hadoop2.x单机搭建分布式集群超详细教程
【前言】
1.个人PC机配置:戴尔,笔记本,内存8G,硬盘西数500G,CPU酷睿i5
2.由于工作中需要经常在集群上做测试,另外我一直想学习大数据,因此结合百度+同事,有了此篇教程,初学者,不足之处,可在下方留言
【准备工作】
下载如下5个软件:
1.VMware,版本10
2.CentOS系统iso镜像,版本6.5
3.Xshell软件
4.jdk,linux版本1.8
5.hadoop软件包,版本2.7
【注:为方便起见,教程中所有密码均设置为123456】
【搭建步骤】
1.安装VMware软件
详见我博客:
http://blog.csdn.net/wy_0928/article/details/51320437
http://blog.csdn.net/wy_0928/article/details/51320549
2.安装CentOS虚拟机系统以及配置网络和远程连接
详见我博客:
网络设置为NAT模式
http://blog.csdn.net/wy_0928/article/details/51320640
博客中用的是SecureCRT工具,个人目前偏爱Xshell,连接方法很简单,这里不赘述
此时ifconfig查看网卡,应该直接有ip了,试着在虚拟机和本地宿主机ping下:
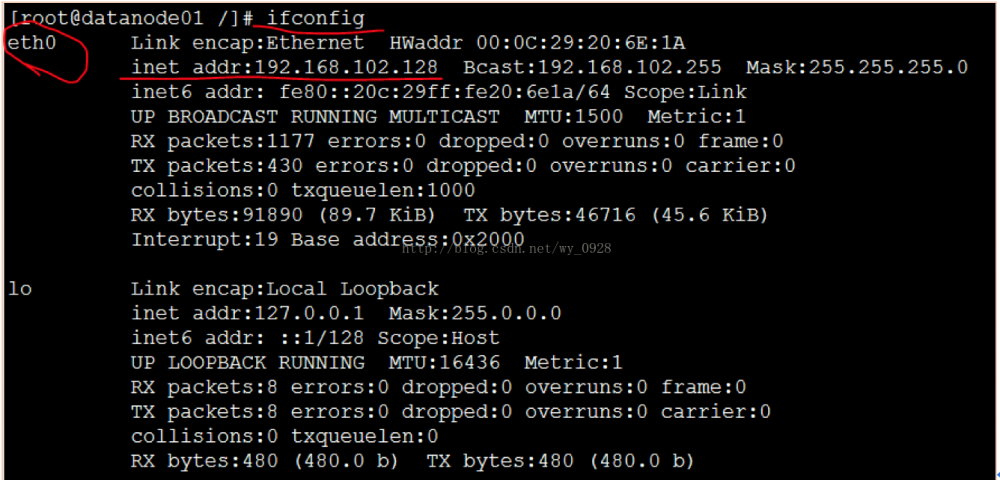
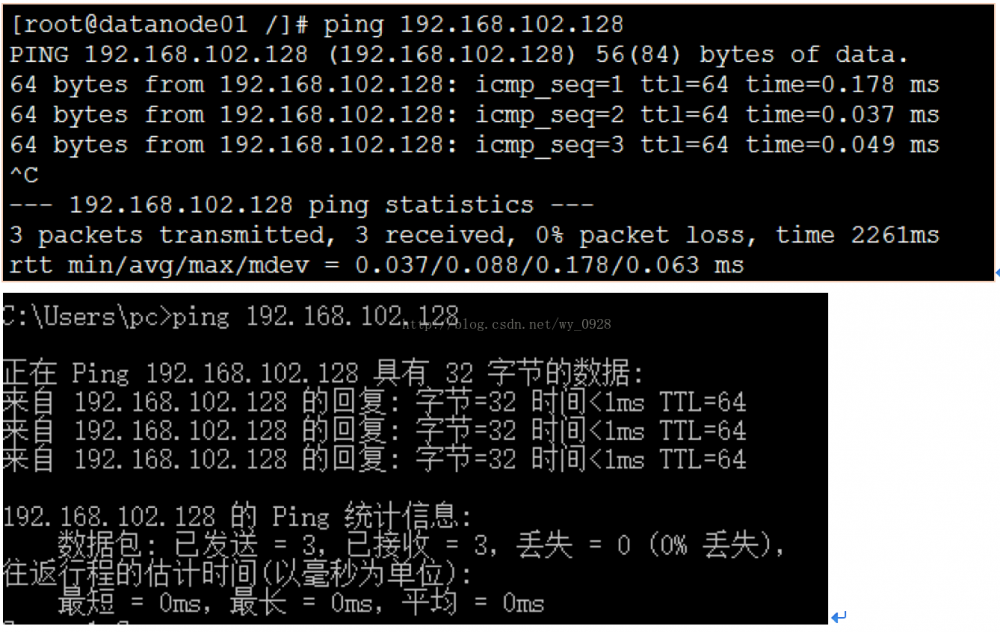
切换root用户:
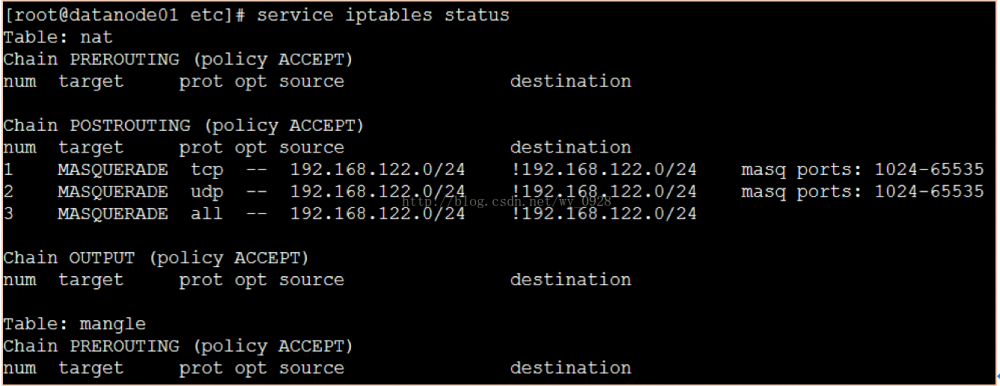
3.关闭虚拟机防火墙
首先查看当前防火墙状态:

关闭防火墙:

查看iptables服务是否开启:
重启虚拟机:

4.安装并配置jdk
这部分用root权限操作
(1)先输入jave-version查看当前jdk版本,不是1.8就先删除已有版本的jdk软件包:

(2)去oracle官网下载jdk1.8的Linux版本(记得下载rpm自安装版本),然后上传到/usr/local/src目录;

(3)输入如下命令开始安装jdk:
rpm -i jdk-8u91-linux-i586.rpm
等待安装完成
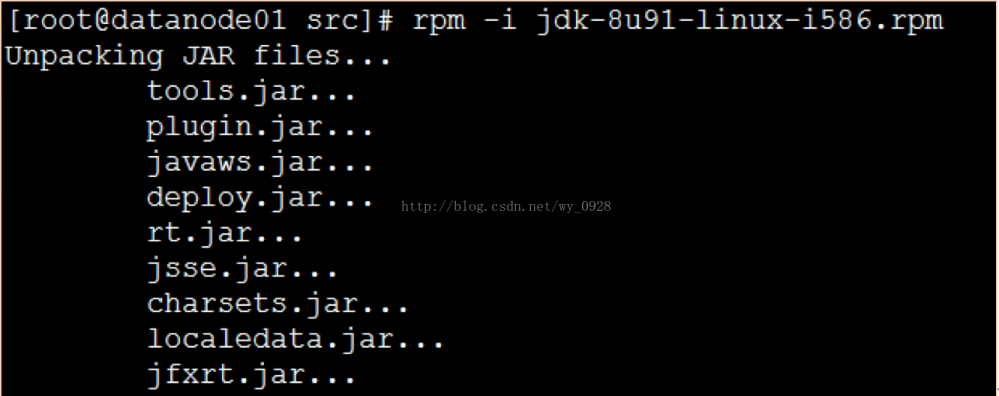
在/usr/java路径下查看是否有jdk1.8文件夹:

有就安装成功了。
(3)配置环境变量,让系统用1.8版本的jdk:
首先修改系统配置文件:vi /etc/profile
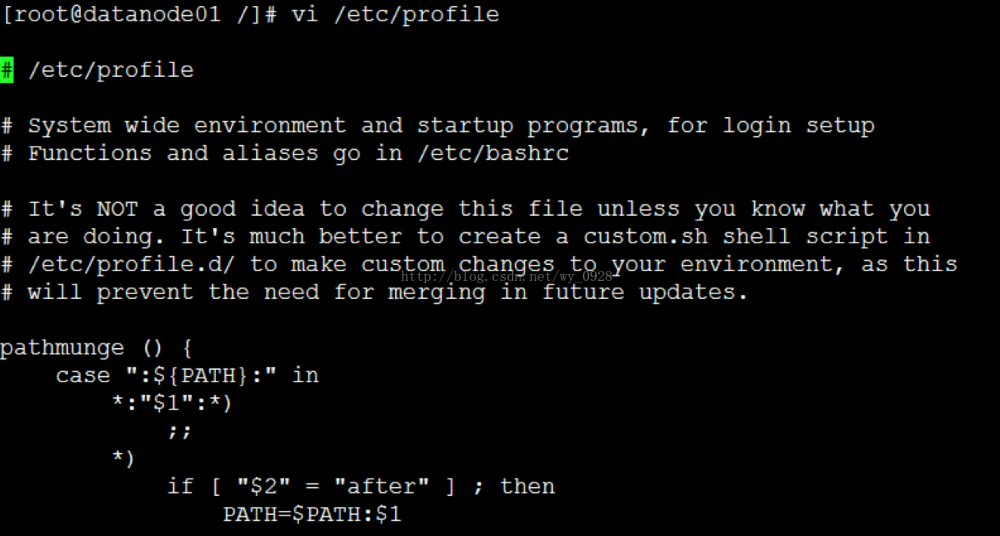
在文件末尾加上如下几行(注意等号前后不要留空格):

