使用SIMD技术提高C++程序性能
作者:张银奎,《软件调试》和《格蠹汇编》作者,从事软件开发和研究十余年,对IA-32架构、操作系统内核、虚拟技术,尤其对软件调试有较深入的研究。微博ID:@dbgger
本文为 《程序员》 原创文章,未经允许不得转载,更多精彩文章请 订阅《程序员》
今天和C++同行谈谈如何提高自己的身价。编程语言只是工具,要把工具用到最合适的地方,扬其长且避其短,打造出有价值的软件产品,那么使用这工具的人自然身价就高了。
C++语言的优势C++语言有哪些优势呢?当然有很多,不然早消亡了。但泛泛地说“有很多”没意义。到底有哪些呢?不同人可能有不同的回答。同一个人在不同时间也可能回答不同。这里我们不妨听听C++之父Bjarne Stroustrup先生如何说。在前不久举办的“2016 C++及系统软件技术大会”上,Bjarne先生做了题为《What C++ is and what it will become》的主题演讲。他很深刻地阐释了到底什么是C++,解说了C++语言的根本特征和优势。有一页讲稿的题目叫“C++ in two lines”(用两行话来描述C++),可谓画龙点睛之笔。这两行是什么呢?第一行是“Direct map to hardware”,第二行是“Zero overhead abstraction”。粗浅翻译一下,就是“直接映射到硬件”和“0负担抽象”。
“直接映射到硬件”是说C++语言和硬件之间直接对应,C++的语句可以直接对应到CPU指令,C++的数据类型也可以直接对应到CPU支持的数据类型。也就是说,C++语言的代码和数据可以很直接地翻译到CPU支持的指令和数据,不需要做这样那样的转换。概言之,就是效率很高。
单纯从效率来讲,最直接的语言当然要属汇编,但汇编语言的问题是缺乏高级抽象,代码难以组织。所以Bjarne先生的第二行是“0负担抽象”,我想这一行又包含两层意思,第一层意思是C++是有抽象的,第二层意思是支持抽象的负担为0。在今天的软件大生产时代,即使是比较小型的软件项目,使用抽象也是必须的。今天流行的编程语言几乎无不支持抽象,不论Java还是C#、F#。虽然都支持抽象,但有些语言为了抽象付出的代价很大,资源消耗多,运行速度慢,也就是额外开销高。而C++是0负担抽象,0额外开销。Bjarne先生一定也知道Java的流行,一定也听见过关于C++和Java孰是孰非的争论。说C++是0额外开销略微有些夸张,但相对其他额外开销高的语言来说,相当于是0了。不这样说的话,说抽象负担远远低于其他语言,岂不啰嗦?一代宗师此言一出,言简意赅,料也无人敢出来说半个不是。

图1 C++之父Bjarne先生在介绍C++的根本优势
这两行话简单有力,一个是效率高,一个是负担小,加起来一起托出C++的核心优势:锐利无比,性能一流。
怀着虔诚的心,我一边聆听Bjarne先生论述上面两行话,一边用手机拍下了这个历史瞬间。地点是上海浦东外高桥的喜来登酒店,时间是2016年10月28日上午10点12分。
大师的话值得反复体味,每个C++程序员都应该牢记。在做设计时,我们应该用这两句话来检查自己的设计,是否大道至简,能否发挥硬件的性能。编写和检查代码时,我们更应该想起这两句话,把杂乱的逻辑理顺,把冗余的代码删掉,反复优化每行代码,把硬件的性能发挥到极致。不然的话,怎么对得起C++语言,怎么对得起Bjarne先生?

