乐视云基于Kubernetes 的PAAS 平台建设
背景
2014年乐视云开始尝试Docker的推广和使用,我们的团队开始开发第一代容器云平台Harbor (分享网址: http://dockone.io/article/1091 )。(在这里提醒一下,这与VMware公司中国团队为企业用户设计的Docker Registry erver开源项目Harbor 重名)。
第一代容器云平台可以认为是一个开放的托管平台。开发者可以将自己从公司申请的虚拟机或者物理机添加到Harbor系统中进行托管管理,平台基本包含:镜像自动构建(CI),应用快速扩容、缩容、灰度升级,资源权限管理,多集群主机管理等功能。
由于那时容器才刚刚兴起,刚开始在公司内部推动也有一定的阻力,刚开始给业务线推广的时候,需要首先介绍Docker,介绍容器和虚拟机的区别,然后再介绍平台本身和使用方法,推广成本以及业务线学习成本也比较高。接入Harbor上的业务的大多是业务线自己提供虚拟机,而物理机占少数。不过鉴于Harbor的易用程度,吸引了很多新业务接入。到现在为止Harbor已经完全实现开发自助化。业务自己添加主机,自主管理应用和容器,对应用进行升级、回滚,弹性伸缩,镜像构建,现在已经稳定运行2年多。
第一代容器云平台不足之处在于:
- 网络方面也是用的最基本的Nat,端口映射模式,存在性能问题。业务必须要知道容器对外映射出来的端口,对业务不透明,不便于报警和运维,也不便于对接负载均衡。
- 容器的分发调度全部自己开发,任务量大,当时没有能够做到容器自动迁移。
- 不支持应用的全球部署。
- Harbor管理的计算资源需要业务线自己申请,计算资源可以是物理机也可以是虚拟机,导致业务线需要关心底层的计算资源,计算资源无法对业务线完全透明。
- 为了降低用户对Dockerfile的学习成本,我们对Dockerfile进行了封装,只让用户写Shell脚本,因封装的不合理,导致制作出的镜像太大,尤其Maven项目,需要编译,每次在Docker Build时候,都会重新下载依赖包,导致编译过程长,镜像大,并且容器内服务启动方式不灵活。
- 监控报警机制不完善,没有做到容器和应用级别的监控和报警。
-
镜像仓库Registry并没有做得到像Docker Hub那样用户权限划分。
随着Kubernetes在越来越多公司开始使用,乐视内部更多的团队和业务线开始接受或者主动了解Docker,同时为了解决第一代平台的存在问题和基于乐视现有服务部署情况,到2015年底,我们团队计划替换掉之前自己写的调度方案,着手尝试使用Kubernetes作为容器的调度引擎,在对比多套网络方案(calico,flannel等等)后,结合乐视现有状况,采用Bridge模式,容器大二层网络方案。负载均衡使用Nginx,计算资源全部使用物理机,计算资源完全对业务透明。经过半年多的调研和开发,在2016年10月第二代PAAS平台LeEngine在美国上线,半个月后,北京地区上线。LeEngine现在保持着一月一版本的开发迭代速度,到现在为止已经开发了3个版本。
LeEngine 采用全新的架构,主要面向于无状态或者RPC应用。现在已经承接了乐视云计算,乐视体育章鱼TV,风云直播,乐视网乐看搜索,云相册等近100多个重要业务,使用的客户普遍反映一旦掌握了LeEngine的使用流程,从开发到上线部署,弹性伸缩,升级的效率可成倍增长,极大简化了运维成本。LeEngine拥有极强的用户粘性,吸引了很多业务线主动申请试用LeEngine,现阶段已经不需要再增加额外的精力在公司内部推广。
简介
Kubernetes:Google开源的的容器编排工具,在整个2016年,越来越多的公司开始在线上使用Kubernetes,同时Kubernetes具备我们迫切需要的容器自动迁移和高可用功能。关于Kubernetes 的架构在这里我就不多介绍了,虽然架构偏重,但是我们最终决定使用它,并且尽量只使用它的Pod,Replicationtroller和Service功能。