保存退出
(4)设置修改后的配置文件生效:

(5)查看服务器当前jdk版本:

至此jdk安装配置结束。
5.创建hadoop相应的文件系统
这部分在root权限下操作
(1)配置hosts文件,路径在/etc/hosts:

之后在虚拟机ping master看看是否通:

(2)查看虚拟机系统中是否安装lvm工具

这就表示已安装。
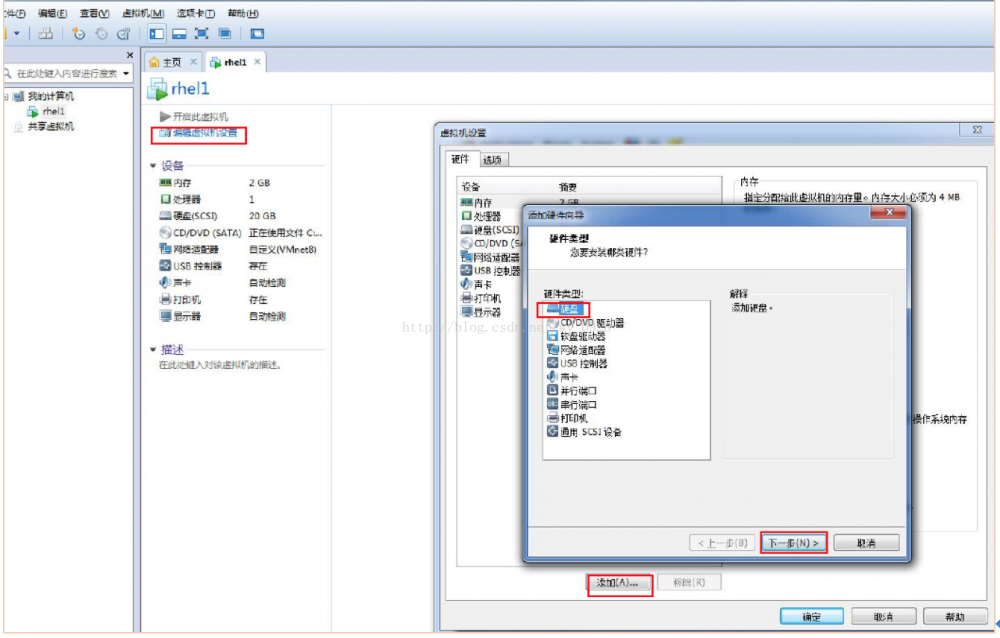
(3)在虚拟机中添加3块硬盘(均为20G)
虚拟机先关机
a)点击 “编辑虚拟机设置”---“添加”---“硬盘”---“下一步”,然后一直点击 “下一步”直到完成:
b)接着,重复此操作2遍,会得到以下图片。最后,点击“确定”并开启虚拟机:
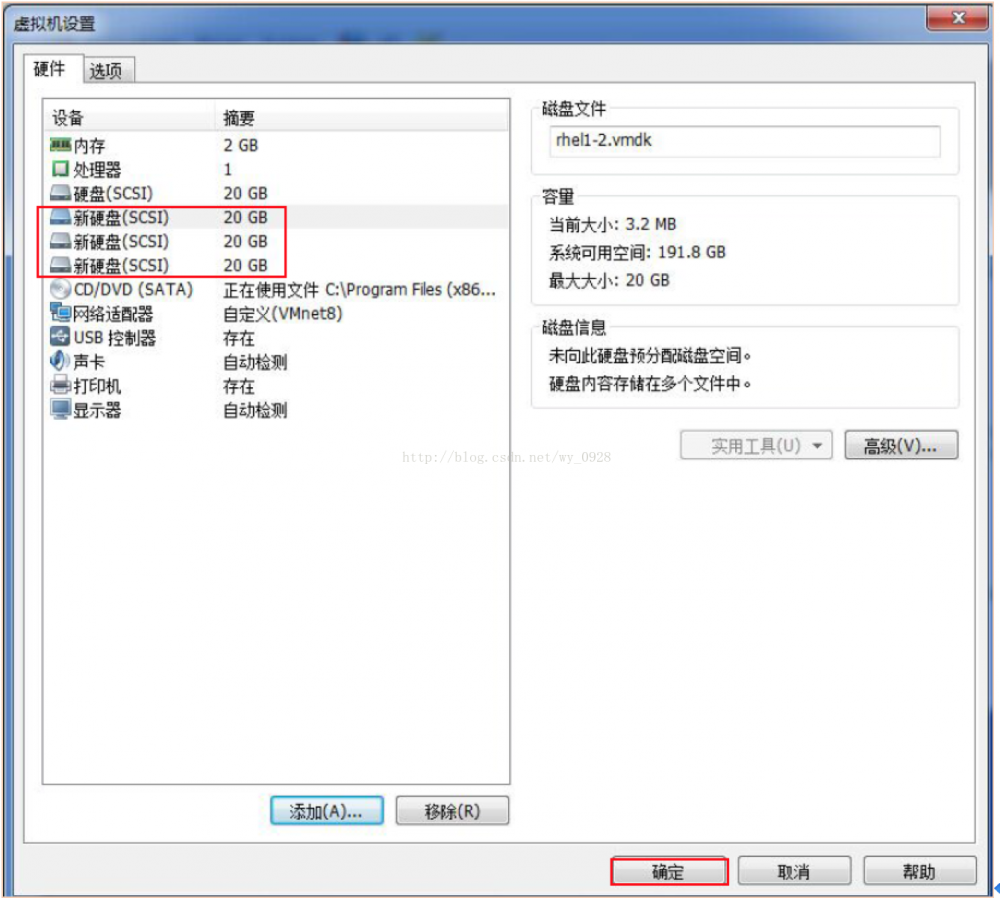
开启后fdisk -l查看硬盘是否开启成功:
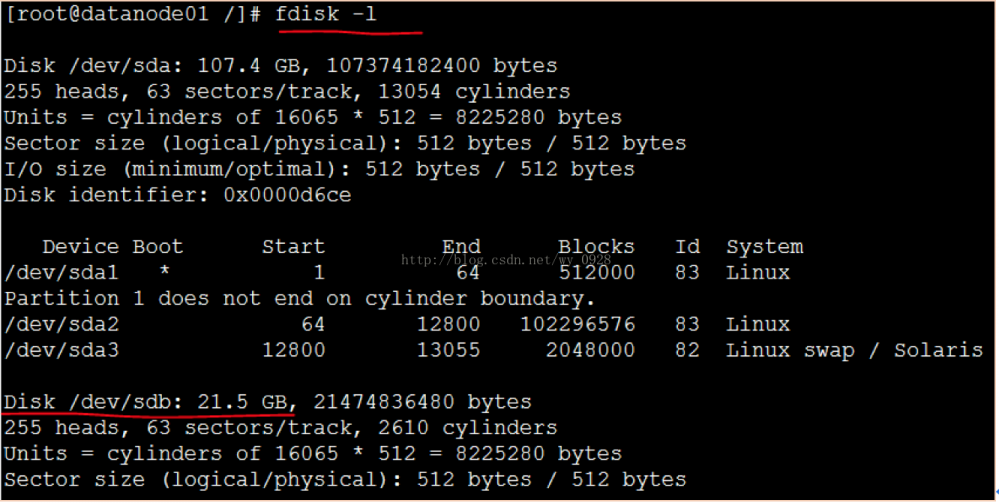
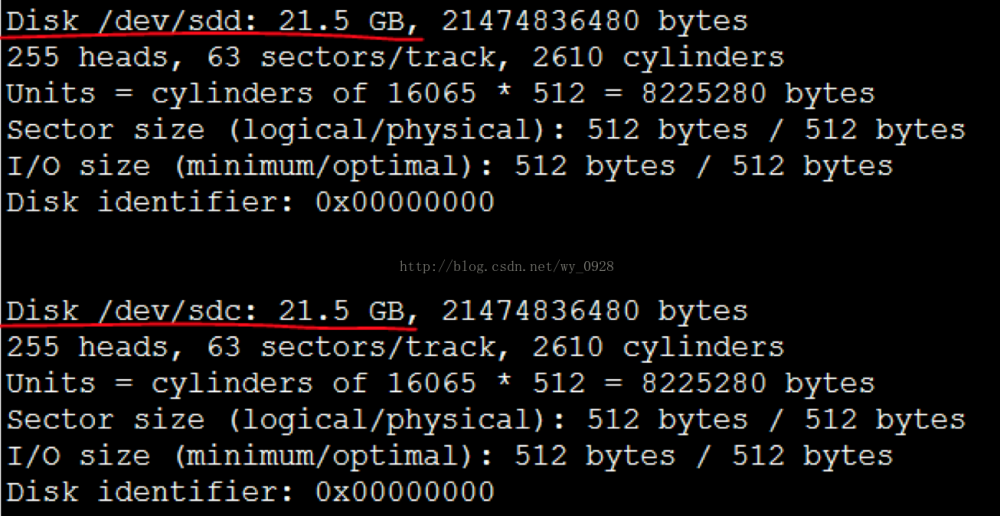
可以看到3个20G的硬盘(sdb、sdc、sdd)
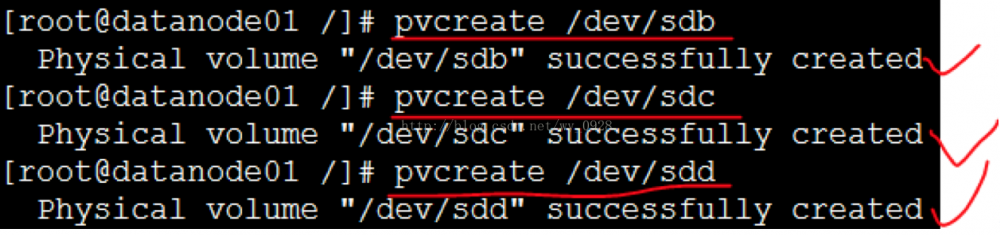
(4)创建物理卷
(pvcreate指令用于将物理硬盘分区初始化为物理卷,以便被LVM使用。)
a)使用sdb创建基于sdb的物理卷
pvcreate /dev/sdb
b)使用sdc创建基于sdc的物理卷
pvcreate /dev/sdc
c)使用sdd创建基于sdd的物理卷
pvcreate /dev/sdd
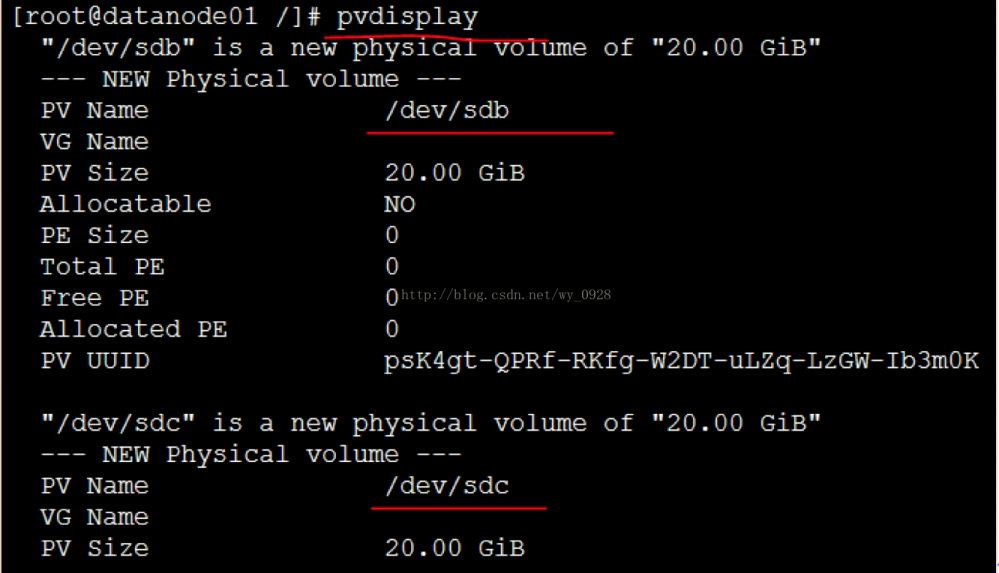
d)查看物理卷是否创建成功
pvdisplay

