禁用Python的GC机制后,Instagram性能提升10%
通过关闭Python垃圾回收(Garbage Collection,GC)机制(通过回收和释放未使用的数据来回收内存),Instagram的性能可以提高10%。是的,你没有听错!通过禁用GC,我们可以减少内存占用并提高CPU LLC缓存命中率。如果你想知道为什么,那么就来阅读Chenyang Wu和Min Ni为此撰写的 文章 。
作者Chenyang Wu是Instagram的软件工程师,Min Ni是Instagram的技术经理。
我们如何管理Web服务器
Instagram的web服务器以多进程的模式运行在Django上,主进程分叉创建几十个工作进程,用来接收传入的用户请求。对于应用程序服务器,我们使用带前置模式的uWSGI来利用主进程和工作进程之间的内存共享。
为了防止Django服务器运行到OOM,uWSGI主进程提供了一种机制,当其RSS内存超过阈值时重新启动工作进程。
了解内存
我们开始研究工作RSS内存为什么在由主进程产生后迅速增长。一个观察是,即使RSS存储器以250MB开始,其共享内存下降非常快:在几秒钟内从250MB降到约140MB(共享内存的大小可以从 /proc/PID/smaps 读取)。这里的数字是无趣的,因为它们一直在变动,但共享内存丢弃的规模很有趣:大约1/3的总内存。接下来,我们想要了解为什么共享内存在工作器产生伊始就变为每个进程的私有内存。
我们的理论:读时复制
Linux内核有一个称为写入复制(Copy-on-Write,CoW)的机制,用作分叉进程的优化。子进程通过与其父进程共享每个内存页开始。仅当页面被写入时复制到子内存空间的页面(有关详细信息,请参阅维基百科上的Copy_on_Write 词条 )。
但在Python中,由于引用了计数,事情变得有趣了。每次我们读取一个Python对象时,解释器将增加其引用计数,这本质上是对其底层数据结构的写入。这就导致了CoW。因此,使用Python,我们就进行读时复制(Copy-on-Read,CoR)!
#define PyObject_HEAD /
_PyObject_HEAD_EXTRA /
Py_ssize_t ob_refcnt; /
struct _typeobject *ob_type;
...
typedef struct _object {
PyObject_HEAD
} PyObject;
那么问题是:我们是在写时复制不可变对象(如代码对象)么?给定 PyCodeObject 确实是 PyObject 的“子类”,那么答案显然为:是。我们的第一个想法,是禁用对 PyCodeObject 的引用计数。
尝试1:禁用代码对象的引用计数
在Instagram,我们先做简单的事情。考虑到这是一个实验,我们对CPython解释器做了一些小的修改,验证了引用计数对代码对象没有改变,然后将CPython应用到我们的一个生产服务器。
结果令人失望,因为共享内存没有变化。当我们试图找出原因时,我们意识到没有任何可靠的指标来证明分析是否正确,也不能证明共享内存和代码对象的副本之间的关系。显然,这里缺少一些什么东西。由此获得的经验是:在运作之前证明你的理论。
分析页面故障
当我们在Google上搜索关于Copy-on-Write的资料后,了解到Copy-on-Write与系统中的页面错误是相关联的。每个CoW在过程中触发页面错误。Linux附带的Perf工具允许记录硬件/软件系统事件,包括页面错误,甚至可以提供堆栈跟踪!
于是我们运行了一个prod服务器,重启服务器后,等待它进行分叉,得到了一个工作进程的PID,然后运行以下命令:
perf record -e page-faults -g -p <PID>
我们就有了一个新的想法,看看当页面错误如果发生在堆栈跟踪的过程中会发生什么。
(点击放大图像)
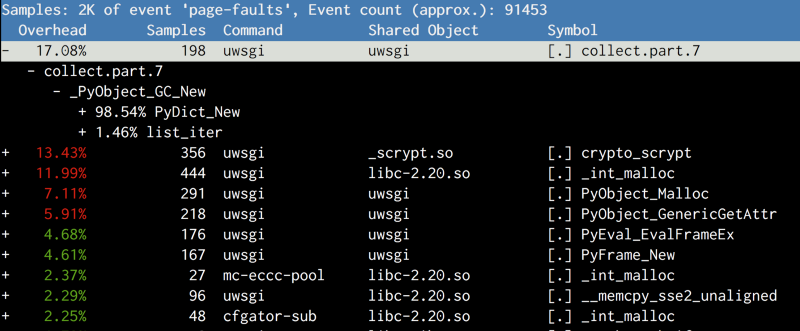
结果出乎意料,并没有复制代码对象,最大的疑凶是 collect ,它属于 gcmodule.c ,并在触发垃圾回收时被调用。在阅读了GC在CPython中的工作原理后,我们得出了以下理论:
基于阈值确定性地触发CPython的GC。默认阈值非常低,因此它在很早的阶段就开始了。它维护对象的分代链接列表,并且在GC期间,链接列表被洗牌。因为链接列表结构与对象本身一起存在(就像 ob_refcount ),在链接列表中改写这些对象将导致页面被CoW,这是一个不幸的副作用。
/* GC information is stored BEFORE the object structure. */
typedef union _gc_head {
struct {
union _gc_head *gc_next;/
union _gc_head *gc_prev;
Py_ssize_t gc_refs;
} gc;
long double dummy; /* force worst-case alignment */
} PyGC_Head;
尝试2:尝试禁用GC
既然是GC捅了我们一刀,那就禁用它!
