沪江任务调度系统的演化
前言
异步任务系统在计算机领域的应用十分广泛,例如音视频的转码及科学计算等,这些任务的特点是运行耗时长,消耗较多CPU和内存。随着音视频清晰度逐渐增强、需要计算的数据量逐渐增大,任务运行的时间变的越来越长,承载任务的服务器也因受到硬件的限制而变得无法承受。
为了解决这个问题,以前会使用诸如银河III等超级计算机来弥补小型服务器的性能不足(scale up),但成本过高。另一种方法就是利用fetch-join模式,把一个大任务分成许多小任务。利用多台小型服务器并行执行,再合并各个小任务的结果(scale out)。这种横向扩展技术由于成本低廉,效果明显,被广泛使用,但其缺点是对开发的技术要求较高。
沪江作为一家在线教育的龙头企业,自然少不了要提供大量教学视频的直播和回放,也免不了要处理较多视频转码、切片等耗时任务。而这些任务的基本特点是时间分布的不均匀。因为老师们的上下课往往是在同一个时间点,这就导致了某一个时刻,直播转录播的需求特别多,而过了这个时间点又降下来了。
因此,沪江的异步任务具有如下两个特点:
- 多媒体处理资源消耗巨大
- 不同时点服务器忙闲不均
为了适应这些需求与特点,我们的任务调度系统经历了封闭阶段、工业化阶段和按需分配阶段的三代演化。
封闭阶段
第一代任务系统出现在2010年。那时候任务数量还比较少,所以结构也简单。它由一个 Task Center和若干个Woker组成,架构如下图:
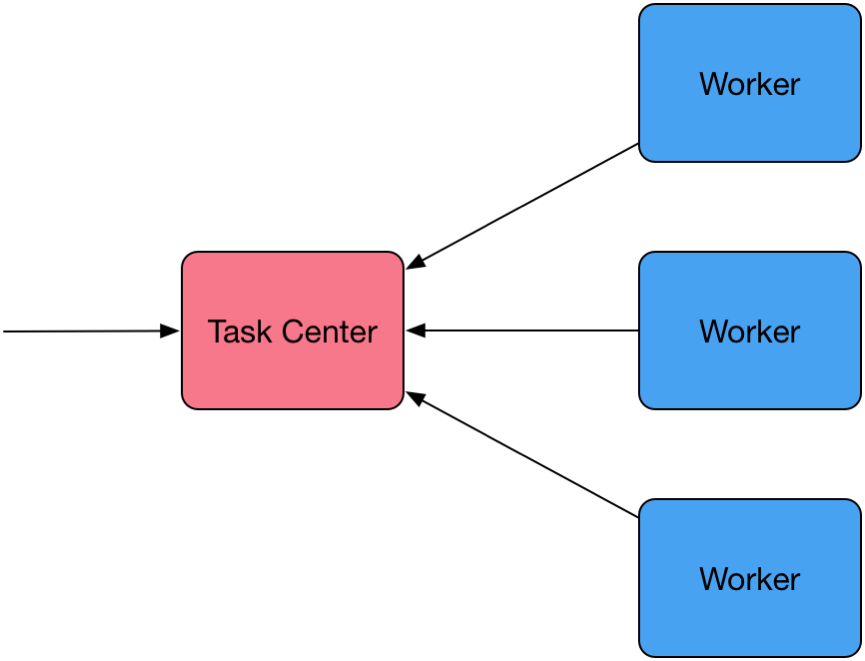
我们知道在一个异步的系统中,需要一个MQ做任务的队列。第一代任务系统的MQ由TaskCenter内存中的一个ConcurrentLinkedQueue组成,它的好处是出队入队的速度非常快。但有个致命的缺点,即由于进程间共享数据的困难性,Task Center只能部署一台,且在一台内只能部署一个instance,无法横向扩展,也没有办法做HA。这是严重违背现代架构理论的,所以又称它为“封闭”的“专政”。
工业化阶段
为了让Task Center能够横向扩展,避免单点问题,我们对第一代任务系统做了一次革命性的重构。从需求的角度去设计,很快想到了工厂的流水线模式。所有的任务相当于流水线的待加工产品,Boss负责接收未加工的任务,并把任务放入流水线MQ上。处理任务的Worker从流水线(MQ)中获取自己的任务并执行,执行完成后再放回流水线中去,下一个Worker继续处理任务。
架构图如下所示:
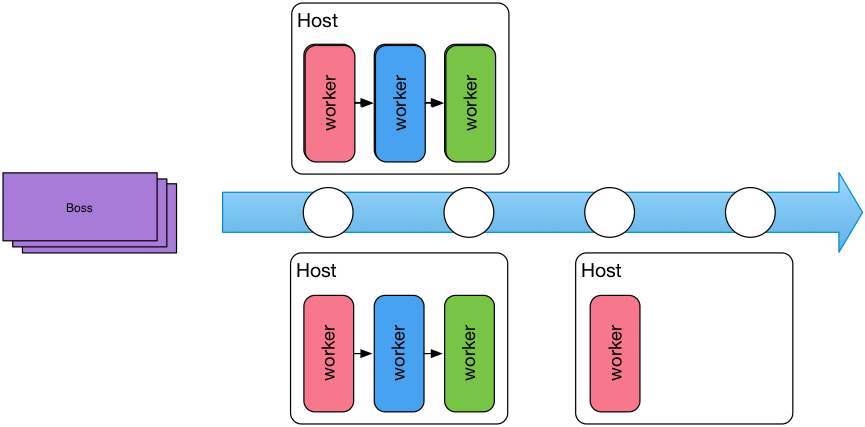
这个看似符合现实场景的模式也存在着一些缺陷:
- Worker无法快速弹性的伸缩。当任务出现瞬时性爆发性增长时,要扩展多个Worker很可能就需要增加服务器的数量。但是过一阵,任务没有这么多的时候,却又不大可能很快地去削减服务器。
