谷歌Lukasz Kaiser为你解读深度学习如何变革自然语言处理
2017 年 1 月 11 日,一个名为 2017 人工智能前沿大会(AI Frontiers Conference)的会议在加利福尼亚圣塔克拉拉举行。包括 Jeff Dean(谷歌大脑的负责人)、邓力(微软人工智能首席研究员)、Adam Coates(百度人工智能实验室负责人)、Alex Smola(亚马逊机器学习负责人)在内的 20 多位世界级业内人士和研究学者向 1500 余名参会者分享了人工智能最前沿的发展情况。
在本次会议中,谷歌大脑高级研究员 Lukasz Kaiser 就自然语言处理的发展现状及目前谷歌翻译的能力做了报告。

自然语言处理是什么?
自然语言处理近些年的变化归因于深度学习的发展。
自然语言处理(NLP)是一个非常大的概念。在本报告中,Lukasz 将其特指为文本到文本的任务(text to text task)。许多语言学家认为文本到文本任务是绝对属于符号工程(symbolic project)的领域,包括语法分析、翻译、语言建模等。
上述任务通常是由人类进行处理的,但神经网络能否为我们代劳?很多人不相信,直至神经网络真的做到了这一点。但神经网络是如何做到的?Lukasz 在接下来的幻灯片中给出了一些解释。
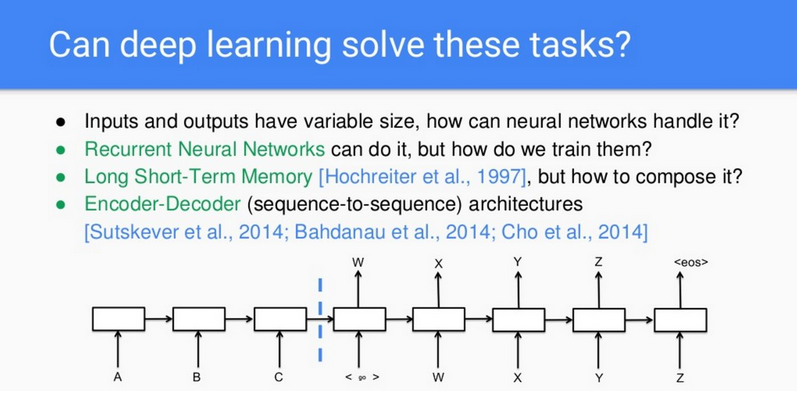 为使神经网络能理解一个句子,我们需要解决的问题到底是什么?
为使神经网络能理解一个句子,我们需要解决的问题到底是什么?
Lukasz 提到:「一开始出现神经网络的时候,它主要用来做图像识别,处理同一个维度上的像素信息。而语句和图像不一样。」[1] 不同的句子由不同数量的词组成,这意味着一个句子的输入维度是不规则的。如果想用神经网络来解析这种情况,循环神经网络(RNN)将会是自然之选。接下来就是训练该网络,如果需要用到的步骤太多,计算的负担将会非常重。那么接下来,我们就用到了长短期记忆(LSTM)。
先进的序列到序列 LSTM
LSTM 让我们能够训练这种循环神经网络。但在 1997 年,在 LSTM 应用的很早期,所能采用的规模很小,没有适合的硬件能处理这样的任务,这些缺点使得 LSTM 仅仅是一种理论突破。
但是,人们还不能利用这种方法来解决实际的问题。直到最近这几年(大概是 2014 年),编码器-解码器(encoder-decoder)架构 [3] 的出现使得 LSTM 变成了一种切实可行的方法,该方法不仅仅能构筑单层网络,而且能构筑很多层的网络。
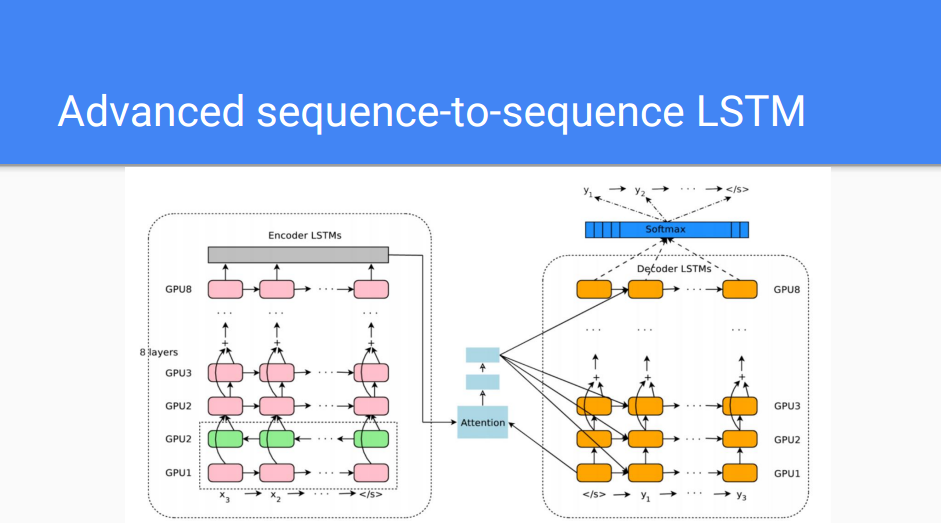
在构筑起这些层之后,通过更大的模型我们得到了更好的结果。
Lukasz 接下来给出了一个语法分析的例子。有了从学校学的知识,要读懂一个句子,我们可能会先识别其中的动词或名词,同时思考一下语法,就像幻灯片 5 中所示的语法分析树那样。而这是以前旧的标准做法,用这种做法去创建自然语言处理模型,去输入词汇含义、语法和句式结构,以使神经网络理解并生成句子。