我们引导脚本添加了一个 gc.disable() 调用,然后重启了服务器。我们重新启动了服务器,但是,很不幸!如果我们再次查看perf,将会看到 gc.collect 仍然被调用,并且内存仍然被复制。利用GDB的一些调试,我们发现,使用的一个第三方库(msgpack)调用 gc.enable() 将其恢复,因此gc.disable()在引导时被清除。
修补msgpack是我们要做的最后一件事,因为它意味着我们没有注意到其他库在未来也会做同样的事情。首先,我们需要证实禁用GS实际上是很有帮助的。答案存在于 gcmodule.c 中。作为 gc.disable 的替代,我们做了 gc.set_threshold(0) ,这一次,没有任何库被恢复过来。
这样,我们成功地将每个工作进程的共享内存从140MB提高到225MB,并且每台机器在主机上的总内存使用量减少了8GB。这就为整个Django集群节约了25%的内存。有了这么大的头部空间,,我们能够运行更多的进程或运行带有更高的RSS内存阈值。实际上,这样的改进将Django层的吞吐量提高了10%以上。
尝试3:需要完全禁止GC
在我们尝试了一堆设置之后,我们决定在更大的范围内尝试:集群。反馈相当快,因为禁用GC后,重启Web服务器变得很慢,以至于我们的连续部署被中断了。通常重启耗时不到10秒钟,但禁用GC后,有时候,耗时会超过60秒。
2016-05-02_21:46:05.57499 WSGI app 0 (mountpoint='') ready in 115 seconds on interpreter 0x92f480 pid: 4024654 (default app)
重现这个bug非常伤脑筋,因为它不是确定性的。经过大量实验后,一个真正的re-top在顶部显示了。当发生这种情况时,主机上的可用内存骤降到接近零并跳回,强迫所有的高速缓存内存撤出。然后到所有的代码/数据需要从磁盘读取(DSK 100%)的时刻,一切都慢吞吞的。
听上去很奇怪,Python会在关闭解释器之前做最后一个GC,这会在很短的时间内,导致内存使用量产生巨大的飞跃。再者就是,我想先证明它,然后弄清楚如何正确处理它。因此,我在uWSGI的python插件中注释掉 Py_Finalize 的调用,问题就消失了。
但显然的是,我们不能对 Py_Finalize 只是一禁了之。因为我们有一堆重要的清理,要用到依赖它的atexit钩子。最后,我们所做的就是,在CPython添加一个运行时标志,来完全禁用GC。
最后,我们开始将这个做法推广到更大的规模。此后,我们在整个集群进行尝试,但是,连续部署再次被中断了。不过,这次它只是在旧CPU型号(Sandybridge)的机器上中断了,甚至更难重现。经验教训:要多测试旧式客户端/旧型号,因为他们最容易被中断。
因为我们的连续部署是一个相当快的过程,为了真正捕获发生了什么,我在rollout命令添加了一个单独的 atop 。这样我们就能够抓住高速缓存内存真的很低的一个时刻。所有uWSGI进程触发了很多MINFLT(minor page faults,小页面错误)。
(点击放大图像)
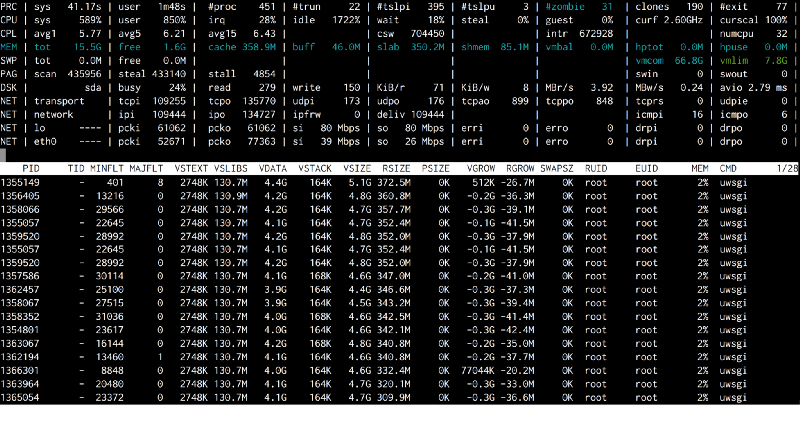
再次通过perf得出的概要,我们再次看到了 Py_Finalize 。在关机时,除了最终的GC,Python做了一堆清理操作,如破坏类型对象和卸载模块。这又一次损害了共享内存。
(点击放大图像)
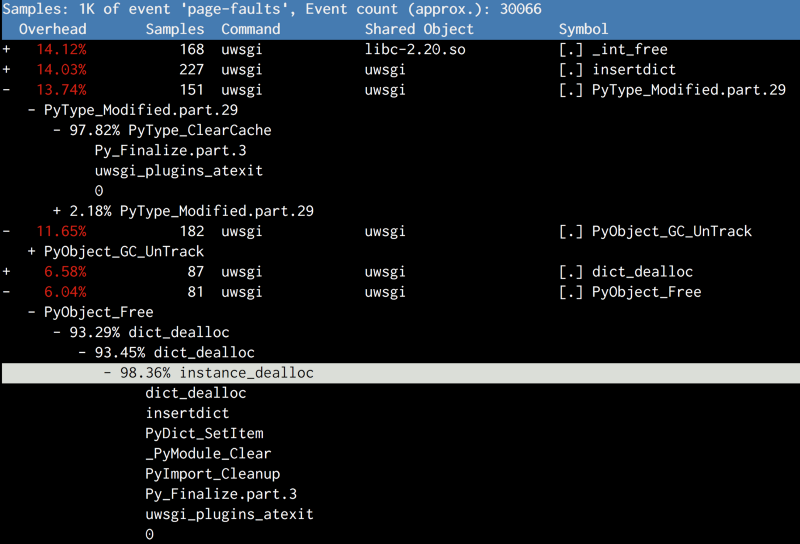
尝试4:关闭GC的最后一步:无须清理