图2 C++之父Bjarne先生希望加入到C++17中的语言特征
有人说,硬件太强大了,写代码时不需要那么在意性能问题。这话真是放屁,每一位有责任心的C++程序员都应该站出来痛斥这样的言论。
在Bjarne先生介绍C++的未来发展时,他谈到了最希望加入到C++17中的语言特征。在这个包含十项内容的列表中,第8项是SIMD向量和并行化算法。刚好与我为准备的讲题不谋而合。
SIMD是Single Instruction,Multiple Data的缩写——意为单指令多数据。我是在Intel工作期间听说这个技术的,好多年前了,什么场合已经记不清,但仍记得当时眼前一亮,仿佛看到一束霞光,心中赞叹这种做法太美妙了。SIMD思想的最大特色和魅力是简单自然——人法地,地法天,天法道,道法自然。为什么如此说呢?因为SIMD思想的应用实例在我们的生活中随处可见,其出现年代或许可以追溯到原始社会。
我喜欢吃面包,因此以面包作坊为例。假设某作坊要做1000个面包,每个面包要经过成型、入炉、烘烤、取出等步骤。如果每次只操作一个面包,那么大多数基本动作都要重复1000次。但如果使用一个图3所示的简单模具,上面有四个“包厢(面包之厢,姑且称此名)”,那么便可以一次操作四个面包。这样一来,很多操作便都是成批的了,一次成型四个,向烤箱里放时,一次四个,拿出来时,又是一次四个,于是很多操作的重复次数便从1000次下降到了250,生产效率大大提高。

图3 SIMD思想源于生活
走进生活,其实有很多类似例子,我小时候看过用黄泥做土坯的劳动场面,一个称为坯模子的木框,上面有多个格子,每个格子对应一块土坯。如果到工厂里看一下,那么就更多了。很多工序都在使用SIMD思想,成批地生产。劳动激发智慧,软件同行们应该好好向现实社会学习。
SIMD在计算机领域应用也有很多年了,目前比较普遍地认为著名的ILLIAC IV大型机是SIMD思想的在现代计算机中的最早实现。ILLIAC IV由美国Illinois大学设计,宝来公司(Burroughs)建造,项目从1965年开始,经历六年时间耗资四千万美元完成,安装在美国国家航空航天局(NASA),服役多年,直到1981年才停机退役。
源于ILLIAC IV使用手册的图4既描述了ILLIAC IV的核心部件,又阐释了它的工作原理。图中的PE是Processor Element的缩写,即处理器单元,其功能和命名都与我们今天所说的Execution Unit(EU)(GPU内的基本执行单元)非常类似。PEM是Processing Element Memory,即处理单元记忆体,用来存放要计算的数据和计算结果。
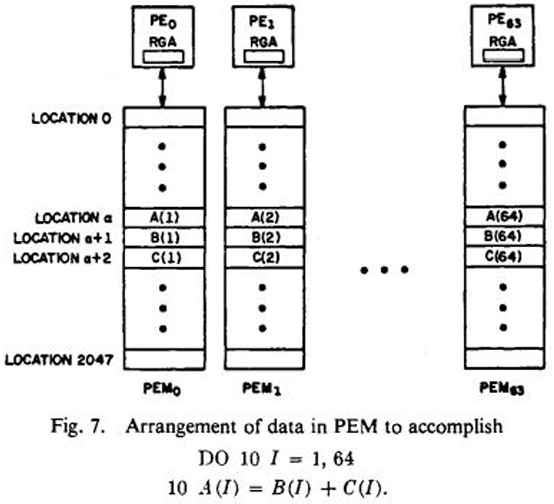
图4 ILLIAC IV工作原理
ILLIAC IV有64个PE(处理器单元),可以同时做64个计算。图中演示的便是把数组B和数组C相加,结果放到数组A,一次便完成64个元素。
在ILLIAC IV手册里,还可以看到一些有趣的插图,比如图5这幅卡通画非常形象地描绘了ILLIAC IV可以成批处理数据的能力,工作人员用大叉子把文件一大摞一大摞地投给ILLIAC IV的大嘴。ILLIAC IV的众多计算单元排成一行在等待“喂食”。
IA CPU上SIMD实现刚才介绍了SIMD的思想以及最早的实现,接下来先总览Intel架构(简称IA)上的SIMD实现,然后再给出实例。
很多人不知道SIMD是什么,但知道MMX。MMX是MultiMedia eXtensions的缩写,意思是多媒体扩展。1997年推出的基于P5架构的奔腾处理器是包含MMX技术的第一款IA CPU。从硬件角度来看,MMX技术包含8个64位的寄存器,称为MM0-MM7,可以对8个单字节整数,或者4个字,或者2个双字做各种组合操作。MMX仅支持整数类型,不支持浮点数。
