专访大象声科汪德亮:利用深度学习解决「鸡尾酒会问题 」
近些年,随着深度学习的兴起,人工智能已经学会了下围棋、玩视频游戏、识别人脸、做翻译、驾驶汽车……甚至在德州扑克这种非完美博弈中也开始崭露头角。但事实上,变化不止于此,在语音增强方面,深度学习技术正推动「鸡尾酒会问题」的解决。
俄亥俄州立大学终身教授汪德亮(DeLiang Wang)是全球第一个将深度学习应用于语音增强的科学家。

汪德亮教授是俄亥俄州立大学感知与神经动力学实验室的主任、校杰出学者、IEEE Fellow、顶级期刊 Neural Networks 主编,主要致力于机器感知和信号处理领域的研究,在听视觉处理的神经计算研究方面开展了多项研究工作,并取得了很多重大成果。他建立了振荡相关理论,在听视觉分析中得到了广泛应用,还开创性地提出了计算听觉场景分析理论与算法,为解决听觉领域中著名的「鸡尾酒会问题」提供了全新的研究思路和方向。前段时间,他在 IEEE Spectrum 上发文详细介绍了其团队在语音增强深度学习技术上的研究进展。
汪德亮以联合创始人兼首席科学家身份加入创业公司「大象声科」,该公司于最近在深圳成立,专注于深度学习在语音增强领域的应用开发,通过声音信号处理技术为企业提供全面的远场语音增强方案。目前大象声科涉及的领域包括会议转录、通讯、机器人、智能家居、虚拟现实、增强现实和混合现实等。
机器之心近日对汪德亮进行了一次专访,以下是专访内容的整理:
机器之心:您是计算听觉场景分析(CASA/computational auditory scene analysis)的主要贡献者之一,您能为我们简单介绍一下 CASA 相关的技术以及您的研究团队的工作吗?
汪德亮:CASA 主要关注的领域是声源分离。这里的声源不单是指人的声音,也可能是其它各种声音(比如街上汽车和救护车的声音)——这些都是声源。声源分离的目标就是将这些声音分离开。针对这一问题的早期解决方式是通过统计的方法把声音里面的统计特性提取出来; 计算听觉场景分析则在很大程度上是对人的听觉特性的模拟。
尽管现在人工智能已经很强大了,但在很多方面人的智能还是比机器智能强很多,尤其是在鲁棒性方面。也就是说,对于有一个同样答案的数据,如果其中有一些变化的话,对机器来说会是很大的困难,但对人来说却没有什么影响。CASA 这个领域很大程度上基于听觉场景分析(ASA/auditory scene analysis)。ASA 是心理听觉(psychoacoustics)的一个研究领域,这是心理学和听觉的交叉领域。其中最有名的问题叫做「鸡尾酒会问题(cocktail party problem)」;而人能够解决鸡尾酒会问题。
鸡尾酒会问题是什么呢?这首先是由一位著名心理学家 Colin Cherry 提出的,他当时研究的是注意机制(attention mechanism),你能在很多的相关书籍中看到他的名字,在历史上的地位非常显赫。当时他在他那本 1957 的书《On Human Communication》里面说道:到目前为止,还没有哪个机器算法能够解决鸡尾酒会问题。这之后鸡尾酒会问题就为人所知了。要解决鸡尾酒会问题,就需要能够达到人类的听觉性能水平。后来麦吉尔大学的教授 Albert Bregman 在 90 年代写了一本巨著——《听觉场景分析(Auditory Scene Analysis)》,这本书对计算领域的影响还是很大的。Bregman 本身是一位心理学家,不管计算问题。他思考的是:人是通过怎样一种心理学机制和生物学机制来达到能够解决鸡尾酒会问题的性能的(当然到目前我们也还并不完全了解人是怎么做到的)。但是他在他的那本书里面提出了一个理论——听觉场景分析理论。后来他这个理论被引入了计算领域,人们就思考怎么可以把人解决鸡尾酒会问题的机制变成算法用到机器上,让机器能够达到解决鸡尾酒会问题的性能,从而回答 Cherry 在很多年前最开始提出的那个挑战。
CASA 这个领域又是怎么由来的呢?Bregman 的那本书是 1990 年发表的,而 CASA 领域最早的工作是 1985 年斯坦福大学的一篇博士论文;这项研究启动的时间比那本书还早 (但也受到了 Bregman 影响)。计算听觉场景分析这个领域就从那个时候开始形成。