这里首先解释一下几个概念:
用户: 乐视各个产品线下的产品,开发,测试,运维等人员。
Region:偏向于地理概念,例如北京和洛杉矶是两个Region。 同一个Region内要求内网可达,网络可靠,低延迟。同一个Region共用一套镜像Registry,镜像构建系统,负载均衡系统和监控报警系统,不同Region 共享全局唯一的sdns和gitlab代码仓库。
Cell: 我们现在使用的Kubernetes 1.2.0版本,理论上能控制1000个计算节点,为谨慎使用,规定一个kubernetes集群最大计算节点会控制在600个左右。 Cell 概念的引入是为了扩充单个Region下计算节点的规模,偏向于机房的概念,一个cell 即一个kubernetes集群,每个Region下可以搭建多个cell。所有cell共享本Region下的镜像Registry,镜像构建系统,负载均衡系统和监控系统。为同一个Cell下的容器配置一个或者多个网段,每个网段划分单独的vlan。同一cell下的计算节点不会跨机房部署。
LeEngine Registry: 基于Docker Registry 2.0 做的部分修改,后端支持乐视云的Ceph存储。并仿照Docker Hub 增加权限和认证机制,只有拥有相应权限的用户才能对特定的镜像进行Push 和Pull操作。也可以设置镜像公开,公开的镜像任何用户都可以Pull。
计算节点: 物理机,Kubernetes 的Node概念。
应用: 定义提供相同业务逻辑的一组容器为一个应用,可以认为应用是一个微服务。这类应用要求是无状态web服务或者rpc类的服务。应用可以部署在多个Cell中。上文提到过,一个Cell可以认为是一个机房。LeEngine在一个Region下会至少部署2个Cell,部署应用时候,我们要求应用至少部署在2个Cell中,这样即使一个机房出现网络故障时,另一个机房的应用容器还能继续对外提供服务。一个应用下可以部署多个版本的容器,因此可以支持应用的灰度升级。访问web类应用时候,我们强制要求这类应用(如果是线上应用)前面必须使用负载均衡,由我们的服务发现系统告诉负载均衡当前应用下有哪些容器IP。从Kubernetes层面讲,我们规定一个应用对应Kubernetes下的一个Namespace,因此在应用的数据库表中会存在一个Namespace的字段,并需要全局唯一,而应用的多个版本对应了在这个Namespace下创建的多个Replicationtroller。
Region,Cell 和kubernetes的关系:
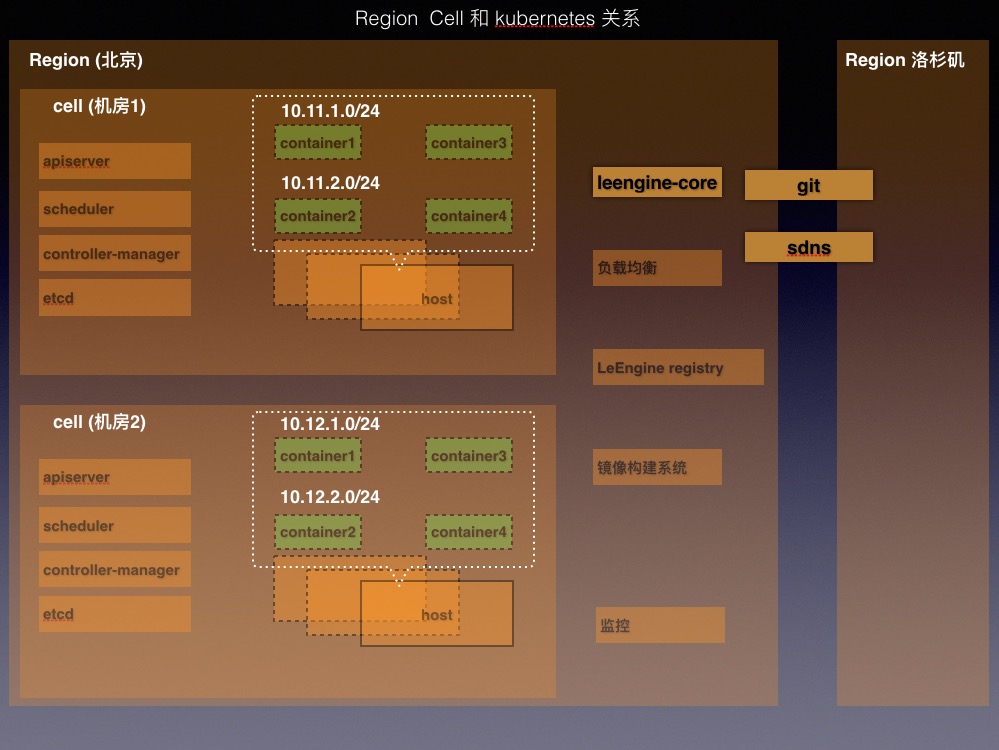
架构平台设计
容器直接运行在物理机上,计算节点全部由我们提供,业务线不需要关心,LeEngine可以作为一个企业解决方案对外全套输出,平台架构如下:
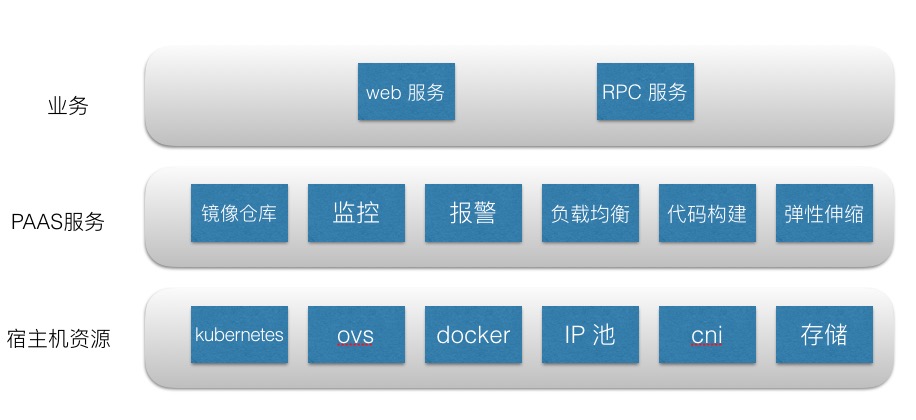
业务层: 乐视使用容器的各个业务线,是LeEngine的最终用户。
PAAS 层: LeEngine提供的各种服务,主要是完成对应用的弹性伸缩,灰度升级,自动接入负载均衡,监控,报警,快速部署,代码构建等服务。
宿主机资源层:主要指Docker 物理机集群,并包含IP池的管理。
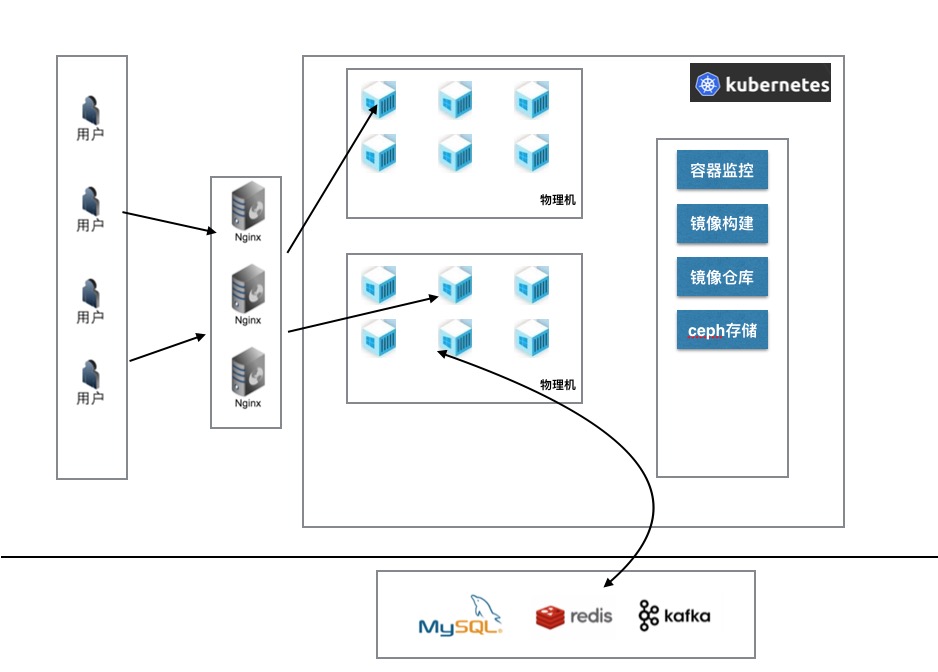
用户访问部署在LeEngine上的应用时,首先通过sdns智能解析到对应的nginx负载均衡集群,然后由nginx 将请求打到对应的容器中。数据库,缓存等有状态的服务并没有在LeEngine体系之内,因为采用大二层网络,容器可以直接连接公司其他团队提供的数据库或者缓存等服务。
