Node.js模块化机制原理探究
前言
Node应用是由模块组成的,Node遵循了CommonJS的模块规范,来隔离每个模块的作用域,使每个模块在它自身的命名空间中执行。
CommonJS规范的主要内容:
模块必须通过 module.exports 导出对外的变量或接口,通过 require() 来导入其他模块的输出到当前模块作用域中。
CommonJS模块的特点:
(1)所有代码运行在当前模块作用域中,不会污染全局作用域
(2)模块同步加载,根据代码中出现的顺序依次加载
(3)模块可以多次加载,但是只会在第一次加载时运行一次,然后运行结果就被缓存了,以后再加载,就直接读取缓存结果。要想让模块再次运行,必须清除缓存。
一个简单的例子:
demo.js
module.exports.name = 'Aphasia';
module.exports.getAge = function(age){
console.log(age)
};
//需要引入demo.js的其他文件
var person = require('./demo.js')
module对象
根据CommonJS规范,每一个文件就是一个模块,在每个模块中,都会有一个module对象,这个对象就指向当前的模块。module对象具有以下属性:
(1)id:当前模块的bi
(2)exports:表示当前模块暴露给外部的值
(3)parent: 是一个对象,表示调用当前模块的模块
(4)children:是一个对象,表示当前模块调用的模块
(5)filename:模块的绝对路径
(6)paths:从当前文件目录开始查找node_modules目录;然后依次进入父目录,查找父目录下的node_modules目录;依次迭代,直到根目录下的node_modules目录
(7)loaded:一个布尔值,表示当前模块是否已经被完全加载
示例:
module.js
module.exports = {
name: 'Aphasia',
getAge: function(age){
console.log(age)
}
}
console.log(module)
执行 node module.js
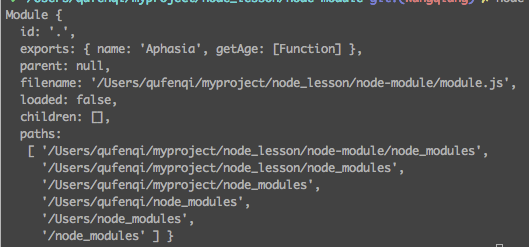
1、module.exports
从上面的例子我们也能看到,module对象具有一个exports属性,该属性就是用来对外暴露变量、方法或整个模块的。当其他的文件require进来该模块的时候,实际上就是读取了该模块module对象的exports属性。
简单的使用示例
module.exports = 'Aphasia';
module.exports.name = 'Aphasia';
module.exports = function(){
//dosomething
}
module.exports = {
name: 'Aphasia',
getAge: function(){
//dosomething
}
}
2、exports对象
一开始我很郁闷,既然module.exports就能满足所有的需求,为什么还有个exports对象呢?其实,二者之间有下面的关系
(1)首先,exports和module.exports都是引用类型的变量,而且这两个对象指向同一块内存地址。在node中,二者一开始都是指向一个空对象的
exports = module.exports = {};
可以在REPL环境中直接运行下面代码 module.exports ,结果会输出一个 {}
(2)其次, exports对象是通过形参的方式传入的,直接赋值形参会改变形参的引用,但是并不能改变作用域外的值。 这句话是什么意思呢?我们举个例子。
var module = {
exports: {}
}
var exports = module.exports
function change(exports) {
//为形参添加属性,是会同步到外部的module.exports对象的
exports.name = "Aphasia"
//在这里修改了exports的引用,并不会影响到module.exports
exports = {
age: 24
}
console.log(exports) //{ age: 24 }
}
change(exports)
console.log(module.exports) //{exports: {name: "Aphasia"}}
现在明白了吧?其实我们在模块中像下面的代码那样,直接给exports赋值,会改变当前模块内部的形参exports对象的引用,也就是说当前的exports已经跟外部的module.exports对象没有任何关系了,所以这个改变是不会影响到module.exports的。因此,下面的这种方式是没有任何效果的,所有的属性和方法都不会被抛出。
//以下操作都是不起作用的
exports = 'Aphasia';
exports = function(){