一个街道上的听觉场景,图片来自 IEEE Spectrum
对于我们这个团队呢——我是从神经网络这个领域切进去的,而他们是从电子电气和信号处理那些领域切进去的——我们的进入方向不一样。我进入的时间也比较早——从 90 年代初就进入了。我在早期的时候研究的是神经动力学,比如大脑里的振荡器。后来我转向了这个方向,在这个过程中 Bregman 的那本书对我的影响非常大。但那时候做这个领域研究的人还不多,我可以说是 CASA 这个领域的主要代表人物之一。后来 CASA 的影响力开始慢慢变大。
我们也第一次把 CASA 和后来的深度学习结合了起来,也就是说把鸡尾酒会问题变成了一个机器学习问题。早期的时候,我是通过神经动力学来做声源分离的。但现在我们把鸡尾酒会问题变成了一个分类问题,源于我们称之为「理想二值模(Ideal Binary Mask)」。这是我们实验室提出的一个很重要的概念。我们就想:什么叫解决了鸡尾酒会问题?也就是说,如果把一个听觉信号在时间域和频率域两个维度(时频二维)进行表示(类似于视觉信号的 x 轴和 y 轴两个维度),你就可以把时频这二维表示成一个二维矩阵,这个矩阵中的每一个元素称为一个「时频元(time-frequency unit)」。我们开始研究的就是怎么量化这个时频元,后来我们发现这个量化只要二值就可以了——要么是 0 要么就是 1。这跟传统的声源处理方法是完全不一样的。传统的声源处理要把信号分得很细。一个信号里面可能有很多的组成部分——一个部分属于这个声源,另一个部分属于另一个声源。我们的方法就不需要分那么细,就只需要分一次——要么属于目标声源,要么就是背景噪声。这就是「二值」的意思。这样我们就把 CASA 问题变成了一个监督学习(supervised learning)问题;相对地,早期方法则是无监督的(unsupervised)——也就是说把一个信号的权值算一算,而不需要教它。我们从理想二值模的角度考虑,就把它变成了一个分类问题。
分类是监督学习领域里面一个最基本的任务。我讲课的时候常常这样比喻:对于一个水果——它是橘子还是苹果?二值就是这个意思——要么是橘子,要么就是苹果。如果最开始你让一个不认识它们的小孩去猜,猜错了之后他妈妈会告诉他错了,最多几次之后这个小孩就能自然地知道该怎么区分了。机器学习也就是这样,我在讲课的时候常常将它比作是「Apple & Orange Problem」。当你把它变成了一个二值模问题之后,这就很自然地变成了一个「Apple & Orange Problem」,也就成了一个分类问题了,之后该怎么做就变得明朗了。
确定了问题之后,接下来就是确定用什么学习模型去做,这就是具体的技术问题了。
为什么我们实验室在声源分离这方面一直处于领先呢?因为是我们最早提出把声源问题变成一个监督学习问题的。最早用过多层感知器(Multi-layer perceptron)、混合高斯模型(Gaussian Mixture Model)等等。因为这是一个全新的思路——原来是一个信号处理问题,现在变成了一个学习问题——而我们一直是领先在做,所以我们也一直处于领先的状态。深度学习出来之后,我们也是最早把深度学习应用到这一领域的。当我们把它变成了一个深度学习问题之后,剩下的就是具体的技术问题了。将来(也许五年之后),也许深度神经网络又比不上一种新出现的学习模型了。我们会照样进行研究,因为我们已经有了概念上的突破。学习模型之间性能当然是有差别的,所以采用更好的模型也是理所当然。而将这个问题变成一个学习问题才是更大的概念上的突破。
所以简单总结一下,CASA 就是基于人的听觉原理来做声源分离,我们实验室的最大贡献是第一次将这个问题变成了一个监督学习问题。
机器之心:您前段时间在 IEEE Spectrum 上面发表了一篇用深度学习变革助听器的文章《Deep Learning Reinvents the Hearing Aid》,谈了您对听觉增强技术的研究工作,尤其是声音分离技术。请您简单介绍一下深度学习是如何将噪声和我们想要的声音分离开的。其中最大的难点是什么?
