百度PaddlePaddle联手Kubernetes,助力开发者高效训练深度学习模型
2016 年 9 月,百度开源了深度学习框架 PaddlePaddle,今天,百度又宣布实现了这一框架和集群管理系统(cluster management system)Kubernetes 的兼容,从而使 PaddlePaddle 成为了迄今为止唯一一个官方支持 Kubernetes 的框架。
据百度研究官网介绍,这种兼容性将使得开发者可以很方便地在全球所有主要的云服务提供商(包括百度云和企业内部的集群(on-premise clusters))上训练大型的模型。该项目是由百度和 CoreOS 联合开发的;CoreOS 是 Kubernetes 的主要贡献者之一。
开发者通常会将人工智能程序与网络服务、日志收集器和数据处理器一起联合部署在同一个通用的集群上,以实现高效的数据流程(data pipelines)。为了管理这个过程,开发者就会用到 Kubernetes 这样的工具;Kubernetes 是现在最复杂精细的通用集群管理系统之一。通过使 PaddlePaddle 与 Kubernetes 兼容,开发者现在可以用它们开发高效的深度学习驱动的应用。
「使用 Kubernetes 这样的框架,开发者再也不用担心为了在一个标准云平台上配置和部署深度学习训练系统而编写不必要的代码。」PaddlePaddle 项目技术负责人 Yi Wang 说,「这最终能帮助他们更快地将他们的项目落地。」
Kubernetes 可将 PaddlePaddle 中需要 GPU 的工作和需要其它资源(如大型存储或磁盘 I/O 流通)的工作封装到同一套物理计算机上,从而可以充分利用集群硬件。而且当白天存在许多活跃用户时,它还会自动扩展其在线服务,而到了夜间用户较少时它又会释放出一些资源。
PaddlePaddle 是一个源于百度的易用的深度学习框架,已经在百度的许多产品和技术中得到了应用,其中包括搜索排序和机器翻译。据介绍,该框架非常适合用于训练循环神经网络,从而使其可以高效地被应用在自然语言理解、语音和多媒体等应用中。百度声称,自去年 9 月开源之后,PaddlePaddle 已经成为了现在增长最快的深度学习框架之一。
关于在 Kubernetes 上运行 PaddlePaddle 的更多细节,可在下面的介绍文章中了解(下文作者为 Baidu Research 的 Yi Wang 和 CoreOS 的 Xiang Li)。

什么是 PaddlePaddle
PaddlePaddle 是一个易于使用、高效、灵活和可扩展的深度学习平台,该平台最初是由百度在 2014 年为其产品应用深度学习而开发的。
现在已经使用 PaddlePaddle 的创新已经超过了 50 项,并支持包括搜索引擎、在线广告、Q&A 和系统安全等 15 项百度产品。
2016 年 9 月,百度开源了 PaddlePaddle,并且很快就吸引了很多来自百度外的参与者。
为什么要在 Kubernetes 上运行 PaddlePaddle
PaddlePaddle 是被工程师们设计成精简且不依赖于计算基础设备的深度学习平台。用户可以在 Hadoop、Spark、Mesos、Kubernetes 和其他平台上运行它。我们对 Kubernetes 有很强烈的兴趣,因为它的适应性、高效性等丰富的特点。
当我们将 PaddlePaddle 应用于百度的各种产品时,我们注意到 PaddlePaddle 的两种主要用法——研究和产品。用于研究的数据并不会经常性地变动,重点是快速地实验以达到预期的科学度量。而应用于产品的数据会经常性地变动,它通常来自网页服务而产生的日志信息。
一个成功的深度学习项目包括了研究和数据处理流程(pipeline)。因为有很多参数需要调整,许多工程师在整个项目的不同部分同时工作。
为了确保项目易于管理且能高效利用硬件资源,我们希望能将项目的所有部分运行在同一个基础平台之上。
这样的平台需要提供:
容错性(fault-tolerance)。它应该将流程(pipeline)的每一个阶段摘取为一个服务,并且这些服务包含了许多过程,这样的冗余能够提供高流通量(high throughput)和鲁棒性。
自动扩展(auto-scaling)。在白天,通常有许多活跃用户,因此平台就需要能向外扩展其在线服务。而到了晚上,平台就需要释放一些资源进行深度学习试验。
