AAAI-17获奖论文深度解读(下):蒙特卡罗定位和推荐系统
机器之心曾深度解读了 AAAI-17 大会评出的杰出论文和 Blue Sky Idea Awards 获奖论文 ,本期我们带来对 AAAI-17 两篇经典论文奖获奖论文的深度解读。
AAAI 经典论文奖会授予最具影响力论文的作者,这篇论文会来自某年会议论文。每一年,作为评选对象的会议都会往后推一年。
2017 年的奖项会授予 1999 年在佛罗里达召开的第 16 届 AAAI 会议最具影响力论文。
论文评选是以影响力为基础的,比如:
-
开启了一个新的研究(子)领域
-
导致了重要应用
-
回答了一个长期困扰人们的问题/议题或者澄清了之前模糊的地方
-
做出了能够载入子领域历史的主要贡献
-
已经被视为重要的研究,已经被人工智能里(或外)的其他领域使用
-
已经被大量引用
本届经典论文有两篇:一篇经典论文奖,一篇经典论文提名奖(Honorable Mention)。
AAAI-17 经典论文奖(Classic Paper Award)
论文标题:蒙特卡洛定位:移动机器人的有效位置估计(Monte Carlo Localization: Efficient Position Estimation for Mobile Robots)
作者:Dieter Fox, Wolfram Burgardy , Frank Dellaert, Sebastian Thrun

机器之心技术分析师 Elva Wang 对该论文进行了深度解读:
蒙特卡罗定位(Monte Carlo Localization/MCL)使用了随机化的样本(randomized samples)来表征一个机器人在环境中的位置的可信度(belief)。和之前的方法相比,这种方法在精确性、效率和易用性方面的表现是值得称道的。MCL 最早是在 1999 年的国际机器人与自动化会议(International Conference on Robotics and Automation)上提出的,并在机器人领域的基于样本的评估(sample-based estimation)中首次得到了应用,而现在它已经在种类广泛的应用中得到了使用。
这种新的基于样本的蒙特卡罗定位(sample-based Monte Carlo Localization)在计算上非常高效,同时还保留了它表征任意分布的能力。这种 MCL 应用了基于样本的方法来逼近样本数量所采用的概率分布,它是可以在线调整的,因此可以动态地调用样本集,这是基于网格的方法(通过三维网格进行表征,在计算上非常繁琐)所无法实现的。
引言
在移动机器人应用中,基于传感器的定位一直以来都被认为是一个关键的问题。定位(localization)是一种在线时间状态估计(on-line spatial state estimation),其中移动机器人需要在一个全局坐标系中估计其位置。定位问题有两种:全局定位(global localizaion)和位置跟踪(position tracking)。这篇论文指出全局定位问题难以解决,因为涉及到并不知晓其起始位置的机器人;而位置跟踪问题则已经得到了很好的研究,其中机器人知晓起始位置,只需考虑其运动过程所带来的误差即可。
机器人定位上的已有方法包括马尔可夫定位(Markov localization)、卡尔曼滤波(Kalman Filtering)、粒子滤波(Particle Filtering)、即时定位与地图构建(SLAM)和多机器人定位(Multi-robot localization)。
1. 马尔可夫定位:
-
中心思想:通过在可能位置上的概率分布来表征机器人的可信度(belief),并在机器人感知或移动时使用贝叶斯规则和卷积来更新这个可信度。
-
马尔可夫假设:如果知道当前状态,那么过去和未来的数据是独立的。
2.卡尔曼滤波:
-
中心思想:将定位问题当作是一个传感器融合问题(sensor fusion problem)
-
假定:高斯分布函数
3.粒子滤波(蒙特卡罗定位)
-
中心思想:由一个包含了 N 个加权的、随机的样本或粒子的集合所确定的后验可信度(posterior belief)
-
即时定位与地图构建(SLAM)
4.多机器人定位