1999年随同奔腾II处理器推出的SSE(Streaming SIMD Extensions)技术弥补了MMX不支持浮点数的不足,并对MMX做了很多改进,包括把寄存器的宽度扩展为128位,并且不再复用x87寄存器,并引入了70条新的指令。
2008年公布的AVX(Advanced Vector Extensions)进一步把寄存器的宽度扩展为256位,并且革新了指令格式,支持三目运算符。2011年发布的Sandy Bridge处理器包含了AVX技术。

图5 描述ILLIAC IV强大并行处理能力的卡通画
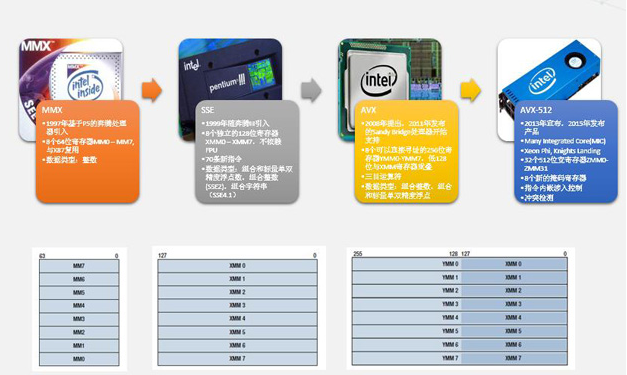
图6 IA CPU上的SIMD实现
“天河二号”是由国防科学技术大学研制的超级计算机系统,峰值计算速度可以达到每秒5.49亿亿次、持续计算速度每秒3.39亿亿次。在2014年11月17日公布的全球超级计算机500强榜单中,“天河二号”名列冠军。天河二号是个庞大的系统,由数以万计的计算节点组成,据说每个节点包含两颗Xeon处理器和三块Xeon Phi协处理计算卡。Xeon Phi具有强大的并行计算能力,其核心技术便是名为AVX-512的SIMD技术。AVX-512是对AVX的再扩展,寄存器的宽度扩展为512位,数量也加大一倍,从16个提高到32个。
至此我们已经介绍了SIMD的思想、历史以及在X86架构CPU的实现,接下来将通过一个具体的图像处理实例来介绍如何把SIMD技术应用到C++项目里,探讨难易不同的多种方案、以及如何衡量所取得的性能提升。
在C++程序中使用SIMD技术图7列出了使用SIMD技术的多种方法,我们先按从上至下的顺序简要介绍每一种,然后重点介绍汇编语言方法。

图7 使用SIMD技术的多种方法
第一种方法是使用著名的IPP库,IPP的全称是Intel Integrated Performance Primitives, 是英特尔公司开发的一套跨平台软件函数库,提供了非常广泛的功能,包括各种常用的图形图像、音视频处理函数。因为其中的很多函数都已经使用SIMD技术做了优化,所以使用这个库是使用SIMD技术的一个快捷途径。通过链接 https://software.intel.com/en-us/intel-ipp/ 可以访问IPP的官方介绍,了解更多信息。
第二种方法是使用编译器的自动向量化(Auto-vectorization)支持。比如图8是在Visual Studio(C++)中通过项目属性对话框启用自动向量化的截图。
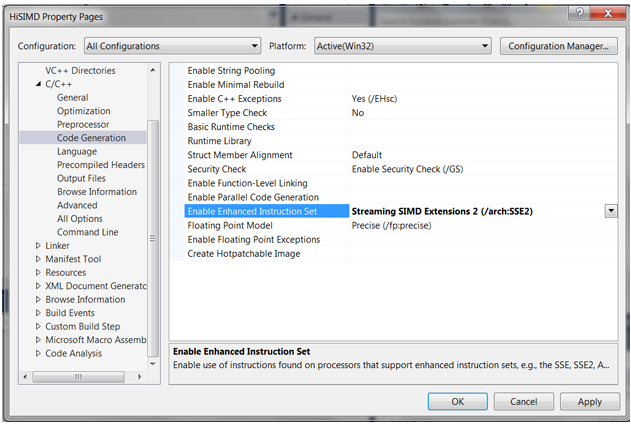
图8 在Visual Studio中启用自动向量化支持
经笔者分析,这样启用后编译好的程序中确实使用了一些SIMD指令,比如图9右侧蓝色加亮那一行使用的便是SSE2中的cvtsi2sd指令,它可以将源操作数中的有符号双字整数转换成目标操作数中的双精度浮点值。
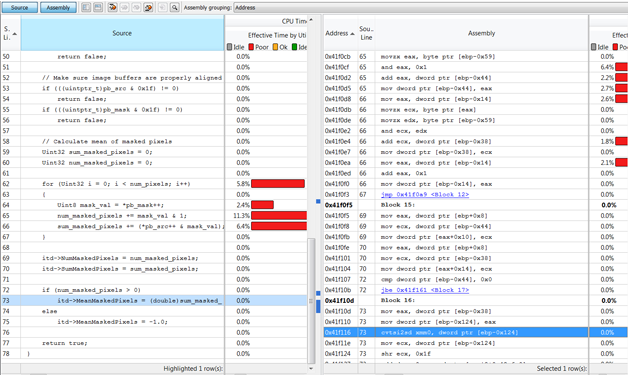
图9 观察编译器自动向量化产生的SIMD指令
如果使用GCC编译器,那么可以使用类似这样的命令行来编译:
代码1如果希望看到编译器所采取的向量化动作,那么可以增加-ftree-vectorizer-verbose=1,于是可以类似图10的输出信息。

图10 使用GCC的自动向量化支持
使用GDB的反汇编功能,可以很容易地观察到GCC产生的SIMD指令,如图11所示。
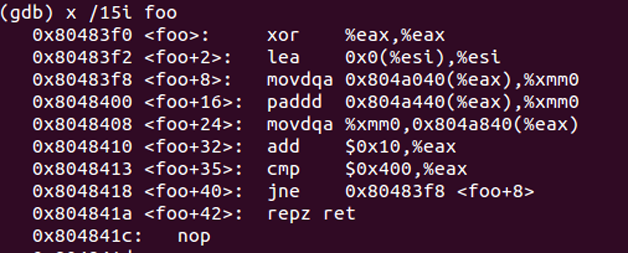
图11 GCC的自动向量化功能产生的汇编指令
第三种方法是使用编译器指示符(compiler directive),比如,如果使用英特尔的C/C++编译器(ICC)编译如下代码,那么ICC便会对#pragma simd指示符下面的for循环做向量化,并给出类似下面这样的输出信息:remark: SIMD LOOP WAS VECTORIZED.
