守护城市安全:时空数据 深度学习

上周,在旧金山召开的 人工智能国际顶级会议AAAI 2017上 ,来自微软亚洲研究院的郑宇博士及其团队的论文Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction首创性的将时空数据与深度学习结合起来,利用时空深度残差网络用于预测城市人流问题。
提及这项研究,郑宇博士介绍到:“这个系统背后的模型研究,其目标是预测整个城市里每个区域在未来时刻有多少人进、有多少人出,从而使得管理者能迅速了解每个区域的公共安全状况,及时采取预警措施。”他补充,“例如在上海市两年前跨年夜的踩踏事件之前,如果有这样的系统,就可以提前给民众发信息,告知他们这里未来会有多少人进来,提醒民众注意,并建议是否需要提前离开。我们这项研究的想法也正是起源于这次事件。”

可扩展的整体预测模型
今天,在贵阳的“块数据”实验室里的一块大屏幕上,贵阳市被分为若干个1KM*1KM的小格子,它实时地输入新数据,以热度图(heat map)的形式不间断的预测每个区域会有多少辆出租车的进和出。这是一个以贵阳出租车实时上传的数据作为样本,基于云计算和大数据的系统。
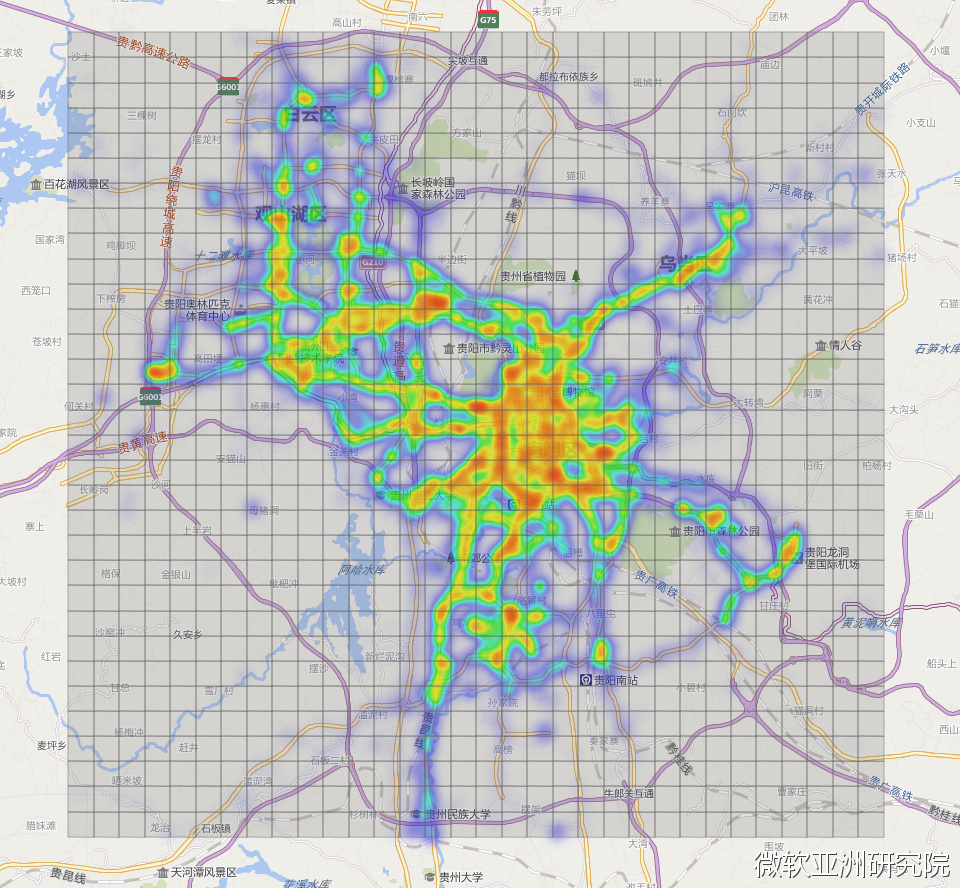
该系统具有极强的扩展性,任何可以用于人流数据预测的来源,无论是正在采用的出租车数据,还是手机信号、地铁刷卡记录等,都可以通过论文Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction中提出的这套系统模型进行运算,得到相应的某地将有多少人进和出的结果,并预测未来十几个小时的城市人流情况。
传统的人流预测方法一般是预测个人行为。理想状态下,只要统计某个区域里的每个人从哪来去哪里就能测算出该区域有多少人进、多少人出。但这样的统计本身有很大的障碍,准确性很难保证,并且涉及隐私问题。除此之外,传统方法还有一些基于物理学模型、交通动力学模型或是土木工程的经典模型等,但这些始终难以应对大规模的人流预测。
郑宇博士及其团队提出的这套方法是一种整体预测,不涉及个人隐私。该系统将整个城市划分成若干个相同大小的格子,进行同时预测。整体性预测的必要性在于区域和区域之间具有相关性,不能单独预测,在预测 A 区域的时候,其实A区域的变化对B区域和C区域同样可能产生影响,反之亦然。因此,把深度学习的思想引入进来进行整体预测,与传统方法相比具有诸多优势。