有别于传统的做法,Lukasz 的研究团队仅仅是把语法树写成以他们所能想象到最最简单的方式所组成的序列里的一句话,这其中包含了括号和符号。
仅通过编写序列的方式来训练网络,而网络根本不知道什么语法树、或者括号、或者任何背景知识。这样做的问题在于缺少数据,因为所有的数据(序列)仅来源于研究人员的编写。相对于旧的训练方法,即输入语法,或者句子结构,新的训练方法似乎在提供背景知识方面更弱。但是,新的方法反而得到了更好的结果,因为网络可以自行学习所有这些知识。
LSTM 也适用于语言模型。语言模型的性能是以复杂度来度量的。更低的复杂度就意味着更好的性能。通过与过去所用模型的对比,复杂度的测量结果急剧地下降,这意味着获得了显著的改进。在 2016 年所达到的最好分数是 28(而 2013 年是 67.6),能达到这样的成绩在以前被认为是不可能的。决定因子是模型的大小。

Lukasz 也给了一些 LSTM 应用于语言建模和句子压缩方面的例子。
最让人印象深刻改进发生在将 LSTM 应用于翻译领域。正像 Lukasz 所描述的那样,在学校里,我们逐词地学习外国语言。但是如果我们不用这种方式来学,我们就是听人们用那种需要交流,看上去好像也可以。实际上,幼儿们学习就是采用这种方式,这实际上就是神经网络学习的方式。在这种情况下,训练数据的大小和数量是问题的关键。
翻译的性能由 BLEU 分数来衡量,分值越高性能越好。在过去的两年中,分值从 20.7 提升到了 26.0。Lukasz 的模型大小似乎是决定因素。
 在早些年(两年以前),经过训练的网络能够达到「人工系统」(也就是能逐个短语进行转化的短语系统)的水平,并且把它做的越来越大,但却始终达不到比较好的效果。通过比较 PBMT(一种旧的标准翻译模型)和 GNMT(采用了 LSTM 的新模型)的结果你会发现,同样是翻译一个德语句子,新模型的结果很明显更清晰更能让人理解。
在早些年(两年以前),经过训练的网络能够达到「人工系统」(也就是能逐个短语进行转化的短语系统)的水平,并且把它做的越来越大,但却始终达不到比较好的效果。通过比较 PBMT(一种旧的标准翻译模型)和 GNMT(采用了 LSTM 的新模型)的结果你会发现,同样是翻译一个德语句子,新模型的结果很明显更清晰更能让人理解。
这样的结果说明翻译过程不再是非要人工参与的工作,而可以变成仅仅需要一个大的神经网络和很多次训练而已。正如 Lukasz 所说,该理论对于许多自然语言处理任务都适用。
不过它究竟有多好呢?我们能考评它吗?我们请人对谷歌翻译最新发布的神经网络的翻译结果进行评价,评价的分值从 0 到 6,其中 0 分意味着翻译得无厘头,6 分意味着是完美的翻译。而且,为了对新旧系统进行比较,我们请人工的翻译(母语是该语言但不是专业的语言学家)也加入这场比赛,并且也让人们去评分。下一张幻灯片显示了这三种翻译系统的评分结果。
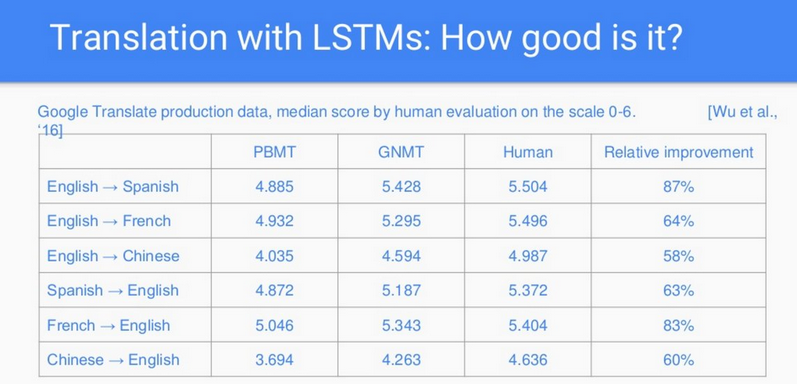
结果显示新的系统有了巨大的改进,而且在某些情况下(比如英语到西班牙语的翻译)几乎和人类的翻译者一样好。通过研究发现,更大的数据库能产生更好的结果。

LSTM 的局限
但是,序列到序列 LSTM 仍然有一些问题待解决。Lukasz 列出了其中的两个:
1. 速度的限制
这些模型都很大。鉴于对数据库大小的依赖,牵扯到相当大的计算量,在这种情况下,处理速度是个大问题。为了缩短处理时间,TPU 在帮助研究人员开展这种翻译的时候是一个很重要的硬件选择。
除此之外,翻译的过程太循序渐进了。即使计算的速度非常快,仍然要一个词一个词地来。即使是一个小任务,处理时间也很慢。为了解决这一问题,新的并行模型(Neural GPU, ByteNet)也许期望能帮助解决这个问题。
2. 需要很多数据
序列到序列 LSTM 需要很多数据。为了解决这个问题,提出了基于注意力和其他能增加数据效率的新架构。其他一些方法可以被用于进行规则化,比如 dropout、信任惩罚(confidence penalty)以及层标准化。
总结
深度学习极大地改变了自然语言处理领域。序列到序列的 LSTM 在很多自然语言处理任务上取得了业界最好的成绩。Google 翻译将 LSTM 用于产品中,获得了翻译质量的巨大提高。但是,新的模型也带来了一些 LSTM 的问题,特别是在速度与对大量数据的依赖上。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

