谁能驾驭马赛克?微软AI打码手艺 VS 谷歌AI解码绝活儿

雷锋网 (公众号:雷锋网) 按:上个月底,微软研究院推出一套基于AI 技术的视频人脸模糊解决方案,通俗讲就是为人脸自动打码。而在今日,谷歌发布了模糊图片转高清图片的解决方案,说白了就是去除马赛克的技术。
你说谷歌,人家微软刚整出一套自动打码手艺,你就来个自动解码绝活,还能不能一起愉快的玩耍。
不少人有个疑问,那么谷歌是否能解除微软打的马赛克,上演一番科技版“用我的矛戳你的洞”?我们先来看下双方的技术原理是怎么样。
微软自动打码手艺
根据微软亚洲研究院副研究员谢文轩介绍,操作这套解决方案,用户只需在后台用鼠标选择想要打码的人物,相应人物在视频中的所有露脸区域都将被打上马赛克。
大致流程如下:
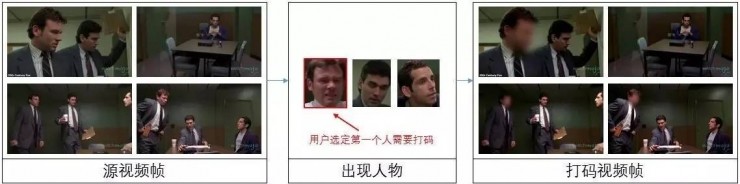
技术解决方案背后的逻辑是先找出视频中全部人脸所在的位置,第二步是把同一个人的所有人脸连接起来。
这背后涉及到人脸检测、追踪和识别。
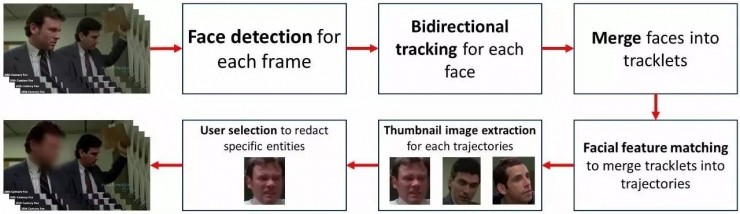
1.人脸检测
人脸检测的作用是定位人脸出现的位置。为了保证人脸尽量不被漏掉,微软采用了一套基于深度网络的、具有高召回率的人脸检测器。该检测器对视频的每一帧都进行检测,记录每个人脸对应的矩形框位置。
2.人脸追踪
在某一帧中给出一个人脸框,在其前几帧和后几帧都找到与之最相似的框。人脸跟踪的作用体现在这两大方面:一是连接相邻帧的检测框,因为人脸检测只负责每一帧的人脸定位,不负责帧间的连接;二是将当前帧的人脸检测框延续到前后几帧,这样即可定位到那些检测不到的侧脸。
3. 人脸识别
当然,该方案仅仅靠人脸检测与追踪还是不够的。假设一个场景,如果视频中存在镜头切换以及人物遮挡等问题,就需要利用人脸识别。微软训练了一套基于深度网络的人脸识别模型,对于不同镜头里的两张人脸,根据相似度对它们进行连接。最后系统将整个视频中不同人物的人脸都各自连接起来,提供给用户进行挑选。
时间复杂度方面,系统在Azure 的 CPU 服务器上能够实时处理 720p 的视频,并且能够以 2 倍时长处理 1080p 的高清视频。
在讲谷歌的自动解除马赛克绝活前,我们先来了解下马赛克还原问题。
马赛克还原之殇
通常来讲,马赛克是不可逆损失信息的,很难还原。
为何难以还原?
打码是一个减少信息量的过程,这些减少的信息已经丢失。马赛克处理相当于对图像信号的进行比原始数据更低频率的采样。根据奈奎斯特采样定理,如果这个采样频率比原始数据的频率的 2 倍还要低,那么必然产生不可逆的数据损失。大部分情况下,“马赛克”处理都会产生不可逆的数据损失。
打马赛克的方式有多种,最常见的就是取平均。我们可以把一张图片想象成一个方格矩阵,里面不同的数值(RGB、CMYK数值)表示不同的颜色。打马赛克的本质就是把那个区域的数字都取周围数字的平均数。
举个简单的例子,一张 16 个像素的图像,用一个很简单的算法打码,每四个像素取左上角的像素的值。
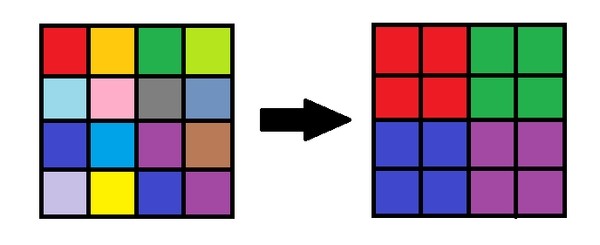
广义的马赛克可为两大类:大块马赛克模糊和小块马赛克模糊。
大块马赛克模糊往往更难处理。

