Face++旷视科技首席科学家孙剑首次接受专访:计算机视觉亟待解决哪些问题?
2015 年 12 月 10 日,在 ImageNet 计算机识别挑战赛中,由首席研究员孙剑带领的微软亚洲研究院视觉计算组,通过 152 层神经网络的应用,以绝对优势获得图像分类、物体定位以及物体检测全部三个主要项目的冠军。
半年前,孙剑博士离开微软研究院入 Face++ 旷视科技(以下简称 Face++)任首席科学家兼 Research 负责人,引发业内热议。孙剑博士于半月前撰写了《创业公司里的研究之美》,详细描述了 Face++ 的研究方向、展开研究的方式。在他看来,无论是使命定位、人员组成和研发方式,Face++ 的 Research 和 MSR 的研究没有本质差别,都是一群富有 Geek 精神的自我驱动者在探索前沿技术。
但仍有不少问题困扰我们。已经在图像领域耕耘十余年的他,为什么会选择创业公司?从大公司到创业公司,又有哪些变化?图像识别领域的下一个「大」问题是什么?152 层的神经网络的创想,究竟是怎样出现的?
为此,机器之心专访孙剑博士,从残差网络、ImageNet 测试、数据标注等多个角度展开了话题。内容整理如下,以飨读者。
关于152 层神经网络和残差学习
机器之心:在 2015 年在 ImageNet 测试中,您带领团队使用了 152 层神经网络,取得了三个主要项目的冠军。您和您的团队是如何想到这个方法,又是怎样去实现的?
孙剑:很多时候做研究,是在无数次的尝试中最后总结出的方法,同时把一个复杂的方法进行简化。做这个(残差网络),我们试了非常多的方法,有一些方法我们都没有公布。中间经历过很多,做了实验之后最后总结出(残差网络),发现它非常有效。
找到这个有效的方式后,我们分析它的原理,为什么能起作用。最后在论文中以残差学习的形式呈现,这是我们当时认为最好的一种解释。后来很多人尝试新的解释和改进,也有 A 解释、B 解释、C 解释,有些我们是认同的,有些我们不认同,其实蛮有意思的。
残差网络并不是说做到多少层,而是你也可以简单的做到这么多层,它核心使深层网络的优化变得容易。残差网络相当于将问题重新描述,但本质没变,以至于用现有的优化算法就很好解。以前不收敛,现在就能收敛了;以前收敛到很差的结果,现在就非常容易收敛到很好结果,所以它本质上是解决了优化问题。
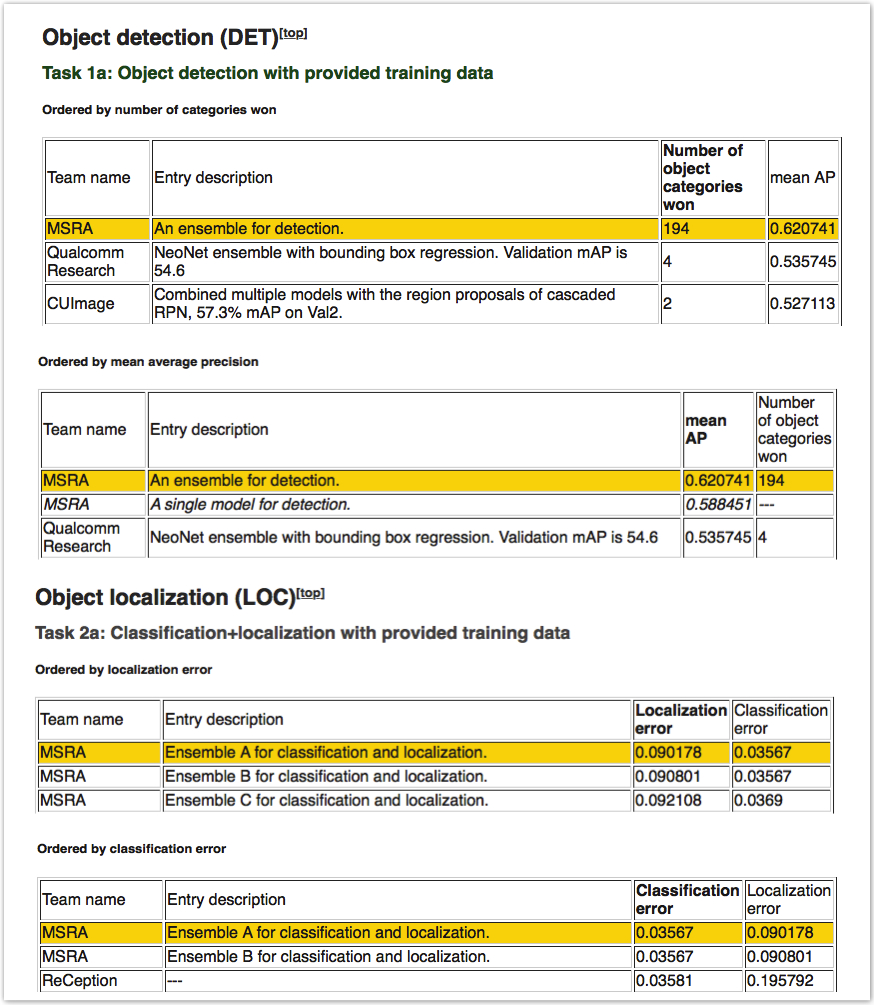