(5)创建卷组和添加新的物理卷到卷组
a)创建一个卷组
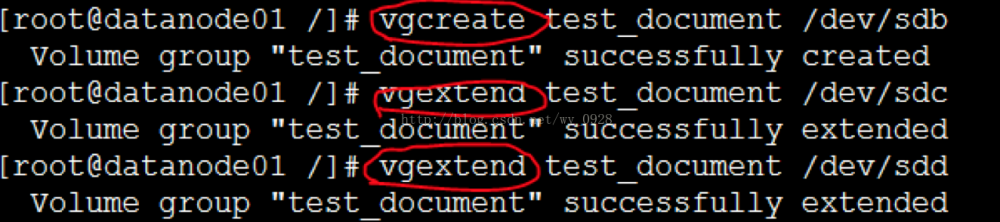
vgcreate test_document /dev/sdb
(vgcreate 命令第一个参数是指定该卷组的逻辑名,后面参数是指定希望添加到该卷组的所有分区和磁盘)
b)将sdc物理卷添加到已有的卷组(注意vgcreate与vgextend用法的区别)
vgextend test_document /dev/sdc
c)将sdd物理卷添加到已有的卷组(注意vgcreate与vgextend用法的区别)
vgextend test_document /dev/sdd
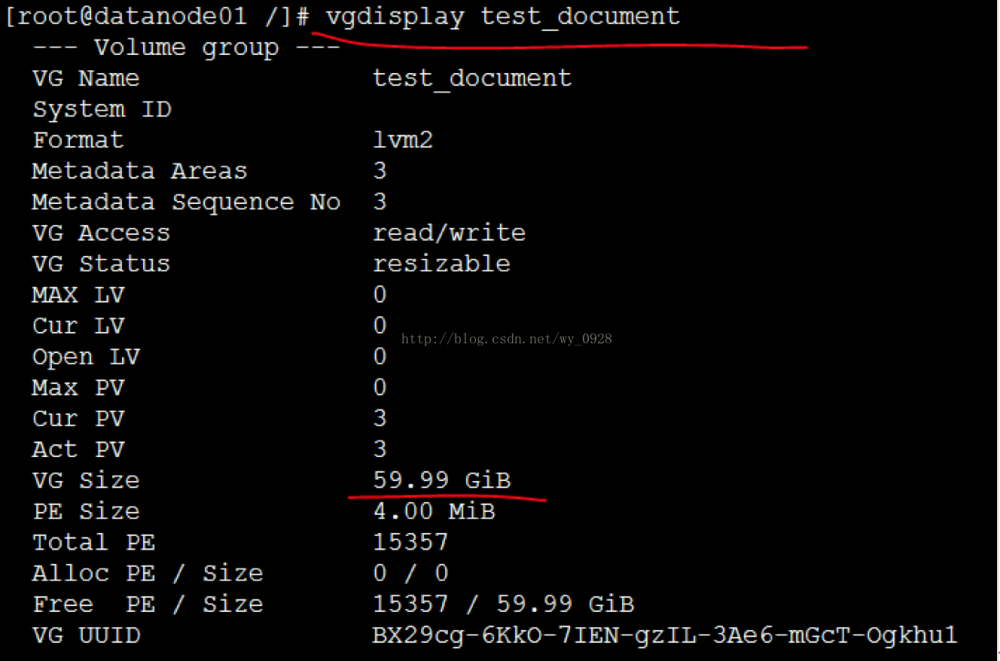
d)查看卷组大小(发现已经60G了)
(6)激活卷组

(7)创建逻辑卷
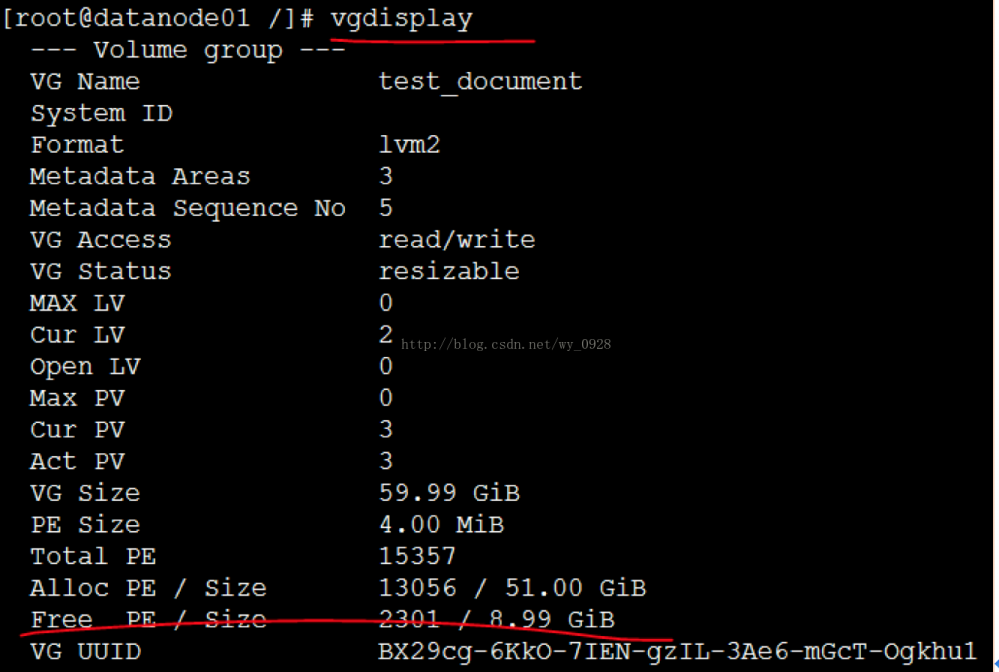
a) lvcreate -L5120 -n lvhadooptest_document
(该命令是在卷组test_document上创建名字为lvhadoop,大小为5120M的逻 辑卷,并且设备入口为/dev/test_document/lvhadoop ,test_document为卷组名,lvhadoop为逻辑卷名)
b) lvcreate -L51200 -n lvdatatest_document
(该命令是在卷组test_document上创建名字为lvdata,大小为51200M的逻 辑卷,并且设备入口为/dev/test_document/lvdata ,test_document为卷组名,lvdata为逻辑卷名)