代码2第四种方法是使用Cilk技术。Cilk一词源于发音相近的Silk一词,蕴含的意思是要把并行编程做的像丝绸一样美丽。Cilk技术最早由MIT开发,第一版本于1994年发布。后来开发者创建了一个名叫 Cilk Arts的公司,推出改进的私有版本。2009年,英特尔收购了Cilk Arts,将Cilk技术整合进英特尔编译器中。2012年后,Cilk再次成为开源项目,GCC中便有支持(需要4.8或者更高版本)。感兴趣的朋友可以从 https://www.cilkplus.org 网站了解更多信息和下载有关工具及示例代码。
第五种方法是使用编译器的内建函数(intrinsic),举例来说,下面这个循环来自我们要详细讨论的图像二值化程序的C++代码。
代码3如果使用Visual C++编译器的SIMD intrinsic进行改写,那么新的代码如清单1所示。
清单1 通过intrinsic使用SIMD技术
代码4第六种方法是直接使用汇编语言编写汇编函数,然后再从C++代码中调用汇编函数,稍后会详细介绍。
比较图7中的六种方法,灵活度和可控性由上至下越来越高,但是使用的难度基本也是越来越大。

有两种方法可以在C++项目中使用汇编代码,一种是通过__asm{}这样的指示符号把汇编代码嵌入在C++函数中,另一种是把汇编代码放在单独的以.asm结尾的文件中。前一种方法因为不支持64位,所以基本过时了。
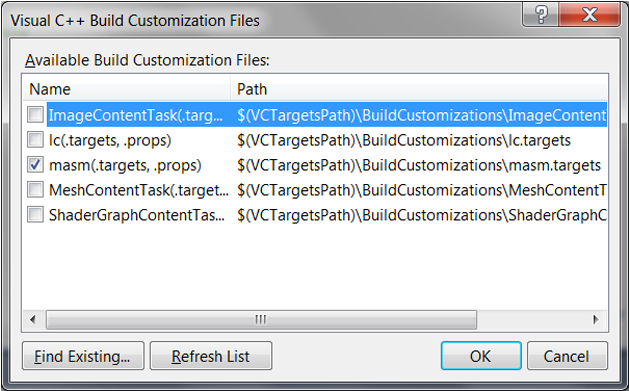
在使用后一种方法时,首先要在项目的Solution Explorer树形控件上右击希望加入汇编文件的项目,然后选择Build Dependencies → Build Customizations调出图6所示的对话框,然后选中masm行。
详细讨论如何编写汇编代码超出了本文的范围,这里只能管中窥豹,介绍与上面讨论的for循环(清单1上方)对应的一段汇编指令(引自《现代x86汇编语言程序设计》一书),如清单2所示。
清单2 对灰度图像进行二值化处理的SSE2汇编程序片段
代码5对于长久没有写过悉汇编代码的同行,理解清单2中的代码可能有些困难,特别是其中的SIMD指令。下面将以笔者惯用的调试方法来帮助大家理解——在调试器里看SIMD。
在清单2的第一行指令处设置断点(与在C++代码中设置断点方法相同),触发程序调用这个汇编函数,断点命中后,单步走过这条指令。
代码6简单说,这条指令就是把edx指向的ITD结构体的Threshold字段赋给EAX寄存器。
打开汇编窗口,编译后的指令为:
代码7这意味着,Threshold字段在结构体中的偏移是0xC。Ctrl + Alt + A调出Visual Studio的命令窗口,观察内存和寄存器的值,可以印证:
代码8看来,这条指令的作用就是把二值化的阈值加载到EAX寄存器。