而小块马赛克模糊相比而言容易一些。


为何小块的马赛克容易还原?
马赛克是一个抽样信号,抽样信号能否还原取决于采样间距,也就是每个色块的大小。如果采样间距不是很大的话,将抽样信号通过一个低通滤波器是可以基本还原原始信号的。上面黑白照片上的马赛克色块大小基本上都超过了允许采样间距。这种信号通过低通滤波器的话会导致高频信号失真,也就是图片的细节。
近视眼可以看做是一种低通滤波器,你可以试着摘下眼镜看看上述黑白照片的马赛克酒壶,比戴眼镜更能看出轮廓。所以我们在远看马赛克的时候反而能看出轮廓,近了就什么都看不出了。
还原马赛克的方式
在面对模糊不是特别严重的情况下,传统的方式可以用插值进行还原。插值通俗讲就是把原来一个像素的地方用多个像素代替。
插值算法在 MATLAB 图像处理工具箱中提供了四种插值的方法:插值最接近原则插值、双线性插值、双三次插值、不规则碎片形插值。
下面的例子是一幅 106*40 的图像放大成 450% 的效果:
最接近原则插值
最接近原则插值是最简单的插值方法,它的本质就是放大象素。
新图像的像素颜色是原图像中与创造的象素位置最接近象素的颜色。如果把原图像放大200%,1个象素就会被放大成(2*2)4个与原象素颜色相同的象素。多数的图像浏览和编辑软件都会使用这种插值方法放大数码图像,因为这不会改变原图像的颜色信息,并且不会产生防锯齿效果。同理,在实际放大照片中这种方法并不合适,因为这种插值会增加图像的可见锯齿。
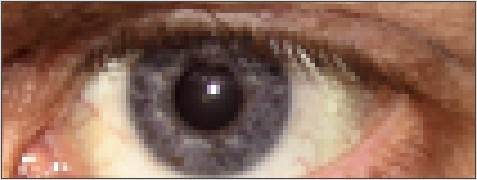
双线性插值
在双线性插值中,新创造的象素值,是由原图像位置在它附近的(2 x -2)4个邻近象素的值通过加权平均计算得出的。这种平均算法具有放锯齿效果,创造出来的图像拥有平滑的边缘,锯齿难以察觉。
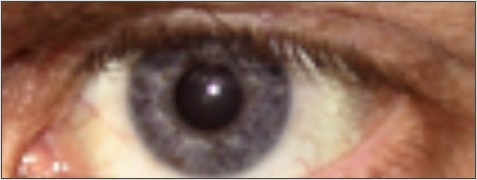
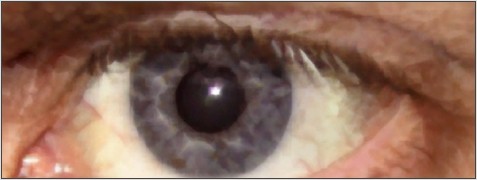
双三次插值
双三次插值是一种更加复杂的插值方式,它能创造出比双线性插值更平滑的图像边缘。从下图中的眼睫毛部分,在这个地方,软件通过双三次插值创造了一个象素,而这个象素的象素值是由它附近的(4 x 4)个邻近象素值推算出来的,因此精确度较高。
双三次插值分类:
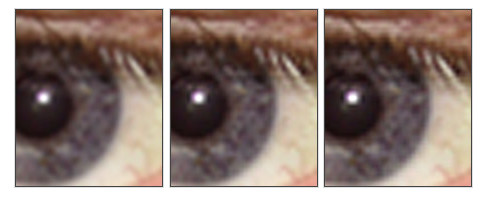
(1)双三次插值平滑化 (2)普通双三次插值 (3)双三次插值锐化
不规则碎片形插值
不规则碎片形插值通常被应用于图像的放大倍率很大的情况(例如制作大幅印刷品)。它能够让放大后的图像无论从形状、边缘、颜色都较接近原图像,而且减少照片的模糊程度,效果比双三次插值法还要好。读者可以把下图于上面的图片比较,就能知道不规则碎片形插值法的优势:
如果图像中的某一区域被严重打码,则可通过下述方式进行还原:
假设原始图像中,同一纹理会出现多次。模糊部分就用图像中清晰的部分来填补,或者将多个模糊的同一种纹理进行比较,构造出一个清晰的纹理来替代它们。也就是说,图像满足一定条件,可以从临近的其他部位补全,类似 PS 中的仿制图章工具。
举个例子,图片中有几只斑点狗,但其中一只斑点狗被打码了,于是去马赛克算法寻找这个图像中“最能匹配这个马赛克的”其它斑点狗的局部图像,然后用这个局部图像来填补那个马赛克。
与此同时,也可在一个图库中寻找并组合出最能匹配马赛克的图案。
去年九月份,德克萨斯大学的研究者研发了“反马赛克”技术。研究人员在 Torch 上一些网络素材进行训练和测试 ,结果显示图片能够达到极高的准确度。它的原理就是利用算法找到和图片相符、相似的原始图像。