console.log('Aphasia')
}
其实module.exports就是为了解决上述exports直接赋值,会导致抛出不成功的问题而产生的。有了它,我们就可以这样来抛出一个模块了。
//这些操作都是合法的
exports.name = 'Aphasia';
exports.getName = function(){
console.log('Aphasia')
}
//相当于下面的方式
module.exports = {
name: 'Aphasia',
getName: function(){
console.log('Aphasia')
}
}
这样就不用每次把要抛出的对象或方法赋值给exports的属性了 ,直接采用对象字面量的方式更加方便。
模块实例的require方法
我们都知道,当使用exports或者module.exports抛出一个模块,通过给require()方法传入模块标识符参数,然后node根据一定的规则引入该模块之后,我们就能使用模块中定义的方法和属性了。这里要讲的就是node的模块引入规则。
1、node中引入模块的机制
在Node中引入模块,需要经历3个步骤
(1)路径分析
(2)文件定位
(3)编译执行
在Node中,模块一般分为两种
(1)Node提供的模块,例如http、fs等,称为 核心模块 。核心模块在node源代码编译的过程中就编译进了二进制执行文件,在Node进程启动的时候,部分核心模块就直接加载进内存中了,因此这部分模块是不用经历上述的(2)(3)两个步骤的,而且在路径分析中是优先判断的,因此加载速度最快。
(2)用户自己编写的模块,称为 文件模块 。文件模块是按需加载的,需要经历上述的三个步骤,速度较慢。
优先从缓存中加载
与浏览器会缓存静态脚本文件以提高页面性能一样,Node对引入过的模块也会进行缓存。不同的地方是,node缓存的是编译执行之后的对象而不是静态文件。这一点我们可以用下面的方式来验证。
modA.js
console.log('模块modA开始加载...')
exports = function() {
console.log('Hi')
}
console.log('模块modA加载完毕')
init.js
var mod1 = require('./modA')
var mod2 = require('./modA')
console.log(mod1 === mod2)
执行 node init.js ,运行结果:

虽然我们两次引入modA这个模块,但是模块中的代码其实只执行了一遍。并且mod1和mod2指向了同一个模块对象。
下面是Module._load的源码:
Module._load = function(request, parent, isMain) {
// 计算绝对路径
var filename = Module._resolveFilename(request, parent);
// 第一步:如果有缓存,取出缓存
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
// 第二步:是否为内置模块
if (NativeModule.exists(filename)) {
return NativeModule.require(filename);
}
// 第三步:生成模块实例,存入缓存
var module = new Module(filename, parent);
Module._cache[filename] = module;
// 第四步:加载模块
try {
module.load(filename);
hadException = false;
} finally {
if (hadException) {
delete Module._cache[filename];
}
}
// 第五步:输出模块的exports属性
return module.exports;
};
对应流程如下图所示:
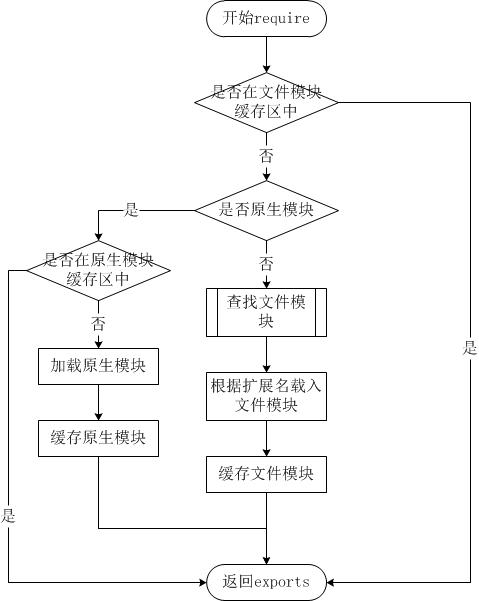
2、路径分析和文件定位
路径分析
模块标识符分析:
(1)核心模块,如http、fs、path
(2)以 . 或 .. 开始的相对路径文件模块
(3)以 / 开始的绝对路径文件模块
(4)非路径形式的文件模块
1)核心模块:优先级仅次于缓存,加载速度最快;如果自定义模块与核心模块名称相同,加载是不会成功的。若想加载成功,必须选择一个不同的名称或者换用路径。
2)路径形式的文件模块:以 . || .. || / 开始的标识符,都会被当做文件模块来处理。在加载的过程中,require方法会将路径转换为真实的路径,加载速度仅次于核心模块
3) 非路径形式的自定义模块:这是一种特殊的文件模块,可能是一个文件或者包的形式。查找这类模块的策略类似于JS中作用域链,Node会逐个尝试 模块路径 中的路径,直到找到目标文件为止。
模块路径: 这是Node在定位文件模块的具体文件时指定的查找策略,具体表现为一个路径组成的数组。