- 无法根据工作的大小分配CPU和内存。每个Worker都是一个APP,它们共享一台Host主机,一般的操作系统没有办法根据任务的复杂程度来动态控制Worker的CPU和内存利用。
按需分配阶段
相比第一代的系统,第二代已经基本解决了单点的问题,并在效率上有了一定的提升。但这样的系统只能满足特有的转码打包任务,也依然没有解决资源消耗过高、维护组件过多的问题。
随着沪江业务的发展,异步任务进一步增多,功耗和效率的问题变得尤为突出了。于是我们决定转变思想,寻找是否有一种不让Worker等待任务,而是由任务触发Worker工作的按需分配(on demand)模式呢?功夫不负有心人,强大的Mesos框架映入了我们的眼帘。
Apache的Mesos是一个分布式操作系统的kernel,最擅长在计算资源之间做调度,它能够调度超过30万台物理机。但其本身却是不能被直接使用的,一定要结合上层框架才能被应用。好在Mesos为“框架(Framework)”提供了足够强大的API。
经过多次尝试以后,发现这样的结构完全能够满足沪江课件转码打包的需求,而且更加灵活和节省资源。联想到这种能力会有很多的应用场景,故专门把这套系统提炼出来,让它不用关心具体的任务,只用来接收任务请求、调度任务执行,并提供状态查询功能。
我们的主角——Juice就是具有这样能力的基于Mesos框架的开源任务调度系统(名称的由来只是因为我们的开发人员,在开发时喜欢喝果汁而命名)。它的基本思想是:在获取到任务需求后,通过Mesos框架的API通知Mesos需要运行的任务资源。比如要执行转码任务,需要8核的CPU、4G的内存和50G的存储空间,Mesos会在相应的集群内寻找合适的服务器资源执行任务,任务执行成功或失败Mesos也会通知框架并得到记录。
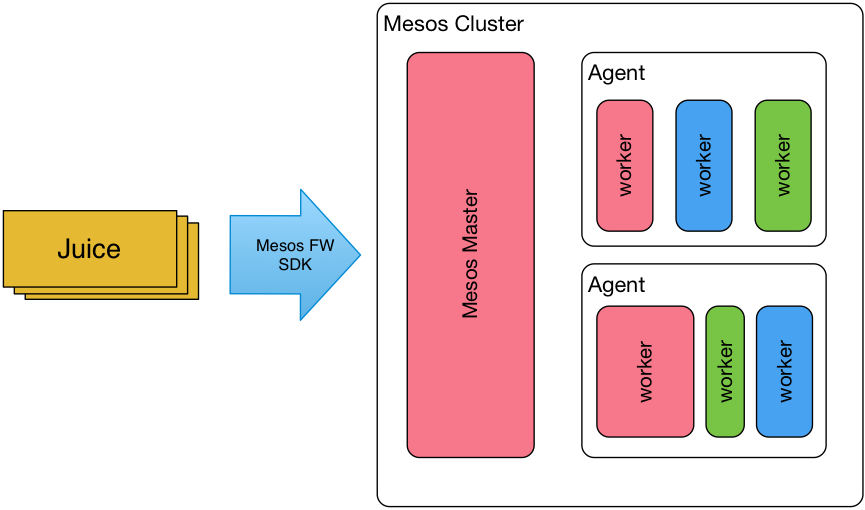
通过这种方式执行任务,有以下优点:
- 结构简单
- 任务做完之后立刻回收
- 根据任务的大小分配Worker的资源
- 任务多时可利用其它主机扩展
Juice系统总体架构如下:
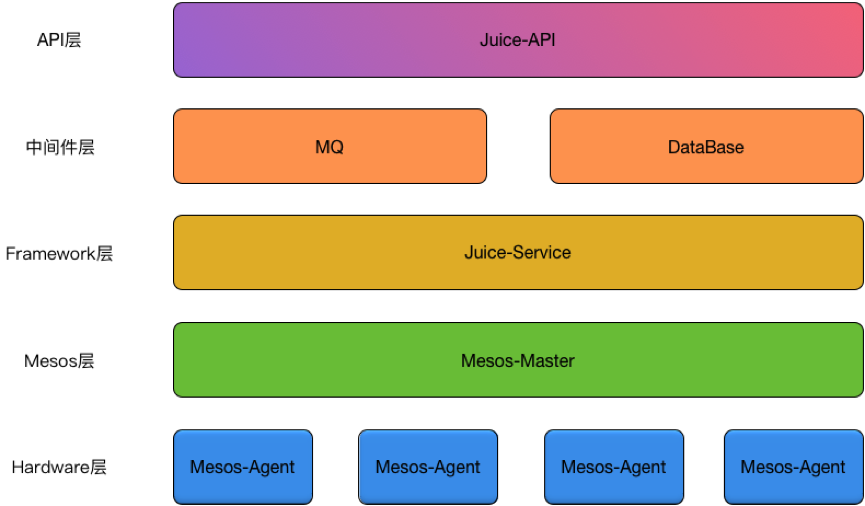
它可分为:
- API层:负责接收外部的任务请求并丢入MQ中。
- 中间件层:数据的记录与MQ的调度。
- Framework层: 通过调用Mesos-Master的API接口,实现对Mesos集群的调度。
- Mesos层:Mesos官方提供的调度框架。
- Hardware层:非常容易扩展的硬件层,每台服务器上安装Mesos-Agent,接收Mesos-Master发送的指令。
Juice的使用
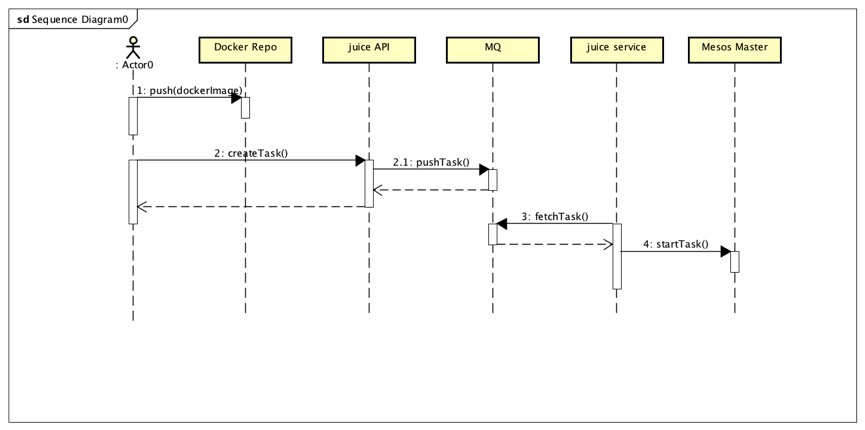