注意,如果分配过大的逻辑卷 lvcreate -L10240 -n lvhadoop test_document 会提示剩余空间不足,此时可用命令 vgdisplay 去产查看剩余空间的大小。
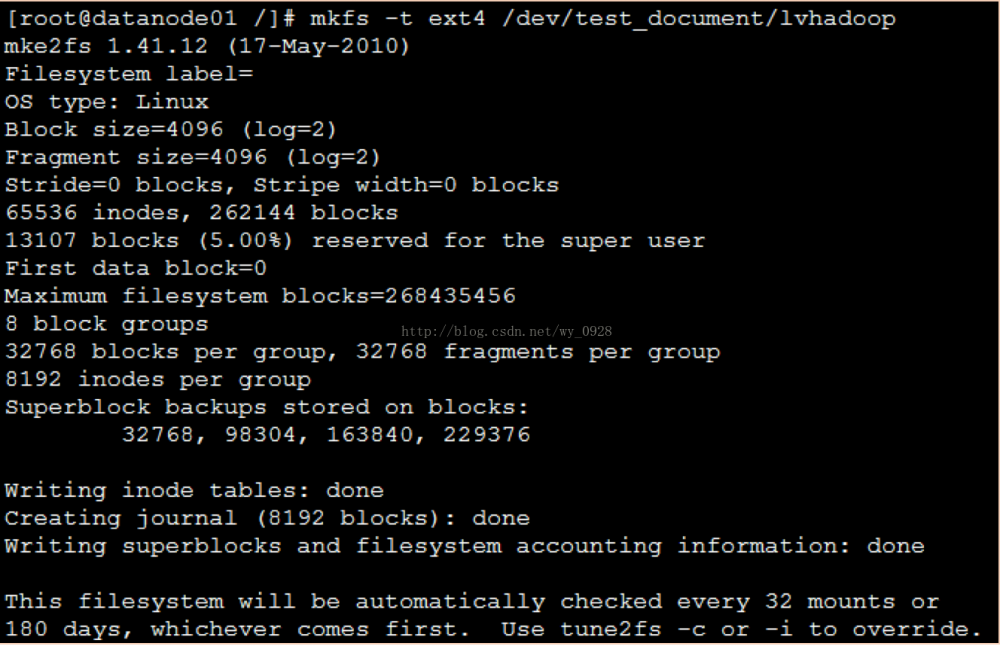
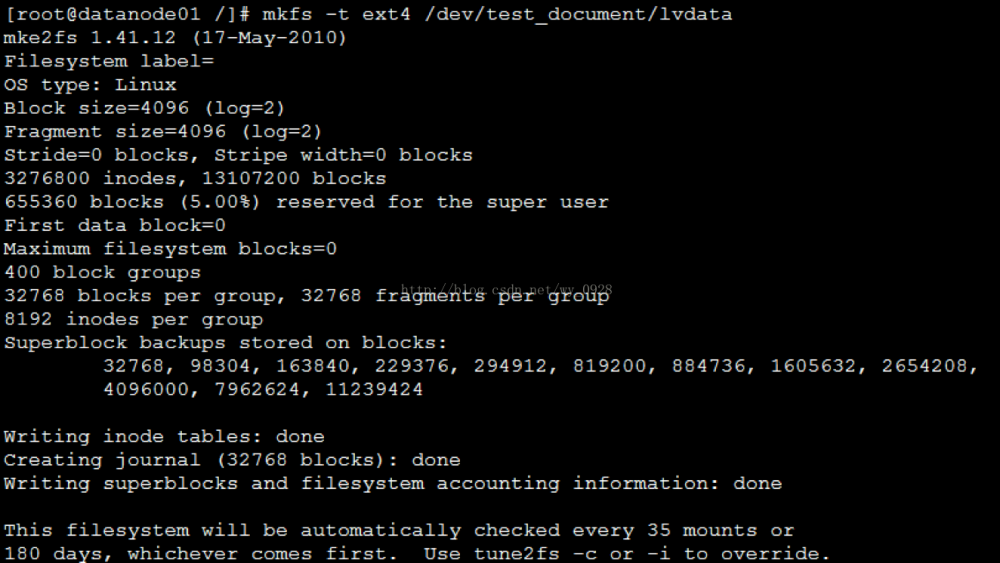
(8)创建文件系统
a) mkfs -t ext4/dev/test_document/lvhadoop
b) mkfs -t ext4/dev/test_document/lvdata
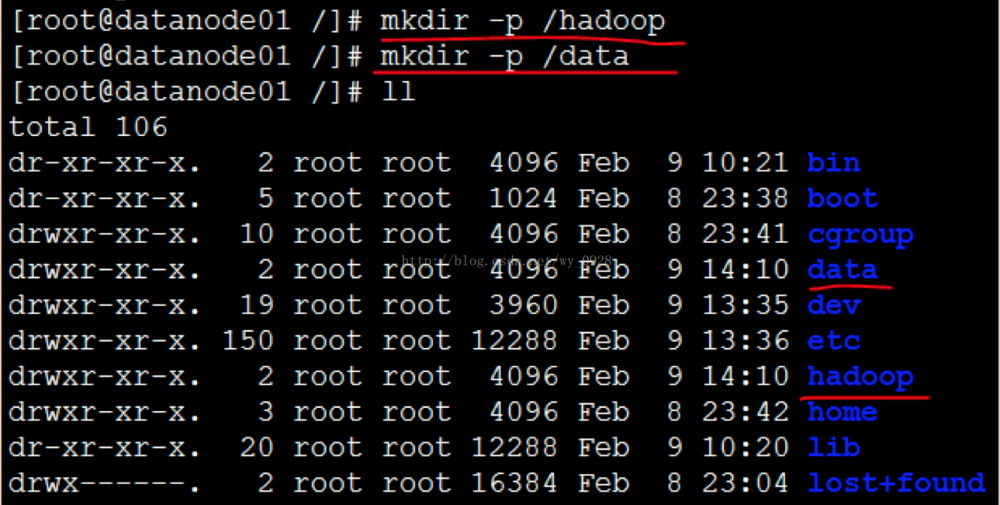
(9)创建文件夹
a)在linux根目录下创建hadoop文件夹 mkdir -p /hadoop
b)在linux根目录下创建data文件夹 mkdir -p /data
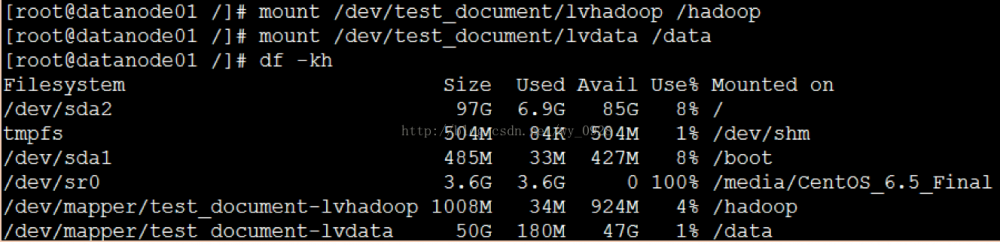
(10)挂载
a)mount /dev/test_document/lvhadoop /hadoop
b)mount /dev/test_document/lvdata /data
c)挂载后,再使用 df -kh 命令查看
(11)修改自动挂载的配置文件
如果下次重启linux系统后,挂载设备就又看不到了,我们需要把这个文件写入到fstab 分区表文件里面。
a)vi /etc/fstab
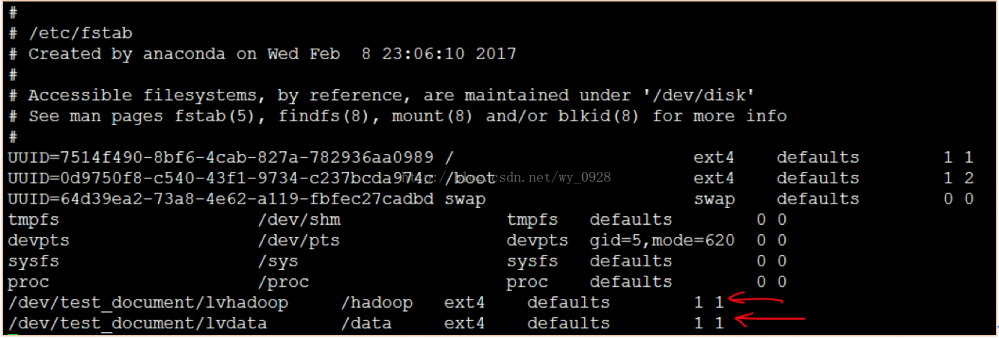
在文件末尾加上如上两行,然后按“ESC”---“shirt”+“:”---输入“x”---回车,之后reboot重启虚拟机。
6.创建hadoop组和用户
(1)创建组
groupadd -g 3000 cloudadmin
(2)创建用户
useradd -u3001 -g cloudadmin hadoop

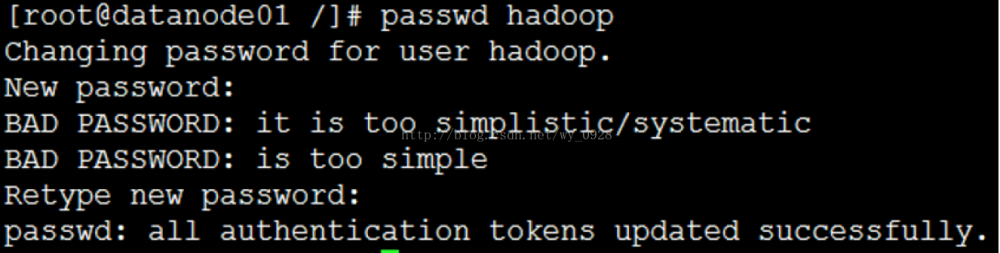
(3)修改密码
passwd hadoop 密码改为: 123456 (与 root 用户的密码一致)
(4)修改文件的系统权限
a)修改hadoop文件的系统权限 chown -Rhadoop:cloudadmin /hadoop
b)修改data文件的系统权限 chown -Rhadoop:cloudadmin /data
c)查看 ls -l / | grep cloudadmin

7.下载hadoop软件包
打开hadoop官网 http://hadoop.apache.org :
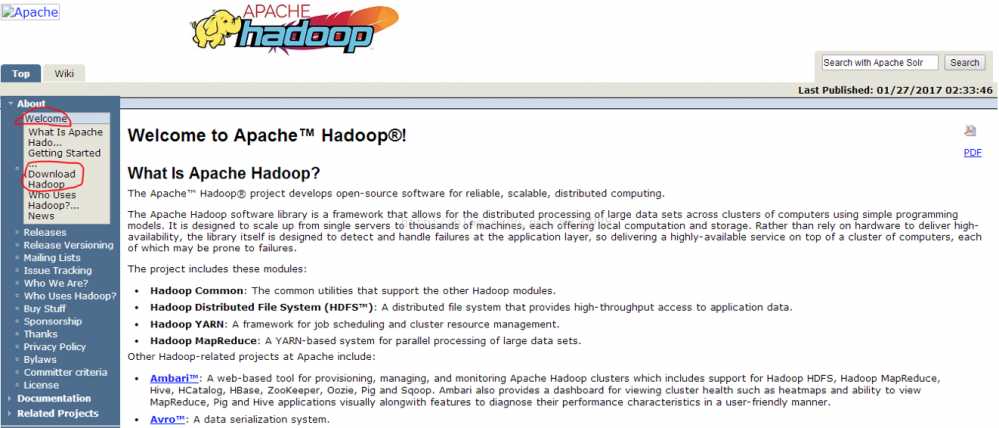
点击左侧的Download Hadoop

