AAAI-17获奖论文深度解读(上):从无标签监督学习到人工智能道德框架

AAAI 2017 大会刚刚闭幕,会议围绕人工智能的研究与发展进行了多场演讲、讲座、Workshop 等活动,吸引了世界各地的人工智能从业者参加。当然,众所周知的是,华人是本次大会不可忽视的一支力量。
依照惯例,AAAI 在会议期间评选了一些获奖论文,其中包括两篇杰出论文(Outstanding Paper,其中有一篇学生论文)以及经典论文、鼓励创新研究的 Blue Sky Idea Awards 获奖论文等。
在 AAAI 获奖论文公布之后,机器之心邀请多位技术分析师对这些论文进行了深度解读,为我们分析了这些论文的杰出和创新之处,带我们领略了人工智能和机器学习领域的最前沿的研究成果和思想。以下即为对本届 AAAI 上获奖论文的解读。
AAAI-17 杰出论文奖(Outstanding Paper Award)
论文标题:使用物理学和领域知识的神经网络的无标签监督(Label-Free Supervision of Neural Networks with Physics and Domain Knowledge)

作者:Russell Stewart and Stefano Ermon
关于该奖:AAAI 杰出论文奖获奖论文体现了技术贡献和阐述的最高标准。这个奖通常是将给在计算机科学领域实现了广度和独特性的研究者,这些研究通常构建了不同科系和学科之间的桥梁。
论文解读
本届的杰出论文《Label-Free Supervision of Neural Networks with Physics and Domain Knowledge》的灵感来自于人类的学习过程,其利用了先前的领域知识来将输出空间约束到一个特定的学习结构,而不是简单的从输入到输出的映射。这种做法让该论文不需再使用大量有标签数据来监督神经网络,而是让神经网络学习更见先进的结构。通常来说,当前将不使用标签进行学习方法称为无监督学习(unsupervised learning),比如说自编码器(autoencoder)。无监督学习方法通常是将输入数据聚类(cluster)成不同的分组,这种方法虽然高效,但往往缺乏有意义的解读。与无监督学习相反,通过没有明确标签但有 ground truth 法则的数据进行训练,我们可以得到两点好处:1)花费在标注上的工作量减少,2)通用性提升,因为单一一套约束可以无需重新标注就被应用到多个数据集上。
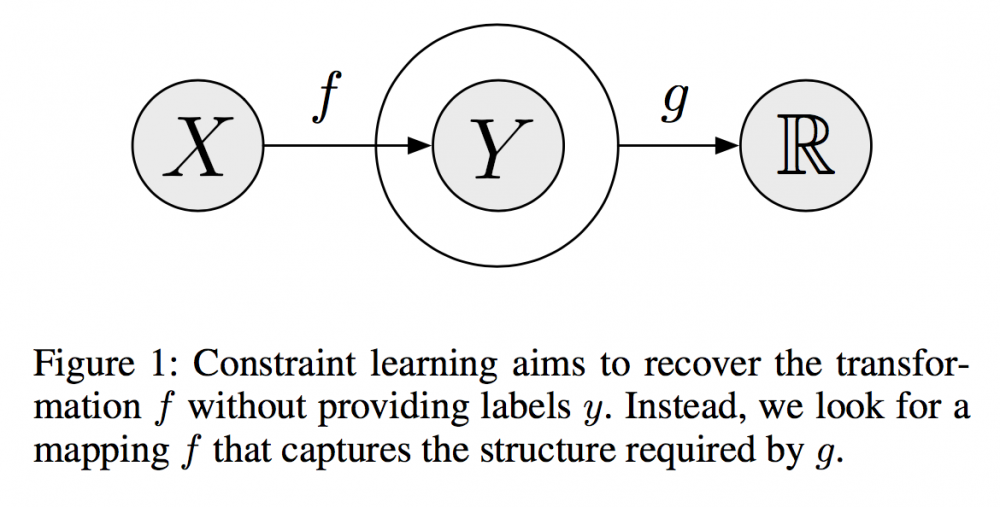
图 1:约束学习的目标是在无需提供标签 y 的情况下恢复变换 f。我们并没有那么做,我们则是寻找一个能够获取 g 所要求的结构的映射 f.