而谷歌这次推出的最新去除马赛克技术解决方案的原理也是与德克萨斯大学的研究成果相似。
谷歌解除马赛克的绝活儿
今日 Google Brain 在提升图片分辨率方面取得了突破性进展。他们已经成功将 8×8(毫米)网格的像素马赛克转换成为肉眼可辨识的人物图像。

随着深度学习的发展和图像数据的剧增,提升低分辨率照片细节的最佳突破口就是神经网路,当我们被照片中所包含的像素信息难倒的时候,深度学习能通过“联想”的方式增加细节。实质就是软件基于从其他图片中学习到的信息对图片进行猜测。
Google Brain 的研究团队已经公布了Pixel Recursive Super Resolution 技术的最新进展,尽管结果看上去并不完美,但是整体还是非常可观的。
下面是他们复原的效果案例之一:

右手边的图片,是 32 x 32 网格的真实人物头像。左手边的图片,是已经压缩到 8 x 8 网格的相同头像,而中间的照片,是 GoogleBrain 基于低分辨率样片猜测的原图。
整个复原过程使用了两种神经网络。首先介绍的是 Conditioning Network,将低分辨率照片和数据库中的高分辨率照片进行对比。这个过程中迅速降低数据库照片中的分辨率,并根据像素颜色匹配一堆同类照片。
接下来介绍的是 Prior Network,它会猜测哪些细节可以作为高分辨率照片的特征。利用 PixelCNN 架构,该网络会筛查该尺寸的同类照片,并根据概率优先对高分辨率照片进行填充。例如,在论文提供的例子中,提供的同类照片是名人和卧室,Prior Network 根据优先级最终确认了名人的照片。Prior Network 会在低分辨率和高分辨率照片中做出决定,如果发现鼻子的可能性比较大,就会选择鼻子。
为了制作出最终的无码高清图片,需要融合这两个神经网络输出的数据,最终结果往往会包含一些似是而非的新细节。

下面也是一些通过超像素技术变化的样本:

这项高清还原技术已经在实际测试中取得了一定的成功。该团队向人类观察员呈现真实的高清明星照和经过电脑还原的照片时,观察员被骗的比例达到10%。而在卧室照片中,人类观察员被骗的比例达到 28%。这两个得分都远高于常规的插值技术,后者没有骗过任何人类观察员。
虽然谷歌这次把去马赛克技术提高了一个水平,但依旧无法达到“还原”的水准,更多属于预测,因此谷歌与微软之间也不存在“用我的矛戳你的洞”这个问题。 雷锋网雷锋网
雷锋网原创文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