单击releases
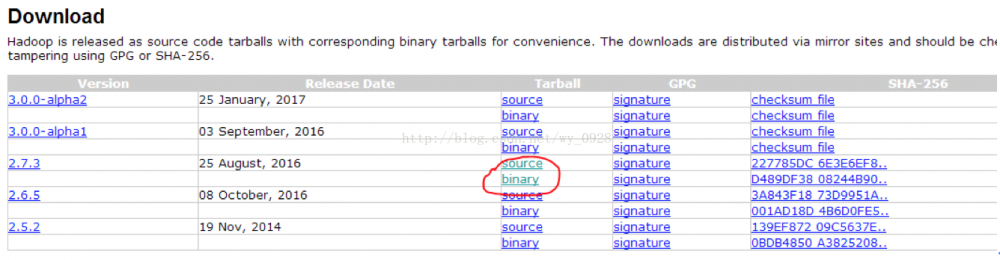
单击binary,注意source是源码,不要下载错了
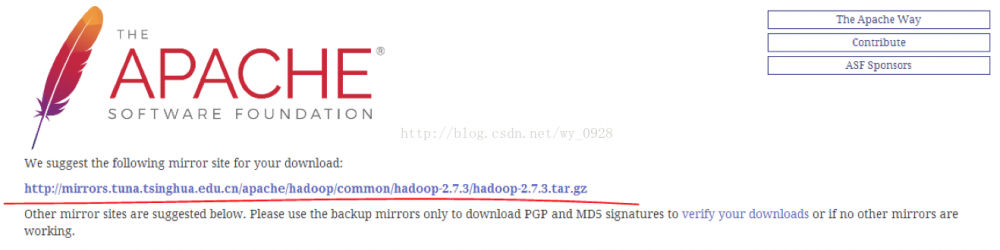
单击上图的链接进行下载

上图中-src是源码文件,我们用另外一个。
8.在虚拟机中解压hadoop
(1)将下载的压缩包上传到/hadoop目录下(rz命令):

(2)切换到hadoop用户
重启虚拟机,用hadoop用户登录,注意Xshell远程连接的时候,新建个hadoop用户登录窗口
(退出hadoop用户exit,查看当前用户whoami)

(3)解压hadoop压缩包:tar -zxvfHadoop-2.7.3-src.tar.gz,解压完成后出现hadoop文件夹:

之后ll查看:

9.创建集群(规划1个主节点,2个从节点)
为了看着舒服,将当前虚拟机改名为hm(直接在VMware右键重命名即可);
(1)克隆2台虚拟机
在VMware虚拟机中右键-管理-克隆
直接下一步
直接下一步

选择创建完整克隆,下一步,将名称改为hd001:

点完成开始克隆,克隆完成后:
点关闭即可,用同样的方法再克隆一台虚拟机(注意名称为hd002)。
克隆的时候,新虚拟机ip自动更新1,就是比如第一台虚拟机ip为192.168.99.1,那么克隆出第二台,ip自动更新为192.168.99.2,以此类推。
(2)修改3台虚拟机的主机名
开启3台虚拟机,用Xshell连接的时候注意ip不同,之后3台虚拟机都切换成root用户:
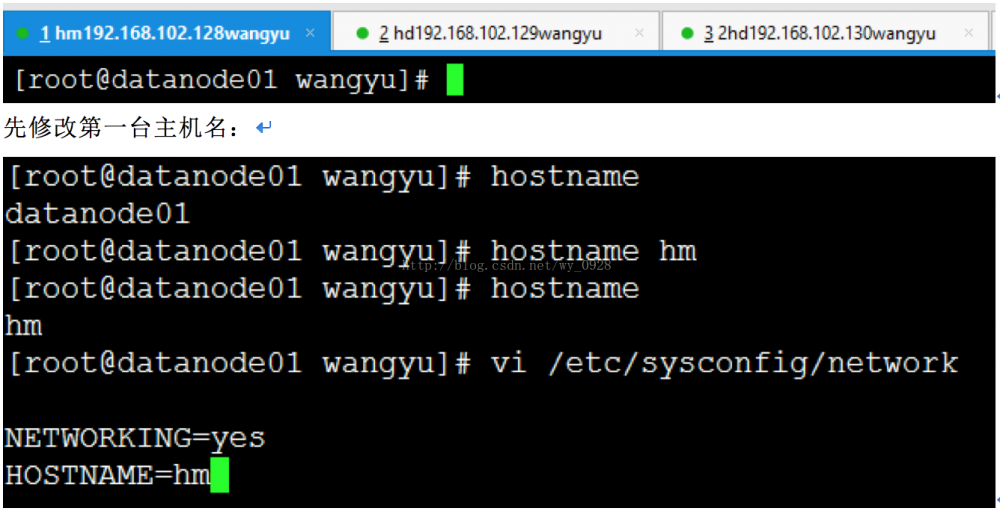
其中hostname是查看当前主机名,hostname hm是将主机名改为hm,但是这么做重启会失效,因此我们修改配置文件network,之后 reboot 重启此虚拟机。
其余所有虚拟机都重复上述操作,注意主机名hm改为hd001和hd002。
(3)修改3台虚拟机的ip和mac
全部用root用户登录!

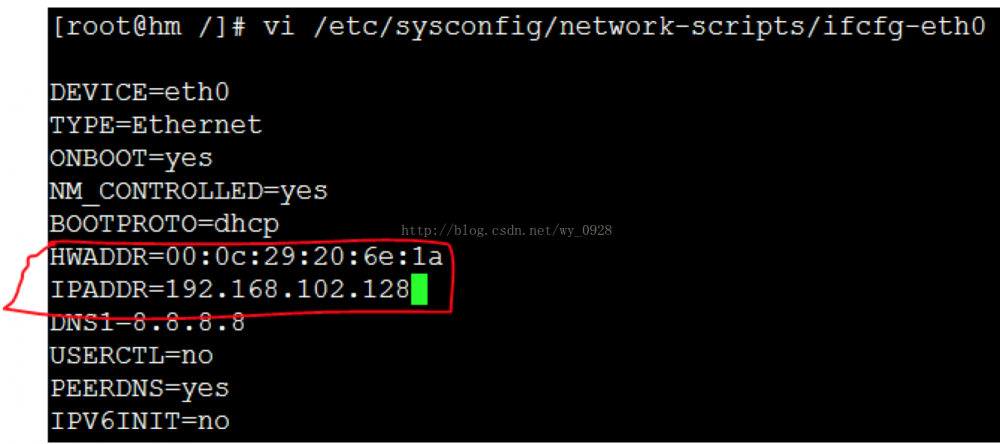
先修改第一台虚拟机的ip和mac,输入cat/etc/udev/rules.d/70-persistent-net.rules查看,如果不是下图的样子,将其余网卡注释掉,另外复制它的MAC地址:

进入network-scripts目录,编辑其内的ifcfg-eth0文件,将该虚拟机的ip和刚刚复制的mac地址覆盖上:
重启网卡
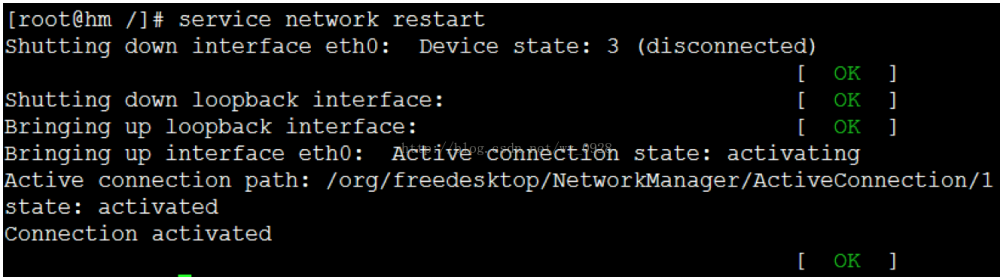
至此,第一台虚拟机的ip和mac配置完毕,接着配置第二台虚拟机的ip和Mac地址,输入vi /etc/udev/rules.d/70-persistent-net.rules修改,因为上面的MAC地址与第一台虚拟机相同,因此我们用下一个,并将网卡修改为eth0:
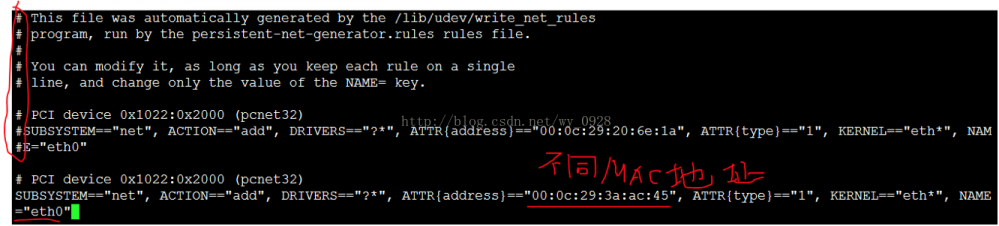
后续步骤同上,接着同理配置第三台虚拟机的ip和Mac地址。
(4)修改映射关系
用root登录第一台虚拟机,输入vi /etc/hosts,按照下图配置,图中的ip为各个虚拟机的ip:
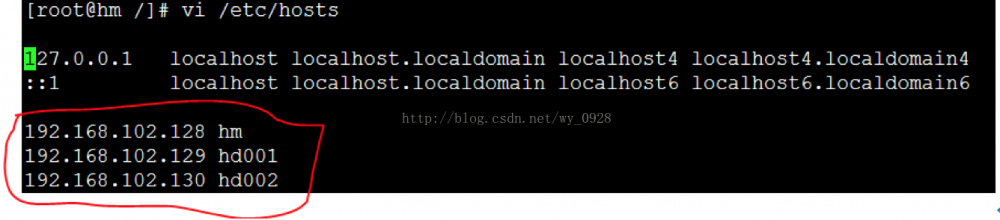
进入/etc文件夹:
scp hosts192.168.102.129://etc/
将hm etc文件夹下的hosts传到192.168.102.128 的etc下
scp hosts192.168.102.130://etc/
将hm etc文件夹下的hosts传到192.168.102.130 的etc下
有提示时,输入yes,密码是刚设置的123456
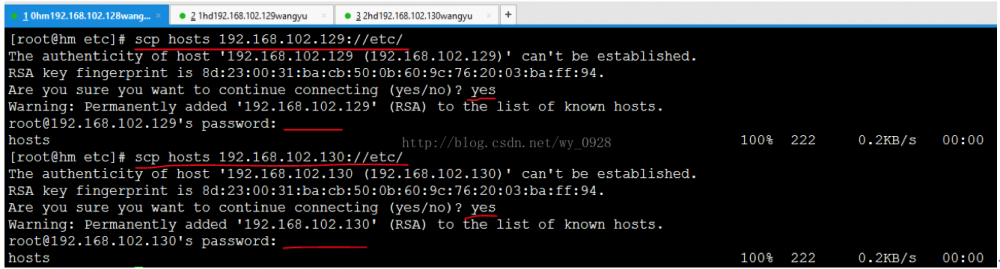
再去另外2台虚拟机查看文件是否传输成功cat /etc/hosts
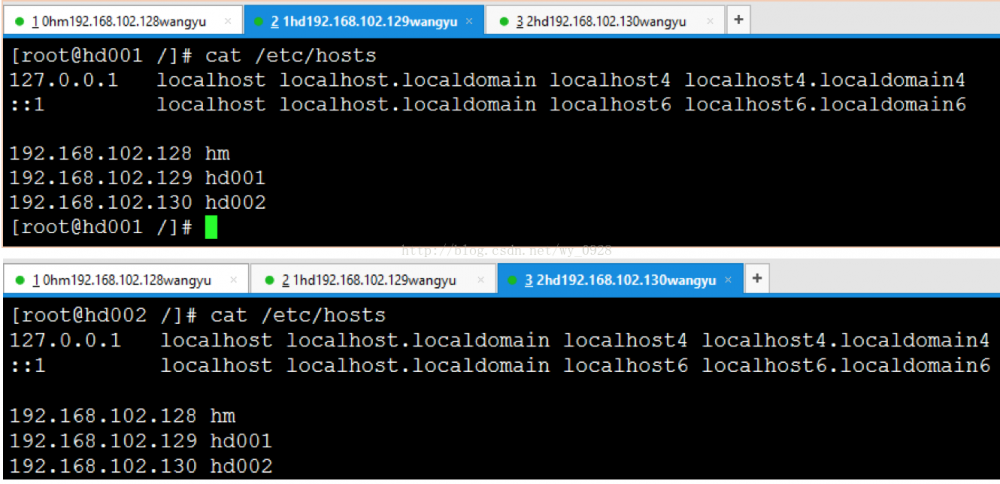
在每台虚拟机中进行ping通测试,这里每台虚拟机都需要测试与另外所有虚拟机是否通,且ping ip和ping 主机名都要测试( 这里很容易漏测 ):