在这篇论文中,作者思考了基于卡尔曼滤波的技术和马尔可夫定位(包括拓扑马尔可夫定位和基于网格的马尔可夫定位)的局限性,然后又提供了基于样本的密度近似蒙特卡罗定位(sample-based density approximate Monte Carlo localization)。这些方法的局限性包括:
-
基于卡尔曼滤波的技术基于一个假设:机器人位置的不确定性可以通过一个单峰高斯分布表示。基于卡尔曼滤波的技术已被证明在持续跟踪机器人的位置上是稳健且精确的。但是,这种方法不能处理多模态的密度,而这在全局定位中很常见。其另一个局限是其最初的姿态必须是已知的,同时高斯不确定性要达到最大。
-
越来越丰富的方案使用拓扑马尔可夫定位(Topological Markov localization)方法来表征不确定性,其已经避开了 vanilla 卡尔曼滤波中固有的高斯密度假设,并且可以通过状态空间的表征所使用的离散化的类型而大致区分开。但是,其状态空间粗糙的分辨率限制了位置估计的准确度。
-
基于网格的马尔可夫定位方法在处理多模态和非高斯密度上非常强大。但是,过度计算负载和表现先验可信度的状态空间大小和分辩率也影响该方法的性能。此外,其计算要求对准确度也有影响,因为并非所有的测量都可以被实时处理,因此有关该状态的有价值的信息就会被丢弃。
通过使用一种基于采样的表征(sampling-based representation),相对于这一领域早期的成果,MCL 有几个关键优势:
-
与已有的基于卡尔曼滤波的技术相比,它能够表征多模态分布,因此能够全局地定位机器人。
-
相比于基于网格的马尔可夫定位,它能极大地减少对内存的需求,并且可以以相当高的频率集成测量。这个在线的算法非常适合任何时间的实现。
-
因为其样本中所表征的状态不是离散的,所以其在有固定的单元大小时比马尔可夫定位更加准确。
-
其实现要容易得多。
蒙特卡罗定位
蒙特卡罗定位通常被称为粒子滤波(Particle Filter),这是一种重要性重采样(SIR),也被称为自举滤波(bootstrap filter)、蒙特卡罗滤波、凝聚算法(condensation algorithm)或适者生存算法(survival of the fittest algorithm)。其关键思想是通过一个有 N 个加权的、随机的样本或粒子 S 的集合来表示后验可信度 Bel(l)。
MCL 中的样本表示成 <<x, y, theta>, p>,表示了机器人的位置(坐标 x,y,方向 theta)和数值权重因子 p,并假设 :

机器人移动
当机器人移动时,MCL 在移动命令之后生成 N 个近似该机器人位置的新样本,其中每一个样本都是从之前计算出的样本集中随机取出的,取出概率由它们的 p 值决定。
然后使用观察到的动作 a,根据 P(l | l』, a) 生成一个单个随机样本,进而得到该新样本的 l。该新样本的 p 值为 N^{-1}。
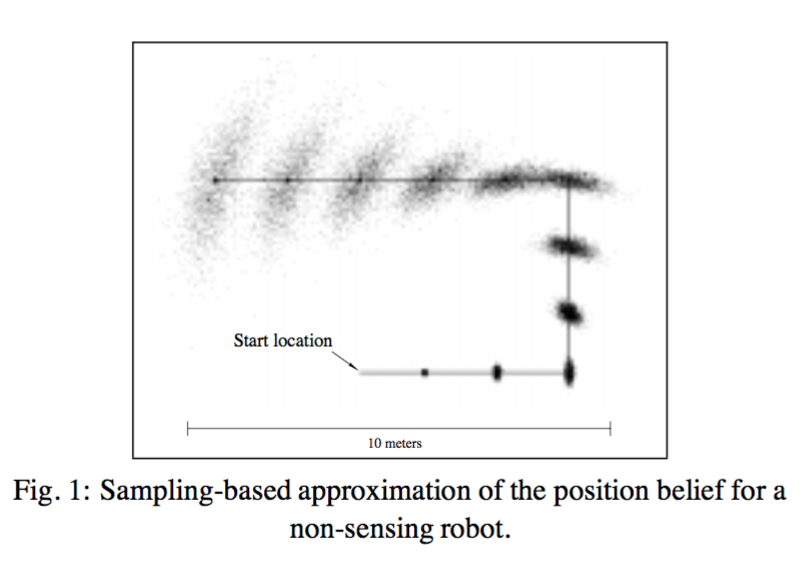
一个非传感机器人的基于采样的位置可信度近似
注意这种采样技术的效果——从一个已知的起始位置开始,然后按实线的指示和不确定性不断增加的样本集近似分布来执行动作;其中不断增加的不确定性代表了由于滑移和漂移所造成的位置信息的逐渐损失。该运动模型必须为噪声提供补偿。这会不可避免地导致运动更新过程中粒子发散。这是可以预见的,因为如果一个机器人不感知环境地盲目移动,那么它对自己的位置就不会很确信。
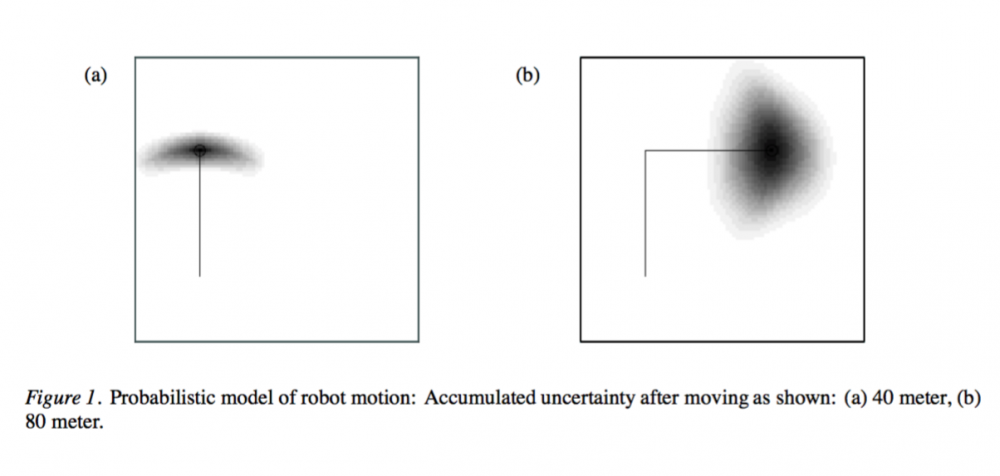
图 1:机器人运动的概率模型:在如图所示的运动之后积累的不确定度:(a) 40 米,(b) 80 米
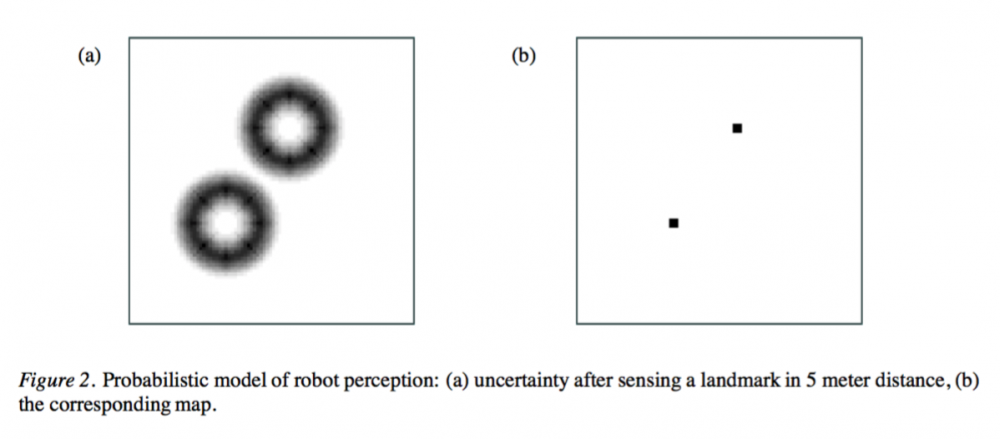
图 2:机器人感知的概率模型:(a) 在感知到 5 米距离内的一个地标后的不确定度,(b) 相应的地图
传感器读数
传感器读数是通过重新加权样本集而整合进来的,这种方式在马尔可夫定位中实现了贝叶斯规则。这种加好的样本对于机器人丢失其位置轨迹的罕见事件中的重新定位(relocalization)是很关键的。如果当 MCL 使用有限样本集时没有生成接近机器人正确位置的样本,那么通过加入数量很少的随机样本,MCL 可以有效地重新定位机器人以解决该问题。
设 <l, p> 是一个样本,p ← alpha P(s | l),其中 s 是传感器的测量,而 alpha 是归一化(normalization)。这些参数总的来说必须使:

一种能在 O(N) 时间有效执行这个重采样过程的算法可见于 (Carpenter, Clifford, & Fernhead 1997)。
补充材料
为了帮助读者更深入地理解,机器之心分析师在下面提供了一些补充材料,其中包括伪代码和一个一维机器人的示例。
伪代码
给定一个环境的地图,该算法的目标是让机器人确定其在该环境中的位置。每次该算法都会以之前的可信度 :

致动命令 u_t 和从传感器收到的数据 z_t 作为输入;然后输出新的可信度 X_t。

示例
这是一个一维机器人的示例。假设一个机器人在一维的带有三个相同的门的圆形走廊中运动,它的传感器会根据自己的位置是否有门而返回 ture 或 false。在这三次迭代的最后,和预想的一样,该机器人的实际位置上的大部分粒子都得到了覆盖。
实验结果
在本论文中,研究者相对于基于网格的方法而对 MCL 进行了评估,测试了 MCL 在仅使用视觉信息的极端情形下的表现,并评估了 MCL 的自适应采样方法的可用性。
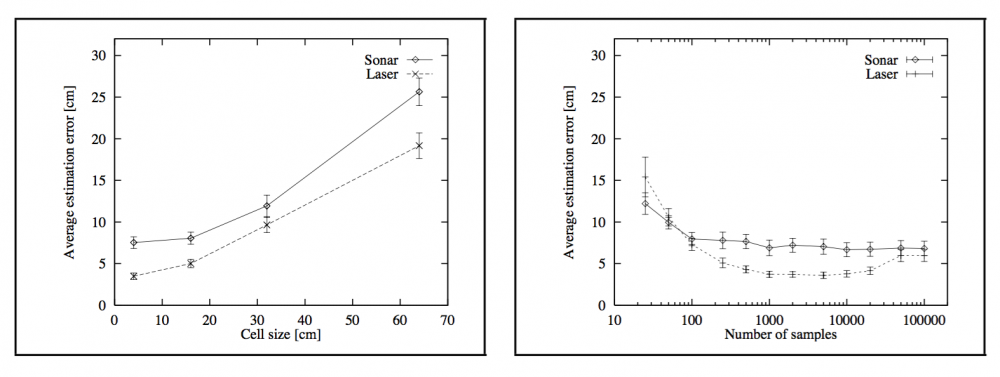
相比而言,基于网格的方法(分辨率为 20 cm)与使用 5000 个样本的 MCL 相比,所需的内存量多达十倍。在全局定位过程中,使用基于网格的方法在整合单次传感器扫描时需要多达 120 秒时间,而在相同条件下 MCL 只需连续不到 3 秒。此外,基于网格的定位的结果不是实时生成的。

图:(a) 使用不同的空间分辨率的基于网格的马尔可夫定位的准确度,(b) 使用不同数量的样本(对数标度)的 MCL 的准确度。
在基于视觉的定位,基于网格的定位不能准确跟踪机器人,因为其计算上的负载使其不可能整合足够的大量图像。但是,MCL 在全局定位和位置跟踪上取得了成功,该系统能够跟踪多个假设以从定位错误中恢复。
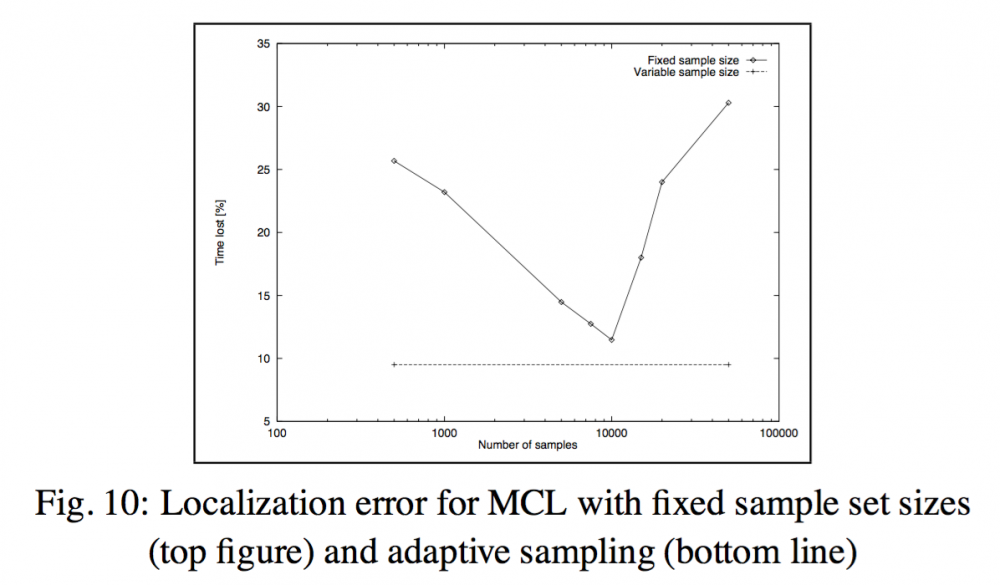
相对于固定的样本集,MCL 在自适应采样(adaptive sampling)的评估中表现更好。顶部曲线描绘了在不同的样本集大小上误差大的频率,而底部的线则给出了自适应采样方法的同样结果。在固定的样本集大小上,自适应采样比最好的 MCL 的误差还要小。
为了评估采样在定位中的效用,该论文的作者在一系列真实世界环境中对 MCL 进行了透彻的测试,其应用了三种不同的传感器(相机、声纳和激光测距数据)。其中两个主要结果为:
-
比大多数之前精确的马尔可夫定位算法,MCL 给出了显著更加精确的结果,同时内存和计算资源的消耗也低一个数量级。在一些案例中,MCL 能可靠地定位之前的方法无法起效的机器人。
-
大体来说,在固定的样本集上,自适应采样的表现和 MCL 差不多。但在涉及到许多有不同不确定度的场景(全局 vs 局部)中,自适应采样比固定样本大小更优。
未来
未来,这种基于样本的定位的更高效将会被应用到多机器人场景上,其中不同机器人的样本集可以在机器人检测到其它机器人时进行同步。他们也在计划将蒙特卡罗方法应用于地图获取问题,其中最近的研究工作已经实现了新的统计框架,这种框架已被成功应用于使用网格表示的大型圆形环境中。
评论
在 AAAI 2017 上,Sebastian Thrun 被授予了两个奖项,AAAI 经典论文奖和 AAAI/EAAI 优秀教育家奖。他是 Udacity 的联合创始人兼首席执行官,并创立了谷歌的自动驾驶团队。去年,Udacity 开发了第一个自动驾驶汽车纳米学位(Nanodegree)项目,在第一轮就吸引了超过 11000 个申请。
在实践中,该 MCL 在线自适应采样实现了比基于网格的马尔可夫更高效、更精确的和更有价值的算法。补充材料部门的伪代码也很容易实现。MCL 依照先验概率中最可能的方式随机的猜测可能的位置,并调整样本数量与传感器数据中的不一致数量比。
相比于 SLAM,包括 MCL 在内的所有定位方法都需要先验地图或预定义地图,因为定位的目的是定位一些关于机器人的特征。我们需要这些特征确定机器人的位置。如果特征不确定,就适合使用 SLAM。
经典论文提名奖
经典论文提名奖(Honorable Mention)被授予了发表于 1999 年的论文:
论文标题:Combining Collaborative Filtering with Personal Agents for Better Recommendations