相关结果截图,来自 ImageNet 2015 测试(ILSVRC2015)网站
这个问题困扰了神经网络工作者非常长时间。为什么叫深度学习?深度就是网络层数,层数越多就越深,刚开始做 5 层就算深度。2012 年 Geoffrey Hinton 做了 8 层,他的论文专门写了一段证明 8 层比 5 层好,越深越好,因为还有很多人不相信这是有道理的。就算他们做得已经很好了,还有一些论文中说浅的网络也能做得一样好,「深」是不必要的。
在神经网络研究的历史中,很长时间内大家不相信那么深的网络能够优化出来。做深度学习之前大家研究 SVM(Support Vector Machine,支持向量机),研究稀疏表示,很大程度上是线性问题。大家试图研究凸的(问题),非凸的还想办法转成凸的做,对于这么深的网络、这么复杂的事情、高度非线性又有这么多参数,数据又很少,很多人都不相信能把它优化出来。今天能够相当程度地解决也包含很多因素。残差学习是其中一个重要因素,但不是唯一的。
把大家研究出来的结论放在一起,才导致今天任意给一个深度网络都能很容易地训练出来,深度再也不是网络不收敛训练不好的问题,破除了以前的魔咒。
最后要说一下做出这个残差网络完全是团队(何凯明、张祥雨、任少卿和我)的集体智慧结晶,缺少任何一人都不敢说能走得到这一步,中间经历很多的失败和曲折。我深感能把我们 4 个不同技能的人凑在一起,打下一个「大怪兽」的幸运;和他们在一起忘我的研究过程是我研究生涯中最难忘的经历之一。
机器之心:在图像识别之外,残差网络还可以运用到其它领域吗?
孙剑:最近语音识别、自然语言处理都在用。它是一种思想,并不是一个局限于图像识别的一个方法。这个思想用在别的地方都管用,我们看到了非常多的例子,大公司、小公司都在用。

论文《Deep Residual Learning for Image Recognition》中,在 ImageNet 上使用残差网络优化后的效果比对图表
而且最先进的系统、最复杂的系统都在用这个思想。并不是简单的用残差网络这个方式做,比如语言处理中的一个环节想要做做深,原来两层就不行,现在可以做得很深。用残差学习或跳层连接做得很深,效果很好,训练也很容易。并不是说以前不能搭这么深,搭这么深结果更差,现在有自由度想搭多深搭多深。
当然也不是说越深越好,跟问题和数据都有关系。考虑复杂度和效果肯定是找折衷点,不过现在不受深度的约束了。
机器之心:那您还会继续残差网络的研究吗?