下图是为了更好的说明支持多地域,多kubernetes集群的部署。
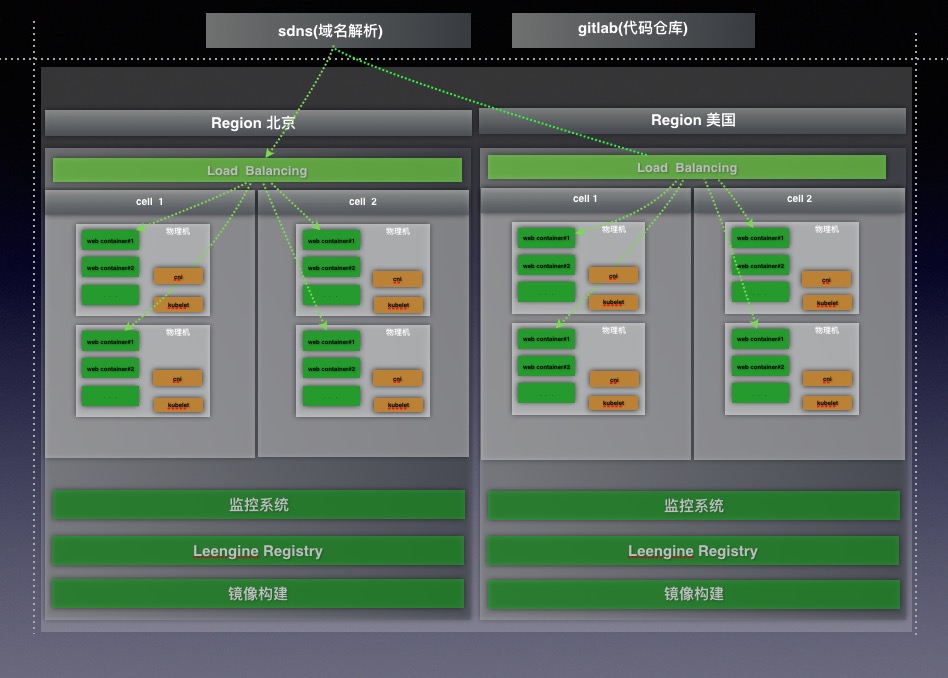
单一Region 下单cell部署图:
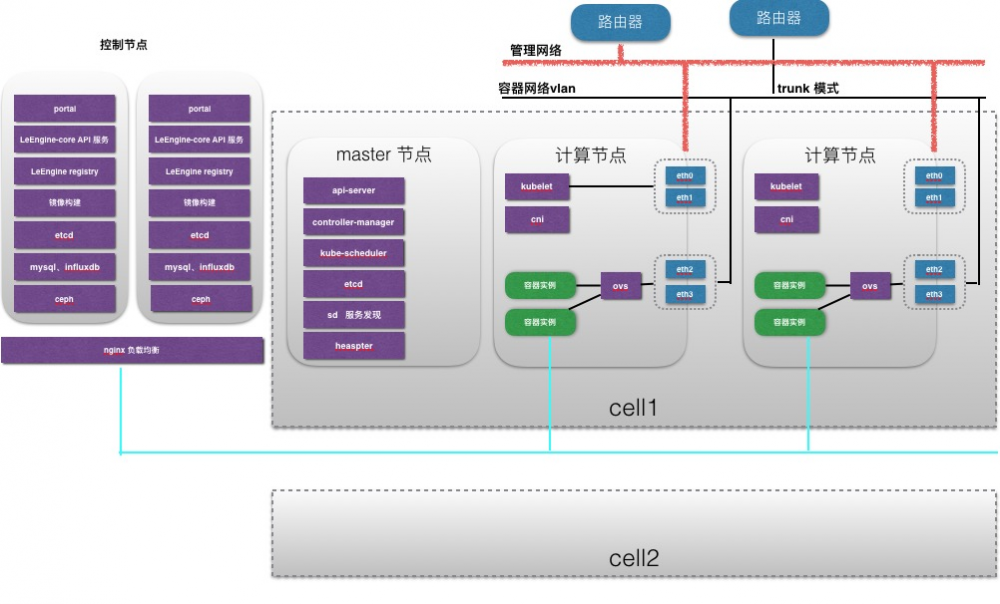
我们将计算节点的管理网络和容器网络划分开并给容器网络划分单独的vlan。
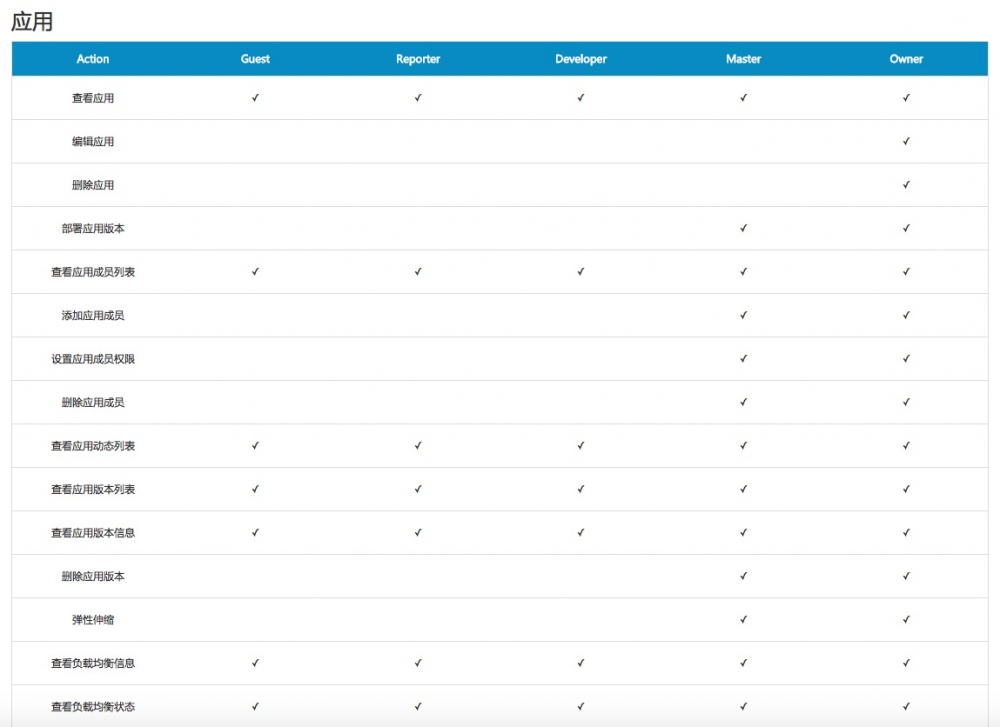
成员,权限管理
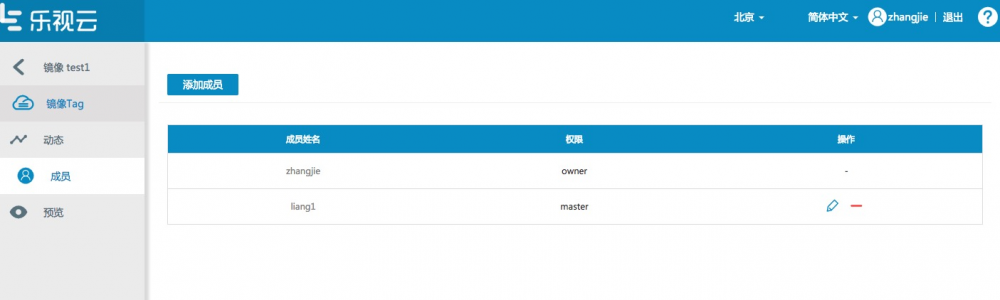
LeEngine下面定义了四大资源,应用,镜像,镜像分组和代码构建。为了团队协同操作,这4大资源都增加了成员和权限管理。成员和权限仿照了gitlab进行了设计,成员角色分为:Owner,Master, Developer, Reporter, Guest。 不同的角色针对不同的资源系统都定义了不同的权限。比如应用,只有Owner和Master有权限对应用部署新版本,弹性伸缩等等。 假如一个用户A创建了一个应用A1,那么A就默认是应用A1的Owner,拥有对应用A1所有操作权限,包括部署新版本,弹性伸缩,修改应用,删除应用等所有操作。而用户B此时对应用A1不可见,若想可见,必须由A对这个应用A1执行添加成员的操作,把B添加到A1中,并赋为除Owner以外的任何一个角色,若此时B被赋为Master角色,那B拥有了对应用A1部署新版本,弹性伸缩等权限,反之则没有。
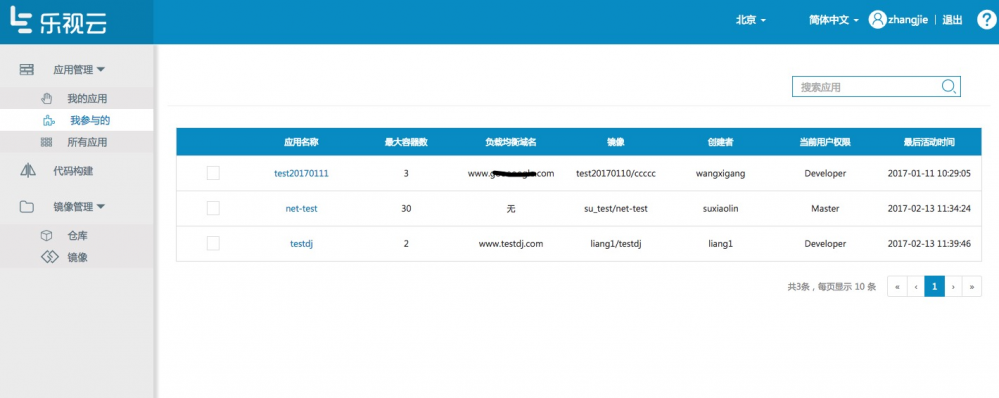
根据上面的权限设计,通过LeEngine的Console界面,不同的用户登录后看到的仅仅是跟自己相关的资源,如下图,在应用中,能看到我创建的以及我参与的应用:
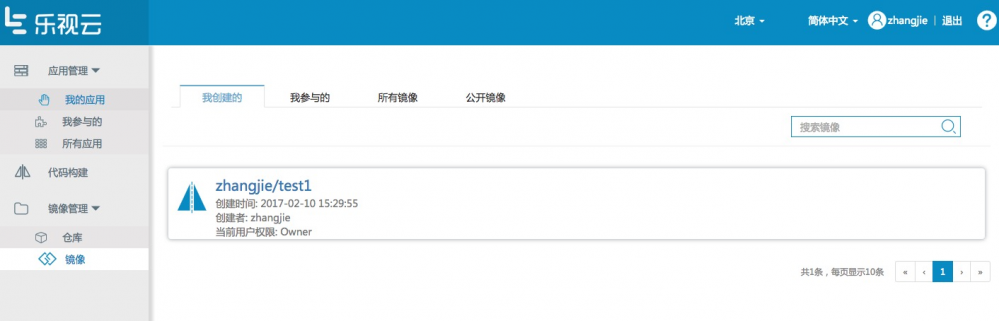
在镜像页面,能够看到我创建的以及我参与的镜像,如下图:
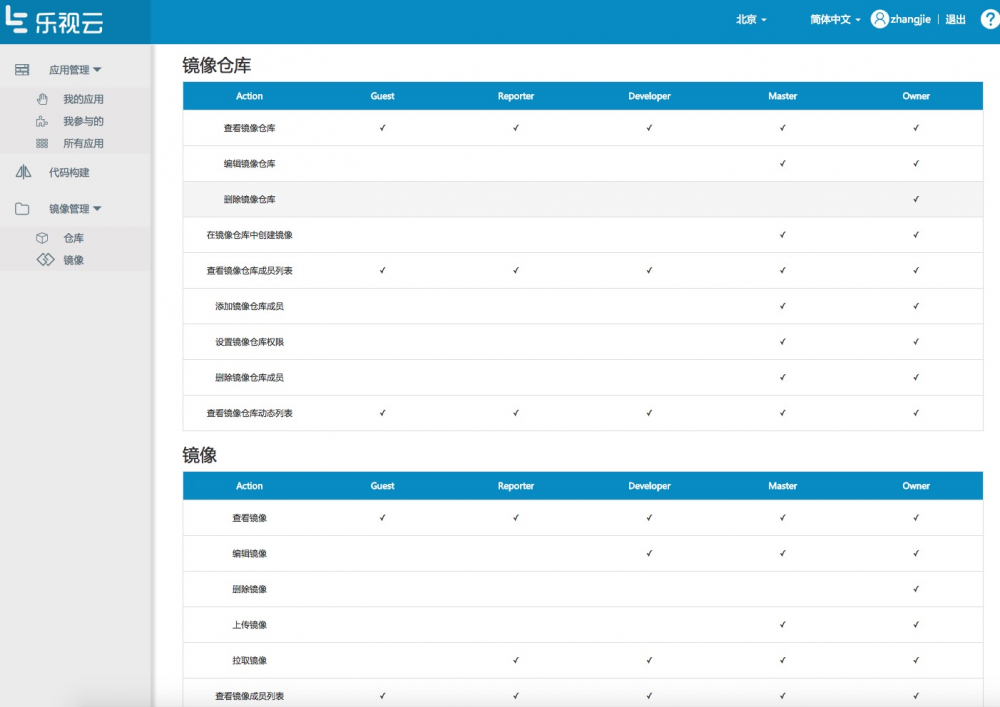
帮助文档会提供给用户不同资源的权限说明:
用户端和管理端
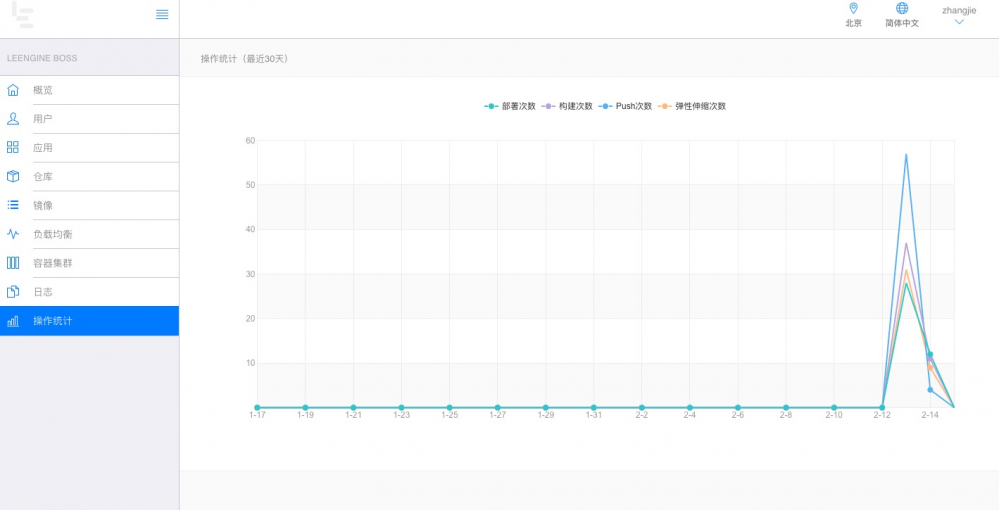
LeEngine具有面向用户端的console界面和面向运维管理员的boss界面,在用户端用户可以看到自己创建和参与的4种不同的资源。管理端则主要是对整个LeEngine平台资源进行管理,包括用户可使用最大资源的限制,负载均衡特殊配置,Cell集群下的资源使用情况,操作频率统计等等。
下图是LeEngine 测试环境 boss系统关于操作频率统计:
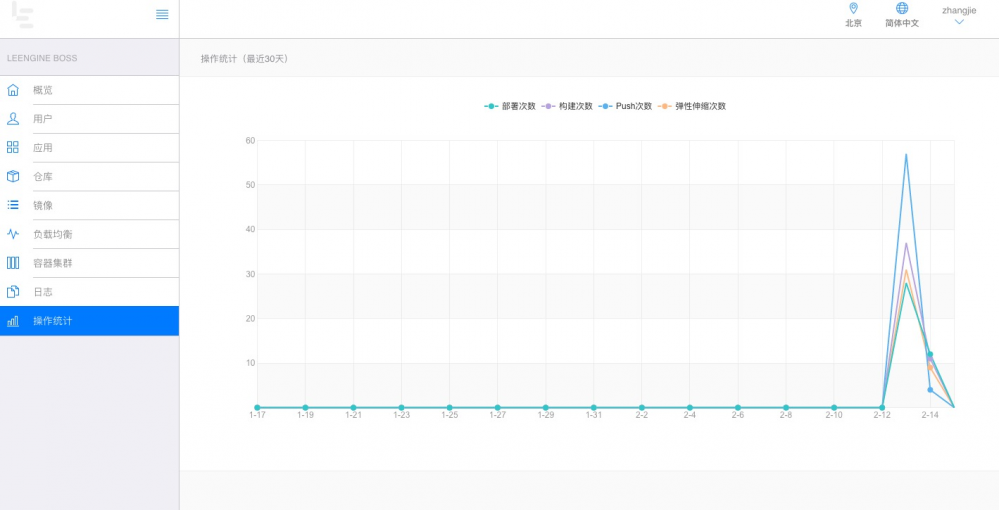
操作频率包括每天所用应用的部署次数,代码的构建次数,镜像的push次数,弹性伸缩次数,在一定程度上能展示出业务线对LeEngine平台本身的使用频率。
LeEngine-core
Leengine-core 是LeEngine最终对外提供服务的API接口层(beego实现),所有4大资源的操作,包括权限控制,都是通过这一层控制的。LeEngine只提供最原子的API接口,特殊业务线要想有特殊的需求,完全可以在现有API基础上进行二次开发。
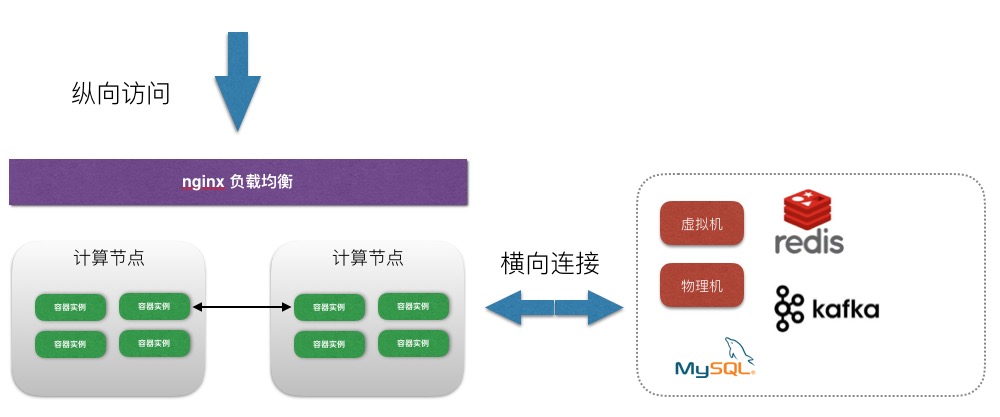
容器网络
容器采用大二层网络,因此可以保证外部服务可以直接连通容器,容器也可以直接连通外部服务,比如数据库,缓存等等。采用此种方案可以保证容器横向可连接,纵向可访问。外部想连接容器可以通过容器IP地址直接连接,也可以通过负载均衡方式进行访问。而容器也可以直接访问LeEngine体系外的虚拟,物理机资源,以及mysq等组件服务。