作者:Nathaniel Good, J. Ben Schafer, Joseph A. Konstan, Al Borchers, Badrul Sarwar, Jon Herlocker, John Riedl
理由:找到了将协同过滤与内容过滤结合起来的有效方式,能够为用户做出更好的推荐。
机器之心技术分析师李俊毅对此论文进行了深度解读:
论文介绍
这篇论文展示了一种组合信息过滤和协同过滤这两种算法的方式。文章提出了一种能够将个人信息过滤(IF)智能体(agent)与产品社区用户的意见结合起来以产生比单纯的基于智能体或者基于用户群更好推荐效果的协同过滤(CF)框架。文章也表明,使用 CF 创造一个个人智能体组合能够得到更好的结果,比单独智能体或其他机制的组合效果都要好。从这些结果种可以得到的一个重要的暗示是用户可以让 CF framework 来帮助用户从所有的选项中选择最优的结果而不用自己亲自选择。在那个年代,这是搭建这一框架的良好尝试。
在这篇论文解读中,除了介绍有关推荐系统的基本思想,我们也打算帮助读者了解假设以及实验设计,并基于 RSs 的当前发展给出我个人的看法。最后还会推荐些有价值的阅读材料帮助读者深入研究推荐系统。
一. 背景——信息超载与推荐系统
时间的推移,我们正在进入一个被称为信息过载的时代。现在,人们发现去寻找他们想要的信息变得越来越困难。用户想要从大量繁杂的信息中寻求最感兴趣的信息,而公司想要将他们的产品有效地推荐给用户。然后这两者在现在都很难实现。因此,推荐系统应运而生来解决这个问题。
Ricci 等人对推荐系统给出了定义:tools which can「recommend a set of items for a user or a set of users for an item」
推荐涉及到了很多的决策(decision-making)的过程,包括知识来源(训练集)以及推荐算法。因为 RSs 是个性化的,并且是从已经被别人知道的且不是个性化定制的产品中进行推荐,所以 RSs 不仅仅可以帮助用户有效的找到感兴趣的东西,更可以帮助公司找到一个有效的方式来介绍他们的产品给潜在的用户。
推荐系统,萌芽于 1970 年,从 19 世纪 70 年代开始发展并逐渐商业化,到现在已经发展了超过二十年。Martin 等人在 2011 年总结了两次 RSs 的潮流,这将有助于初学者理解 RSs 的发展进化。我们以下将要 review 的论文被发表在 1999 年,算是第一次大潮的结尾和第二次大潮的开始。
第一次浪潮发生在 1990 到 2000 年,电子邮件和新闻报纸等一起带来了第一次信息过载,很多人开始重视这个问题,并且 RSs 出现了。这个是 RSs 的启蒙阶段。然而,dot-com 泡沫在 2000 年破裂,狠狠的打击了 RSs 的发展。之后第二次浪潮出现在 2000 年间,这是 RSs 的快速发展阶段。随着互联网的用户和产生的数据在急剧增长(例如 电子商务和社交网络),RSs 在帮助公司传递消息给用户的这个过程中逐渐扮演着一个越来越重要的角色。举例而言,Netflix、Amazon、Yahoo!音乐以及 Pandora 都在使用 RSs 来推销他们的商品。协同过滤以及内容过滤算法在这段时间变得越来越流行。在 2006-2009 年间,Netflix 发布了一个包含数百万电影评分数据库,并且号召相关研究人员来根据它来开发一个新的能够打败他们自己的推荐系统,Cinematch [21]。这个竞赛在当时掀起了一股 RSs 研究热潮。在当时有许多杰出的研究者以及算法诞生,最后这个比赛以「BellKor's Pragmatic Chaos」的获胜告终。
二. 应对信息超载的常见解决方案
1.三种应对信息超载的方法
这里有三种通常应对信息过载的方法。每个方法都对应处理不同的问题:
-
信息检索: 完成瞬时出现的兴趣查询
-
信息过滤:将新的信息流分化归类
-
协同过滤:我应该看哪个 items(总体或者从某个集合)或者我有多喜欢这些 items。
这三种方法每一种对于推荐系统来说都十分重要。我们可以简单地把 IR 当作搜索引擎,把 IF 看作基于基于内容过滤的方法(方便理解)。下面是一些对这三个技术的一些解释:
信息检索是一个可以根据用户的请求从一个信息库中检索信息的系统。如果你正在使用 google,那么对你而言理解这个概念应该并不困难。在这篇 paper 中,作者认为由于 IR 并不能抓取到用户的偏好,并不是很有价值因为他们并没有抓取到除了用户的精确的请求之外的偏好,所以作者并没有在他的框架中使用 IR。
协同过滤系统构建一个数据库容纳着供用户选择的项目。举例而言,Mike 和 John 都是学习计算机科学的学生,那么 Mike 买了一本名叫机器学习的书而 John 没有,那么 RSs 就会将这本名叫机器学习的书推荐给 John,根据相似用户。
协同过滤算法有很多优点:
-
用户和数据友好性:可以处理分结构化信息,能够发现新的兴趣点,并没有专业知识需求,并且可以个性化推荐;
-
性能方面:自动化程度高,并且性能是会随着时间的推移变好的
-
交互性好:协同过滤能够让用户之间互相分享选择,并且一小部分的用户额选择是会影响到推荐系统给别的用户的推荐结果的
尽管 CF 有很多优点,但它依然存在稀疏性问题,冷启动问题以及可解释性差的问题。下面我们要介绍的 IF 可以在某些方面解决这个问题。
信息过滤(IF)需要一个针对用户需求和偏好地简介。最简单的系统需要用户手动的或者在一定的协助下创建这个简介。举例而言,如果 Mike 买了一本叫做 C++ programming 的书,那么 RSs 就比较倾向「认为」Mike 也会喜欢「Data Structure」或者「C programming」这本书因为这些书之间都十分的相似。现在,我们把协同过滤和基于内容的过滤当作两种信息过滤的方式,但是这篇 paper 把他们分开考虑。因此,如果你在理解这个概念的时候有困难,暂时将它当作基于内容的过滤会有帮助。
信息过滤依旧不能应对所有的情况。尽管它能够解决冷启动的问题,并且也很有效率,但是依然有很多问题存在:在信息挖掘方面缺乏全面性,推荐内容的限制和用户反馈的不足。
无论是 CF 还是 IF 都不是完美的,但是他们都有自己的优势,所以有一些研究者会尝试组合他们。
2.混合推荐系统
一些混合推荐系统会组合两个或者更多的推荐技术来得到一个更好的可以克服单一推荐技术的缺点的推荐系统。尽管我们已经有了两个流行的并且也有一定效率的推荐算法,IF 以及 CF,但是他们都不能够满足所有的需求。因此有很多方法通过组合这两种方法来避免 CF 或者 IF 的缺点:
-
组合 CF 系统和 IF 系统的预测结果,比如使用投票策略或者评级策略。例如 Pazzani 的组合就是将每个系统的输出作为一个投票集合,然后将他们组合
-
基于协同过滤算法,添加一些 IF 算法的特点,就像我们这篇论文的思路。
-
基于 IF 算法,添加协同过滤算法的特点。
-
构建一个新的可以结构系统过滤算法和 IF 算法的特点的模型。例如,我们可以在使用协同过滤进行推荐之前使用基于内容的过滤先处理数据集。如果我们把整个决策过程分开的话,这看起来有点像是预处理,但实际上要复杂一些。
Sarwar, et al. (1998) 提出了一个将内容过滤评分整合协同过滤器系统的模型。它是一个简单但是稳定的可以评估用户网新闻文章的拼写质量的智能体,它甚至可以作为一个协同过滤社区中有价值的一个参与者。在那篇研究中,他们表明这些过滤器机器人程序——作为协同过滤系统的参与成员的评分机器人——如何通过给与他们有类似偏好的人高的偏好相关性,来帮助这些用户。而对于并不赞同自己的用户,CF 会分配一个低的偏好相关性,并不会利用自己的评分来帮助他们。
我们正在 review 的这篇论文从三个重要的方面延伸了过滤器机器人程序的概念。首先,使用了一套更加智能的过滤器机器人程序,包括会学习的智能体,它能根据个体用户定制化。第二,这篇研究被应用于小型社区,包括使用 CF 为单个人类用户服务。第三,评估了同时使用多过滤器机器人程序的效果。另外,我们也探索了其他组合机制,作为 CF 的替代。我们证实,CF 是一个有用的框架,无论对于综合智能体来说,还是用于结合智能体与人类。
三.数据集与评估指标
数据集
有许多能被用来训练推荐系统的数据组,比如,Netflix dataset, CiteULike, Delicious 数据组以及 MovieLens 数据组。这篇论文基于 MovieLens 进行实验【2,3】。用于实验的用户评分来自 MovieLens system (http://movielens.umn.edu),这个系统大概有 3 百多万评分,来自 8 万多名用户。随机挑选 50 名用户的 120 多条电影评分。针对每个用户,不放回地随机挑选三套电影/评分对。第一套是 50 个评分,叫做训练集合,用来训练个性化信息过滤智能体;第二套是 50 个评分,叫做关联集合,在基于用户组合,智能体组合以及用户和智能体的组合的时候使用。最后一个集合有 20 个评分,作为测试集合。在每个试验中,目标用户的测试评分会被保留并且和系统产生的推荐结果做对比。