可以在REPL环境中输出Module对象,查看其path属性的方式查看上述数组
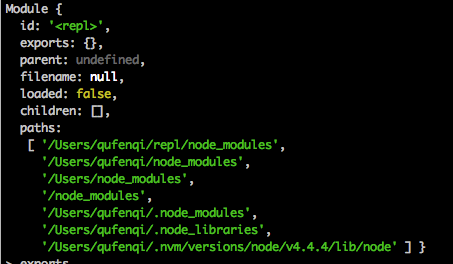
文件定位:
-
文件扩展名分析
require()分析的标识符可以不包含扩展名,node会按.js、.node、.json的次序补足扩展名,依次尝试
-
目标分析和包
如果在扩展名分析的步骤中,查找不到文件而是查找到相应目录,此时node会将目录当做包来处理,进行下一步分析查找当前目录下package.json中的main属性指定的文件名,若查找不成功则依次查找index.js,index.node,index.json。
如果目录分析的过程中没有定位到任何文件,则自定义模块会进入下一个模块路径继续查找,直到所有的模块路径都遍历完毕,依然没找到则抛出查找失败的异常。
参考源码
在Module._load方法的内部调用了Module._findPath这个方法,这个方法是用来返回模块的绝对路径的,源码如下:
Module._findPath = function(request, paths) {
// 列出所有可能的后缀名:.js,.json, .node
var exts = Object.keys(Module._extensions);
// 如果是绝对路径,就不再搜索
if (request.charAt(0) === '/') {
paths = [''];
}
// 是否有后缀的目录斜杠
var trailingSlash = (request.slice(-1) === '/');
// 第一步:如果当前路径已在缓存中,就直接返回缓存
var cacheKey = JSON.stringify({request: request, paths: paths});
if (Module._pathCache[cacheKey]) {
return Module._pathCache[cacheKey];
}
// 第二步:依次遍历所有路径
for (var i = 0, PL = paths.length; i < PL; i++) {
var basePath = path.resolve(paths[i], request);
var filename;
if (!trailingSlash) {
// 第三步:是否存在该模块文件
filename = tryFile(basePath);
if (!filename && !trailingSlash) {
// 第四步:该模块文件加上后缀名,是否存在
filename = tryExtensions(basePath, exts);
}
}
// 第五步:目录中是否存在 package.json
if (!filename) {
filename = tryPackage(basePath, exts);
}
if (!filename) {
// 第六步:是否存在目录名 + index + 后缀名
filename = tryExtensions(path.resolve(basePath, 'index'), exts);
}
// 第七步:将找到的文件路径存入返回缓存,然后返回
if (filename) {
Module._pathCache[cacheKey] = filename;
return filename;
}
}
// 第八步:没有找到文件,返回false
return false;
};
3、清除缓存
根据上述的模块引入机制我们知道,当我们第一次引入一个模块的时候,require的缓存机制会将我们引入的模块加入到内存中,以提升二次加载的性能。但是,如果我们修改了被引入模块的代码之后,当再次引入该模块的时候,就会发现那并不是我们最新的代码,这是一个麻烦的事情。如何解决呢?
查看require对象

- require(): 加载外部模块
- require.resolve():将模块名解析到一个绝对路径
- require.main:指向主模块
- require.cache:指向所有缓存的模块
- require.extensions:根据文件的后缀名,调用不同的执行函数
解决方法
//删除指定模块的缓存
delete require.cache[require.resolve('/*被缓存的模块名称*/')]
// 删除所有模块的缓存
Object.keys(require.cache).forEach(function(key) {
delete require.cache[key];
})
然后我们再重新require进来需要的模块就可以了。
参考链接
- 通过源码解析 Node.js 中一个文件被 require 后所发生的故事
- 阮一峰--CommonJS规范
- Nodejs源码--GitHub
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

