基于规则和检索的聊天机器人引擎
雷锋网按:本文作者王海良,呤呤英语开发总监,北京JavaScript/Node.js开发者社区的运营者,曾就职IBM创新中心。本文为系列文章第二篇,由雷锋网 (公众号:雷锋网) 独家首发。
第一篇传送门: 《 聊天机器人的发展状况与分类 》 。 在上一篇文章中,介绍了聊天机器人目前的发展。本篇主要介绍基于规则的,检索的聊天机器人引擎 - Bot Engine.
问题域
Speech to Text => Logic => Text to Speech
STT和TTS,目前有很多厂商提供技术产品:
-
Speech to Text语音识别技术
Google Cloud Platform, IBM Watson API, 云知声,科大讯飞
-
Text to Speech 语音合成技术
IBM Watson API Docs demo
经过多年的研究,尤其是深度学习的采用,在这两项技术上取得了突破性进展。今天本文所要讨论的是logic,而且是基于规则引擎的logic, 基于机器学习的部分将在以后的文章中讨论。
Conversation Model
在两个人之间的对话,可以用下面这个模型表示,双方头脑中所要向对方表达的目标,需要通过语言来交换意见,为了达成共识,二者需要在一个语境下。
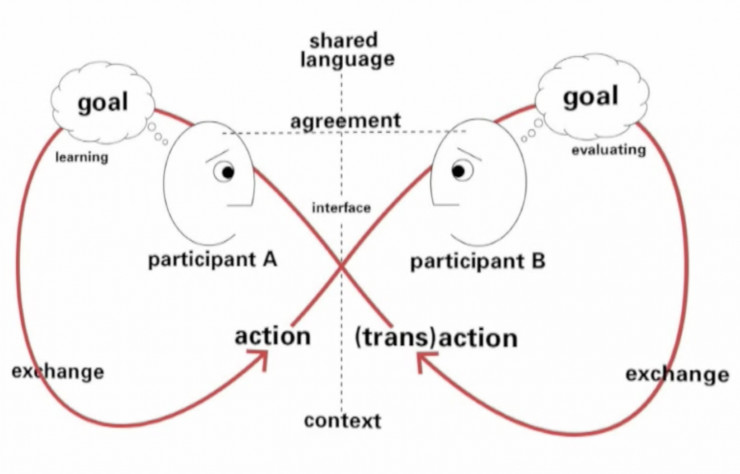
为了支撑这个模型,在设计Bot Engine过程中,要考虑如下的要点:
-
低成本的构建对话
-
能区分不同类型的对话
-
规范化输入
-
高效率的规则引擎
-
用户画像
-
回复时,考虑对话的历史记录
低成本的构建对话
构建聊天内容最好是不需要有开发技能,而且有的开发者也没有很好的聊天的技能。即便像Botframework这样的大厂的产品,在构建对话时,都不够友好,只能面向有开发技能的人,而且是一种硬编码。这样对于维护对话很不利。
-
使用Botframework的waterfall,设计对话的人需要了解builder.Prompts接口和session.beginDialog|endDialog。这样做很不合理。
exports.start = [(session, arg, next) => {
builder.Prompts.text(session, "Do you want to start Class now?");
}, (session, results) => {
co(function*() {
return yield watson.sentiment(results.response);
}).then(function(o) {
let reply;
switch (o.docSentiment.type.toLowerCase()) {
case 'positive':
reply = '_begin_';
break;
case 'negative':
reply = "Got it."
break;
case 'neutral':
reply = "Ok, then.";
break;
}
if (reply == '_begin_') {
session.beginDialog('/daily_lessons/vocabulary');
} else {
builder.Prompts.text(session, reply);
session.endDialog();
}
});
}];
而另外一方面,使用script的方式,显得更合理,比如SuperScript.
+ Do you want to start Class now?
- start_class
+ ~yes
% Do you want to start Class now
- Great, ^redirectTo(/daily_lessons/vocabulary)
+ ~no
% Do you want to start Class now
- Ok, then.
还有 rivescript , chatscript , 同样类似于superscript方式进行构建对话。
能区分不同类型的对话
设计对话时,至少有三种类型的对话:
-
system
系统对话,只能聊一次,或者只能由系统主动发出。比如自我介绍,bot和小明进行初次对话,bot会问:“你叫什么名字?”。小明回答“小明”。那么bot就知道"id:xxx"是小明。而将来bot都不应该再问这个问题。
-
daily
这些是bot可以重复和用户聊的主题,可能并不是每天,它们可以每隔一段频率就触发,比如:问候,节日祝福,“你在做什么”, etc.
-
business
和一些闲聊的机器人不同,bot应该提供一些价值,这些价值可能是个人信息助手, 导购,教育, 播放音乐。
声明对话类型:
> topic:business (vocabulary class)
+ Do you want to start Class now?
- start_class
+ ~yes
% Do you want to start Class now
- Great, ^redirectTo(/daily_lessons/vocabulary)
+ ~no
% Do you want to start Class now
- Ok, then.