为什么我们需要清理?这个进程将会死掉去,我们将得到另一个替代品。我们真正关心的是清理应用程序的atexit钩子。至于Python的清理,我们不必这样做。下面是在bootstrapping脚本中的结束:
# gc.disable() doesn't work, because some random 3rd-party library will # enable it back implicitly. gc.set_threshold(0) # Suicide immediately after other atexit functions finishes. # CPython will do a bunch of cleanups in Py_Finalize which # will again cause Copy-on-Write, including a final GC atexit.register(os._exit, 0)
基于这个事实,atexit函数以注册表的相反顺序运行。atexit函数完成其他清除,然后调用 os._exit(0) 来退出最后一步的当前进程。
随着这两条线的变化,我们终于完成了整个集群的推广。在仔细调整内存阈值后,我们获得了10%的全局性能提升!
回顾
在回顾这次性能的提升时,我们有两个疑问。
首先,没有垃圾回收的话,因为所有的内存分配不会释放,Python内存就不会爆破吗?(记住,在Python内存中没有真正的堆栈,因为所有的对象都是在堆上分配的。)
幸运的是,这并非事实。Python中用于释放对象的主要机制仍然是引用计数。当一个对象被解除引用(调用 Py_DECREF )时,Python运行时总是检查其引用计数是否降到零。在这种情况下,将调用对象的释放器。垃圾回收的主要目的是打破引用计数不起作用的参考周期。
#define Py_DECREF(op) /
do { /
if (_Py_DEC_REFTOTAL _Py_REF_DEBUG_COMMA /
--((PyObject*)(op))->ob_refcnt != 0) /
_Py_CHECK_REFCNT(op) /
else /
_Py_Dealloc((PyObject *)(op)); /
} while (0)
打破增益
第二个问题:增益来自哪里?
禁用GC的增益是两倍:
- 我们为每个服务器释放了大约8GB的RAM,用于为内存绑定服务器生成创建更多的工作进程,或者降低CPU绑定服务器生成的工作程序刷新率;
- 随着每周期CPU指令(IPC)增加约10%,CPU吞吐量也随之提高。
# perf stat -a -e cache-misses,cache-references -- sleep 10
Performance counter stats for 'system wide':
268,195,790 cache-misses # 12.240 % of all cache refs [100.00%]
2,191,115,722 cache-references
10.019172636 seconds time elapsed
禁用GC时,高速缓存未命中率有2~3%的下降,主要原因是IPC增加10%所致。CPU高速缓存未命中的代价太高了,因为它使CPU管道停滞。对CPU缓存命中率的微小改进通常可以显著提高IPC。使用较少的CoW,具有不同虚拟地址(在不同的工作进程中)的更多CPU高速缓存线指向相同的物理存储器地址,导致更好的高速缓存命中率。
我们可以看到,并非每个组件都按预期工作,有时,结果可能会非常令人惊讶。所以继续挖掘、四处观望,你会惊讶事情究竟是如何运作的!
感谢魏星对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