要将先验知识整合进监督学习中,通常有两种方式:1)通过限制能特定假设类 F 的可能函数,2)通过为 F 中的特定函数增加一个 a-prior preference,其对应的正则化(regulation)为 R(f),其中 f 属于 F。
在这篇论文中,作者重点关注了约束函数 g:X*Y 根据先验知识(即物理法则)映射到 R,以在学习过程偏离先验知识时惩罚学习结构——这些先验知识是抽象的高层面思考,而不仅仅是标签。在这个训练场景中,标签 y 仅用于评估,而且其对于发现 f* 属于 F 的最优规则并不是必需的。为了确保收敛以找到正确的 f*,我们也可能需要为监督机器(supervise machine)增加额外的正则化项。这个设计约束函数 g 和正则化项的过程确实是一种监督形式。
该论文提供了三个案例:1)跟踪一个自由落体,2)跟踪一个行人的位置,3)根据因果关系检测目标。
第一个案例遵循最简单的规则——任何物体受到没有重力之外的其它力时都会下落。因此,当一个物体被扔出去后,其运动轨迹毫无疑问是一条抛物线。通过使用这种物理定律的先验知识,我们可以设计一个约束函数迫使神经网络向其收敛。在训练过程中,该数据集包含了 65 个不同的轨迹,共计 602 张图像。使用 Adam 优化器和 0.0001 的学习率,该 CNN 训练了 4000 次迭代。
让人惊讶的是,结果很不错。训练好的神经网络得到了 90.1% 的相关性(correlation),相比而言,在标签上训练好的神经网络的相关性为 94.5%。不使用标签,神经网络仍然实现了出色的输出。
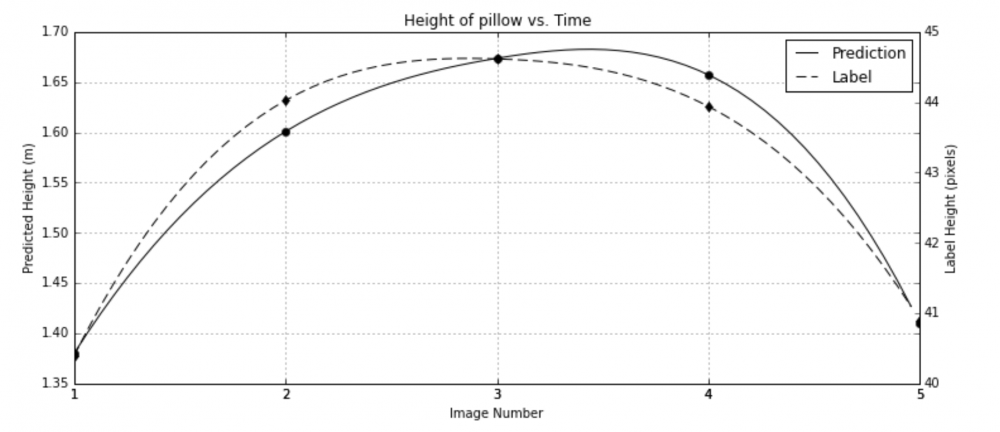
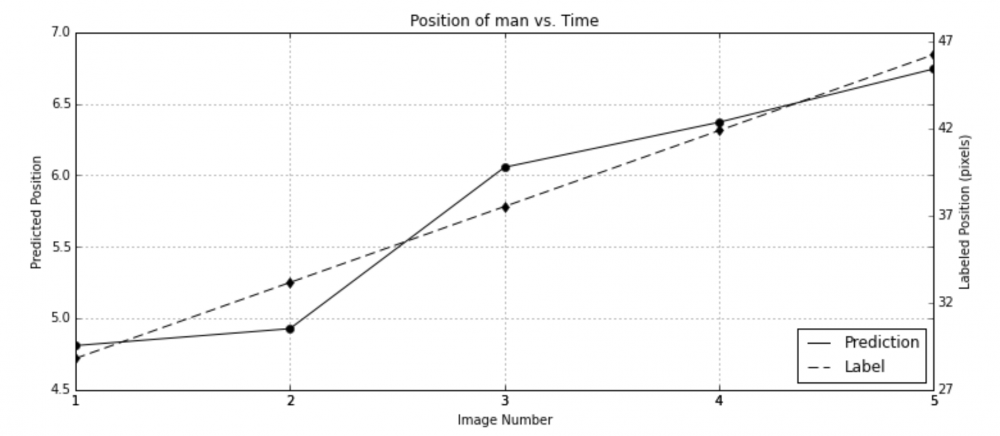
第二个案例和前一个类似,但其约束函数需要修改,因为其有收敛问题。在这个场景中,这个常速假设大约仍然还存在。这两个实验都涉及到运动方程,唯一的区别是第二个实验中没有重力项。如果我们没有明确地防范这种平凡的解决方案,这里的问题是该网络总是可以收敛到一个常量 C。所以我们需要设计正则化项以帮助约束函数 g 以随机化其网络,因此,一个平衡辅助函数(counterbalance helper function)是必需的。