10.在集群中配置SSH免密登录
(1)重启所有虚拟机,均用hadoop用户登录
(2)在主节点hm的Xshell里输入ssh-keygen -t rsa命令,然后一直按回车即可
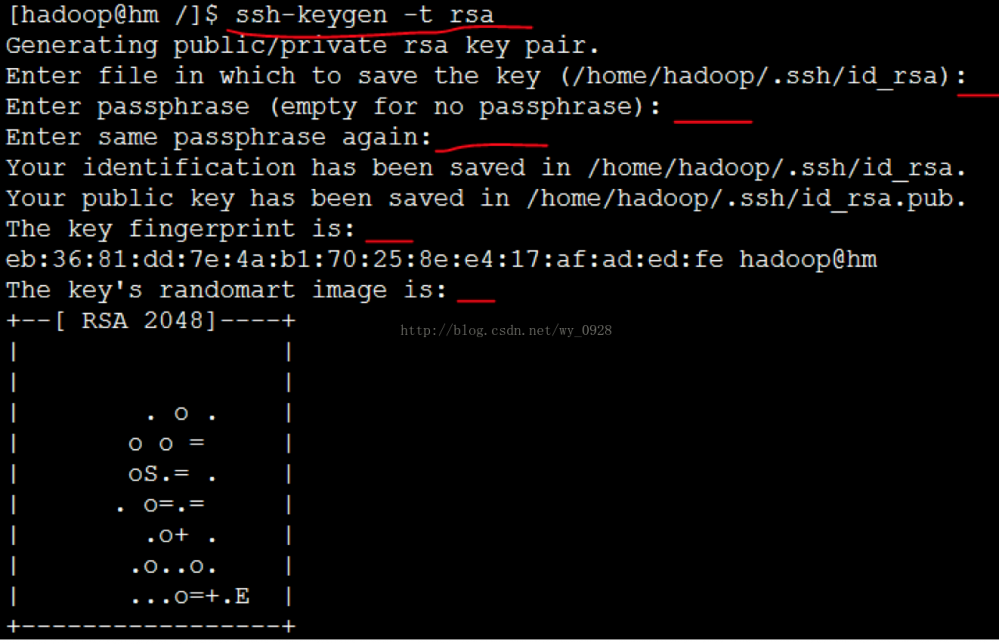
在主节点hm上执行如下命令:
cd ~
cd .ssh
catid_rsa.pub >> authorized_keys
scp authorized_keys192.168.102.129:/root/.ssh/
scpauthorized_keys 192.168.102.130:/root/.ssh/
出现提示就输入 yes ,密码是之前设置的 123456 , 这里如果在scp时提示Permission denied,是因为当前登录的hadoop用户没有权限,解决办法3个:其一是为hadoop用户授权,其二是切换成root用户进行操作,其三是将authorized_keys从主节点下载到本地再逐一上传到所有从节点。
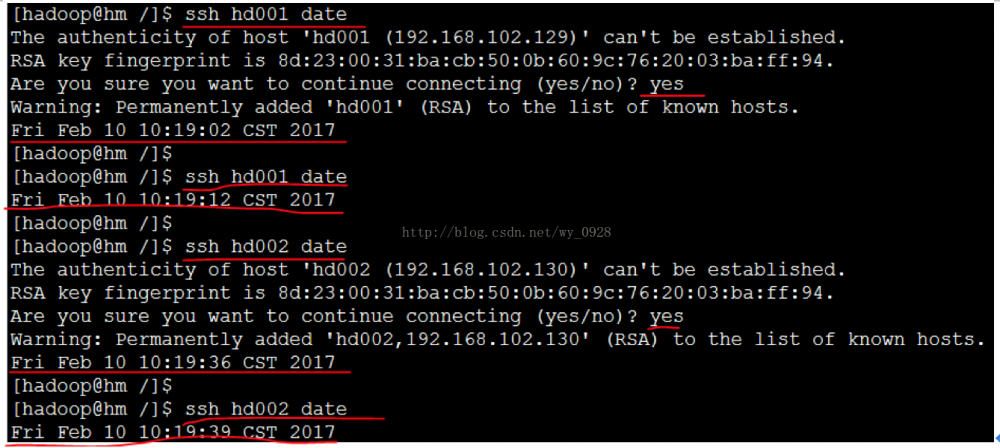
(3)SSH免密码登录验证
ssh hd001date
ssh hd002date
第一次输入会有提示,输入yes,后面就正常
11.修改hadoop集群的配置文件
在hadoop用户下进行以下操作:
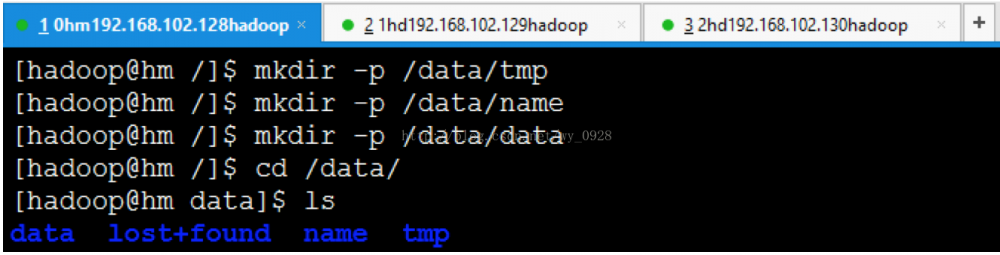
(1)在集群中的所有节点上创建相应的文件目录
a)创建tmp文件,mkdir -p /data/tmp
b)创建name文件,mkdir -p /data/name
c)创建data文件,mkdir -p /data/data
d)进入data目录,cd /data
e)查看data文件夹下的文件,ls
(2)在主节点上修改配置文件
a)进入根目录cd /
b)进入hadoop配置文件所在目录cd /hadoop/hadoop-2.7.3/etc/hadoop/