评估指标
-
推荐系统研究者会用一些不同的评估方法来评估推荐结果的质量
-
覆盖率:覆盖率是评估系统能够提供的推荐结果中 items 的数量
-
统计精度度:通过对每一个 item 比较数字化的评估 (预测) 值和用户的评分(真实值)来评估系统的准确度。我们通常用 mean absolute error 或者 root mean squared error 来帮助评估这个指标。
-
决策支持度:苹果推荐结果对于用户选择高质量的 item 有多大额帮助。最常用的决策支持度评价指标有 reversal rate、weighted errors 和 ROC 敏感度。ROC 经常用来评估算法性能,也是这篇论文主要使用的指标之一。ROC 敏感度是从 0 到 1 在变化的,其中 1 代表完美,0.5 代表随机。
-
统计重要性也可以用平均绝对误差(mean absolute error)来进行评估
-
评估假设:面对多个评价指标的话,评估假设(是否成立)是一个很困难的工作。我们认为统计精确度和决策支持度都很重要。当出现 A 和 B 在两个指标上面表现不同但是又无法比较的时候,就是说当 A 假设在 x 指标上比 B 假设要好,但是 y 指标上却相反,那么我们就认为他们中的任意一个都是潜在的「最优智能体」,就用所有的智能体与别的模型进行比较;然而,如果 A 智能体在 x 指标上比 B 智能体要好,y 指标 s 却相差不多,那么我们认为 A 智能体远胜于 B 智能体。
假设与实验设计
这篇 paper 呈现了一种很有趣的实验设计思路。首先,它给定四个假设然后根据这些假设进行实验设计,之后通过实验来验证这些假设。这是我们可以从这篇 paper 中学习到的很棒的一点。基于四个假设,这个 paper 设计了两个层次。第一比较每个模型的不同实现, 并且选择最好的一个作为 (每个模型的) 代表. 第二, 通过比较每个模型的代表来比较不同的模型。下面是四个假设:
-
(基于)一组用户(的实验)可以提供比基于单个个性化的智能体更好的推荐效果
-
(基于)个性化智能体的组合(的实验)可以产生比单个个性化智能体更好的效果
-
(基于)一组用户(的实验)可以提供比基于个性化智能体的组合更好的推荐效果
-
(基于)个性化智能体以及一组用户的组合(的实验)可以产生比单使用智能体组合或者用户组合更好的效果
总的来说,对智能体和用户的组合要优于单单使用他们中的任何一个;一组用户的选择要优于任何种类的个性化智能体。这篇论文使用 控制变量法来设计了四个模块,如下图所示:
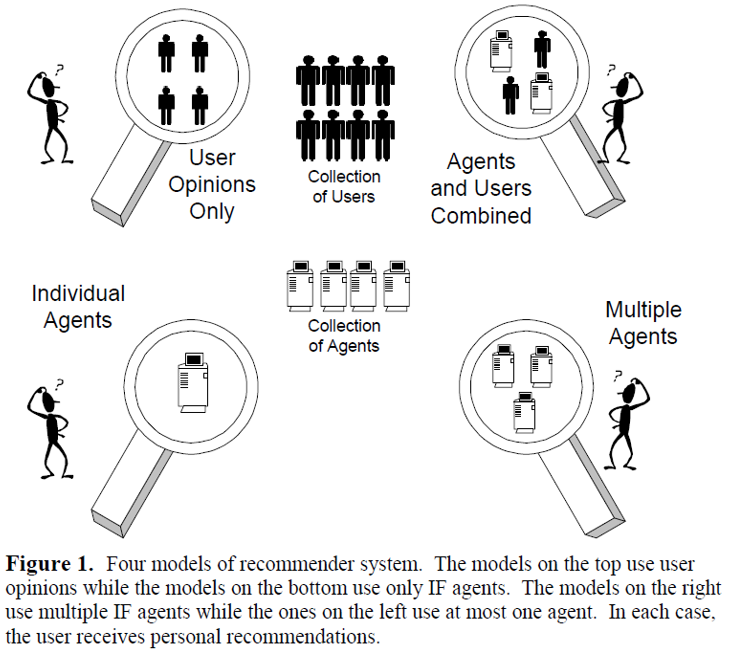
基于我们所说的假设,四个模块分别是:一组用户的选择,单独的一种智能体,多种智能体组合以及智能体和用户(的选择)的组合。
1. 只基于用户选择进行实验
DBLens,是被包括作者在内的 GroupLens 的一个研究项目。它是一种基于 Orcle 的用来实现协同过滤的工具箱。并且它语序实验者通过控制几个参数来改变系统性能,覆盖率以及准确度。因此这篇论文使用了 DBLens 的协同过滤器引擎来探究协同过滤器算法。
2. 单种 IF 智能体
这篇论文探究了三种 IF 智能体:DGBots、RipperBot 以及 Genrabots。
-
Doppelganger Bots (DGBots) 使用 IR/IF 技术(一种改进 TFIDF 技术)基于电影的内容特征来创建一个可以反应用户偏好的简介,生成一个预测性的个性化机器人。本文中为广播的数据,描述性的关键词以及两者的组合分别创建了 DGBots。
-
Doppelganger Bots (DGBots)是一种通过 IR/IF 技术基于电影内容特征来创建和预测用户偏好的个性化机器人。IR/TF 技术改进自 Salton 和 Buckley 于 1987 年提出的 TFIDF。本文中为传播的数据,描述性的关键词以及两者的组合分别创建了 DGBots.