基于对时空数据的深度理解
这项工作其实面临着诸多难点,其中一个重要原因是:影响人流量的因素非常之多。可能包括:与区域里面前一个小时有多少人进和出有关系;与周边区域有多少人进和出也有关系;甚至很远的地方有多少人进和出等等……但是这些区域之间的关系又是相互影响的。
另一个难点是,人流的变化还受很多外部因素的影响,例如天气和事件等等。
第三点,人流量的预测是一种 时空数据 ,它包括时间属性和空间属性。不同于图像数据和文本数据等,这种特别的属性就意味着传统的深度学习方法不能直接应用。
为什么传统的深度学习方法不能直接拿来用?这包括以下四点原因。
第一, 空间属性 。空间有距离,空间有层次。根据地理学第一定律,地理事物或属性在空间分布上互为相关,一个空间单元内的信息与其周围单元信息有相似性。即在地图上,两个点的距离越远,可以认为该两点的如空气质量、温度等属性可能差异越大。
第二, 城市的天然层次性 。一个城市它有很多区,每个区又由很多街道社区组成,它有天然的层次。不像图像数据中的像素,像素和像素之间并不存在层次感。城市的区域、街道等这些地理信息里都蕴藏着明确的多层次的语义信息。
以上两点是空间上的不同。
第三, 时间变化的周期性 。在相邻两个时间点之间,城市的交通容量和人流可能是一个平滑变化的趋势。例如7点和8点的人流可能是平滑变化的,这很容易理解。但周期性则是一种属性,城市的交通流量也好、人流也好,它是有一个往复的周期性。比如说今天早上8点的车流量和昨天早上8点的车流量可能很像,但是今天早上8点和今天中午12点的车流量却大相径庭,尽管今天中午12点钟离今天早上8点钟只有4个小时,而昨天早上8点钟离今天早上8点钟有24个小时,但反而是昨天同一时间的数据却更为相似。不同于传统的视频数据和图像数据,周期性是时空数据的特有属性。
第四, 时间变化的趋势性 。其实,周期性也不是固定的,它有一种趋势性的上扬和下降,这就叫趋势性。什么叫趋势?比如冬天天气越来越冷了,天亮的时间越来越晚,大家出门的时间就会越来越晚,因此早高峰来的时间就会越来越晚,这种趋势性慢慢渐变的过程,并不是一个固定的数值,不是说永远早高峰都是8点钟来。
当空间属性和时间属性结合在一起,人流数据作为时空数据的一种,就区别于以往的视频、图像和文本等数据,已有的深度学习方法是无法直接奏效的,这也是研究这类数据的难点所在。
时空残差网络
说完了研究难点,那么郑宇博士及其团队是如何解决这个意义非凡的研究难题的呢?