工作封装和隔离(job packing and isolation)。平台需要能够为 PaddlePaddle 训练器过程(trainer process)分配要求的 GPU、需要大内存的网络后端服务和需要磁盘吞吐量的 CephFS 过程,并且保证相同的节点充分利用其硬件资源。
我们想要的是一个能在同一个集群上运行深度学习系统、网页服务器(如 Nginx)、日志收集器(如 fluentd)、分布式队列服务(如 Kafka)、日志加入器(log joiner)和使用 Storm、 Spark、Hadoop MapReduce 编写的其他数据处理器的平台。我们希望所有的工作(线上线下、产品和实验)都能在同一个集群上运作,这样我们才能充分利用集群,因为不同的工作需要不同的硬件资源。
我们选择的是基于容器(container based)的解决方案,因为由虚拟机(VM)引入的总开销与我们的高效、实用这一目标相矛盾。
基于我们对不同的基于容器(container based)解决方案的研究,Kubernetes 最符合我们的要求。
在 Kubernetes 上的分布式训练
PaddlePaddle 本就支持分布式训练,在 PaddlePaddle 集群中有两个角色:参数服务器(parameter server)和训练器(trainer)。每个参数服务器处理包含全局模型的一部分,每个训练器有该模型的局部复制,并且使用它的局部数据更新该模型。
在训练的过程中,训练器将模型更新信息发送到参数服务器,参数服务器负责聚集这些更新,以便于训练器能够能够与全局模型同步它们的本地复制版本。
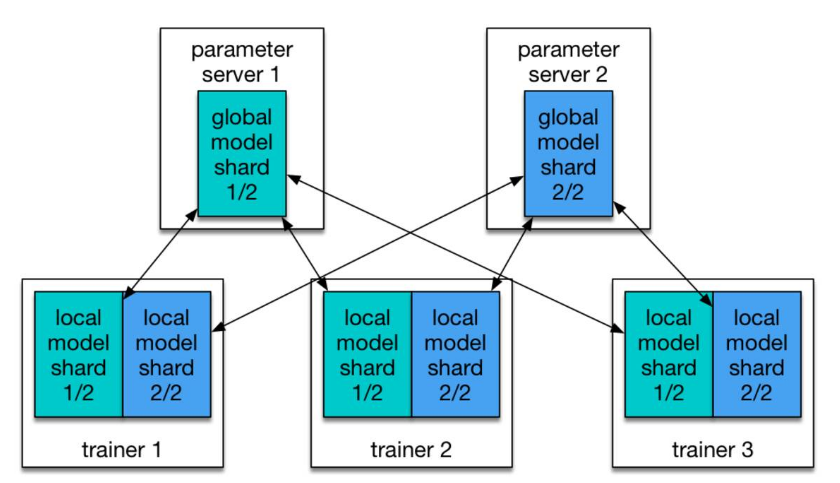
图 1:模型被划分为两个分片(shard),分别由两个参数服务器管理
一些其他的方法使用一系列参数服务器在多台主机的 CPU 存储空间中一起存储一个非常大型的模型。但在实际中,我们通常没有这么大的模型,因为由于 GPU 的存储限制,处理特别大的模型是效率低下的。在我们的配置中,多参数服务器大部分是为了快速通信。假设只有一个参数服务器处理与所有的训练器一起工作,参数服务器要聚集来自所有训练器的梯度,这是一个瓶颈。在我们的经验中,经实验验证的有效配置包括同样数量的训练器和参数服务器。我们通常在同样的节点上运行一对训练器和参数服务器。在下面的 Kubernetes 配置中,我们启动了一个运行了 N 个 pod 的工作,其中每个 pod 中都有一个参数服务器和一个训练器。
yaml
apiVersion: batch/v1
kind: Job
metadata:
name: PaddlePaddle-cluster-job
spec:
parallelism: 3
completions: 3
template:
metadata:
name: PaddlePaddle-cluster-job
spec:
volumes:
- name: jobpath
hostPath:
path: /home/admin/efs
containers:
- name: trainer
image: your_repo/paddle:mypaddle
command: ["bin/bash", "-c", "/root/start.sh"]
env:
- name: JOB_NAME
value: paddle-cluster-job
- name: JOB_PATH
value: /home/jobpath
- name: JOB_NAMESPACE
value: default
volumeMounts:
- name: jobpath
mountPath: /home/jobpath
restartPolicy: Never
我们能从配置中看到,并行和实现都被设定为 3。所以该工作将同步启动 3 个 PaddlePaddle pod,而且在所有的 3 个 pod 结束后运行的工作才会结束。
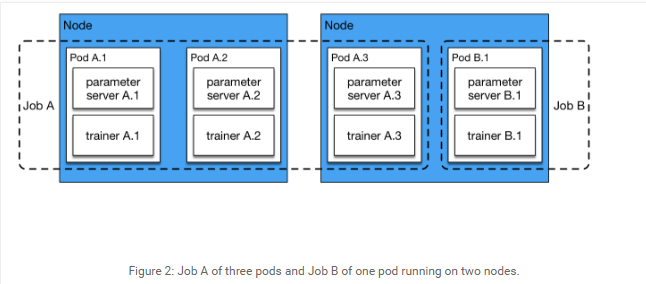
图片 2:运行在 2 个节点上的 3 个 pod 的 Job A 和 1 个 pod 的 Job B
每个 pod 的入口是 start.sh。它从一个存储服务下载数据,所以训练器可以从 pod 本地的磁盘空间快速读取。下载完成之后,其会运行一个 Python 脚本 start_paddle.py,该脚本会启动一个参数服务器,然后等待所有 pod 的参数服务器都为使用做好准备,之后再启动该 pod 中的训练器过程。
