我的日志分析之道:简单的Web日志分析脚本
原创作者:北风飘然@金乌网络安全实验室,本文属FreeBuf原创奖励计划,未经许可禁止转载
前言
长话短说,事情的起因是这样的,由于工作原因需要分析网站日志,服务器是windows,iis日志,在网上找了找,github找了找,居然没找到,看来只有自己动手丰衣足食。
那么分析方法我大致可分为三种:
1. 基于时间: 将请求url按时间段分类,那么我们根据每个时间段的url数量及攻击数量就可以大致判断出哪个时间段有apt类型攻击,哪个时间段是扫描器行为;
2. 基于攻击ip: 正常的攻击肯定会有请求被记录(当然你要是有0day当我没说,正常的探测总会有吧=。=!),然后每个ip去分析;
3. 基于访问请求的状态码 ,也大致可以判断出行为。
规则可以基于开源waf规则,分析扫描器写正则也可以,开源waf地址是
https://github.com/loveshell/ngx_lua_waf/tree/master/wafconf 。
扫描器正则 https://github.com/smarttang/w3a_SOCD 的database里面有详细地址
https://github.com/smarttang/w3a_SOC/tree/master/db_sql 。
Sql语句里面有想把它做的功能全一些,但是学python学习时间也不是很长,写出来的代码也没有pythonic,会慢慢写的。目前分三个模块,一个日志归类模块命名为url.py,攻击分析模块attac.py, ip地理位置查询模块ipfind.py,还有一个主函数。
日志归类模块 url.py
import re
import os
import sys
from datetime import datetime
dt = datetime.now()
date = str(dt.date())
loglist = [] #
iplist = [] # ip统计
urllist = [] # url统计列表
needlist = [] # 需要统计的
errorlist = [] # 格式错误的列表
ipdict,urldict = {},{}
rizhi = str(input('请输入要分析的日志文件名'))
def find_log():
print('>>>>>>>开始解析日志')
with open(rizhi,'r',encoding='UTF-8',errors='ignore') as f:
#loglist = f.readlines()
for i in f.readlines(): #
if i[0] != '#':
b = re.split(' ',i)
iplist.append(b[10])
urllist.append(b[6])
try:
needlist.append([b[10],b[1],b[5],b[6],b[15]])
except:
errorlist.append(i)
print('>>>>>>>日志解析完毕')
def count(iplist,urllist): #统计ip url访问量函数
print('>>>>>>>开始分析url与ip访问量')
global ipdict,urldict
for i in set(iplist):
ipdict[i] = iplist.count(i)
for i in set(urllist):
urldict[i] = urllist.count(i)
ipdict = sorted(ipdict.items(),key=lambda d: d[1], reverse=True)
urldict = sorted(urldict.items(),key=lambda d: d[1], reverse=True)
print(type(urldict))
iplist = list(ipdict)
urllist = list(urldict)
ipdict,urldict = {},{}
print('>>>>>url与ip分析完毕.......')