我们自己写了cni插件和cnictl管理工具,支持添加多个IP段,用来防止IP资源不够的情况。IP段的信息存在了当前kubernetes集群里的etcd中。我们会为每个Cell即每个Kubernetes集群下都添加至少一个IP段,一般1024个IP地址22子网掩码,单独vlan防止广播风暴,这需要提前跟网络部门规划好IP段。如果这个IP段已经使用完,我们会使用cnictl工具,重新增加一个新的IP段。
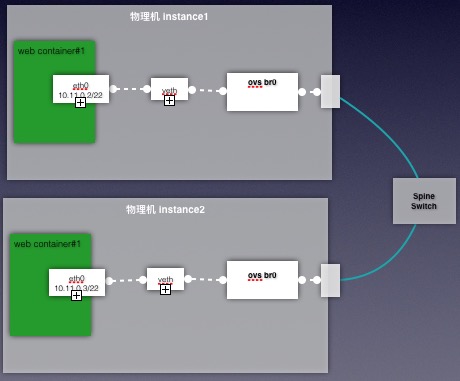
为了进一步保证业务容器在网络方面的稳定性,我们所有的计算节点都是4个网卡,2千兆,2万兆,双双做bond,千兆bond1用来做管理网卡,万兆bond1用来跑业务容器,每个计算节点在交付时候会创建一个ovs 网桥,并将bond1挂载上去,上联交换机做堆叠,计算节点尽量打散在多个不同机柜中。
计算节点物理机上的Kubulet在创建pod的pause 容器后,会调用我们自己cni插件,cni会创建一个veth pair, 一端扔到这个容器的namespace中,并命名eth0,一端挂载到ovs 网桥上,之后从etcd中大的IP段中找出一个连续16个IP地址的小段给这个计算节点,然后再从这个子段中找一个空闲的IP给这个容器,配置好容器IP,以及路由信息,同时会根据配置来确定是否发送免费ARP信息,之后遵守cni规范把相应的信息返回给kubelet。当这个计算节点再次创建新的Pod时,会优先从这个子段中选择空间的IP,若没有空闲的IP地址,会重新计算一个子段给这个计算节点用。
现在cni不能保证pod删掉重新创建时候IP保持不变,因此应用在每次升级操作后,容器IP地址会变,这就需要我们的服务发现与负载均衡做对接。
不过现在的这套方案也会存在一些问题:比如物理主机突然down掉,或者docker进程死掉,导致本主机上所有容器挂掉,等kubelet重新启动后,原来死掉的容器所占用的IP并不会释放。我们现在的解决方案是通过我们开发cnictl命令来进行定期检测。cnictl 提供一个check命令,会检索etcd中所有分配的IP和对应的POD信息,之后调用apiserver获得所有Pod信息,取差值则为没释放的IP地址。收到报警后,人工调用cnictl的释放IP功能,手动释放IP。
服务发现
我们充分利用了Kubernetes的Service概念,前面已经提过,一个应用对应一个Namespace,一个版本对应一个RC,在用户通过API请求创建应用时候,LeEngine核心api层:LeEngin-core 会默认在对应的kubernetes集群中创建相关联的Namespace,同时默认在这个Namespace下创建一个Service,并创建一个唯一的标签属性,用户在部署新版本(RC)时候,LeEngine 会给这个RC添加这个Service的唯一标签。这样就可以通过Service来发现后端的Endpoint。我们用go写了一个服务发现服务,通过watch api-server的api接口,自动归类发现哪个应用下有IP变动,之后调用我们负载均衡的API接口,动态更改nginx的后端upstream serverip。
在我们没使用kubernetes的健康探测功能之前,会有一定的几率出现容器创建完成,服务没有完全启动,这时候容器IP已经加载到负载均衡的情况,如果这时候如果刚好有请求过来,会出现请求失败的现象。之后我们在最新一版中,加入了健康探测功能,用户在给应用部署新版本时,允许用户指定自己服务的监控探测HTTP接口,当容器内服务探测成功后,才会加入到负载均衡中去。而删除容器则不会出现这种情况,执行RC缩容命令后,需要删除的容器首先会立马从负载均衡中删除,之后才会执行容器的删除操作。
负载均衡