在训练过程中,该数据集包含了 6 种不同场景的 11 种不同轨迹,共计 507 图像。而在第一个实验中的超参数也得以保留以体现参数的稳健性。最后的结果是与 ground truth 相关 95.4%。此外,这个模型仍然在测试集(在训练集上 99.8%)上实现了 80.5%。论文作者将性能下降归咎于在小训练数据量(11 轨迹)上的过拟合(overfitting),对于一个得到了良好训练的监督式分类器,可能实现接近完美的相关性。
第三个案例是更一般化,这并不是来自真实世界的现象,而是来自逻辑和基于约束的方法(formalisms)。因此,在第三个实验中,我们从施加在单张图像上的逻辑约束中探索了学习的可能性。该数据集由随机收集的任天堂角色(马里奥、桃子公主、耀西、库巴)组成,其中每个角色都有因旋转和翻转造成的轻微的外观改变。其生成的分布编码了一种基本巧合——即马里奥和桃子公主同时出现的场景(和游戏 Save Peach! 本身一样)。这个神经网络任务是分辨马里奥和桃子公主。我们没有使用直接标签来进行监督,我们通过约束它们的输出到有 y1 到 y2 的逻辑关系来训练网络,其中 y1 表示桃子公主,y2 表示马里奥。在这个设置中,我们总是可以预测 y1 === 1 和 y2 === 1,因为这个规则总是正确的。没有任何惩罚(penalty)和正则化,其输出最终会是决定性的和无意义的(以 ROC 曲线,这个情形对应于:错误检测概率等于 1,同时检测概率也等于 1,这是无意义的)。为了避免这种无价值的解决方案,我们需要更加复杂的正则化项来让网络将重点放到物体的存在而非位置上。在一个有 128 张图像的测试集上,该网络学会了将每张图像映射到一个正确的描述——图像是否包含了桃子公主和马里奥。
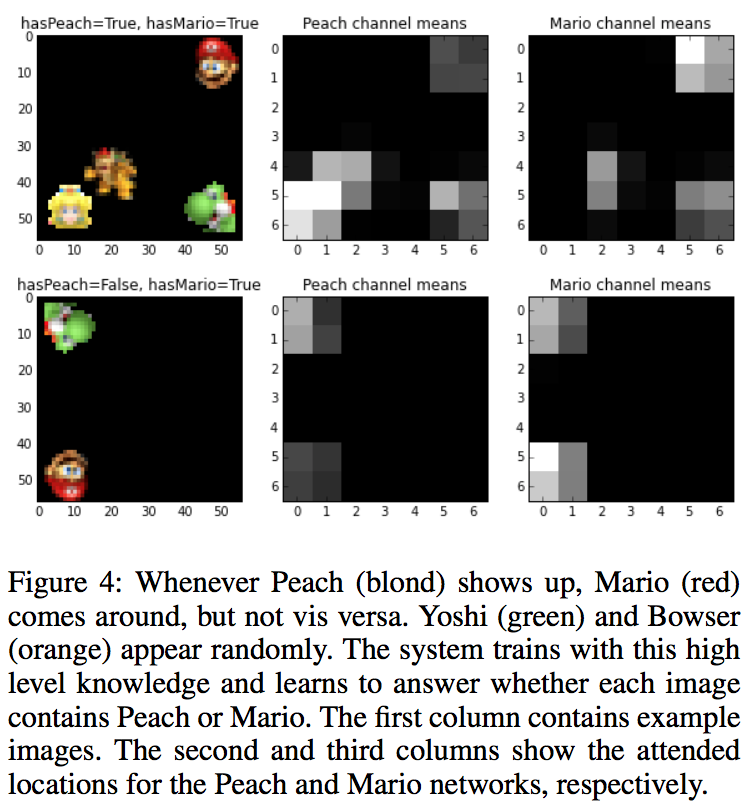
图 4:不管桃子公主(金黄色)什么时候出现,马里奥(红色)就会在附近出现,但反之并不亦然。耀西(绿色)和库巴(橙色)随机出现。该系统使用了这种高层面的知识进行训练并学习了回答每张图片是否包含桃子公主和马里奥。第一列包含了样本图像,第二和三列给出了桃子公主和马里奥网络分别出现的位置。
