记一次kubernetes网络调试
过了年leetcode的用户量渐渐起来了,1台服务器已经有点吃力,当高峰的时候经常有些请求超时。而且为了防止服务器的单点问题,需要部署多个replica以保证高可用性。之前的架构已经是在kubernetes集群上了,因此扩容相对而言比较容易。整个webserver的架构如下图所示:
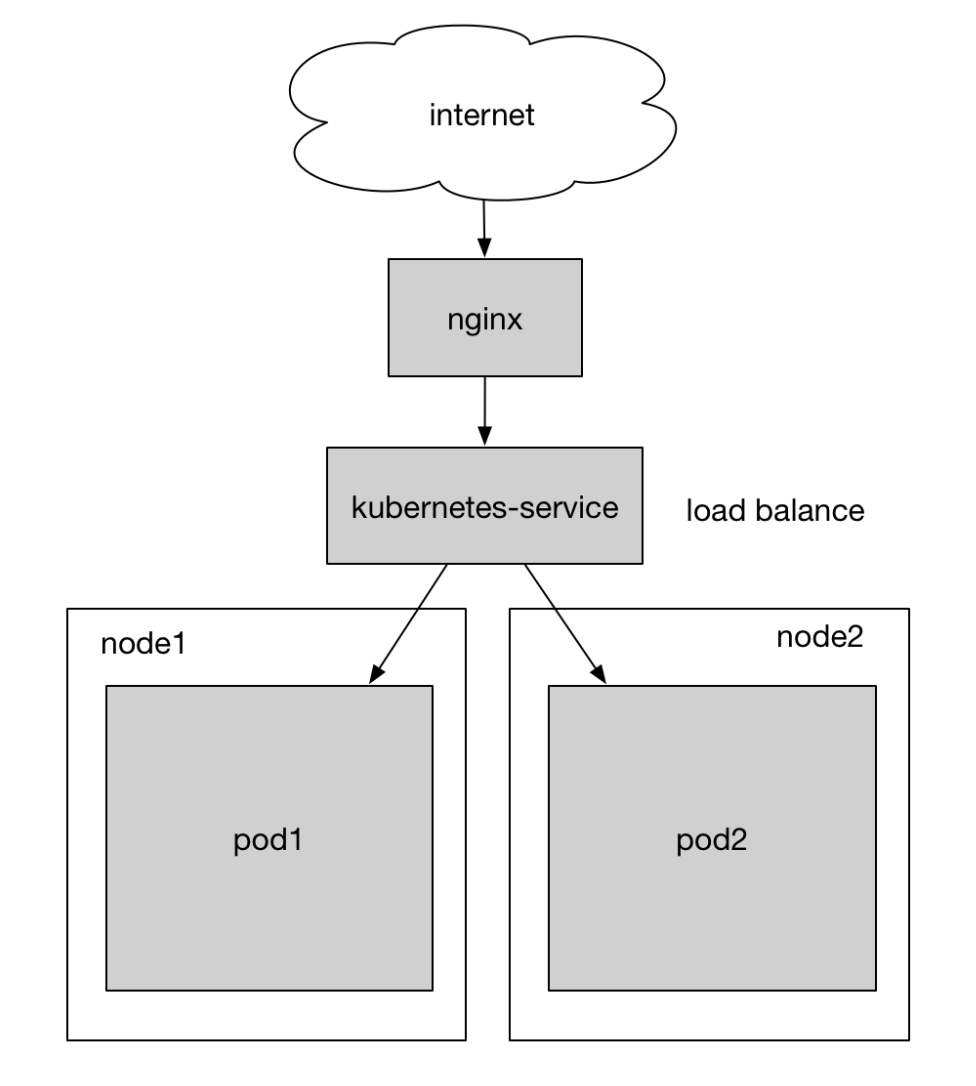
- nginx作为反向代理监听互联网的请求
- 对于leetcode.com的访问转发到kubernetes service
- 通过label将service与pod绑定,并在service层作负载均衡
两个pod分布在不同的机器上,其中pod2所在的机器是为了这次的扩容而部署的。关于如何在已有的集群中增加机器,可以参考我这篇文章。当然手动部署可能不是最方便的,如果想要自动部署,可以去看看关于 kubeadm 的相关资料。
遇到的问题
当一切准备就绪并导流的时候,旧机器的log在不断地输出,说明工作正常,但新机器的日志文件没有滚动,请求一个也没有进来。检查pod的状态,发现它是一切正常的:
[root@kubernetes-slave-2 ~]# kubectl get pod --namespace=noj NAME READY STATUS RESTARTS AGE noj-rc-i3aca 1/1 Running 0 2h noj-rc-vgb5e 1/1 Running 0 2h