我们并没有使用Kubernetes的proxy作为负载均衡,而是使用Nginx集群作为负载均衡。Nginx我们原则上会部署在同一个Region下的多个机房中,防止因为机房网络故障导致全部的Nginx不可用,支持Nginx横向可扩展,当负载均衡压力过大时候,可以快速横向增加Nginx物理机。为防止单一Nginx集群下代理的Domain数目过多,以及区分不同的业务逻辑,比如公网和内网负载均衡,我们支持创建多个nginx负载集群。
下图为用户浏览请求路径。
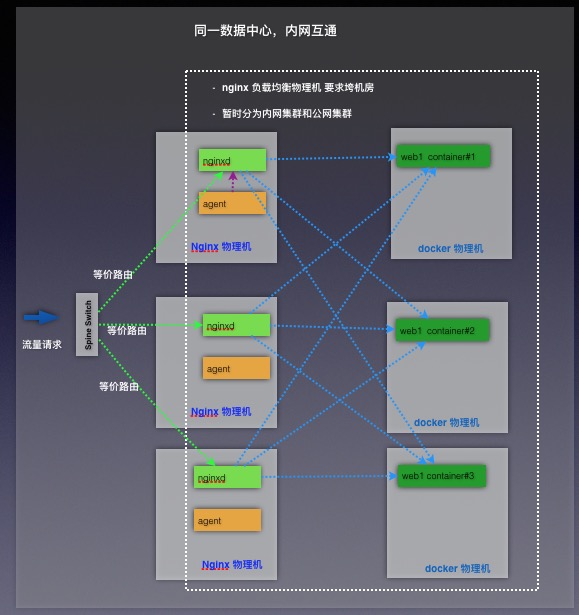
关于如何能够通知nginx集群自动更新upstream下的server ip 问题, 我们在nginx集群外面用beego框架设计了一层api 层:slb-core, 专门对外提供api接口,具体结构如下:
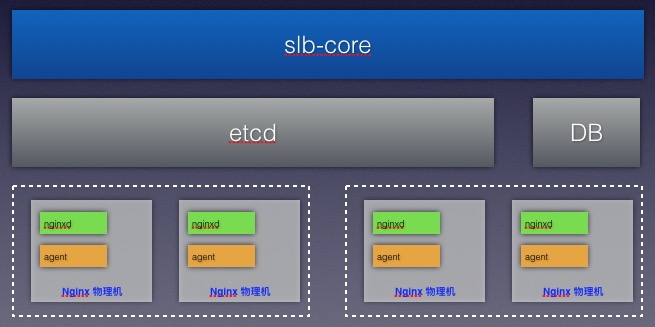
etcd里面存放每个domain的配置信息。具体key结构如下:
/slb/{groupname or groupid}/domains/{domain_name}/
每一台nginx主机上都会安装一个agent,每个agent 监控他所属的groupid 的key,比如/slb/2/
这样可监控本Nginx 集群下所有Domain的配置变化, Agent 将变化过的Domain 配置更新到nginx下的目录下,并判断配置变化是否是更改的upstream 下的server ip 还是其他配置,如果发现是其他配置更改,比如location或者增加header,则会reload nginx, 如果发现单纯更改upstream 下server ip ,则直接调用nginx动态更改upstream ip 的接口。
上层的slb-core 则会提供domain 动态更改后台upstream ip 的接口, 供服务发现调用。
如果多个互相关联,互相调用的业务域名都同时被一个Nginx集群所代理,若其中一个domain 需要更改配置,导致需要reload nginx,很可能会出现reload 时间过长的问题。
基于这套架构,后端nginx主机可以快速扩展,迅速增加到对应集群中。由于增加了nginx test 机制,当用户更改domain的配置有语法问题, 也不会影响负载均衡,还会保持上一个正确的配置。现在这套架构已经是乐视负载集群的通用架构,承载了乐视上千个域名的负载均衡。
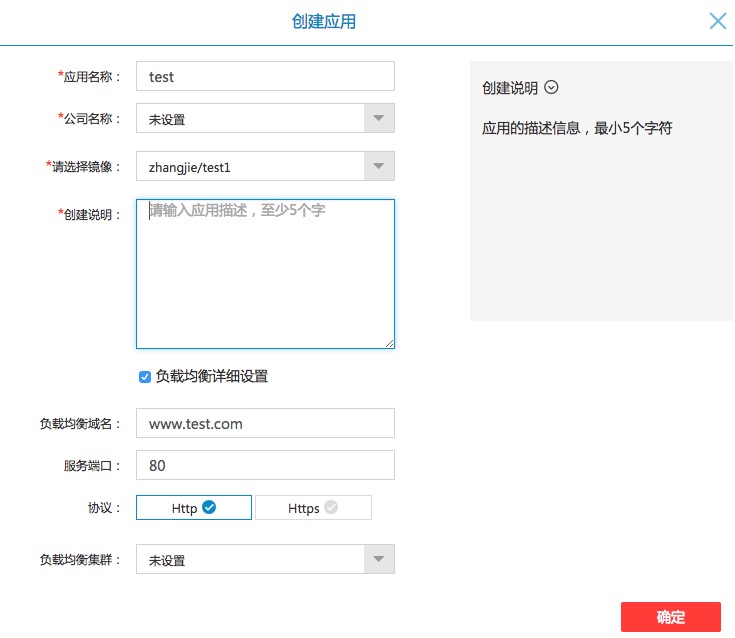
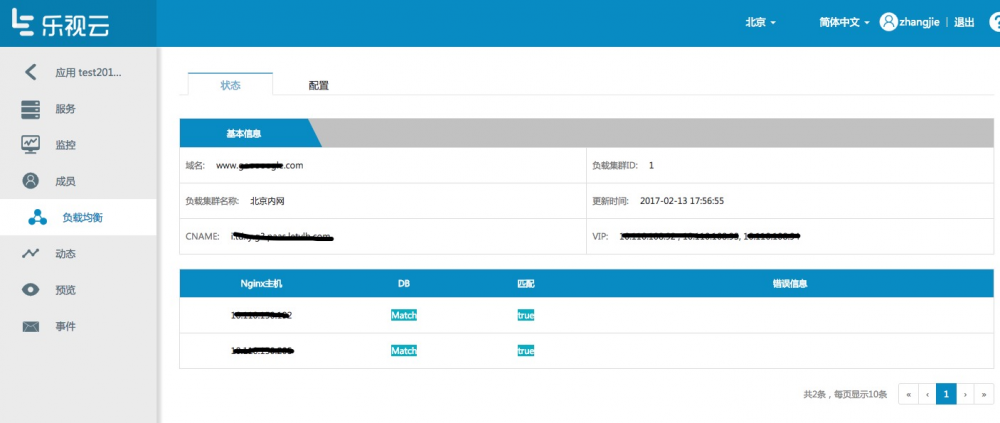
用户在创建一个应用时候,如果需要负载均衡则需要填写负载均衡域名,nginx集群等信息, 如下图:
创建成功后,通过查看应用的负载均衡导航栏可以知道这个应用负载均衡的CNAME和VIP信息,等业务测试成功后,DNS系统上配置使域名生效。
如下图:
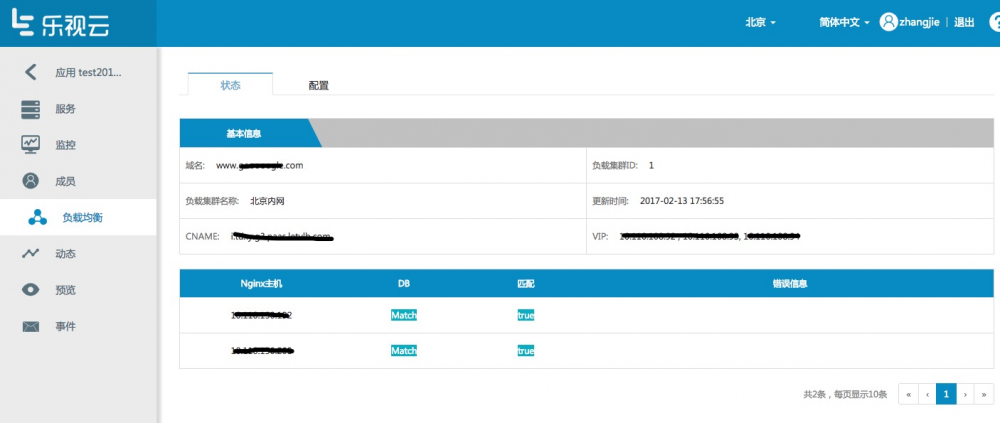
下图可以让用户查看负载均衡nginx配置信息:
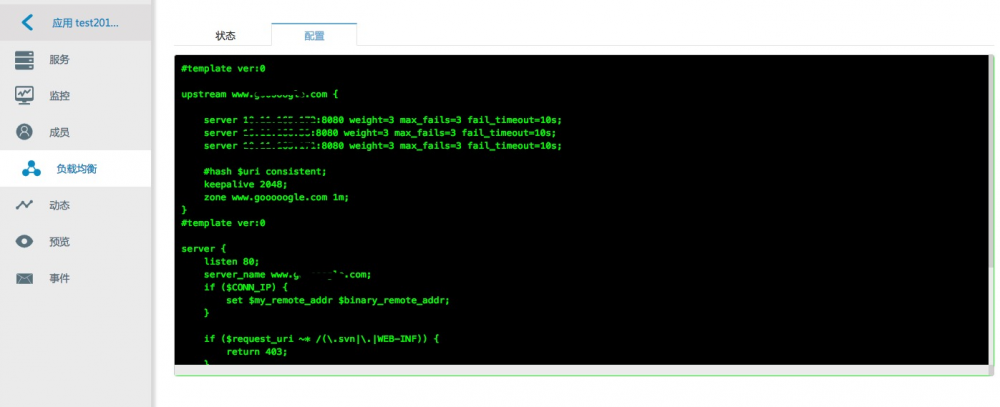
现阶段nginx负载均衡集群并没有按照一个应用来进行划分,大多数情况是一个nginx负载均衡集群代理了多组domain。因此对于用户端,为了防止业务线用户恶意或者无意的随便更改,而导致整个nginx集群出现问题,现阶段用户端无权更改nginx 配置,如果需要更改特殊配置,需要联系管理员,由管理员进行配置。后续我们会考虑给一个应用分配一组nginx容器进行负载均衡代理,这样用户就会拥有nginx配置更改的最高权限。
LeEngine registry