接下来一条指令比较简单,movd xmm1,eax,就是把常规寄存器EAX中存放的阈值传递给SSE的SSE寄存器XMM1。Visual Studio的寄存器窗口默认不显示SIMD的寄存器,但是可以通过快捷菜单很容易解决这个问题,点击右键,调出图12所示的快捷菜单,选中SSE即可。
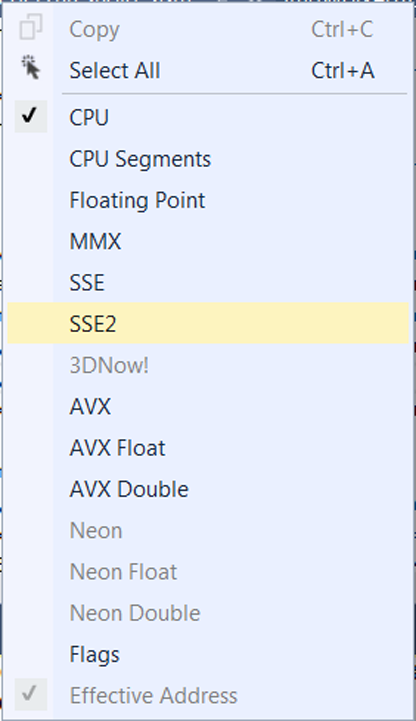
图12 配置显示SSE寄存器
选中SSE后,单步执行,再观察寄存器窗口,可以看到XMM1的值如下:
代码9接下来的两条指令是要把已经在XMM1最低字节中的阈值(0x98)散列(shuffle)到其他字节中。
代码10两条指令中的p代表packed,即组合数,是SIMD中的常见术语,pshufb是Packed Shuffle Bytes的缩写,它根据第二个操作数指定的控制掩码对第一个操作数执行散列操作,产生一个组合数。描述起来比较拗口,单步执行这两条指令后看一下效果大家就明白了:
代码11有趣吧。接下来的这条指令(movdqa xmm2,xmmword ptr [PixelScale])是把PixelScale常量数组中的缩放值赋给XMM2。
代码12执行后,XMM2的值为:
代码13接下来的指令是做组合减法,最有SIMD特色的操作。
代码14单步前两个寄存器的值为:
代码15单步后为:
代码16也就是一次完成16个整数减法。
做好准备工作后,接下来就开始处理ESI指向的图像数据了,movdqa xmm0,[esi]每次可以把16个字节加载到XMM0,psubb xmm0,xmm2减去缩放值(128),然后使用下面这条pcmpgtb指令进行比较。
代码17pcmpgtb的全称是Compare packed signed byte integers for greater than,它会根据比较结果来把目标字节写为全0或者全1(大于)。例如,单步前的XMM0和XMM1如果是:
代码18那么单步后便是:
代码19而后,movdqa [edi],xmm0指令把结果写到EDI指向的目标缓冲区中。然后把ESI和EDI都增加16,进行下一次循环。
图13是比较编写的测试程序界面,列表控件中包含了以不同方式对同一幅图像执行二值化操作测量到的时间。
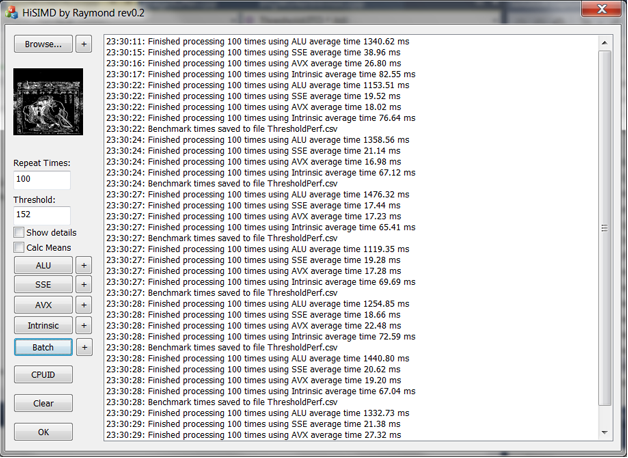
图13 比较不同计算方式的测试程序
从图13可以看到,与普通的C++代码(图中以ALU表示)相比,使用SSE方法的速度提升是非常明显的,从原来的1000多毫秒,加快到了10/20多毫秒,这就是SIMD的魅力。篇幅关系,要就此打住了,感兴趣的朋友可以下载示例程序的完整源代码( http://advdbg.org/ 的资源板块)亲自体验一下。
订阅2017年程序员(含iOS、Android及印刷版)请访问 http://dingyue.programmer.com.cn

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