而且, noj-rc-vgb5e 这个pod也是顺利被分配到slave2并启动的。这说明 kubelet 和 kube-proxy 的配置没有问题,不然是无法收到master机器的调度请求从而部署pod的。因此首先怀疑 两台机器网络状态是否不一致 。
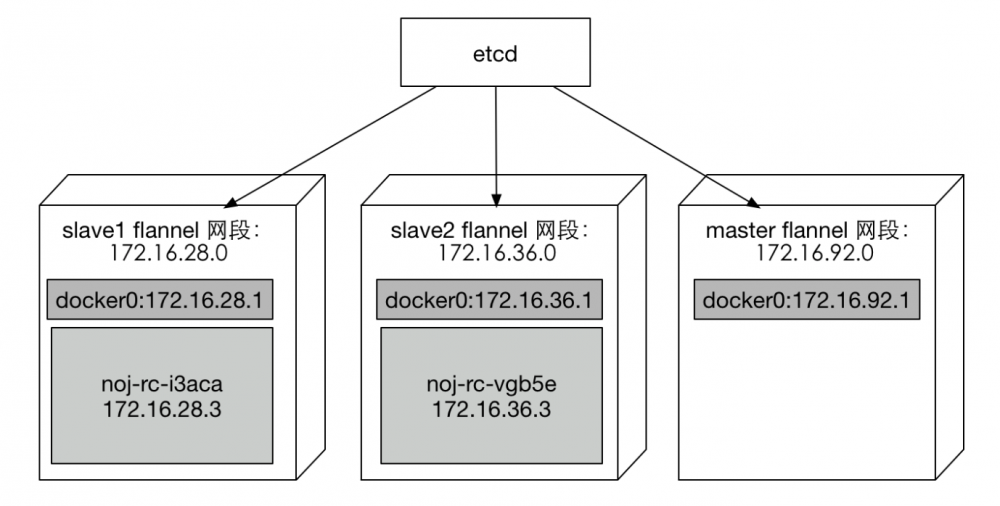
在slave2执行 systemctl stop firewalld ,请求陆陆续续地进来了。因此应该就是iptables配置的问题,某些规则配置错误,导致网络包被reject了。在debug之前先贴上网络结构图方便之后说明。
调试纠错
step1
由于kubernetes集群的iptables规则较为复杂,执行 iptables -L -n 和 iptables -L -n -t nat 发现有上百条记录,对于一条条比对的任务就望而却步了,粗略看了一下一模一样,就连行数都是一样的。
[root@kubernetes-slave-2 ~]# iptables -L -n | grep -c '' 135 [root@kubernetes-slave-2 ~]# iptables -L -n -t nat| grep -c '' 174
[root@kubernetes-slave-1]# iptables -L -n | grep -c '' 135 [root@kubernetes-slave-1]# iptables -L -n -t nat| grep -c '' 174
这就让我犯难了 :既然两台机器的网络环境都一模一样,为什么请求一台能进去,一台进不去呢?