如上文贵阳市“块数据”实验室的大屏幕所显示的,郑宇博士及团队创造性地把城市划分成若干个均匀且不相交的网格。例如采用1KM*1KM的格子把城市划分成网格,接下来把收到的人流数据,例如手机数据或者是出租车轨迹等代表人流量的数据, 投射在网格 里面。第三步,以网格为单位计算每个格子里分别有多少人流量的进和出。第四步,根据这些数据生成简单的 热度图 。例如某个方格颜色越亮,则说明这个地方人越多。
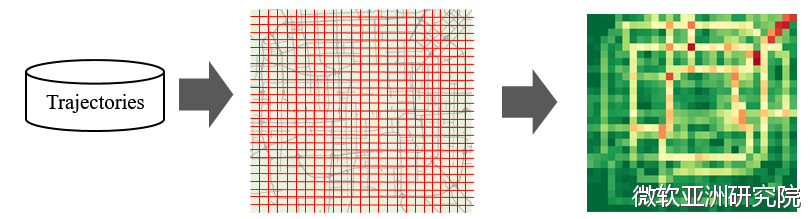
因此,某一个时间点的数据就能生成一张二维的平面图。多个时间点的数据生成对应的图像,就变成了一个时序。此外,研究员同时挖掘出了数据对应的事件和天气信息。这些就构成了数据的输出。
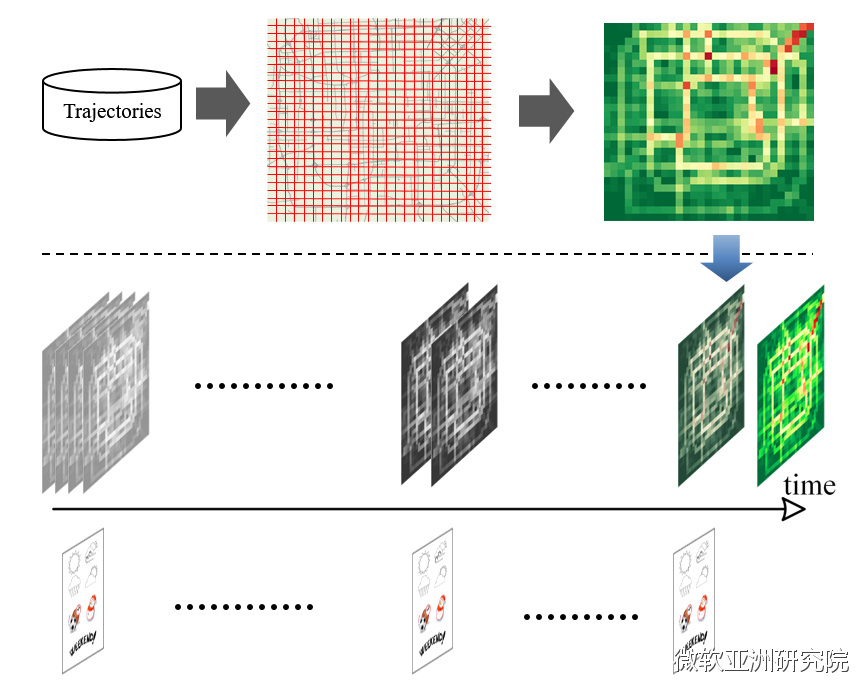
有了这些数据,是否可以直接用上深度学习了呢?答案是否定的。根据论文的描述,我们还要经过以下几个步骤。
第一,把最近几个小时的数据,即把最近这几帧的数据,输入到一个深度残差网络里面,即 时空残差网络 ,来模拟相邻时刻这些时间点的人流变化的 平滑过程 。
第二,把对应时间点不同日期的对应时刻,例如周一的两点钟和周二的两点钟,以及周五的两点钟,这些同一时刻的数据作为输入,来模拟 周期性 。
第三,模拟 趋势性 ,即从更长的时间维度进行模拟。例如将每个月的第一周,第二周和第三周周一的下午三点钟的对应数据作为输入,从而模拟趋势性。
以上三点均通过同样的深度残差网络分别模拟三个属性:平滑、周期、趋势。通过这些关键帧的抽取,只要用几十帧的关键帧作为输入,就可以体现出城市几个月时间里所包含的周期性和趋势性,这极大地简化了网络结构,但同时保证了训练的质量和效果。
接下来,将这三个结果进行融合,在这一阶段仅考虑时间属性和空间属性。因为外部因素,例如事件和天气等更多的是全局的、更广域的影响。因此下一步,再把外部的天气、事件等因素做二次融合。
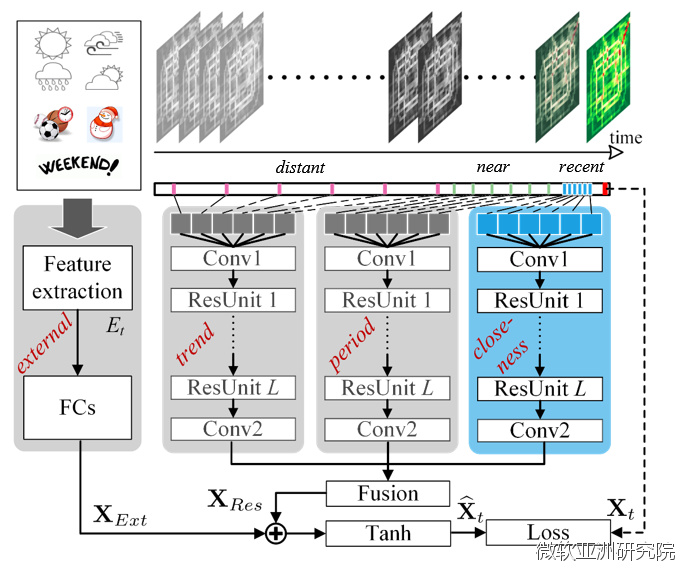
那么,空间的特性在这里是如何模拟的呢?