-
RipperBot 是在 1995 年被 Willam Cohen 发明的归纳逻辑程序,而它在有限的类型标志符以及 200 个最常见的关键词的数据集上表现最好。
-
Mega-GenreBot 通过使用线性回归来在每个用户的训练集上面训练实现,而且根据后期的实验它确实提供了最好的推荐结果。
3. 这篇论文使用了四个不同的策略来组合智能体:
-
BestBot:通过在相关数据集测试每个 bot 然后选择 MAE 最低的那个 bot 作为最好的 bot。
-
Agent Average:通过分别计算 5 个或者 23 个智能体的算术平均得到
-
Regression:我们使用线性回归来针对一个给定用户产生一个「最适应」的组合
-
CF Combination:我们使用 DBLens 协同过滤引擎来创建一个智能体的协同过滤组合
4. IF 智能体和用户选择的组合
因为用户评分是不完整的,并且基于 23 个智能体的 CF 被证明是最有效的对 IF 的组合,我们使用 CF 来组合 23 个智能体以及全部的 50 个用户。
结果与结论
在结果中,这篇论文分别讨论了四个假设的情况,并且对每个假设都得出了结论。最后,我们发现假设 1 和假设 3 是成立的,但是假设 2 和假设 4 是不成立的。由于分析方法类似,所以我们着力分析假设 1 的情况。
对于假设 1 来说,就像我们从这张表中看到的情况,低的 MAE 表示高的准确度,而高的 RCO 代表高的决策支持度。只有 RipperBot,Mega-GenreBot,以及基于 cast 和 keywords(表格中)的 DGBot 没有被别的智能体碾压。但是他们表现都不完美。RipperBot 有高的准确度但是决策支持度不是很好;DGBot Comb 有最好的决策支持都但是却有相对低的准确度;Mega-GenreBot 在两个指标上面都排第二。所以我们用他们和 CF of Users 进行比较。结果发现,RipperBot 拥有最棒的准确度,而且要优于 CF of Users;而 CF of Users 尽管拥有最好的决策支持度,但是却好的十分有限,相差不是很多。所以我们综合而言,判定假设 1 不成立。

部分结果
分析和假设 1 十分类似,对于假设 2 来说,我们可以看到,CF 1 usr, 23 bots(应该是 bot,不过作为为了节省空间写作 bts)要在两项指标上面优于 Ripperbot, MegaGenreBot 以及 DG Combo Bot。对于假设 3 来说,CF 1 usr,23 bots 要优于 CF(users only);对于假设 4 来说,CF 50 usr, 23 bots 要优于 CF 1 usr, 23 bots。所以我们最后判定假设 2 和 4 成立,而 3 不成立。
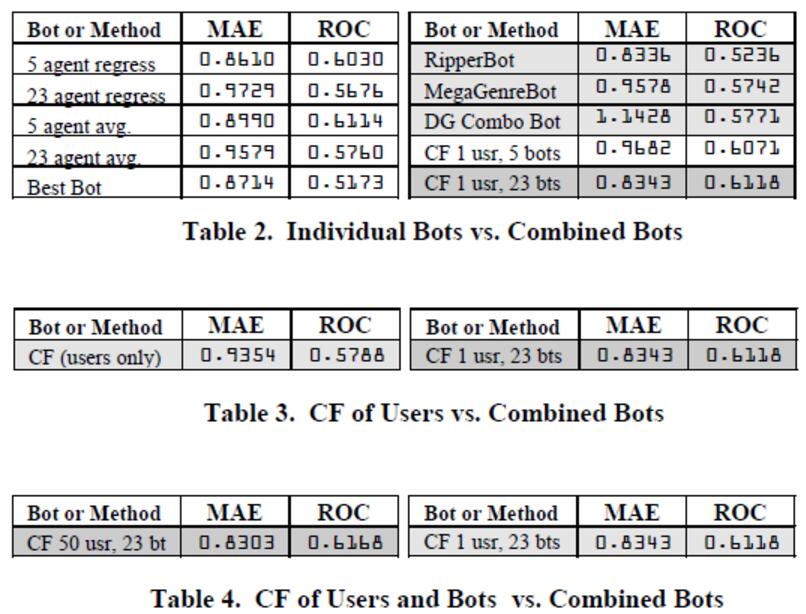
结论
这篇论文发现的最重要的结果是用 CF 来组合智能体的价值以及用 CF 来组合智能体和用户的价值。这个意味着他们确确实实找到了一个可以用来组合 IF 智能体以及用户的并可以产生更好的结果的 CF 框架。除此以外,实验结果中还发现了 CF 作为智能体的组合机制要比线性回归更好,这属于意外收获出乎意料的。实验结果表明,CF 在数据的行数接近列数的时候可以避免过拟合数据并且可以处理不完全的数据集合。
或许因为作者的实验是基于自己以往的正面经验,所以 RipperBot 和 CF 在 50 个用户的数据集上取得了很好的效果,但是进一步调整之后情况却并不很好,这一点作者也无法给出解释。
在未来,他们打算实现推荐系统中智能体与用户的进一步结合。具体地说,他们有兴趣开发一个有大量用户与智能体共存的社区。他们希望回答的一个问题是相似情况额用户,能够从根据彼此的情况训练出来的智能机中得到有用的信息呢?
评论
该论文演示了一个能够结合个性化 IF 代理和用户社区观点的 CF 框架。随着时间发展,推荐系统会变得越来越成熟。大约从 1999 年起,许多研究团队都在尝试寻找改进推荐系统性能的好方法。该论文想出了结合 IF 和 CF 的好思路,尽管这种思路在现在来说很普遍,但在当时来说还是很有意义的。
在这一框架中,作者们没有提到信息检索,因为除了特定查询,它不会捕捉用户偏好的其他信息。在此论文中,这是合理的。因为它的框架适用于这种情况。然而,我认为它对改进推荐系统很有帮助,因为这是来自用户的特定需求,可通过推荐系统调整结果。此外,如果用户有明确的要求,推荐系统反而会难以给出结果。因此,我认为搜索引擎和推荐系统的结合在未来会更加流行。
关于度量指标,我们如今也有更多的方式。新奇程度 [13]、惊讶程度 [14] 和可理解程度 [15] 都可作为推荐系统的指标。如果使用这些度量指标评估该实验,可能会有新的发现。
阅读推荐
-
Adomavicius, Gediminas, and Alexander Tuzhilin. "Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions." IEEE transactions on knowledge chachu'lnd data engineering 17.6 (2005): 734-749.
-
Ricci, Francesco, Lior Rokach, and Bracha Shapira. Introduction to recommender systems handbook. Springer US, 2011.