Juice目前只支持能运行在Docker内的任务。如果需要通过它调度任务,要提供一个能够运行的Docker镜像名称。通过Restful API(其API结构类似于Mesos的另一个框架Marathon),就能在规定的服务器集群中运行你的任务,是不是很酷呢?
它的系统流程如下图所示:
艰辛开发之路
开发过Mesos框架的人都知道,框架分两个角色,Scheduler和Executor。但是在1.0发布之前,要实现这两个角色需要调用Mesos Native lib,所有的外部教材也是用这种方法作为例子。我们在第一次尝试使用时,自然也选用了这种方法。开发过程轻松愉快,但当我们想使用Docker打包并发布时,不得不把Mesos Native Lib一起安装入Docker,其镜像竟然超过了1GB。不仅下载镜像和发布时间很长,而且也不符合微服务的设计理念。
镜像的庞大和依赖的繁琐促使我们不得不继续探索新的方案。正当探索进入了瓶颈时,Mesos 1.0的发布给了我们强烈的启发:正式支持Http的API。只要通过一个Http的客户端就能操控Mesos。不但能够摆脱臃肿而复杂的依赖包问题,而且让Executor的开发者不必关心如何和Mesos交互。但是Mesos的官方文档却令人抓狂,我们不得不一边猜测,一边开发。经过不懈的探索,新一代的任务系统Juice终于开发完成,程序的镜像仅仅只有180M,通过Marathon部署更快捷方便。
设计中另一个挑战是系统的HA与任务的恢复。Mesos框架的scheduler有一个问题是:同一个时刻只允许有一个Master scheduler在工作。好在我们的Juice是使用Marathon启动的,让它来临时确保高可用再好不过了。所以初期我们并不打算使用主从模式做HA。
但在某些特定的场景,比如Mesos Agent重启的瞬间,如何保证任务状态不丢失,并且能自动恢复?参考了Marathon的代码后,我们把任务的状态及分配的Agent记录进缓存中,在Juice启动后先从缓存中读取所有任务的状态并尝试恢复。
结束语
Juice可以根据任务的类型,复杂的程度,来索取更符合需求的资源执行任务,大大减少了资源浪费和资源竞争,真正做到了按需分配。与此同时,作为一个新生的开源项目,很多的功能还没有被完善,例如管理界面、支持非Docker的任务等,我们将继续完善和维护Juice系统,让它不但能为沪江,更能为外部异步任务提供统一的运行平台。
感谢
感谢徐佳、潘东及整个OCS团队对Mesos的持续探索和Juice的开发。
感谢余晟老师对本文提出修改意见。
原文链接: 沪江任务调度系统的演化 ,作者:黄凯 (沪江Java架构师)
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