约束学习是一种监督学习的泛化,允许实现更具创造性的监督方法。而这种新方法是通过以下方式学习的:
利用现代神经网络的表征学习能力;
当主要约束仅仅是必要条件时,添加充分条件。
未来的挑战包括将这些结果扩展到更大型的数据集(其中每张图像都有多个目标)上,以及简化为新的和有趣的问题挑选充分项的过程。通过让操作者免于收集标签,我们的小规模实验表明了未来使用弱监督训练神经网络的潜力。
拓展阅读
-
Convexification of learning from constraints.
https://arxiv.org/abs/1602.06746
-
A method for stochastic optimization.
https://arxiv.org/abs/1412.6980
-
Building high-level features using large scale unsupervised learning. https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/unsupervised_icml2012.pdf
AAAI-17 Blue Sky Idea Award
论文标题:人工智能的道德决策框架(Moral Decision Making Frameworks for Artificial Intelligence)

作者:Vincent Conitzer, Walter Sinnott-Armstrong, Jana Schaich Borg, Yuan Deng, Max Kramer
AAAI-17 Blue Sky Idea 奖授予了论文《Moral Decision Making Frameworks for Artificial Intelligence》
关于该奖:根据 AAAI 的设定,这个奖项是为表彰那些论文中所提出的想法和愿景能够促进研究团体去寻求新的研究方向(如:新问题、新应用领域或新方法)的论文。
现在有越来越多的人工智能系统在帮助我们做决策以及减少类似粗心这样的行为所导致的错误。当我们赋予人工智能系统更多自主性时,我们是否应该为这些人工智能系统或许会做出的伦理视角下的反直觉判断而担忧呢?