这里的等待是必需的,因为每个训练器都需要与所有的参数服务器进行通信(如图 1)。Kubernetes API 使训练器能够检查 pod 的状态,所以该 Python 脚本可以等待,直到所有的参数服务器的状态都改为「running」,然后它才会触发训练过程。
目前,从数据分片(data shards)到 pods/trainers 的映射是静态的。如果我们要运行 N 个训练器,我们需要将数据分割成 N 个分片,并将每个数据分片静态地分配给训练器。同样我们依赖于 Kubernetes API 来获取工作中的 pods,因此我们可以将 pods / trainers 从 1 到 N 建立索引。第 i 个训练器将读取第 i 个数据分段。
训练数据通常是在一个分布式文件系统上提供的。我们实际上在我们的企业内集群上使用了 CephFS,在 AWS 上使用了 Amazon Elastic File System。如果你对构建 Kubernetes 集群来运行分布式 PaddlePaddle 训练工作感兴趣,请参考这个教程:
https://github.com/PaddlePaddle/Paddle/blob/develop/doc/howto/usage/k8s/k8s_aws_en.md
未来
我们正在努力让 PaddlePaddle 能够在 Kubernetes 上运行得更加顺畅。
你可能已经注意到,当前的训练器调度(trainer scheduling)完全依赖于基于静态分区图(static partition map)的 Kubernetes。这种方法开始是很简单,但也可能会导致一些效率问题。
首先,缓慢或死亡的训练器会终止整个工作。在初始部署之后就没有什么受控的优先权(preemption)或重新调度(rescheduling)了。
其次,其资源配置是静态的。所以如果 Kubernetes 有比我们预计的更多的资源,那么我们就必须手动修改其资源要求。这是一个非常繁重的工作,与我们的效率和实用的目标不一致。
为了解决上述问题,我们将添加一个理解 Kubernetes API 的 PaddlePaddle master,其可以动态地添加/移除资源量,并且可以以一种更加动态的方式为训练器处理分片(shard)。该 PaddlePaddle master 使用 etcd 作为从分片到训练器的动态映射的容错存储。因此,即使该 master 崩溃,该映射也不会丢失。Kubernetes 可以重启该 master,然后该工作将会继续运行。
另一个潜在的提升是更好的 PaddlePaddle 工作配置(job configuration)。我们的有相同数量的训练器和参数服务器的经验大多数都收集自在专用集群(special-purpose clusters)上的应用。据我们观察,这种策略在我们客户的仅运行 PaddlePaddle 工作的集群上是高性能的。但是,这种策略可能在能够运行许多种工作的通用集群上并不是最优的。
PaddlePaddle 训练器可以利用多个 GPU 来加速计算。GPU 目前还不是 Kubernetes 中的首选资源。我们还必须半人工地管理 GPU。我们期望能与 Kubernetes 社区一起提升 GPU 支持,以确保 PaddlePaddle 能在 Kubernetes 上实现最佳的表现。
资源
Kubernetes:
http://get.k8s.io/
本 Kubernetes 项目的 GitHub:
https://github.com/kubernetes/kubernetes
Stack Overflow 问题讨论:
http://stackoverflow.com/questions/tagged/kubernetes
Slack 社区:
http://slack.k8s.io/
正文到此结束
- 本文标签: ip 集群 管理 REST Uber ACE 深度学习 Hadoop 搜索引擎 数据 value Amazon http ORM 分布式 翻译 产品 开发者 Kubernetes 同步 主机 处理器 id 服务器 广告 UI 智能 开源 DDL 神经网络 Master Nginx tar 配置 空间 百度 core Job 希望 root map 代码 开发 src 下载 文件系统 云 https 安全 GitHub 参数 线下 文章 IO git apr API 快的 企业 python 图片
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