汪德亮:一旦把它变成了一个监督学习问题之后,我们就希望学习机的分类结果和理想二值模的分类是一样的。理想二值模是「理想的」,是在声音没有重叠之前计算出来的,就是说不管噪声比目标声音强多少倍,它都能将目标声音分离出来。尽管是二值的,但是功效非常之大。
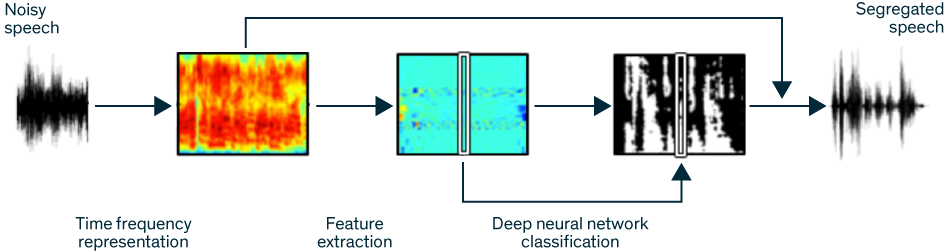
深度学习声音分离技术的流程,图片来自 IEEE Spectrum
其中的难点就在怎么通过学习的方式来不断地提高精度,让它不断接近理想二值模。其中最大的难点?我想所有的监督学习都一样,就是说:我们可以怎样在数据有限的条件下学习到足够好的模型,并且可以推广到新的场景。我们谈的计算听觉场景分析就是要在所有的场景中都达到能够实用的要求——因为也许它大部分场景都见过,但有的场景却从没碰到过。这就类似于早期时候的自动驾驶汽车在雪地里没法行驶,因为它从来没有在雪地里行驶的数据,之后有了这方面的训练数据之后,自动驾驶汽车就能应对雪地了。这就是一个数据问题。而现在这个难点我们已经走过了,「突破」就是这个意思——就是说以前人们百思不得其解的东西,现在已经有了方向,接下来就开始加速发展了。
机器之心:就是说现在技术已经有了,现在最大的难点是在数据上?
汪德亮:对,数据是个问题,还有就是训练过程。目前深度学习代表着最现代的一种方法,但我们还不清楚它究竟能走多远、能不能最终完全解决鸡尾酒会问题。不过我是持乐观态度的。因为我们也可以从其它领域看到深度学习的好处,像是汽车驾驶、机器翻译、图像识别,甚至还有可以谱曲的模型了。声源分离问题也可以被看作是这个大潮流的一部分。
机器之心:刚才您提到早期的方法是无监督的,而我们现在用的机器学习/深度学习方法是有监督的,但也有一些学者认为未来的发展方向是无监督的学习,因为这样可以实现更强的自主智能?您怎么看?
汪德亮:无监督或有监督只是具体的方法,有的无监督方法也可以变成有监督的方法。学习大概可以分为三类:无监督学习、有监督学习和强化学习。最近下围棋的程序就用到了强化学习,但基本上可以把它看作是有监督学习,但是它的学习信号非常少。学习究竟具体使用了什么算法我觉得倒不是很重要,重要的是我们的目标要非常明确——就是要解决鸡尾酒会问题。
鸡尾酒会问题的答案有两种定义方式,一种是要让算法在现实场景中语音识别上达到人类的水平,另一种是算法能够帮助有听觉障碍的人能够像正常人一样在现实场景中听懂语音。视力不好的人一般戴上眼镜问题就解决了,助听器则不是这么回事,远未达到眼镜的水平。所以有监督还是无监督都会有,这并不重要,重要的是要能够达到解决鸡尾酒会问题的目标。
机器之心:在这篇文章最后,您也谈到了这项技术正在进行商业化的过程中,那么我们大概什么时候能在市面上见到深度学习助听器产品?