LeEngine Registry 是我们内部提供的镜像仓库,根据docker registry 2.0 版本:docker distribution做了修改,支持乐视ceph 后端存储,同时使用auth-server 以及LeEngine 的权限机制,定义用户和权限划分。允许镜像私有和公开。 公开的镜像任何用户可以执行pull 操作。私有的镜像可以添加团队成员,不同角色的成员具有不同的push,pull, 删除权限。基于以上的设计LeEngine Registry 可以完全独立于LeEngine对外提供镜像仓库服务, 业务线如果不想使用LeEngine的代码构建功能,可以完全使用自己的构建方法,构建出镜像来,之后push 到LeEngine registry中。
如下图是关于镜像tag的相关操作:

成员:
动态:
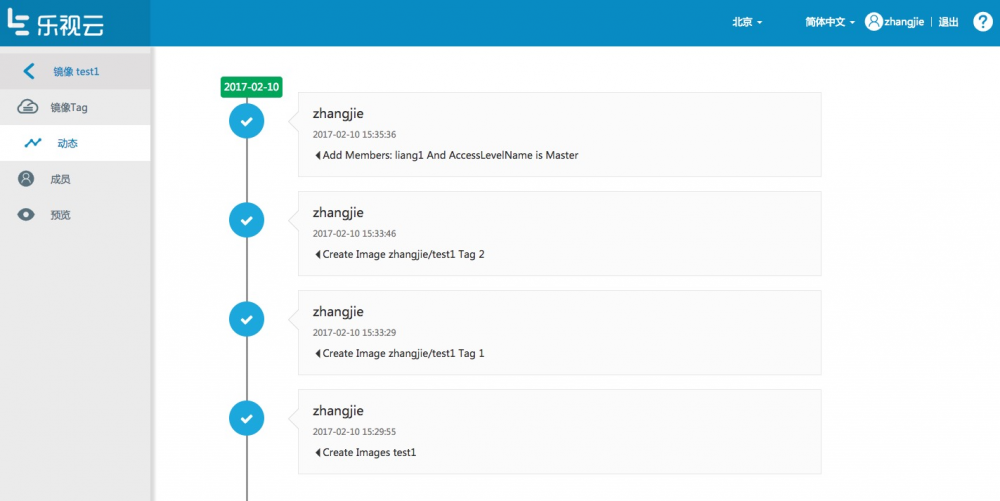
LeEngine下4大资源:应用,镜像,镜像组织,代码构建,在每个资源页里都是有动态一栏,用来记录操作记录,方便以后的问题追踪。
代码构建
为了快速将代码构建成Image,并push 到镜像仓库中,LeEngine后面会设置一组专门构建用的docker物理机集群,用来执行构建任务,每个构建物理机都会安装一个agent。
LeEngine的代码构建框架如下:
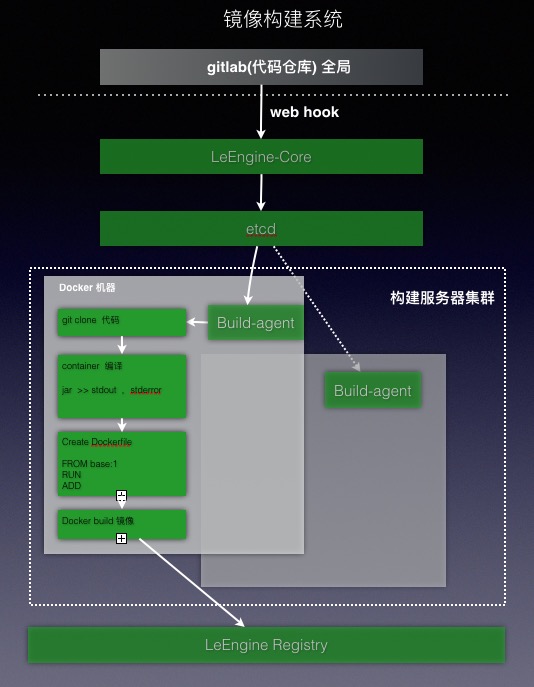
每个构建物理机上的agent 启动后,都会将自己的信息定期自动注册到etcd中,表示新增一台构建机,当agent 意外停止或者主机挂掉,etcd中的注册信息会失效,表示已经下线一台构建机。另外agent会监控自己的任务key,用来接收LeEngine-core 下发的构建任务。
当有一个构建请求时会调用LeEngine-core 的api,LeEngine-core 会从etcd中选出一个合适的构建机(一般按照hash方式,尽量保证一个代码构建在同一台物理机上构建,加快构建速度), 然后将构建任务放到这个构建机的任务key中,对应的agent监控到key 变化后,会执行代码clone,编译,buid和push 操作。
Etcd在LeEngine中扮演这非常重要的角色,是各个模块通信的消息总线。
鉴于Maven项目,需要编译,在第一代Harbor系统中,编译步骤放在了Docker Build 过程中,由于Maven编译需要大量的mvn依赖,每次编译都需要重新下载依赖,导致编译时间长,编译的镜像多大,因此我们在buid之前,会起一个container,在container中对代码进行编译,并将mvn依赖的目录映射到主机上,这样同一个代码构建,在每次构建时候,都会共享同一个mvn依赖,不需要重新下载,加快编译速度,同时还能保证不同的代码构建使用不同的mvn依赖目录,保证编译环境绝对纯净,最后只将编译好的二进制打到镜像中,在一定程度上保证代码不外泄。
代码构建仅限于放在git上的代码,现阶段并不支持svn,因此有的业务如果代码在svn上,可以使用其他工具自己将代码制作成镜像,然后push 到LeEngine Registry上。由于LeEngine Registry 上对镜像和镜像仓库做了权限认证,保证了镜像的安全。
代码构建支持手动构建和自动构建,在gitlab上设置相应的web hook,这样用户只要提交代码,就会自动触发LeEngine的代码构建功能。
下图为创建代码构建的web页:
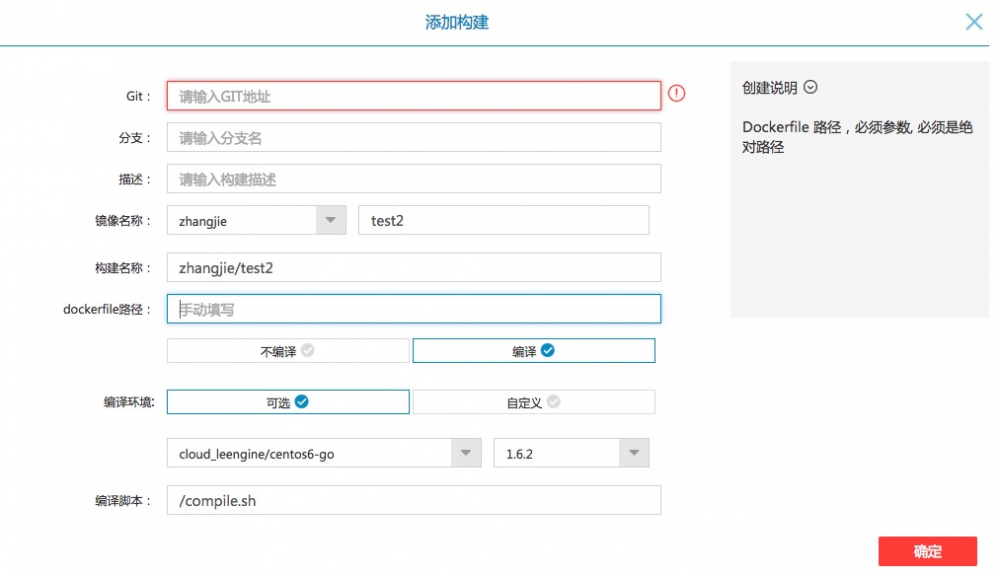
使用LeEngine的代码构建,我们要求用户的代码里需要自己写Dockerfile,Dockerfile 里FROM 的根镜像可以使用LeEngine Registry 里公开的镜像,也可以使用docker hub里公开的镜像。