孙剑:这是我们的一个中间结果。我觉得残差网络是一方面,但是我们做研究希望找下一个大想法,当然结构可能融合了残差网络方法,因为它这个很好的思想并不是具体的一个网络。
后来有很多人开发各种网络,结构都不一样,但残差网络的思想是其中必不可少的部分。现在所有网络都是残差网络,重点已经不是加残差网络了,而是说在以加了它为基础的情况下,再去研究别的特性,把这个问题再深刻理解,怎么能够做得更好。举个例子,分类能做得好,但这个网络未必适合于检测、分割这样的问题。只有把问题理解更深入,才能设计出最适合特定问题的网络。
关于 ImageNet 测试与数据
机器之心:ImageNet 已经诞生了很长时间,现在用它的测试结果判断一个图像识别模型好不好用还可行么?或者,我们应该如何去判断一个图像识别的模型是优秀的?
孙剑:ImageNet 今天仍有它的价值。做新问题新的标注数据很少,还离不开这个数据集。它很通用,上面 pre-train 的模型肯定不是最优的,但是在只有很少数据的时候起到了很大作用。另外 ImageNet 做得很好,它的训练和测试之间也是非常一致的。它是诞生研究方法、新的思想的平台,包括我们做人脸识别,都是通过 ImageNet 继承来的思想和做法。
当然遵循游戏规则得到了冠军固然可贺,但主要还是看是否有可以通用的新方法或思想。随着深度网络的快速发展,ImageNet 1K 这个数据目前已经很容易出现严重的过拟合了,期待下一代的 ImageNet 出现。我们最近也在考虑如何设计更好的 ImageNet。
机器之心:李飞飞后来也做了图像与语言结合的 Visual Genome,您认为在数据集方面还有哪些值得去做的事?
孙剑:Visual Genome 这个数据集非常好,李飞飞她们付出了非常大的努力,我们也在用这个数据集。数据集中不只有图像一个层次,图像里面的物体、物体之间的关系都标出来了,包括动作关系、位置关系都有。
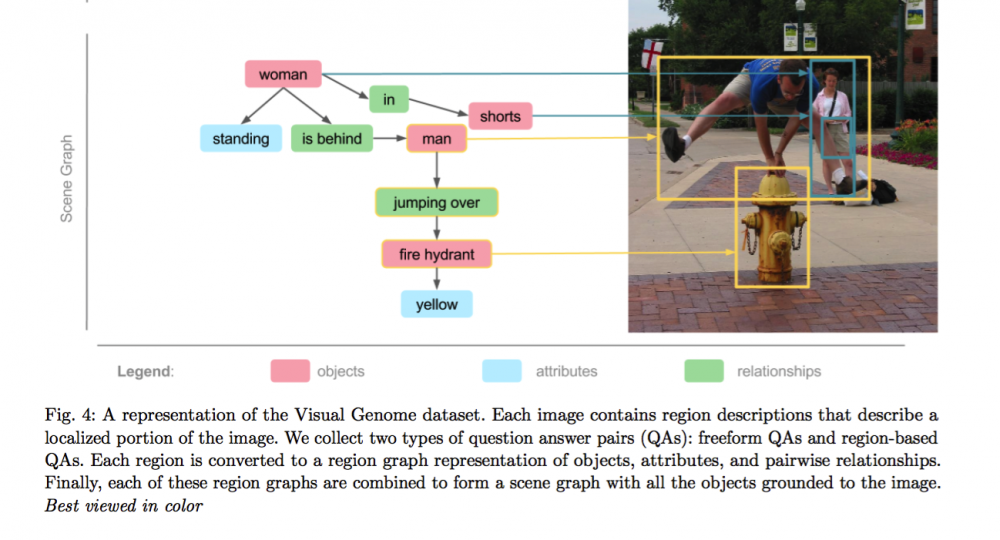
Visual Genome 的标注情况,详见其官网 Paper 部分
这些是研究认知问题必须要有的东西。比如房子上是没有马的,这件事情是常识。以前通过大量的数据统计学习可以做,送进来很多训练数据,确实数据里房子上没有马。但其实也隐含这件事,还没有表示出来,一旦你的算法出现了这种情况(房子上有马)就是已经做错了。但是如果能引入语言的话,他就会告诉你新的常识,房子上没有马。
换句话说,为什么 Visual Genome 清楚的描述照片很重要?比如你想教计算机认图片,你怎么教?教小孩图里面有什么、谁在干什么,语言可能是最自然的教计算机认图的方式。
希望这个库更大,也许再增加两个数量级就会产生下一个意想不到的突破。
机器之心:有更多维度的标注数据,会是解决图像识别问题的重要方向之一吗?