汪德亮:这个还需要一点时间。你想要完全采纳这个技术,对现有的技术就是一种颠覆。传统的方法是通过信号处理的方式把信号分成各个频段,然后对这些频段的信息进行分析,看应该对这些频段进行放大还是缩小;而现在我们是通过学习的方式来做。而要把它放进实际的助听器中,有实时性方面的问题,需要把器件做得足够小,而且还需要助听器厂商的配合;所以我觉得正式上市还需要几年的时间。
机器之心:那么你们的技术现在在时延方面的表现如何?
汪德亮:我们目前还没有很关注时延方面的问题。因为我们觉得在性能上还需要提高,要让这个技术在各种场景下都能够行之有效。现在只能做到在一些场景或很多场景下有效,但还不能做到在所有的场景都有效。所以时延的问题我们还没有太关注,但将来做商业规划的时候时延就非常重要了。
当然反过来讲,神经网络的好处在于能把整个任务分成两个部分。一个部分是训练,这个部分可以不用在乎用什么来做训练,CPU 或 GPU 都可以,训练多长时间都没关系。比如说谷歌的 ASR 可以训练六个月时间,但运行时的时延就很短了,可以达到几秒钟。这个概念和传统的方法有区别,传统的方法是把这两个过程放到一起。神经网络的方法把它分成训练过程和使用过程,训练完了之后可以得到一个单独的实用模型;只要这个模型不是特别大,使用时其实用不着很大的计算量。慢的地方主要还是在训练阶段。另外,训练完之后的模型还可以进一步简化。
机器之心:如果噪声的音量远比我们想要的声音的音量大,模型也可以正确的识别吗?
汪德亮:可以。我们的 demo 现在已经可以做到 -8 分贝了。0 分贝就是说两个声音一样强,-8 分贝就是说噪音比目标声音高 8 个分贝。在这种比例下,你几乎听不到人说话的声音,但模型还是能分离和识别。因为模型是看它的特征,在训练过程中它已经学会怎么做了,在处理的时候它不需要管噪音有多大,它只要发现声音中有特征和训练时学习的特征接近,它就能将目标音分离出来。所以这倒不是一个大问题。
机器之心:我们知道深度学习对计算性能和在功耗上的要求还是比较高的,而老人佩戴的助听器这样的便携式设备基本上无法提供这样的性能或功率支持,这个问题有可能通过什么方法来解决?
汪德亮:这个不难解决,就像我们刚才讲的,深度学习的训练和使用可以分开,助听器里面可以只用训练好的模型。现在比较好的助听器是几千美元一只,这些助听器也是需要进行「训练」的,首先是试戴,之后还会发现这个频段需要调或那个频段需要调,需要拿到卖助听器的地方去调节。训练本身就是这样一个调节的过程。功耗、大规模数据、训练时间这些成本都主要体现在训练过程中,训练完成之后这些问题就不存在了。
机器之心:您的研究经历中也有关于图像分割(image segmentation)的成果,图像分割和语音分离(speech segregation)在技术上有哪些相同点和不同点?
汪德亮:最大的不同点是:声音信号是叠加的,即多个声音信号加在一起;而视觉信号则不是相加的,而是遮挡(occlusion)的,即前面的物体把后面的物体挡住。
人的五官很有意思。我一直在研究人的感知觉。人为什么有五官呢?我们知道外界世界是同一个物理世界,而五官则是通过物体的五种不同类型的属性来对外界进行分析,比如视觉上是通过亮度、颜色等等特征,而听觉上则是通过声音的振幅、频率之类的特征。听觉有一些视觉做不到的地方,比如你就算睡着了,你的耳朵照样还在观察四方,你也可以听见隔壁或房间外面的声音,而通过视觉的话你就会被墙遮挡。当然在光线比较好的地方,视觉的精度要比听觉的精度高。但是,总的来说它们是一种互补的关系。
前面我们也讲了,还有一个不同之处是:声音是时间维和频率维两个维度,图像则是横轴和纵轴两个维度。图像的两个维度基本是对称的,而声音的两个维度则很不同。我们还可以给图像加第三维的深度信息。声音也可以加深度信息。
而它们之间的共同之处也非常多。理想二值模就是把这个问题变成二值的,就像前面的东西会把后面的东西给挡住一样,强的声音把弱的声音给掩蔽掉。其中的概念在某种程度上受到了之前的在视觉上的工作的影响。在视觉上做 segmentation 的时候,我们可以很自然地根据像素归属于某个物体很容易地将其分开——要么属于该物体,要么就不属于。这个二值概念对我们提出听觉上的理想二值模是有启发的。
所以它们既有共同之处,也有不同之处。
机器之心:有可能使用同一个模型同时完成这两种功能吗?