return [iplist,urllist]
def save_count():
print('>>>>>>>正在保存分析结果')
ipname = 'ip-'+date+'.txt'
urlname = 'url-'+date+'.txt'
with open(ipname,'w') as f:
for i in iplist:
f.write(str(list(i))+'/n')
with open(urlname,'w') as f:
for i in urllist:
f.write(str(list(i))+'/n')
print('>>>>>>>分析结果保存完毕')
find_log()
[iplist,urllist] = count(iplist,urllist)
save_count()
iis日志和apache日志觉得都差不多,就是切割时候改一下就行了。
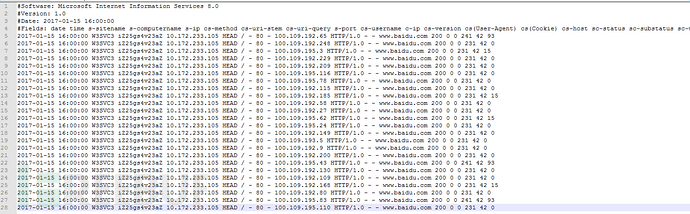
Iis日志大概是这样的,用pythonreadlines然后切割出来就好了。
这个url.py我加了个功能把ip访问量及url访问量排序输出出来所以有点慢,=.=没办法野路子哪里会什么算法。将地址,时间,ip,状态码都扔进一个列表里就行了。
攻击分析模块attack.py
import os
import sys
import url
sqllist,xsslist,senlist = [],[],[]
otherurl,xssip,sqlip,senip = [],[],[],[]
feifa = []
def find_attack(needlist):
print('>>>>>>>开始检测攻击')
sql = r'product.php|preg_/w+|execute|echo|print|print_r|var_dump|(fp)open|^eval$|file_get_contents|include|require|require_once|shell_exec|phpinfo|system|passthru|/(?:define|base64_decode/(|group/s+by.+/(|%20or%20|%20and%20|sleep|delay|nvarchar|exec|union|^select$|version|insert|information_schema|chr/(|concat|%bf|sleep/((/s*)(/d*)(/s*)/)|current|having|database'
xss = r'alert|^script$|<|>|%3E|%3c|>|/u003c|/u003e|&#x'
sen = r'/.{2,}|%2e{2,}|%252e{2,}|%uff0e{2,}0x2e{2,}|/./|/{FILE/}|%00+|json|/.shtml|/.pl|/.sh|/.do|/.action|zabbix|phpinfo|/var/|/opt/|/local/|/etc|/apache/|/.log|invest/b|/.xml|apple-touch-icon-152x152|/.zip|/.rar|/.asp/b|/.php|/.bak|/.tar/.gz|/bphpmyadmin/b|admin|/.exe|/.7z|/.zip|/battachments/b|/bupimg/b|uploadfiles|templets|template|data/b|forumdata|includes|cache|jmxinvokerservlet|vhost|bbs|host|wwwroot|/bsite/b|root|hytop|flashfxp|bak|old|mdb|sql|backup|^java$|class'
for i in needlist:
if i[2] == 'POST' or i[2] == 'HEAD' or i[2] == 'GET':
response = re.findall(sql,i[3],re.I)
if response == []:
responsexss = re.findall(xss,i[3],re.I)
if responsexss == []:
responsesen = re.findall(sen,i[3],re.I)
if responsesen == []:
otherurl.append(i)
else:
senlist.append(i)
senip.append(i[0])
print(responsesen)
print('检测出敏感目录扫描')
print(i)
else:
xsslist.append(i)
xssip.append(i[0])
print(responsexss)
print('检测出xss攻击')
print(i)
else:
sqllist.append(i)
sqlip.append(i[0])
print(responsexss)
print('检测出sql攻击')
print(i)
else:
feifa.append(i[0])
print('非法请求:'+str(len(feifa))+'次'+str(len(list(set(feifa))))+'个ip')
print('>>>>>>>攻击检测完毕')
return [xssip,sqlip,senip,sqllist,xsslist,senlist,otherurl]