<
所以,一个对话看起来像是这个样子。
规范化输入
表达同样的意思,可以有多种表示方法。
whats the color of the calanders
what is the colour of the calenders
what be the colour of the calender
在将输入语句传给规则引擎前,要先做规则化处理。比如:
-
tokenized - 分词
-
stemmed - 英文单词取词根
-
lemmatized - 英文单词变形的归类(例如单复数归类)
-
part-of-speech (POS) tagger - reads text in some language and assigns parts of speech to each word
-
named entity recognizer (NER) - [ labels sequences of words in a text which are the names of things] 专有名词 - 人名、地名、组织名、URL链接、系统路径等
这里需要结合很多工具库来实现:NLTK, Stanford CoreNLP, Jieba分词,Wordnet, ConceptNet.
比如,借助Stanford CoreNLP,可以有下面的标注:
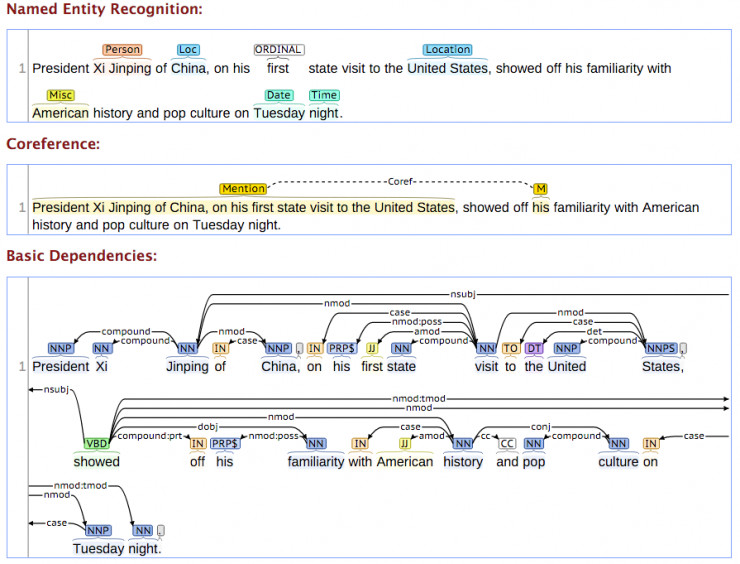
经过规范化输入,在规则引擎中,可以依赖词性和函数实现更智能的回答。
高效率的规则引擎
Bot可以有大量的主题,即便是只有100主题,每个主题15个对话,那就是1500个规则。如果只是单机运行,至少要进行下面两个优化:
-
排序
通过聊天的记录和关键字,先给对话栈排序。
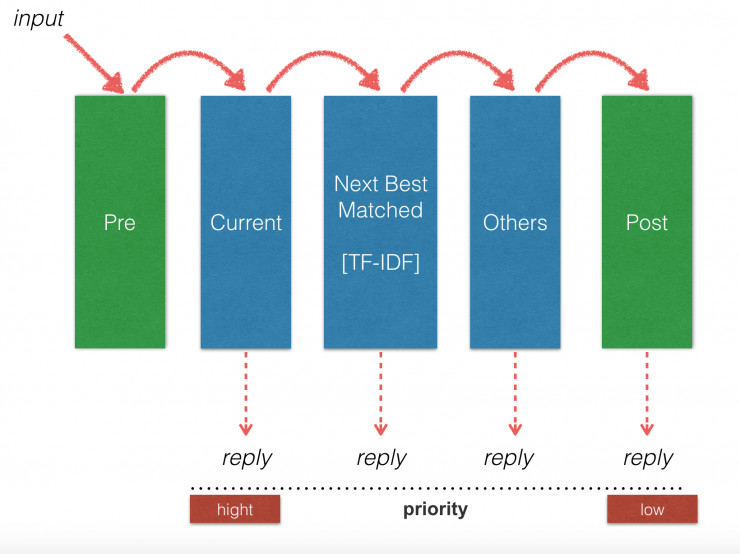
排序的思路大概是这样:
1) 查看当前对话,是否还有下文,一个对话的下文可以对应多个规则。
如果有下文,检测是否一个规则能匹配上输入。如果匹配上了,回复。 如果没有下文,或者没有规则能匹配上,进入次优匹配。
2) 次优匹配是将聊天主题的历史记录,使用TF-IDF算法进行排序。
简单说,就是使用一个函数计算用户聊天的对应主题频率。给不同的聊天主题加权重。在次优匹配中,都是处理用户曾经聊过的主题。
3) 在次优匹配中,没有命中,进入其他匹配。
其他匹配包括了以前没有聊过的主题。
-
并发
在排序后,去同时处理匹配运算,将命中的规则的回复,按照排序的顺序放到数组里,然后,从数组中取第一个元素。这样就比按照顺序一个一个检测快很多。
比如,一些Node.js模块: async 。
用户画像
在和用户聊天的过程中,获取到的用户相关的信息,有必要记录在数据库中,这其实是构建知识图谱的过程。
知识图谱所用的数据库是存在三个字段的结构化数据:
{
"subject": "Mao",
"predict": "chairman",
"object": "China"
}
由此构建了一个关系:
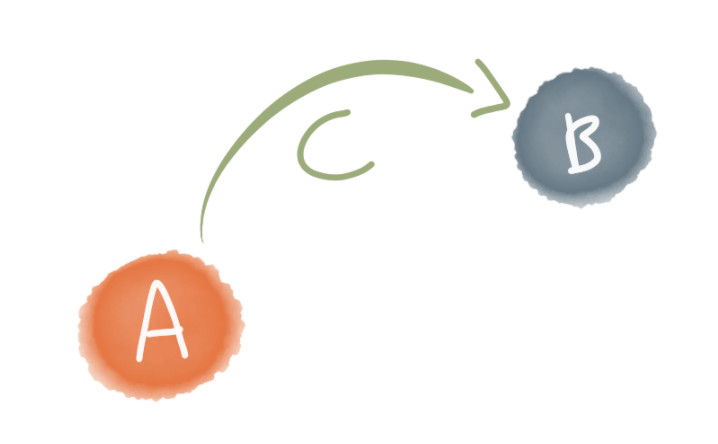
而B又可以跳转到D。
目前,较为成熟的商业产品和开源方案都有。
Google Knowledge Graph API
cayley graph