汪德亮:现在有一个叫做 audiovisual 的领域,它既有「视」的通道,也有「听」的通道。我觉得它们之间的互补性大于它们之间的重叠性,也就是说当我们把 audiovisual 做在一起的时候,它们之间会有一些重叠的部分;也就是说视觉很不错、听觉也很不错,两者可以互相支持。但很多情况下,只能靠视觉模型、或听觉模型。当然我们也确实可以把它们做进同一个模型。
机器之心:这和迁移学习有什么联系吗?
汪德亮:迁移不太一样。迁移(transfer)是把在一个方面做得已经很不错的模型迁移到类似的一个任务上去,而 audiovisual 是把两种模型合在一起做。也就是说,对于一个物体(object),audiovisual 并不把它作为一个视觉的物体,也不把它作为一个听觉的物体,而是一个视觉和听觉整合的物体,也就是把这个物体的信息通过两个不同的渠道进行获取,而这两个渠道的信息有互补,效果会比仅使用一个渠道的要好。
而迁移学习是把已经训练好的模型进行少许改进后应用到类似的任务上,这样让我们可以在新的任务不用完全从头开始训练。
机器之心:2016 年是深度学习/神经网络大突破的一年,翻译、语音识别等等许多领域都取得了里程碑成果,您能预测一下 2017 年这一领域的发展吗?
汪德亮:这是一个很大的问题。大数据量、大计算量是现在的大潮流。现在人工智能基本上已经冲击到各个领域了,包括前面讲的语音增强,语音识别、自然语言理解、视觉、机器人、自动驾驶等等。其中关键的问题是我们能不能把一个问题变成监督学习的问题。我 16 年 9 月份在做一个大会报告后有不少人问我:之前很多年我们都没有这么考虑过,现在应该怎么办?我就说:其实也不难,上一门神经网络的课就行了。而最关键的还是要把你的问题变成一个监督学习的问题。这和过去是一种完全不同的思路。我们现在看到很多很有说服力的成功例子,这将吸引大量的人将原来用传统方法解决的问题变成学习问题来做。
对于 17 年的深度学习领域,我觉得首先毫无疑问它将渗透到更多的领域里面并且推进这些领域的发展,而且我相信会是大幅度的推进。
另外我觉得在神经网络研究本身上也会有进展。因为神经网络/学习模型可以说是一种工具,其本身也还是有很多工作要做的。深度学习开始出来的时候,人们最看好的是应用领域。看起来好像没有什么理论上的突破。我觉得这种说法有一点太挑剔了。我认为今后网络体系的发展会越来越多样化,会有新的模型、新的架构出来。除了多样化之外,网络还可能会更加细分,也就是说对于不同的任务,有效网络的结构可能会不一样,这和现在网络结构都大同小异的情况不一样——以前全是单向网络(feedforward network),后来加入了循环网络(recurrent network)、LSTM 等等,一个潮流推动一个潮流。最近大家都一窝蜂地去做 LSTM。我认为以后不同的任务和任务的不同特征也会反映到网络的结构上。比如说,大家都是循环网络,但是做语音的循环网络和做视觉的循环网络应该不太一样。我认为随着做的人越来越多,其结构也会不断细化,最后每一个领域(domain)可能有自己特定结构的网络。我认为 2017 年这一趋势还将继续,这一领域还将继续发展。
正文到此结束
热门推荐










相关文章

近期评论
-
666 666
-
666
-
文章和留言都翻到11页了 没有OOM
-
-
朋友,翻页到11页,及以后,会出现OOM,无法访问
-
-
-
-
版本号是多少,你可以下载哪个代码仓库,jdk选1.8 直接跑就行
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