这个就简单多了,基于正则分析的正则不是很完善,还有好多是根据自己公司情况来定,大牛轻喷,检索完毕返回ip及url。
IP 地理位置查询模块 ipfind.py
Ipfind.py是查找ip地理位置的
import re
import urllib.request
def url_open(ip):
url = 'http://www.ip138.com/ips138.asp?ip='+ip
response = urllib.request.urlopen(url)
html = response.read().decode('gb2312')
return html
def find_ip(html):
a = r'本站数据.{20,}</li>'
p = re.compile(a,re.I)
response = re.findall(p,html)
for i in response:
b = i
response = re.split(r'</li><li>',b)
ipaddrs = str(response[0][5:])+','+str(response[1][6:])+','+str(response[2][6:-5])
return ipaddrs
def find_ipaddrs(ip):
html = url_open(ip)
ipaddrs = find_ip(html)
print(ip+' : '+ipaddrs)
这个简单我是直接像爬虫那样写的,用ip138的网址(接口没有找到,百度注册了好几次都不成功,有api的可以用api)。
主函数
主函数main.py
import re
import os
import sys
from datetime import datetime
import url
import attack
import ipfind
needlist = url.needlist
sqllist,xsslist,senlist = [],[],[]
otherurl,iplist = [],[]
[xssip,sqlip,senip,sqllist,xsslist,senlist,otherurl]=attack.find_attack(needlist)
xssip = list(set(xssip))
sqlip = list(set(sqlip))
senip = list(set(senip))
print('>>>>>>>检测出xss攻击'+str(len(xsslist))+'次'+'共计'+str(len(xssip))+'个ip')
print(xssip)
print('>>>>>>>检测出sql攻击'+str(len(sqllist))+'次'+'共计'+str(len(sqlip))+'个ip')
print(sqlip)
print('>>>>>>>检测出敏感目录扫描'+str(len(senlist))+'次'+'共计'+str(len(senip))+'个ip')
print(senip)
iplist = list(set(xssip+sqlip+senip))
print(len(iplist))
print('开始分析ip地理位置')
for i in iplist:
ipfind.find_ipaddrs(str(i))
要分析什么就把需要分析的和main.py放在一个目录下就行了
总结
脚本大概说了一遍,说说不足及怎么分析吧。
现实不足:看了差不多有3个月日志了吧,先说一个最严重的问题,post请求data看不见,本身日志就看不到data,何况等到https普及了日志什么样也不知道,要是有能力最好做成和waf联动那样的。还有就是未知威胁从waf来看基于正则,基于关键词有很多都是能绕过的,但是有攻击行为没删日志的话,肯定是会留下攻击痕迹的,这样可以从检测出来的ip来看具体攻击的url,而未知威胁则不同了,就好比一个0day,攻击waf没用了,日志分析看不出来了,那么只能依靠应急响应以及服务器的报警了。
还有好多攻击类型没有加入到里面,后期打算把判断攻击类型写成函数,拿if,else判断,类型少还可以,类型多了感觉很容易乱,还有user-agent的收集与判断(虽然大多数扫描器都能改user-agent)。
具体分析:我都是用脚本跑一遍,然后按ip来看会比较方便些,而这里缺少机器识别,我单独写了一个简易的机器识别的东西,其实要实现很简单,把全部日志按时间,url,ip扔进一个列表里统计一下相同时间相同ip的就可以了。我写的是识别短信轰炸的,后期还会渐渐的完善,如果有能力就把它结合django来弄成图形化,毕竟脚本始终是脚本,终究听着不好听。
效果如下
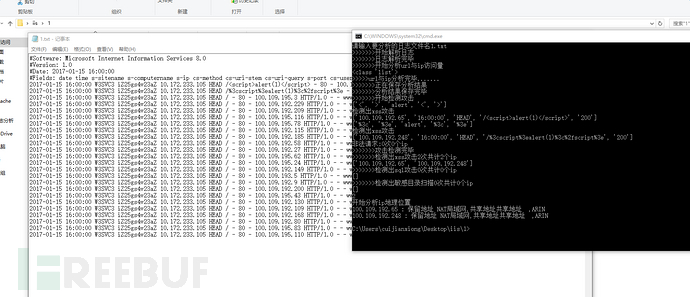
正文到此结束
- 本文标签: find GitHub Select schema Action PHP servlet tar API 解析 开源 python web db 数据 HTML 百度 ACE apache windows js UI App 总结 关键词 Master zip tab https sql CTO list http IO java ssl git 安全 Apple key 统计 NIO 目录 服务器 网站 时间 XML src cache root ip cat 代码 json lib ORM phpmyadmin shell
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