我们都知道,深度卷积神经网络的过程是这样的——在将城市区域划分成若干个格子之后,把相关的区域进行卷积运算合并到一个值,你可以认为通过一次卷积之后,相关周围地区的 人流的相关性 就能有所了解。卷积多次之后,相当于把更远的地方属性都卷积到一起了。如果你想研究距离很远的两个地方的相关性,那就对网络层次的深度提出了要求。在上海外滩的踩踏事件中,外滩观景平台的人流对冲被认为是事件的主要原因,但造成大规模人流对冲的原因仍不清楚。而该模型既可用于解释人流对冲的原因和趋势,另一方面还能对人流疏散问题提供解决方案。
但另一方面,一旦网络的层次比较深,就会让训练变得非常复杂、非常困难,精度也无法保证。为了保证训练效果好、提高训练精度,研究员们引入了残差网络结构来解决这个问题。这样既保证了人流量的空间相关性,又使得训练精度变得更好。
在论文Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction中,郑宇博士及研究团队用四年内的北京市出租车GPS轨迹数据和纽约自行车租赁的公开数据进行了验证。这套模型的通用性也保证了其他类似数据同样可以用于人流量的预测问题。
郑宇博士介绍道:“这篇论文可以认为是(在国际知名学术会议上)真正把深度学习有效用在时空数据上的第一个研究成果,具有重要意义。”而深度学习在时空数据方面的应用,目前也是微软亚洲研究院城市计算组的重点研究方向。
为城市喝彩
关于城市计算的研究已经走过了近十年的时光。从2008年初开始,通过分析和融合城市中的各种大数据,郑宇博士和团队实现了一系列关于智能交通、城市规划、环境和能源等的实际案例。相关技术不仅被应用于微软的产品,并且还在多个城市为政府决策提供服务。

城市计算作为一个交叉学科,包括城市感知及数据捕获、数据管理、城市数据分析、服务提供四个环节。与自然语言分析和图像处理等“单数据单任务”系统相比,城市计算是一个“多数据多任务”的系统。城市计算中的任务涵盖改进城市规划、缓解交通拥堵、保护自然环境、减少能源消耗等等。而在一个任务中又需要同时用到多种数据。比如,在城市规划的设计过程中,我们需要同时参考道路结构、兴趣点分布、交通流等多种数据源。
在城市计算的中文页面介绍上,郑宇博士写道:“更具体的说,城市计算是一个通过不断获取、整合和分析城市中多种异构大数据来解决城市所面临的挑战(如环境恶化、交通拥堵、能耗增加、规划落后等)的过程。城市计算将无处不在的感知技术、高效的数据管理和分析算法,以及新颖的可视化技术相结合,致力于提高人们的生活品质、保护环境和促进城市运转效率。 城市计算帮助我们理解各种城市现象的本质,甚至预测城市的未来 。”
注:城市计算的中文页面网址:https://www.microsoft.com/en-us/research/project/城市计算/ (请直接复制网址至浏览器中打开)
如何成为一个帮助城市建设,为城市喝彩的数据科学家?郑宇博士给出了以下几点分享。
首先,数据科学家是区别于数据分析师的概念,后者通常都是针对明确的任务和明确的数据进行处理。而数据科学家往往需要自己找出问题,找出对应的数据。例如,如何解决城市的雾霾问题等。
其次,数据科学家需要 会分析问题 ,知道这个问题和什么因素相关,也知道用什么样的数据体现这样的问题。不仅如此,他还需要知道过去解决方案的优缺点,并博采众长,提出自己的解决思路。
再来,数据科学家要 看懂数据 ,理解数据背后的洞察。例如路面上的GPS轨迹,它不光反映了路面的交通容量和速度信息,它也反映了人们的出行规律。我们知道每个人的上车地点和下车地点,如果我们有很多人的出行规律,就可以进一步反映这个区域的经济、功能甚至环境。进而可以用领域A的数据去解决领域B的问题,做到跨数据多元融合。
还有就是要 了解各种模型 ,包括数据管理、数据挖掘、机器学习、可视化等等,以及云计算平台问题。
郑宇博士总结道,一个好的数据科学家应该是 站在云平台上面看问题,想数据、关联模型,并把这些模型有机地组合起来,部署到我们的云平台上面,让它产生鲜活的知识,最终解决行业问题 。
这,也是郑宇博士和城市计算团队一直追求的方向,也是他们为城市喝彩的一种含蓄的表达方式吧。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

