在阿里云上实践Serverless架构
Serverless架构是随着微服务架构的兴盛而逐渐兴起的,这种软件架构目前还没有清晰且又准确的定义,目前对Serverless架构公认的特征包括:
(1)Serverless架构起初用于描述通过依赖于第三方服务即各种云服务来实现业务的逻辑和状态进行管理的应用。比如常见的SPA(单页Web应用)、富客户端应用等。
(2)基于Serverless架构的应用还可以是这样的应用,一部分服务逻辑由应用实现,但是跟传统架构不同之处在于,Serverless架构的应用运行于无状态的容器中,可以由事件触发,短暂的,完全被第三方管理。
在阿里云上采用Serverless架构有如下优点:
1. 无需管理多个阿里云实例
2. 使得整个软件架构具备良好的可扩展性
3. 可以很方便地做到按执行次数计费
要在阿里云上实现一个基于Serverless架构的大数据管道应用,需要先理解大数据管道应用的功能。大数据管道应用负责从数据源中获取各种数据,然后通过ETL进程(即提取Extract、转换Transform、加载Load等)把数据输出到目的地。下图描述了一个典型的服务器大数据管道:
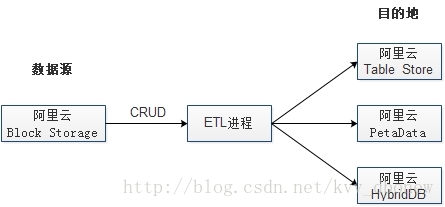
这里我们使用了阿里云提供的几种服务:
- 块存储(Block Storage)
Block Storage是阿里云为云服务器ECS提供的低时延、持久性、高可靠的数据块级随机存储。 - 表格存储(Table Store)
Table Store是构建在阿里云飞天分布式系统之上的NoSQL数据存储服务,提供海量结构化数据的存储和实时访问。 - 云数据库ApsaraDB PetaData
PetaData是同时支持海量数据在线事务OLTP和即席分析OLAP的HTAP(Hybrid Transaction /Analytical Processing)关系型数据库。 - 云数据库ApsaraDB HybridDB
HybridDB是一种在线MPP大规模并行处理数据仓库服务。
我们开发的基于Serverless架构的大数据管道应用可以用于:
(1)通过阿里云的负载均衡器存储并收集日志,并对日志进行转换和过滤,存储到HybridDB。
(2)实时获取输入源的数据,并对数据进行转换和过滤,存储到PetaData,用于下一步的在线OLTP事务。
(3)对阿里云块存储的数据进行转换和过滤(比如转码),继续存储到块存储上。
(4)其它外部事件数据、时间计划数据等的处理等。
在构件基于Serverless架构的大数据管道应用也有一定的局限性,比如:
* 最大执行时间:300秒
* 最大内存:3584MB
* 临时磁盘容量:512MB
一些真实使用案例:
* 加载生产数据CSV文件
* 云存储的解压数据
* 数据压缩
* 数据格式转换
* 数据编解码转换
* 数据上传
使用数据流处理方法,而不是线性执行。
var ALIService = require("aliyun-MY-sdk");
var zlib = require("zlib");
var split = require("split");
var transform = require("stream-transform");
var sourceBucket = "BUCKET_NAME";
var sourceKey = "KEY";
var targetBucket = "BUCKET_NAME";
var targetKey = "KEY";
var storage = new ALIService.storage();
var transformer = transform(function(record, callback) {
// TODO transform
callback(null, record);
});
var pipeline = storage.getObject({
Bucket: sourceBucket,
Key: sourceKey
})
.createReadStream()
.pipe(zlib.createGunzip())
.pipe(split())
.pipe(transformer)
.pipe(zlib.createGzip());
storage.upload({"Bucket": targetBucket, "Key": targetKey, "Body": pipeline}, function(err) {
if (err) {
console.error(err);
}
});
基于Serverless架构的大数据管道应用可以让用户处理数据而不影响内存或磁盘空间的限制。目前实现的300秒最大执行时间对于数据管道的最大吞吐量有一定的局限性,但是常规情况下也够用了,如果真遇到不满足需求的情况,可以考虑把数据分割成更小的块。
注意,转载本篇文章请注明出处,否则将追究其法律责任!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