如果业务代码需要编译,则可以指定编译环境,编译脚本也是需要放到代码中。
下图为手动构建页面:
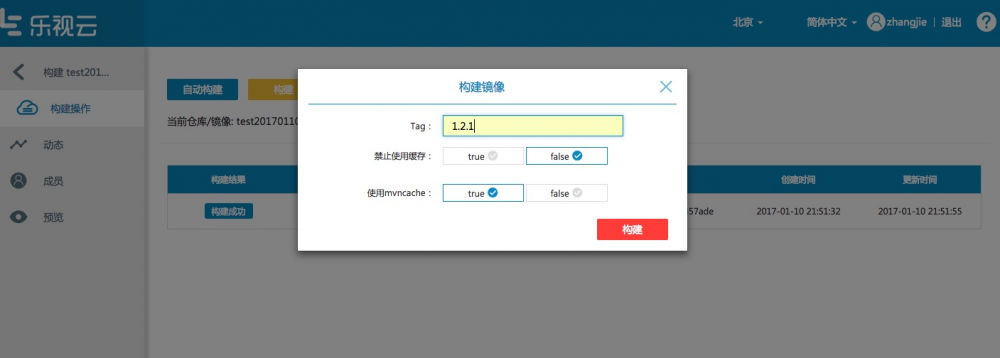
tag名如果不写,LeEngine会根据当前分支下的commit号作为镜像tag名。如果选用mvncache,则本次构建就会使用上次构建所下载的mvn依赖,加快构建速度。
下图为构建结果:
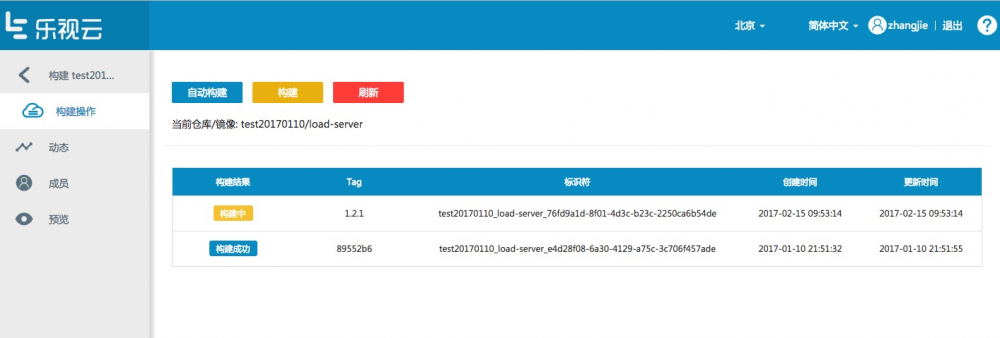
构建过程:
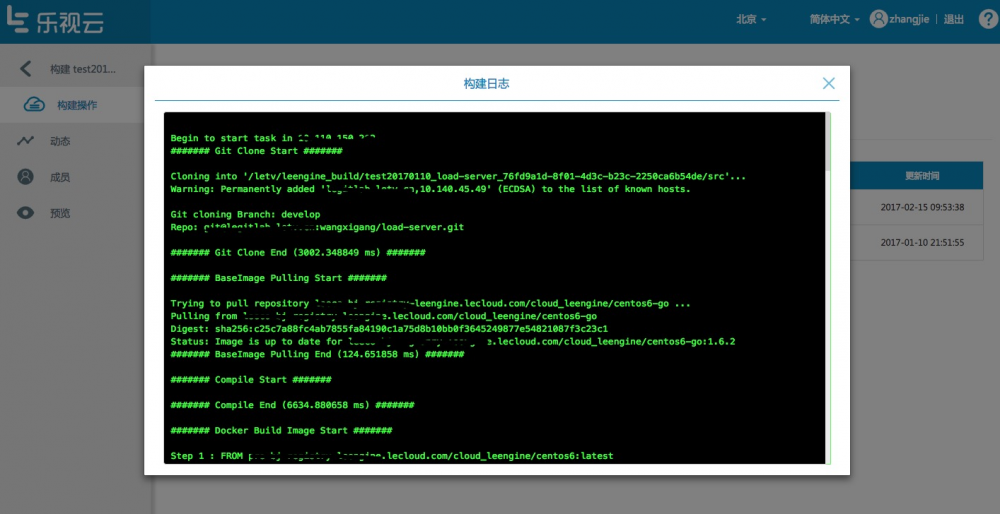
构建日志中,每一关键环节都记录了耗时时间,以及具体的执行过程。
应用管理
应用支持垮机房部署,多版本灰度升级,弹性伸缩等功能。我们规定一个应用对应一个镜像。
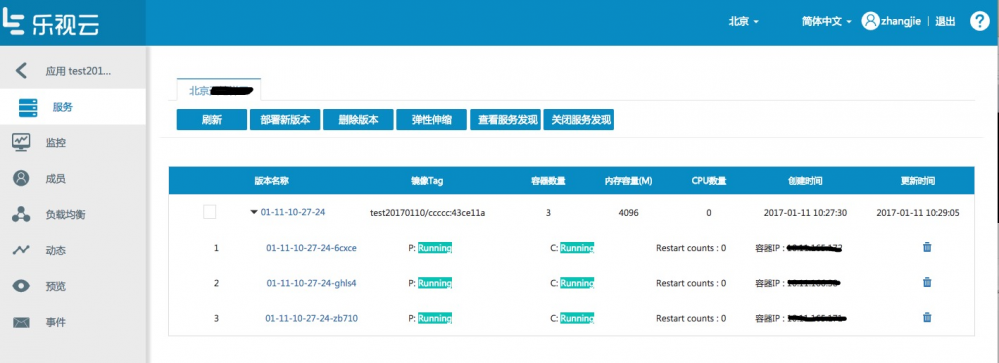
部署版本(一个版本即一个RC)时候,需要指定镜像tag,容器数目,CPU,内存,环境变量,健康检查等等参数,现在的健康检查我们暂时只支持http 接口方式:
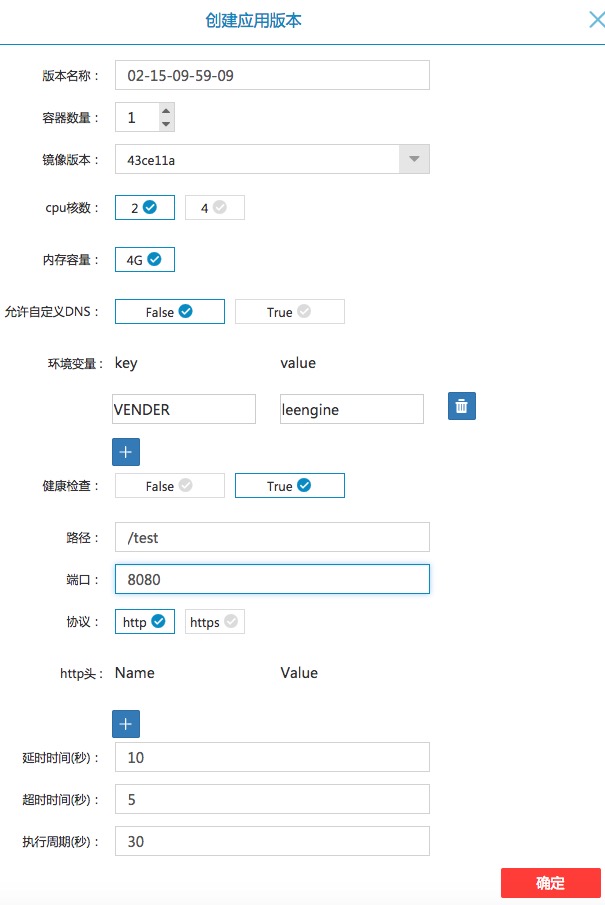
由于大部分的升级,都是更改镜像tag,因此每次部署新版本时候,LeEngine会在新弹出框内,将上一版本的容器数目,cpu,内存,环境变量,健康检查等等参数自动填充到弹出框中,用户只需选择新的镜像tag就可以了。因此最后灰度上线,只需要创建新版本等新版本的容器完全启动,服务自动加入负载均衡后,再将旧版本删除即可。
下图为应用事件查看:
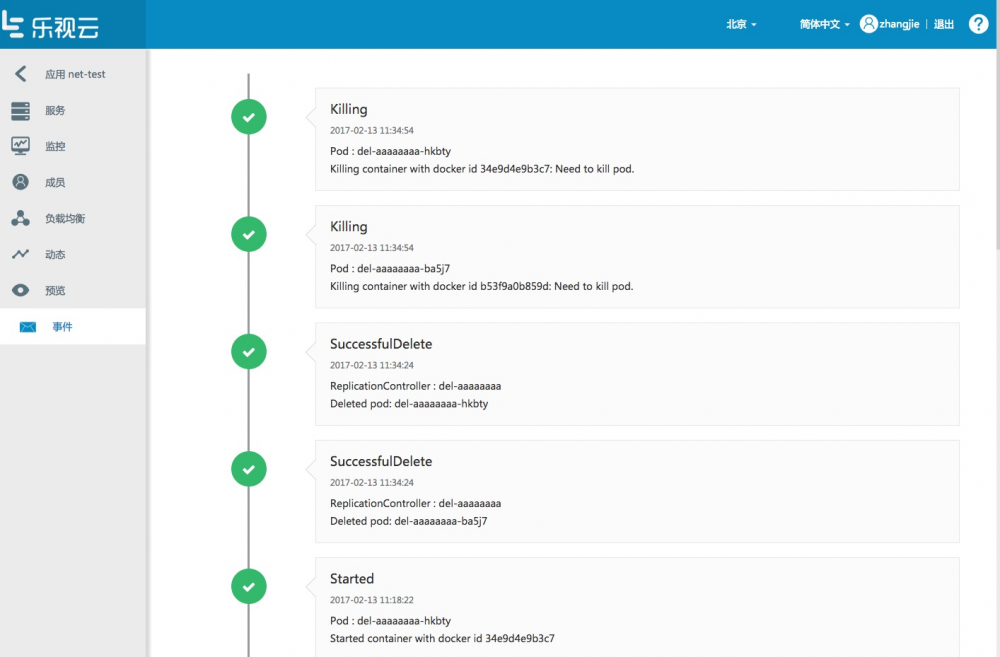
应用事件主要收集的是应用在kubernetes集群中的事件信息。
监控、告警系统
监控报警我们分PAAS平台和业务应用两大类。
PAAS平台主要聚焦在基础设施和LeEngine的各个服务组件的监控报警(比如主机cpu,内存,IO,磁盘空间,LeEngine各个服务进程等等),这一类使用公司统一的监控报警机制。
业务应用类,也就是跑在LeEngine上的各个业务线的监控和报警,需要由LeEngine进行对其进行监控和报警,触发报警后,会通知给各个应用的负责人。我们采用了heapster 来收集容器的监控信息和kubernetes的各种事件。每个cell集群中都部署一个heapster,监控数据存放到influxdb中。设定了一个应用全局对应一个kubernetes的namespace,因此我们能很好的聚合出应用和单个容器的监控数据。
如下图 针对应用的网络流量监控:
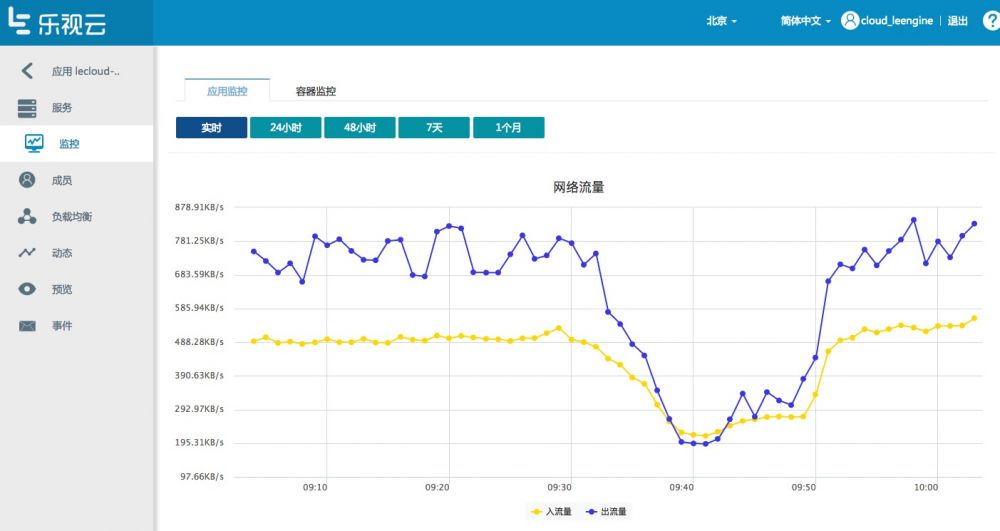
容器 IP,运行时间和状态:
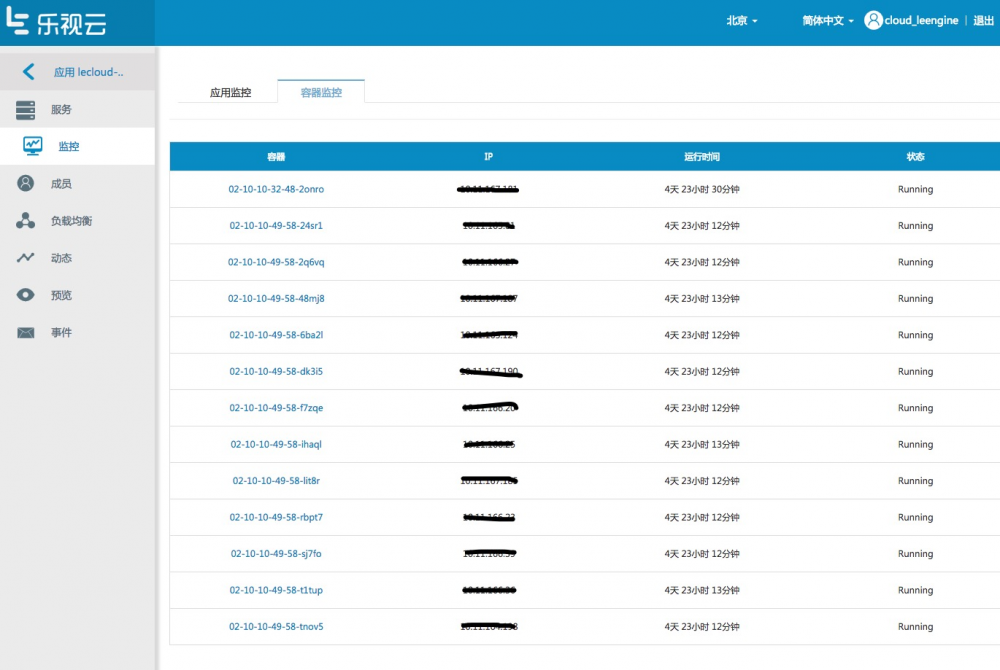
下图是针对应用下单个容器的监控:
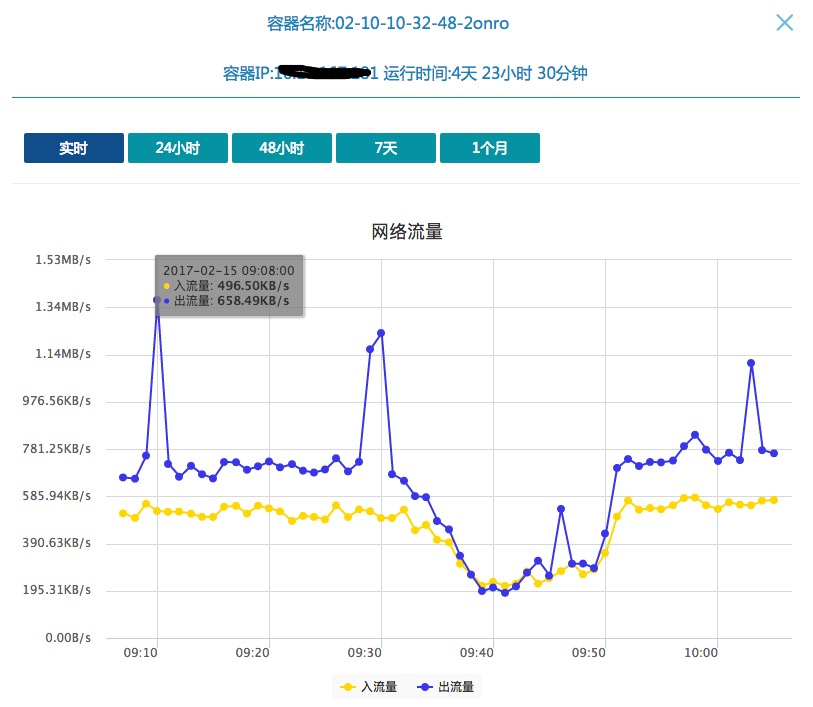
现在heapster 没法收集容器的磁盘io数据,后期我们会增加对于磁盘io的监控收集,同时我们会丰富其他的监控数据(比如请求量等等)。关于报警,我们后期准备使用kapacitor 进行用户自助化报警,让用户自定义设定针对于应用cpu,内存,网络,IO,容器重启,删除等的报警阀值。触发报警后,会调用公司统一的告警平台(电话,邮件,短信三种方式)对相关人员进行报警。默认报警人员为当前应用的owner和master角色的成员。此功能已经基本调研完成,计划3月底上线。
日志收集
根据公司具体状况,容器的日志收集暂时还没有纳入LeEngine范围内,全部由业务线自己收集,然后统一收入到公司的日志系统中或者由业务线自己搭建日志存储和检索系统。我们后期会考虑日志统一收集。
总结
一键式解决方案
LeEngine提供了代码构建,镜像仓库,应用管理,基本上实现了开发者一键式解决方案:
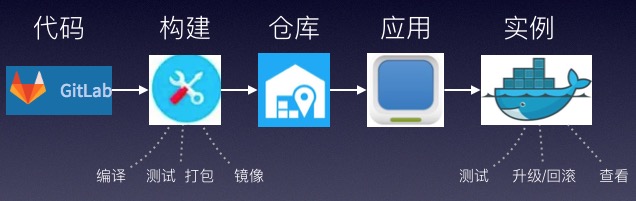
各个业务线开发人员只需要提交代码,剩下的就会根据打包和构建规则自动生成特定的镜像版本,测试和运维人员只需要拿着对应的镜像版本进行测试和线上升级即可,极大简化开发运维工作。
减少运维成本
我们建议程序在容器内前台启动,利用kubernetes的功能,程序死掉后,由kubelet自动拉起,实时保证线上容器实例数。若需要调试,业务或者运维可以直接通过ssh 连接到容器内排查问题。由于kubernetes强大的容器自动迁移功能,即使后端物理主机出现宕机或者网络问题,也不会产生严重的问题,除非后端物理计算资源不够,这在很大程度上减少了运维人员大半夜被叫起处理问题的次数。
计算资源对业务完全透明
底层计算资源完全由我们提供,业务线不用担心资源的问题。
产品化
LeEngine在设计之初,保证尽量少的依赖其他外部资源和服务,整个LeEngine可以作为一个解决方案整体对外输出。
存在的问题
任何一款产品不管怎么设计,都有它的不足之处,LeEngine在上线之后,我们也收到了不少反馈和问题。
1 按照之前的运维习惯,运维人员在排查问题时候,经常会根据IP来进行区分,而LeEngine下的应用每次升级后,容器IP都会变化,这对传统的运维造成一定的冲击。我们现在的解决思路是,如果运维人员一定要通过IP去排查,我们会让运维人员登录LeEngine的console,查看当前应用下的容器IP列表,之后再去逐个排查。同时有的业务会对IP进行访问限制,针对这种情况,我们只能让这些业务对一个IP段进行限制。
2 kubernetes 1.2 版本,对容器的swap并没有控制,若业务应用有bug,出现大量的内存泄露,往往会把容器所在物理机的swap吃满,而影响了物理机上其他的容器。 我们现在的解决方案暂时只能通过报警方式,尽快让用户修复问题。
3由于dockerfile 和编译脚本都要求放在用户git代码中。会存在用户git使用不规范,不同分支代码互相merge,导致dockerfile和编译脚本出现变化,导致构建出的镜像与预期的不一样,从而上线失败。这种问题,我们只能要求业务线规范git使用规范,LeEngine代码构建本身已经无法控制到这种细粒度。
4 现阶段我们还没法做到自动弹性扩容(给应用设定一个最小容器数目和最大容器数目的阀值,根据cpu,内存,io,请求量,或者其他值,自动觉得容器是否需要扩容,缩容)。
展望
Docker 和kubernetes也在飞速发展中,相信kubernetes未来会有更加强劲的功能,我们后续也会考虑把有状态的服务跑到kubernetes中去,欢迎大家一块探索。
微信号:longxingtianxia0619
电话:18310797319
正文到此结束
- 本文标签: 产品 开发 调试 dist web VMware 需求 下载 id swap Docker 安装 Developer 管理 推广 认证 业务层 网卡 智能 压力 参数 开发者 build ssh 代码 ACE maven Master 实例 安全 开源 开源项目 统计 测试 ip 域名 Service 进程 插件 UI 线下 目录 SDN 删除 db IO 负载均衡 DOM 集群 性能问题 PaaS core 编译 shell 空间 免费 美国 组织 Region 企业 云 Google http node cache DNS 解析 cat 总结 数据 src Nginx SVN 时间 2015 高可用 数据库 key 配置 Uber API 主机 端口 自动生成 git Kubernetes
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