-
Martin, Francisco J., et al. "The big promise of recommender systems." chulchuI Magazine 32.3 (2011): 19-27.
-
Resnick, Paul, and Hal R. Varian. "Recommender systems." Communications of thchu'le ACM 40.3 (1997): 56-58.
-
Burke, Robin, Alexander Felfernig, and Mehmet H. Göker. "Recommender schulstems: An overview." AI Magazine 32.3 (2011): 13-18.
-
Bennett, James, and Stan Lanning. "The netflix prize." Proceedings of KDD cup and workshop. Vol. 2007. 2007.
第一篇解读文章的参考文献:
-
Dieter Fox, Wolfram Burgard, Sebastian Thrun, “Markov Localization for Mobile Robots in Dynamic Environments”, J. of Artificial Intelligence Research 11 (1999) 391-427
-
Sebastian Thrun, “Probabilistic Robotics: Tutorial presented in AAAI 200” – available through S.Thrun Web page
-
Ioannis M. Rekleitis. "A Particle Filter Tutorial for Mobile Robot Localization." Centre for Intelligent Machines, McGill University, Tech. Rep. TR-CIM-04-02 (2004).
-
Frank Dellaert, Dieter Fox, Wolfram Burgard, Sebastian Thrum "Monte Carlo Localization for Mobile Robots." Proc. of the IEEE International Conference on Robotics and Automation Vol. 2. IEEE, 1999.
-
Sebastian Thrun, Wolfram Burgard, Dieter Fox "A Probabilistic Approach to Concurrent Mapping and Localization for Mobile Robots "- Autonomous Robots, 1998, Springer
-
Sebastian Thrun, Wolfram Burgard, Dieter Fox. Probabilistic Robotics MIT Press, 2005. Ch. 8.3 ISBN 9780262201629.
-
Sebastian Thrun, Dieter Fox, Wolfram Burgard, Frank Dellaert. "Robust monte carlo localization for mobile robots." Artificial Intelligence 128.1 (2001): 99–141.
-
Dieter Fox. "KLD–Sampling: Adaptive Particle Filters." Department of Computer Science and Engineering, University of Washington. NIPS, 2001.
第二篇解读文章的参考文献:
-
1. http://nathangood.com/
-
2. https://movielens.org/_ (https://movielens.org/)
-
3. https://en.wikipedia.org/wiki/MovieLens_ (https://en.wikipedia.org/wiki/MovieLens)
-
4. Pazzani, Michael J. "A framework for collaborative, content-based and demographic filtering." Artificial Intelligence Review 13.5-6 (1999): 393-408.
-
5. Claypool, Mark, et al. "Combining content-based and collaborative filters in an online newspaper." Proceedings of ACM SIGIR workshop on recommender systems. Vol. 60. 1999.
-
6. Balabanović, Marko, and Yoav Shoham. "Fab: content-based, collaborative recommendation." Communications of the ACM 40.3 (1997): 66-72.
-
7. Soboroff, Ian, and Charles Nicholas. "Combining content and collaboration in text filtering." Proceedings of the IJCAI. Vol. 99. 1999.
-
8. Basu, Chumki, Haym Hirsh, and William Cohen. "Recommendation as classification: Using social and content-based information in recommendation." Aaai/iaai. 1998.
-
9. Popescul, Alexandrin, David M. Pennock, and Steve Lawrence. "Probabilistic models for unified collaborative and content-based recommendation in sparse-data environments." Proceedings of the Seventeenth conference on Uncertainty in artificial intelligence. Morgan Kaufmann Publishers Inc., 2001.
-
10. Martin, Francisco J., et al. "The big promise of recommender systems." AI Magazine 32.3 (2011): 19-27.
-
11. Resnick, Paul, and Hal R. Varian. "Recommender systems." Communications of the ACM 40.3 (1997): 56-58.
-
12. Negroponte, N. "The Architectural Machine: Toward a More Human Environment." (1970): 5.
-
13. Oscar Celma and Perfecto Herrera. A new approach to evaluating novel recommendations. In Proceedings of the 2008 ACM conference on Recommender systems, RecSys ’08, pages 179–186, New York, NY, USA, 2008. ACM.
-
14. Mouzhi Ge, Carla Delgado-Battenfeld, and Dietmar Jannach. Beyond accuracy: evaluating recommender systems by coverage and serendipity. In Proceedings of the fourth ACM conference on Recommender systems, Rec-Sys ’10, pages 257–260, New York, NY, USA, 2010. ACM.
-
15. Burke, Robin, and Maryam Ramezani. "Matching recommendation technologies and domains." Recommender systems handbook. Springer US, 2011. 367-386.
-
16. http://www.aaai.org/Conferences/AAAI/aaai17.php
-
17. Burke, Robin. "Hybrid recommender systems: Survey and experiments." User modeling and user-adapted interaction 12.4 (2002): 331-370.
-
18. Negroponte, N. "The Architectural Machine: Toward a More Human Environment." (1970): 5.
-
19. Burke, Robin. "Hybrid recommender systems: Survey and experiments." User modeling and user-adapted interaction 12.4 (2002): 331-370.
-
20.Claypool, Mark, et al. "Combining content-based and collaborative filters in an online newspaper." Proceedings of ACM SIGIR workshop on recommender systems. Vol. 60. 1999.
-
21.Bennett, James, and Stan Lanning. "The netflix prize." Proceedings of KDD cup and workshop. Vol. 2007. 2007.
正文到此结束
- 本文标签: 时间 IO 定制 https key 标题 自适应 FIT 文章 自动化 智能 教育 开发 数据 http 需求 个人信息 root struct DOM cat Amazon API 汽车 db CTO id 数据库 参数 UI ECS 代码 ORM PHP ip parse 产品 同步 NSA Architect node 空间 希望 泡沫 谷歌 map 统计 电子商务 Action web mina 初学者 互联网 苹果 Bootstrap Word 创始人 十年 测试 list 搜索引擎 src Google 社交网络 spring 质量 App 学生 总结 IDE 关键词
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