c)修改hadoop-env.sh文件vi hadoop-env.sh

这里JAVA_HOME的地址是之前配置JDK那里的地址
d)修改core-site.xml文件vi core-site.xml
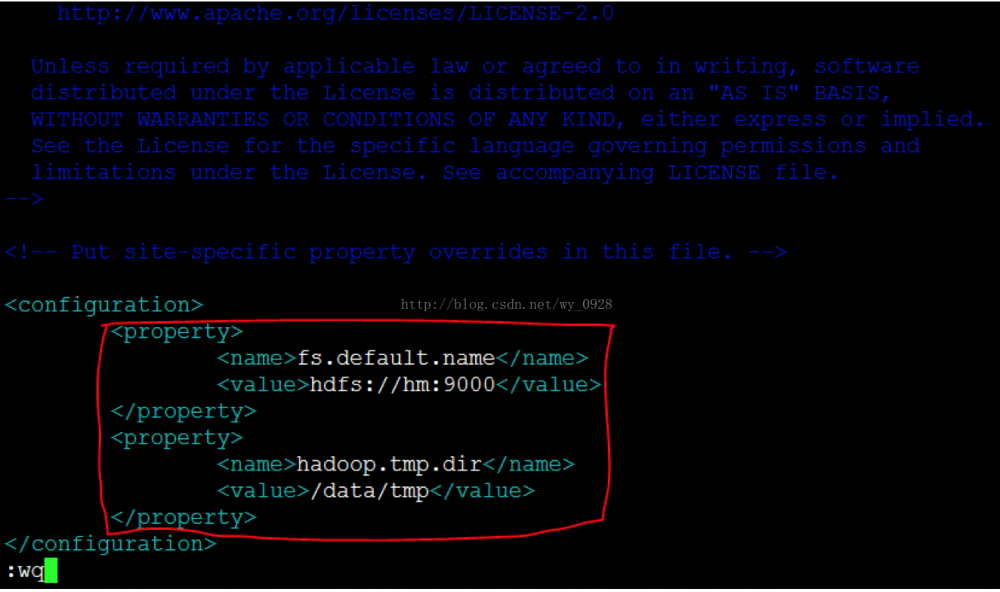
注意主机名hm和路径是之前设置好的,不要配错了
e)修改hdfs-site.xml文件vi hdfs-site.xml
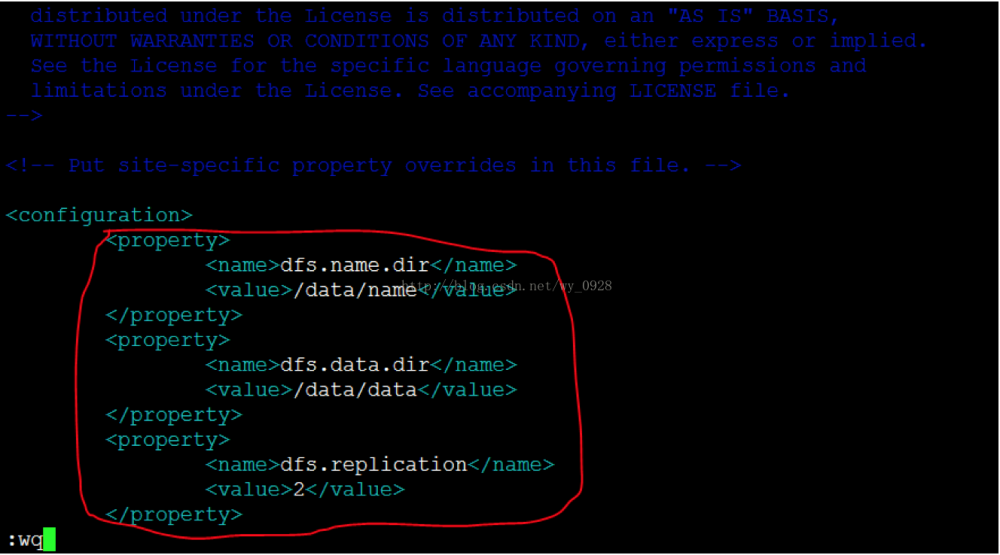
注意这里的路径是之前设置好的,不要配错了,另外有几台从节点就写几,我这里写2
f)修改mapred-site.xml.template文件vi mapred-site.xml.template
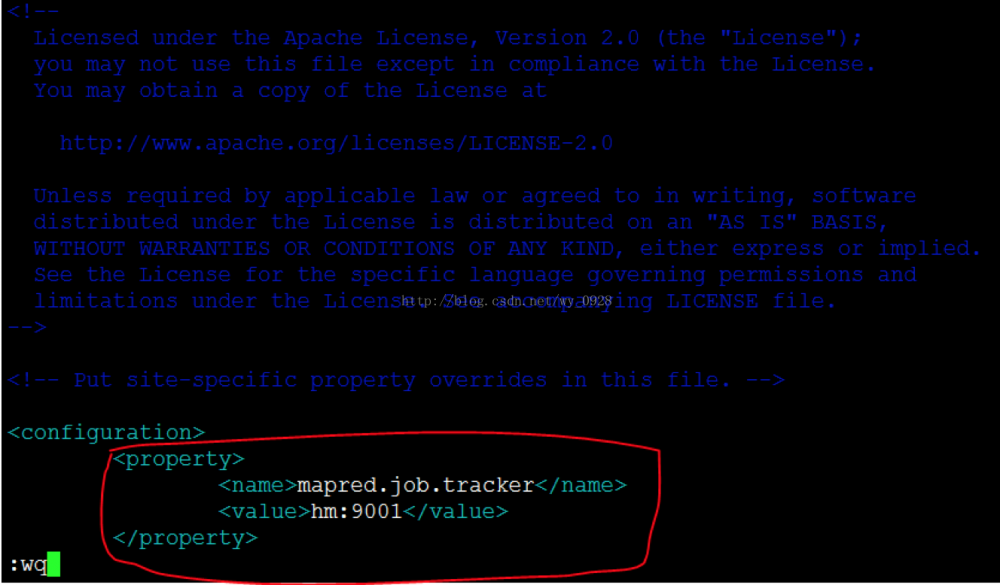
注意主节点名hm是之前设置好的,不要配错了
g)复制文件,将mapred-site.xml.template复制一份并重新命名为mapred-site.xml存放在当前路径:

同理将mapred-queues.xml.template复制一份并重新命名为mapred-queues.xml存放在当前路径:

注:hadoop1.x版本直接有这两个文件,而hadoop2.x版本需要复制重命名一下
h)继续修改hdfs-site.xml文件
因为hadoop2.x删除了1.x版本的masters文件,因此将master在hdfs-site.xml里面
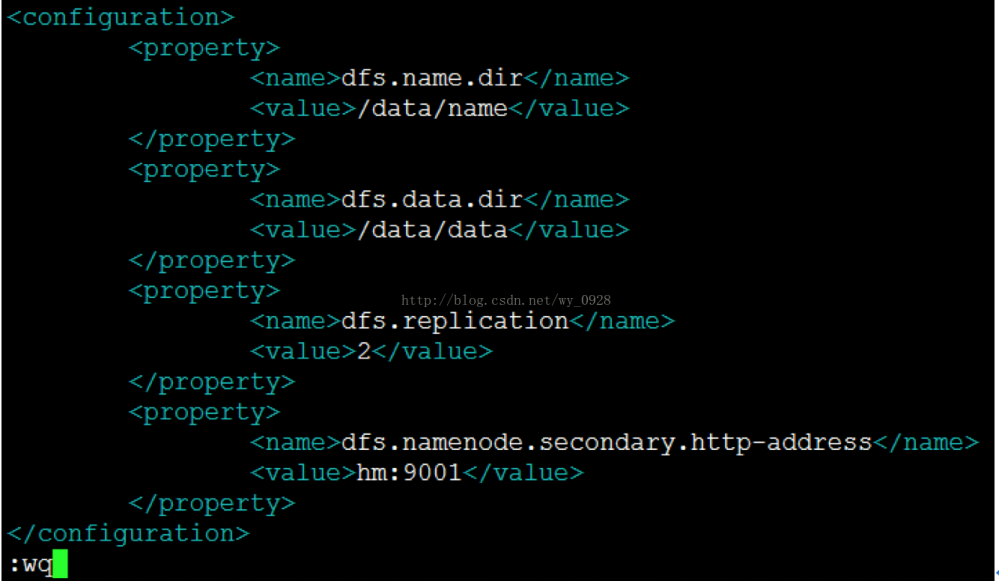
i)修改slaves文件vi slaves
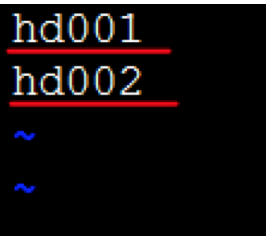
这里写入所有从节点的主机名
(3)同步时钟
ntpdate
(4)分发hadoop软件包到从节点上
注意这步是hadoop用户在/hadoop目录下操作,时间较长,请耐心等待
scp -r hadoop-2.7.3hd001:/hadoop/
scp -rhadoop-2.7.3 hd002:/hadoop/
12.格式化HDFS
(1)在hadoop用户下进入主节点的/hadoop/hadoop2.7.3目录
(2)格式化hdfs
bin/hadoop namenode -format

如果有提示,输入大写的Y,小写的报错,没有就算了
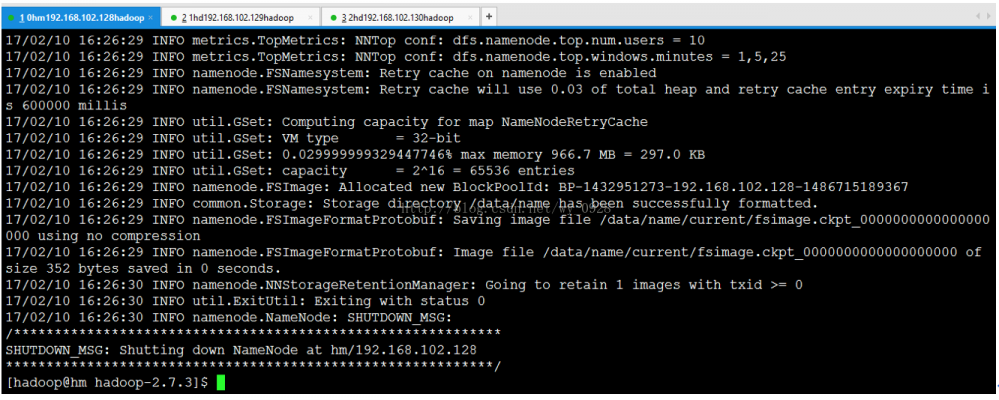
格式化出错的解决方法
a 、查看端口 9000 的信息(需要在 root 用户下查看)
netstat -anp|grep 9000
b 、格式化只能 1 次,如果后面再次格式化则会导致不成功,需要将所有节点上根目录下 data 目录下的 data 、 name 、 tmp 文件删除,再新建 data 、 name 、 tmp 空的文件夹。
13.启动hadoop 系统
(1)用hadoop用户登录主节点,进入/hadoop/hadoop2.7.3目录
(2)启动hadoop系统
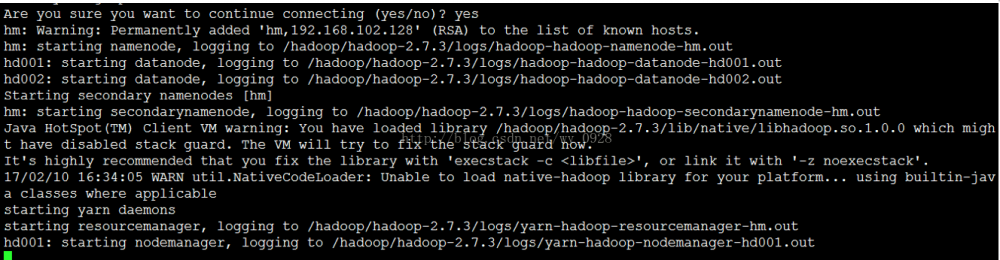
bin/start-all.sh或sbin/start-all.sh
(关闭集群sbin/stop-all.sh)
版本不同,apache的2.x版本启动脚本是在sbin文件夹内。