在Bot Engine中,可以得到相关用户的Knowledge Graph.
this.user.memory.get( ...)
this.bot.createUserFact( ...)
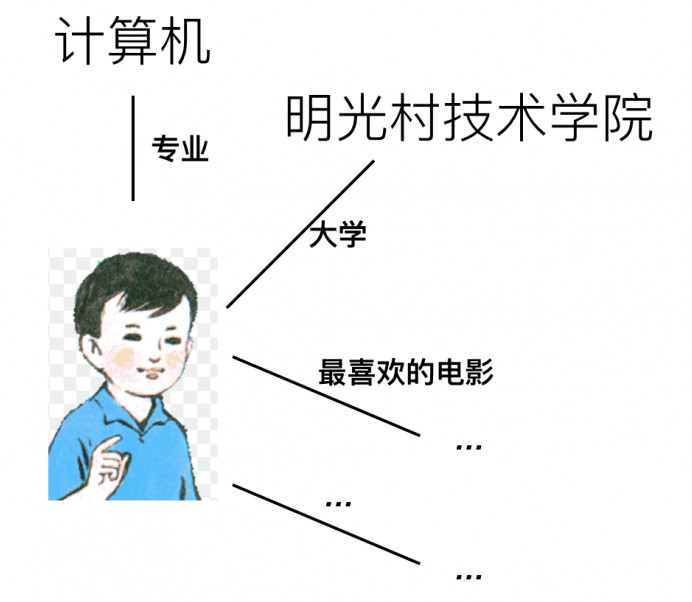
使用知识图谱,除了对实体之间完成关系构建外,还有一个原因是,搜索速度非常快,搜索功能强大。
SuperScript
介绍了这么多,那么到底怎么实现一个Bot Engine呢?经过了很多比较后,我觉得基于SuperScript实现Bot Engine是可行的。主要是下面这几点:
-
社区活跃:目前稳定版本v0.12.2没有bug, 最新版v1.0.0也在快速开发。
-
轻便灵活: 将SuperScript的源码读了一遍,觉得即便是作者不维护了,我也可以维护。
-
功能强大:在上面讨论的问题中,SuperScript都是有涉及的。
对话脚本
-
topic type - 话题
-
conversation - 对话
-
function - 插件和函数
Get started
-
npm install superscript
var superscript = require("superscript");
new superscript({ ...}, function(err, bot){
bot.reply("userId", "hello", function(err, reply){
// do your magic
})
})
Conclusion
很多人预计2017年,AI方向最可能取得成功的领域是聊天机器人。那么,在这种情况下,面向聊天机器人的架构设计,是一个热门问题。包括Google,Facebook都有可能发布类似于微软的Botframework平台。而Bot Engine, 一种处理对话的引擎,起着很关键的作用。在开源社区,还没有看到哪个呼声非常高的实现,SuperScript,至少在JavaScript社区,是一个不错的选择。
在下一篇文章中,我将介绍使用深度学习技术,依靠聊天语料,训练Bot Model.
Reading List
NaturalNode - General natural language facilities for node.
SuperScript - A dialog system and bot engine for conversational UI's.
Stanford CoreNLP - a suite of core NLP tools
Natural Language Toolkit - NLTK is a leading platform for building Python programs to work with human language data.
How to Cook a Graph Database in a Night - A Knowledge Graphic tool based on LevelDB.
最后
欢迎联系我,尤其是业内人士,给予指正,一起优化。
文章封面图来自:中国智能制造网
雷锋网特约稿件,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

