动态图计算:Tensorflow 第一次清晰地在设计理念上领先
北京时间 2017 年 2 月 8 号,Google 宣布在其博客上发布 TensorFlow Fold 支持动态图计算。动态图计算是 Tensorflow 第一次清晰地在设计理念上领先。

1. 图计算
梯度计算,或者自动求导,是深度学习框架中不可回避的问题。图计算是深度学习框架实现梯度计算的一种方式。不同于一般的编程模式,图计算先生成计算图,然后按照计算图执行计算过程。下面这段代码便属于图计算程序。
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
# compiles the function
f = compile(D)
d = f(A=np.ones(10), B=np.ones(10)*2)
当执行 C = B * A 这一行代码时,程序并没有进行真正的计算,而是生成了下面的计算图。只有执行 d = f(A=np.ones(10), B=np.ones(10)*2) 这行代码时,程序才会将数据灌进 A 和 B,运算得到 d。
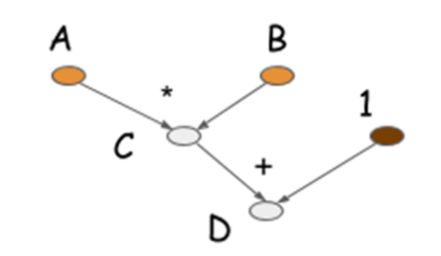
图计算怎么实现梯度计算?我们来看下面用图计算实现梯度计算的代码。
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
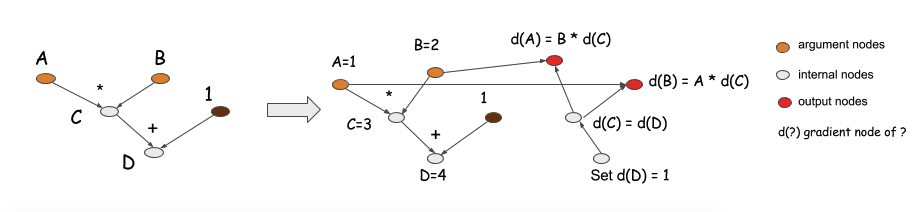
# get gradient node.
gA, gB = D.grad(wrt=[A, B])
# compiles the gradient function.
f = compile([gA, gB])
grad_a, grad_b = f(A=np.ones(10), B=np.ones(10)*2)
D 的 grad 函数产生向后计算图,返回 gA 和 gB 梯度节点(下图中的红色节点)。
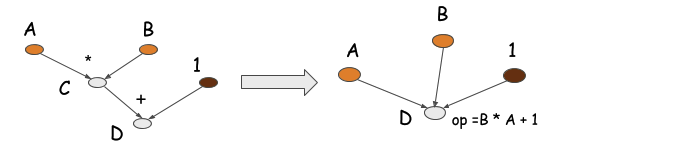
图计算在内存使用和运算时间两个方面比较高效。如下图所示,图计算能够对上述代码中的乘法和加法运算进行运算折叠。如果使用 GPU 计算,运算折叠之后的程序只需用到一个GPU内核(而不是两个)。
2. 动态图计算
上面介绍了图计算和图计算的优点,图计算也有不够灵活的缺点。因为图计算在输入数据之前就定义图结构,因此用一张图计算所有的输入数据。但是有些时候,我们必须针对不同的输入数据建立不同的计算图。例如自然语言理解中的解析树(parse trees),源代码中的抽象语法树(abstract syntax trees)以及网页中的 DOM 树等等。
如果我们还要用图计算,解决这个问题的方法就显得比较 trick 了。 LSTM 对长度不定的句子建模的场景中,先把长度相近的句子聚在一起(bucketing),然后把长度补到最长的那句 (padding),这样就能用统一的一张图计算所有的句子了。如果是树型结构,则需要先将树转化序列,然后在 bucketing 和 padding。另外一种方法则是放弃或者部分放弃图计算。Torch 和 Chainer 没有采用图计算,不需用一张图计算所有数据。Theano 用 scan 实现循环功能,算是部分放弃图计算。这样做的代价就是不能利用图计算高效的优点。
这次 Google 提出的动态图计算则解决这个问题。动态图计算对批量训练中的每一个样本生成一张计算图,然后把这些计算图进行归并生成一张大的计算图,最后用下面的贪心算法高效地这张大的计算图。这样一方面能够利用图计算高效的优点,另一方面又能处理不同输入需要不同计算图的场景。

3. 总结
Tensorflow 是开源最迟的深度学习框架,积累不如 MXNet、Theano、Caffe 和 Torch 深厚。因此给大家的感觉,Tensorflow 一直在追赶这些深度学习框架。Tensorflow 出一个新东西,我们似乎可以在其他深度学习框架中找到。动态图计算是 Tensorflow 第一次清晰地在设计理念上领先于其他深度学习框架。
当然动态图计算还刚刚问世,应该还需要时间优化。毕竟,承载动态图计算思想的 Tensorflow Fold 并不是 Google 的正式项目。最后欢迎关注我的公众号,每两周的更新就会有提醒哦~

参考文献
- Programming Models for Deep Learning
- Deep Learning With Dynamic Computation Graphs
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