在这篇论文中,Conitzer 等人为如何设计具有道德考虑的人工智能系统提供了一个路线图,虽然还处于研究的婴儿期,他们希望在不久之后就能设计出一个通用框架,这个通用框架将支持人工智能系统在面临道德困境时自主做出合理的道德决策。
将道德推理引入人工智能系统是非常必要的,因为人工智能系统需要更多的自主性,当设计一个包含道德的人工智能系统时,应该有一个道德理论来清晰定义下面的内容:
-
哪些行为在道德上是正确的以及哪些行为是错误的;
-
智能体来表达行为结构以及系统在不同情形下做审判时所需要的语言体系,包括行为中与道德相关的特征以及特征如何交互影响道德审判的规则。
-
用以抽象表征道德困境的路线图
一个博弈论方案
博弈论是讨论对同一博弈条件下多个不同利益智能体的场景建模。并且智能体所采取的行动将会导致它们在不同范围内有更好或者更坏的表现,因此博弈论为抽象表征道德困境(moral dilemmas)提供一个潜在的优质备选。
扩展式(extensive forms)是标准的表征体系之一,因此直观的想法是用扩展式来叙述道德困境、展示博弈中的智能体、智能体所采取的行动以及博弈的结果。然而,Conitzer 等人同时指出过分简单化的博弈论解决方案并不能完全顾及道德的各方面考虑,因为博弈论中标准的解决方案将各方限定在预指定的效用实现上。因此,他们指出扩展式需要有延伸,从而支持「博弈的分析与评估一个智能体是否应该追逐另一个智能体的福祉结合在一起。」
论文为对博弈论方案中道德人工智能系统的未来工作开展感兴趣的研究者提供两个研究方向:
-
将博弈的概念泛化到有更多博弈方参与的完美/不完美信息博弈中;(注:完美信息(perfect-information)博弈应该能够给博弈(如国际象棋)中所有博弈方提供当前博弈状态的全局观察,这与不完美信息博弈(如德州扑克)并不是这样。)
-
定义能获取其它道德关注点的其它不同的解决方案概念
扩展式的一个范例:
如果我们(第一个博弈者)不采取任何行动,让一个失控的火车继续前进,那么这列火车将马上撞向第二个博弈方;我们是否应该马上采取行动将火车转到另一个轨道上行驶从而避免第二个博弈者受到伤害,但是转到另一个轨道上会让第三个博弈方的生命处于危险之中。
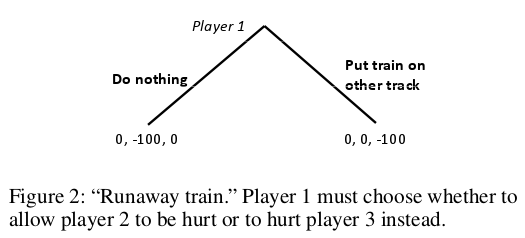
一个机器学习方案
另一个展示道德困境的方式是基于机器学习的。从根本上来说,我们将有一组道德正确的决策作为训练集,这组正确的决策是由人工标注的并交由人工智能系统来归纳。这篇论文里还提到了一些悬而未决的问题:
-
什么是正确的表征?
-
那些特征是重要的?
-
怎样精确构建和标注一个好的训练集?
Conitzer 等人宣称道德困境可以由关键道德特征来表征,构建出一个让人工智能系统自动做出道德抉择的通用框架的主要任务是确定能在不同领域内应用的抽象特征,而不是去寻找只适用于个别情形的某些特定特征。给定一个由特征值表征的道德困境的标注训练集,机器学习的技术能够帮助人工智能系统学会区分智能体的行为是道德正确的还是道德错误的。
除了创建一个行为二分类(要么道德正确,要么道德错误),还可以进一步分析用回归(regression)算法所产生的抉择的道德错误程度;以及例如在贝叶斯框架下,一个抉择在道德错误上的似然性大小,或者把这两个方法结合在一起看看。
道德困境由什么构成?