孙剑:现阶段可能是。有两个新的方向我们也在尝试,一个是制造合成数据,通过图形学的方法造出一些非常逼真的、和真正训练图像很像的图。用这个方法可以产生大量数据,而且有标注,可以得到很好的效果,能不能搞得真实还需图形学的同行们努力。另一种方法是,通过对抗学习或者叫对抗神经网络,可以从一堆样本中没有监督的自动生成生成新的样本。
标注方面有的标注是人工,有的标注网上已经有的,包括视频中前后两帧的相关性也是一种标注。我们训练人脸识别,只需要知道这几张照片是同一个人,另几张照片不是同一个人的。或者只需要知道这两张是同一人,那两张是同一人,这些标注都可以用来训练。
获取训练数据的方式是非常多的,数据训练也是非常重要的,我们也是最大努力获取最好的数据。对于旷视的研究员来说,获取数据是研究责任的一部分,想办法获取也好,造也好,拿到数据是工作职责之一。
关于计算机视觉的过去和未来
机器之心:您涉足图像领域已经有近二十年的时间,在您看来这个行业有什么样的特点?到今天有哪些可以称之为里程碑的事件?
孙剑:我至今还觉得我还是这个行业的新手,好多东西了解还是比较浅的,不敢妄自评判里程碑事件,这绝不是谦虚。当然深度学习是最近、最重要的事件,再之前可能是机器学习方法引入计算机视觉,改变了计算机视觉中很多问题的研究方式。在现在火热的深度学习之前,更多的是怎么用机器学习、统计学习来研究和思考视觉问题。
这不是某一个时间点突然发生的,而是一段时间内慢慢发生的。这对计算机视觉改变很大,以至于今天非常大比例的计算机视觉人员都是非常懂机器学习的人。
有一个里程碑是深度传感器的普及。2009 年,微软 Kinect 诞生是当时的一个大事件,因为终于可以很方便和低成本地获取 3D 信息 了。计算机视觉有两大问题,一个图像理解,一个三维重建。求解 3D 是梦想,原来需要拍两张或多张照片,费很大的劲儿来重建。今天有 sensor 直接可以测量 3D。它一下就开启了今天和未来的很多应用。
至于未来,我的导师沈向洋博士经常引用的一句话是:「The best way to predict the future is to create it.」
机器之心:接下来计算机识别或者说图像识别的发展,哪些问题是亟待解决的?
孙剑:我觉得挺难预测的。今天大家都在研究无监督学习,因为监督学习已经比较成熟了,但无监督学习不够好,这是非常大的问题。我在很多年前读过《On Intelligence》,最近又读了一遍,再次受到很多启发。无监督学习当然很重要,现在有很多人研究,但还没做到马上能解决问题,从一堆无标注的数据生成另一堆无标注的数据,很难说立刻能带来多大的实际价值。

《On Intelligence》,副标题为「How a New Understanding of the Brain will Lead to the Creation of Truly Intelligent Machines」
我现在看好两个研究方向,一个是深度神经网络,必须能记住东西。并非长短时的短期记忆,而是像小孩长大一样的长时间记住,有一个大的记忆库,把事物放进去还可以决定要不要拿掉,或者把它们关联在一起,都需要有记忆机制。现在大多数有监督学习都记在网络参数里,并没有显式的记忆。虽然已经有很多不错的研究了,但还没到实用,我觉得这会是一个非常大的突破。
还有一个方向是,如何完成连续的输入-输出。人之所以能处理这些视频、做好无监督学习,因为在实时处理各种视频,连续输入、连续输出。现在的问题是,大家不知道怎么准备这样的训练数据来教计算机。可以把视频输入进去,可你想教它什么呢?教它什么,教到什么颗粒度还不清楚。
送入连续的、动态的内容,少量的有标注(数据)、大量的没标注,因为不可能将所有的内容都标注。在学术领域中组织一个大的训练问题让大家研究,才能推动下一步的进展。因为现在数据的进出都在拟合一个单一的函数 F(x),深度学习完成得非常好。但当函数不是静态的输入-输出时,是不断变化的输入,该怎么做是非常大的挑战。
机器之心:有一种声音认为,我们现在的计算机视觉太专注于研究人脸识别这样的功能分支,这还是停留在识别(或者说是感知)层面,是否也应该去关注认知这个更加重要的目标?