输入yes
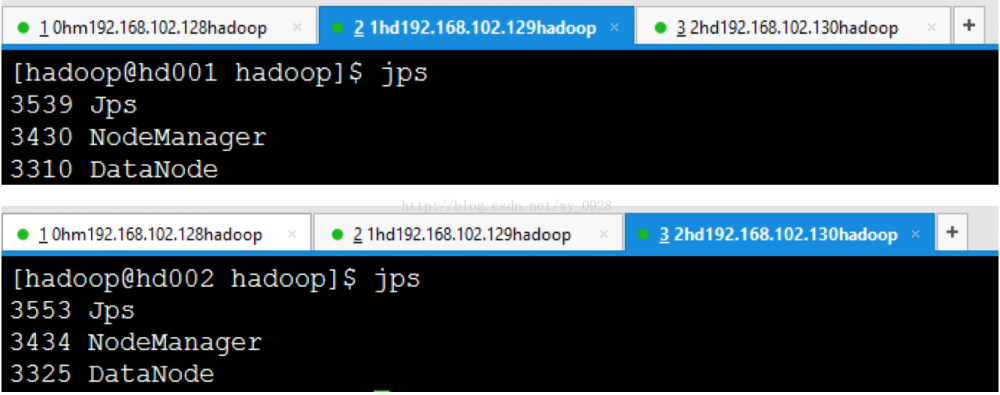
(3)检查hadoop的相关进程是否启动成功
a)主节点jps

b)所有从节点jps
(4)检查集群状态
a)在hadoop用户下进入主节点的/hadoop/hadoop2.7.3目录
b)输入bin/hadoop dfsadmin -report命令

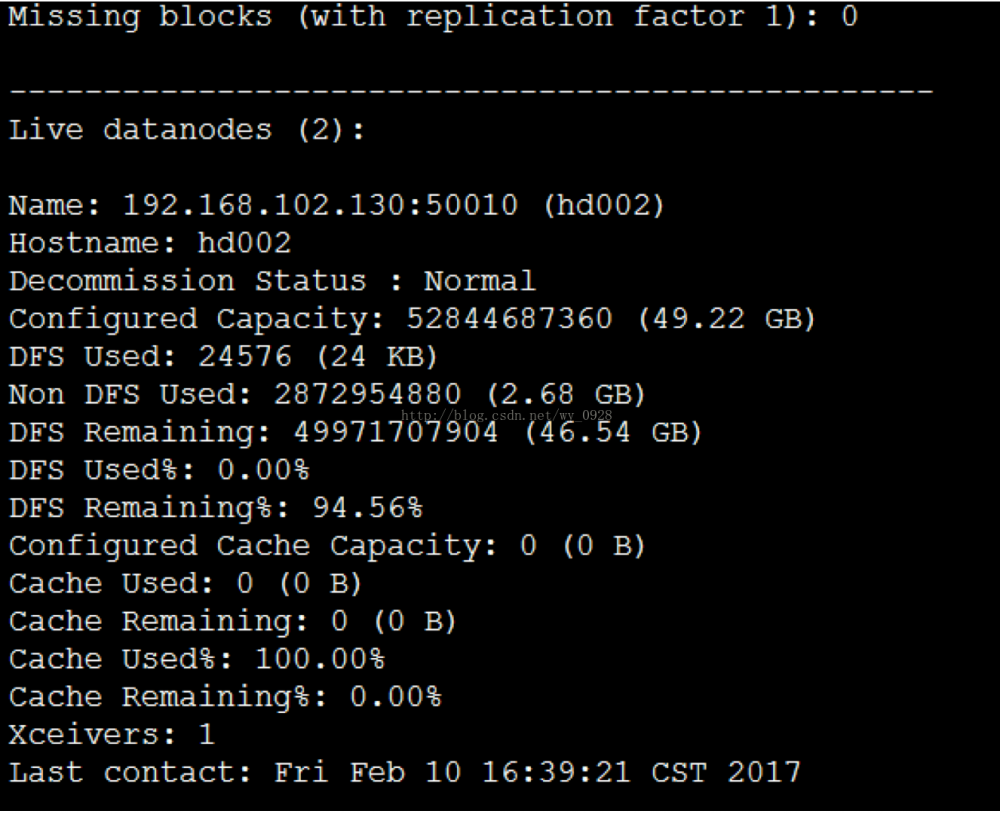
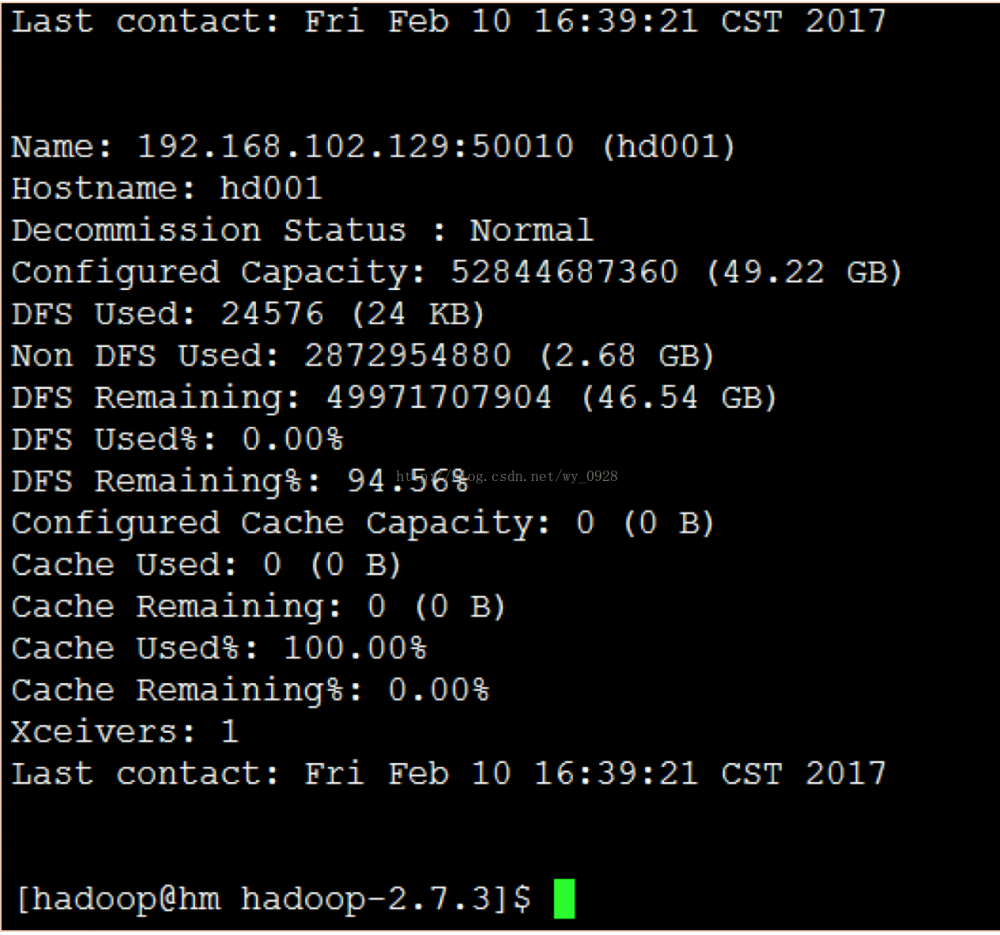
(5)查看监控界面
a)在浏览器地址栏输入192.168.102.128:8088回车
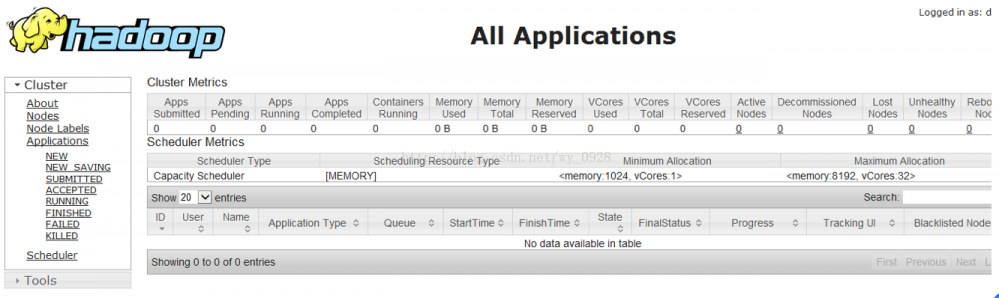
hadoop1.x端口是50030,后来2.x改为8088了。
【后记】
1.开启hadoop集群方法
所有虚拟机开机-Xshell远程登录所有虚拟机(建议用hadoop用户)-在主节点用hadoop用户进入/hadoop2.7.3目录,输入/sbin/start-all.sh回车。
2.关闭hadoop集群方法
在主节点用hadoop用户进入/hadoop2.7.3目录,输入sbin/stop-all.sh回车。
3.网页监控
192.168.102.128:8088
正文到此结束
- 本文标签: 百度 博客 希望 apache tab iptables Slaves UI 初学者 解决方法 fstab 文件系统 ssh Hadoop 网卡 集群 配置 空间 参数 删除 IO java 源码 ip cat 安装 注释 修改密码 http 图片 rmi rpm shell 进程 map 时间 软件 主机 ORM 目录 测试 VMware Oracle apr SDN key core queue 分布式 linux 服务器 db grep centos 管理 src 下载 id 安装配置 node tar Namenode 大数据 XML 同步 SecureCRT Master root 端口 HDFS 数据 Document
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

