing Research on Video Understanding with the YouTube-BoundingBoxes Dataset
除非特别声明,此文章内容采用 知识共享署名 3.0 许可,代码示例采用 Apache 2.0 许可。更多细节请查看我们的 服务条款 。
Post Views: 0
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