孙剑:这是个误解,计算机视觉领域从来就没有太专注研究人脸这个问题,Face++也不是只研究人脸。我们主要做我们最关心的 4 个计算机视觉的核心问题(图像分类、物体检测、语义分割、和序列学习),还有核心网络训练问题、底层构架问题、深度学习平台问题等。
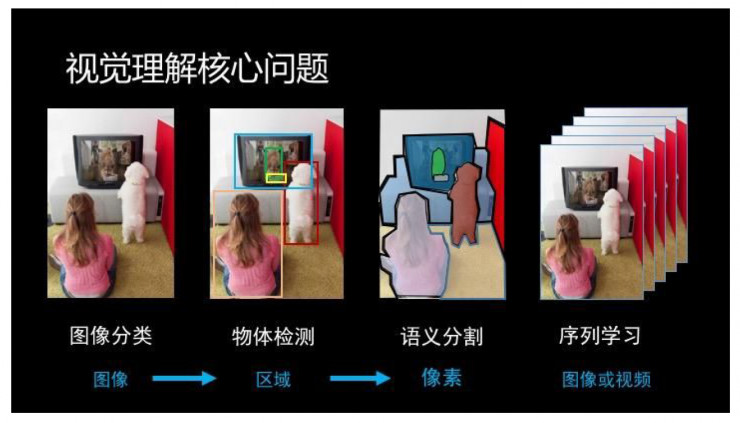
层面的东西当然也要研究,不然人工智能解不掉。最近的 Image Caption(看图说话)是一个非常好的研究课题,它把图像感知和这个语义理解串在一起了,而且它可以反过来帮助解决感知的问题。感知经常会出错,出的错又是很不合理的。不合理是因为没有常识,比如在房子上识别出马。常识其实在语言里面,要通过语言才能表示出来,人是通过语言、通过概念抽象来表示的。这个东西不研究清楚,就没法表示知识,没法表示房子上一般不可能有马这件事情。
机器之心:深度学习是图像识别最主流的一个方法,去年《Science》也发表了一篇关于通过贝叶斯程序学习识别手写体的文章。要让图像识别能够发展得更快更好,除了深度学习是不是也需要一些其他的方法或模型?
孙剑:深度学习是个广泛的概念,是端对端的,具体表现形式是深层神经网络。我觉得再发展下来,他可能就是一个无监督学习、增强学习内的部件,它和其他方法并不相互排斥。
深度学习狭义的讲是有监督的深度学习,或者有监督训练的神经网络。广义的讲它已经渗透在无监督学习和增强学习里面了,它是一个大的概念集合。
机器之心:最近图像识别比较火的方向是医疗,Hinton 认为不需要放射科医生了,因为图像处理技术已经足够成熟。在您看来医疗上的图像识别已经到这个程度了吗?或者接下来需要做什么?
