谷歌刚发布的深度学习动态计算图工具TensorFlow Fold是什么?
2 月 7 日,谷歌通过博客正式发布了 TensorFlow Fold,该库针对 TensorFlow 1.0 框架量身打造,可以帮助深度学习开发者根据不同结构的输入数据建立动态的计算图(Dynamic Computation Graphs),简化了模型训练阶段对输入数据的预处理过程,提升了系统的运行效率。
一般而言,大部分的深度学习项目都需要对模型的训练数据进行一定程度的预处理。在这个过程中,各种不同规模和结构的输入数据(例如不同分辨率的图片数据)将被裁剪成相同的维度和尺寸,然后被压入栈,等待模型训练阶段的批处理流程。这一步骤之所以至关重要,是因为它使得 TensorFlow 等高性能的深度学习框架可以并行地针对不同的输入数据运行同一个计算图,加上当前的 GPU 和多核 CPU 普遍支持的 SIMD(Single Instruction Multiple Data,单指令多数据流) 等加速技术,大大提升了深度学习模型的运算速度。
然而,依然存在诸多问题域无法进行一般的预处理,因此模型必须针对不同的输入数据建立不同的计算图。例如自然语言理解中的解析树(parse trees),源代码中的抽象语法树(abstract syntax trees)以及网页中的 DOM 树等等。在这些问题中,不同的输入数据具有不同的计算图,而且这些计算图并不能划分到同一个批处理流程中,因而也就无法实现对处理器、内存和高速缓存的最高效利用。
谷歌此次发布的 TensorFlow Fold 完美解决了这一问题。按照谷歌官方博客的介绍,TensorFlow Fold 库会根据每个不同的输入数据建立单独的计算图,因为各个输入数据都可能具有各自不同的规模和结构,因此计算图也应该各不相同。此后,动态批处理功能将自动组合这些计算图,以实现在输入数据内部和不同输入数据之间的批处理操作,同时还可以通过插入一些附加指令来实现不同批处理操作之间的数据互通。更重要的是,相比于其他实现,TensorFlow Fold 将 CPU 的速度提高了 10 倍以上,GPU 的速度提高了 100 倍。
更全面的原理介绍详见《DEEP LEARNING WITH DYNAMIC COMPUTATION GRAPHS》,论文链接如下: https://openreview.net/pdf?id=ryrGawqex
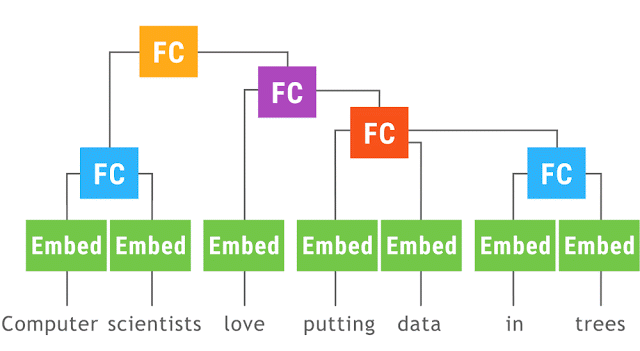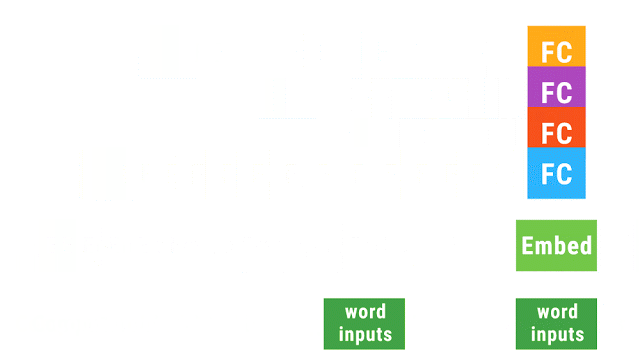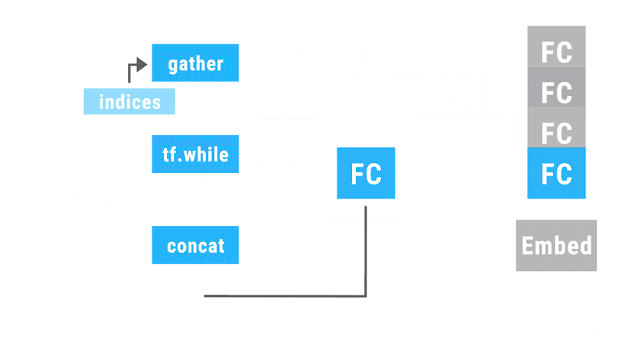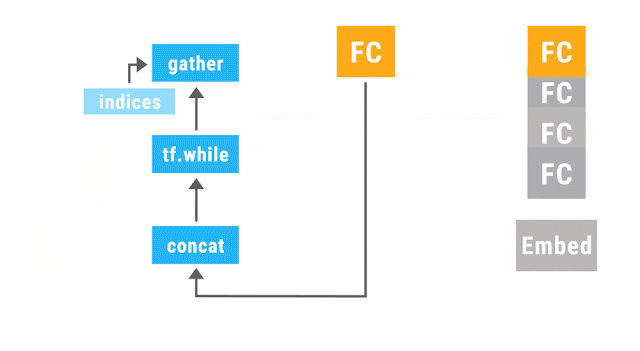
上图的动画展示了一个利用动态批处理运行的递归神经网络。相同颜色的操作被划分到同一次批处理中,这使得 TensorFlow 能够更高效地运行。其中Embed操作负责将单词转换为向量表示,FC(完全连接,Fully Connected)操作负责将单词向量组合为短语的向量。该网络最后的输出是一个完整句子的向量表示。虽然这里只展示了一个针对单一语句的解析树,但实际上该网络可以在任意形状和大小的多个解析树上并行地进行动态批处理。
目前,谷歌已经在 Github 平台开源了 TensorFlow Fold 库的源代码。 需要注意的是,目前 TensorFlow Fold 只在 Linux 平台进行了测试,而且由于API接口的变化,TensorFlow Fold 目前也只适配了 TensorFlow 1.0 。另外,TensorFlow Fold 兼容 Python 2.7 和 3.3+ 版本。详细的安装和文档说明请见 Github 页面: https://github.com/tensorflow/fold
来源: googleblog ,雷锋网编译 雷锋网 (公众号:雷锋网) 雷锋网
雷锋网版权文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