考虑图 1(来自 Conitzer 等人的论文)中被称为「信任博弈」的例子。
假设在最开始的时候,第一个博弈者(下简称 P1)有 100 美金,而第二个博弈者(下简称 P2)没有任何资金。
如果 P1 决定给出一部分钱,比如说 50 美金,那么这时候 P2 将会收到 3 倍于 P1 给出钱数目的钱,也就是 150 美金。此时,P1 有 50 美金,P2 有 150 美金。
现在如果 P2 想还 P1 一个人情,将 100 美金还给 P1,那么 P1 将只收到 100 美金。这个时候,P1 有 150 美金,而 P2 拥有 50 美金。
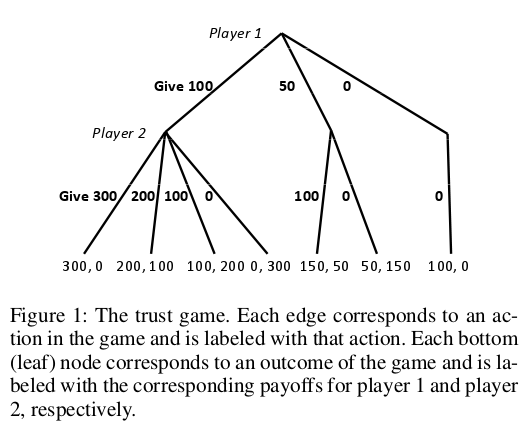
直观的博弈论分析将是这样的,每一个博弈方应该尽最大可能使自己的钱数最大化。P1 和 P2 将很可能把钱留在自己那里而不是给对方。甚至即使收到对方给的钱,仍旧不会给回任何钱以作感激。但是显然人在做决定时不总是只考虑自己的利益。
Conitzer 等人指出「信任博弈(the trust game)」是道德推理的一个普遍特征,即人们会考虑所采取的行为的后果以及行为发生的情形,同时还会考虑他们的行为是否表现出公平、不感恩、不忠诚、不可信任或者理所应当。参与者或者智能体会从未来的影响和过去的影响来评价自己的行为。
显然让所有人都认同哪些道德特征是相关的,或者是解决道德困境的最重要特征。找出每个智能体的道德价值点也许是可行的,抽象表征它们并且在人工智能系统中对其编码。在道德困境中,人工智能系统可能会遵从某个智能体的道德价值(「道德相对主义(moral relativism)的一种」),或者拥有人的道德价值所聚合的社会选择理论,例如,只运用对所有智能体都常见的道德价值。
我们授予了人工智能系统自主权,而这使得人工智能系统在做一些道德上的决策时可能会产生适得其反的效果。所以我们就需要将人工智能系统设计成能制定出更具稳健性和安全决策的系统,并且这个决策绝大多数人都认为是合理的。建立道德体系可能的一个方法就是在必要的时候创建专门的道德规则,但是一般来说,人工智能系统受益于采用跨领域(cross-domain)的方法,在这方面起到关键作用的是预期最大效用,而预期最大效用却又会阻止制定出合理的道德决策。因此,研究者已经在寻求道德人工智能系统的一般道德框架,其中当人工智能系统在学习和理解了道德价值后,道德困境可以用抽象的形式来表示。
然而,道德人工智能系统仍处于起步阶段,我们还有很长的路才能建立一个通用框架,才能使人工智能系统自动地做出道德决策。Conitzer 等人的论文是引人深思的,该论文提供了表征人工智能系统中道德困境的两个范例,即带有道德决策成分的博弈论方法和使用人工标注案例的机器学习方法,另外这两种方式是潜在的互补范式。可能还存在建立道德人工智能系统的其它范式,但是 Conitzer 和他的同事肯定会给我们带来道德人工智能系统方面上的进步。
扩展阅读
Joshua Letchford, Vincent Conitzer, and Kamal Jain. An ethical game-theoretic solution concept for two-player
perfect-information games. In Proceedings of the Fourth Workshop on Internet and Network Economics (WINE), pages 696–707, Shanghai, China, 2008.
Michael Anderson and Susan Leigh Anderson. Machine ethics: Creating an ethical intelligent agent.
AI Magazine, 28(4):15–26, 2007.
Nick Bostrom and Eliezer Yudkowsky. The ethics of artificial intelligence. In W. Ramsey and K. Frankish, editors,
Cambridge Handbook of Artificial Intelligence. Cambridge University Press, 2014.
Swarat Chaudhuri and Moshe Vardi. Reasoning about machine ethics, 2014. In Principles of Programming Languages (POPL) - Off the Beaten Track (OBT).
James H. Moor. The nature, importance, and difficulty of machine ethics. IEEE Intelligent Systems, 21(4):18–21, 2006.
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