孙剑:我觉得今天在整体还不成熟,个别问题有希望。医疗数据还是不够大规模而且不够开放,医疗数据经常是 3D 的,3D 既有优点也有缺点。另外医生做出判断也并不是只是看图像,还设计很多背景知识。从好的一方面讲,医疗影像识别相对一般的自然图像识别容易,因为自然图像中的事物特别多,涉及我们对常识的理解和对知识的表达;而医疗图像是相对比较限定的,它的歧义、困难都少很多。今天的问题可能是数据不够,研究的人不够多,数据平台不够开放,还有病人隐私问题。种种问题综合在一起,现在可能非常个别情况下是可以用,大多情况据我所知还需要研究。
关于首席科学家与 Face++旷视科技
机器之心:您为什么会在半年前加入 Face++?
孙剑:我就想试试,想有这段经历。接触计算机视觉已经 20 年了,最早在大三就接触了图像处理,后来在我大四末做的毕业设计「混沌神经网络的硬件实现」,当然那时候的神经网络是另一番模样。我也很早就研究过人脸识别,但是用的是上上一代的技术了。现在有了深度学习,真的让以前不能落地的一些事情能落地了。
其实在微软,我一直是同时注重研究方法和实际应用的风格,做了很多研究工作应用到公司产品上去了。我上大学期间我从教我自动控制的老师学习了这样一个理念:做好事情要即做神也做鬼,做神是说要把方法搞明白、作对了,做鬼是说要用实践来检验、来指导。
想加入创业公司是因为今天创业公司跟以前创业公司不一样了。你可以认为今天的创业公司就是大公司的一个部门,并且投入全部的人力、心力和财力,200% 聚焦在做一件事情。我想参与在这个非常专注的过程中。

旷视科技目前的主要产品
机器之心:Face++很早就有研究院这样的设置吗?
孙剑:Face++是技术公司,最早全是研究员,而且非常早的采用了深度学习的方法。所以可以认为一开始 Face++就是一个研究院,然后慢慢的有产品、商务、销售,然后慢慢就变成现在这样子。
因为深度学习,特别是计算机视觉,在纯研究性的工作之外有很多工程性的事情要做。它是实践性非常强的一门学科,必须动手做实验,动手处理数据、理解问题,所以我们研发不分家。做好的研究成果会以内部的算法库、SDK,交付给产品部门;产品部门在 SDK 基础上,再去开发他们的产品,然后产品再到销售。
机器之心:您接下来要主要研究的方向,或者说研究院要研究的方向是什么?
孙剑:就像之前说的,研究院的主要聚焦在 4 个核心研究课题上(图像分类、物体检测、语义分割、和序列学习),这和我在微软所做的完全一致,我们会继续推进在这些问题上的进展。新的方向我们也在探索,但还不是主线。
机器之心:那是产品引导我们的研究工作,还是研究工作相对独立,更贴近于前沿技术?
孙剑:现在所有公司的研究院已经没有没有纯粹的纯研究了,真正的纯研究只有在学校里才有。每个公司的研发部门,都有不同程度的目的折衷,所以不能说是完全独立做纯研究,或者完全为了产品开发。
机器之心:对于创业公司,更需要前沿研究的科研成果,还是工程化成果?
孙剑:我们都要,这不是贪心,而是最好的方式。我们付出很大精力和资源来研究和提升本质方法,本质方法的提升会传导到产品上去,比如精度更高了、速度更快了。这方面不能短视,必须短期、中期、长期(目标)都有。公司刚创立的时候其实没产品,做的都是研究相关的东西。研究本身也分两种研究,应用性研究和基础研究,非常基础的研究放之四海皆准,应用性研究要解决问题。
其实这是大家都懂的道理,但是知易行难,控制好度是关键。
机器之心:此前您的分享中提到 Face++将涉足机器人,能具体谈谈吗?
孙剑:现在我们做人脸识别、物体识别的硬件模组,和国内几家家庭服务型机器人都有合作。可以认为机器人的核心部件是眼睛、脑、手和脚:视觉是眼镜,手是机械臂,脚这个东西叫做 AGV+导航,当然还有更难的双足、多足机器人。
Face++已经在提供想机器人行业提供硬件模组,其中内置了我们的算法。下一步,我们非常有兴趣会研究它的身体部分、手的部分、腿的部分,做完整的机器人。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