step2
我们现在知道的症状有限,还有没有别的可供参考呢?找找其它症状吧。
进入slave1的container:
[root@kubernetes-slave-1]# kubectl exec -it noj-rc-i3aca bash --namespace=noj root@noj-rc-i3aca:/leetcode/noj# nslookup google.com Server: 10.254.0.10 Address: 10.254.0.10#53 Non-authoritative answer: Name: google.com Address: 216.58.194.174
进入slave2的container(其中nslookup的过程花了很久,大约2-3秒):
[root@kubernetes-slave-2]# kubectl exec -it noj-rc-vgb5e bash --namespace=noj root@noj-rc-vgb5e:/leetcode/noj# nslookup google.com Server: 8.8.8.8 Address: 8.8.8.8#53 Non-authoritative answer: Name: google.com Address: 216.58.194.174
在kubernetes集群中,我部署了dns服务在 10.254.0.10 ,slave2确实将 10.254.0.10 配置为首选dns服务器,但是slave2并没有使用它或者访问不到它。
root@noj-rc-vgb5e:/leetcode/noj# cat /etc/resolv.conf search noj.svc.cluster.local svc.cluster.local cluster.local nameserver 10.254.0.10 nameserver 8.8.8.8 nameserver 8.8.4.4 options ndots:5
这也就解释了为什么在slave2执行nslookup那么慢的原因: 10.254.0.10 失败了,再选择 8.8.8.8 。
step3
slave2访问集群内部服务失败,它是不是也无法跨机器ping通docker呢。
在slave1上ping master
[root@kubernetes-slave-1]# ping 172.16.92.1 PING 172.16.92.1 (172.16.92.1) 56(84) bytes of data. 64 bytes from 172.16.92.1: icmp_seq=1 ttl=64 time=2.71 ms 64 bytes from 172.16.92.1: icmp_seq=2 ttl=64 time=2.18 ms
[root@kubernetes-slave-2 ~]# ping 172.16.92.1 PING 172.16.92.1 (172.16.92.1) 56(84) bytes of data. --- 172.16.92.1 ping statistics --- 5 packets transmitted, 0 received, 100% packet loss, time 3999ms
step4
既然关闭防火墙是可以服务的,那我们一步步在防火墙中添加ACCEPT记录,看看究竟是哪条记录导致网络包被REJECT了。
[root@kubernetes-slave-2 ~]# iptables -I INPUT 1 -j ACCEPT
非常幸运,在INPUT链添加ACCEPT规则后,一切请求马上都正常了,包括step3中的ping也可以正常服务了。
删掉刚才添加的ACCEPT规则,并在iptables中打日志,看看 ping 172.168.92.1 的时候会有那些日志进来:
[root@kubernetes-slave-2 ~]# iptables -I INPUT 1 -j LOG
tail -f /var/log/messages ,我发现有以下的包在slave1是可以顺利通过防火墙的,但在slave2被拒绝了:
Feb 11 08:18:03 kubernetes-slave-2 kernel: IN=eth0 OUT= MAC=5a:e9:b7:d6:88:8d:30:7c:5e:91:9c:30:08:00 SRC=<ip of master> DST=<ip of slave2> LEN=134 TOS=0x00 PREC=0x00 TTL=60 ID=16426 PROTO=UDP SPT=56731 DPT=8472 LEN=114 Feb 11 08:18:04 kubernetes-slave-2 kernel: IN=eth0 OUT= MAC=5a:e9:b7:d6:88:8d:30:7c:5e:91:9c:30:08:00 SRC=<ip of master> DST=<ip of slave2> LEN=134 TOS=0x00 PREC=0x00 TTL=60 ID=16426 PROTO=UDP SPT=56731 DPT=8472 LEN=114 Feb 11 08:18:05 kubernetes-slave-2 kernel: IN=eth0 OUT= MAC=5a:e9:b7:d6:88:8d:30:7c:5e:91:9c:30:08:00 SRC=<ip of master> DST=<ip of slave2> LEN=134 TOS=0x00 PREC=0x00 TTL=60 ID=16426 PROTO=UDP SPT=56731 DPT=8472 LEN=114
注意到8472端口,这个端口是vxlan用于广播数据报文用的端口,vxlan是flannel底层用于跨机器通信用的。我明明记得配置kubernetes机器的时候对这个端口开了白名单呀:
[root@kubernetes-slave-1 ~]# iptables -L -n | grep 8472 ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:8472 ctstate NEW [root@kubernetes-slave-2 ~]# iptables -L -n | grep 8472 ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:8472 ctstate NEW
这个时候我终于发现问题了,当时给8472开的白名单误写成了tcp,然而vxlan使用的是udp!!!
最后,两条命令解决问题,终于一切都正常了!
firewall-cmd --zone=public --add-port=8472/udp --permanent systemctl restart firewalld
总结
一个非常小的错误,导致这一通排查花了我一整天的时间,还是应该多仔细啊。在排查的过程中,其实我也走了一些弯路,刚开始我就确定是网络配置的问题,step2和step3其实都是没有必要的。如果刚开始就直接在iptables中打日志,就可以更快的发现这个问题。因为事后证明新发现的症状对于最后的debug并没有太大的帮助。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

