jQuery 源码系列(六)sizzle 编译
讲了这么久的 Sizzle,总感觉差了那么一口气,对于一个 selector,我们把它生成 tokens,进行优化,优化的步骤包括去头和生成 seed 集合。对于这些种子集合,我们知道最后的匹配结果是来自于集合中的一部分,似乎接下来的任务也已经明确:对种子进行过滤(或者称其为匹配)。

匹配的过程其实很简单,就是对 DOM 元素进行判断,而且弱是那种一代关系(>)或临近兄弟关系(+),不满足,就结束,若为后代关系(space)或者兄弟关系(~),会进行多次判断,要么找到一个正确的,要么结束,不过仍需要考虑回溯问题。
比如 div > div.seq h2 ~ p ,已经对应的把它们划分成 tokens,如果每个 seed 都走一遍流程显然太麻烦。一种比较合理的方法就是对应每个可判断的 token 生成一个闭包函数,统一进行查找。
Expr.filter 是用来生成匹配函数的,它大概长这样:
Expr.filter = {
"ID": function(id){...},
"TAG": function(nodeNameSelector){...},
"CLASS": function(className){...},
"ATTR": function(name, operator, check){...},
"CHILD": function(type, what, argument, first, last){...},
"PSEUDO": function(pseudo, argument){...}
} |
看两个例子,一切都懂了:
Expr.filter["ID"] = function( id ) {
var attrId = id.replace( runescape, funescape );
//这里返回一个函数
return function( elem ) {
return elem.getAttribute("id") === attrId;
};
}; |
对 tokens 分析,让发现其 type 为 ID,则把其 id 保留,并返回一个检查函数,参数为 elem,用于判断该 DOM 的 id 是否与 tokens 的 id 一致。这种做法的好处是,编译一次,执行多次。
那么,是这样的吗?我们再来看看其他例子:
Expr.filter["TAG"] = function( nodeNameSelector ) {
var nodeName = nodeNameSelector.replace( runescape, funescape ).toLowerCase();
return nodeNameSelector === "*" ?
//返回一个函数
function() { return true; } :
// 参数为 elem
function( elem ) {
return elem.nodeName && elem.nodeName.toLowerCase() === nodeName;
};
};
Expr.filter["ATTR"] = function( name, operator, check ) {
// 返回一个函数
return function( elem ) {
var result = Sizzle.attr( elem, name );
if ( result == null ) {
return operator === "!=";
}
if ( !operator ) {
return true;
}
result += "";
return operator === "=" ? result === check :
operator === "!=" ? result !== check :
operator === "^=" ? check && result.indexOf( check ) === 0 :
operator === "*=" ? check && result.indexOf( check ) > -1 :
operator === "$=" ? check && result.slice( -check.length ) === check :
operator === "~=" ? ( " " + result.replace( rwhitespace, " " ) + " " ).indexOf( check ) > -1 :
operator === "|=" ? result === check || result.slice( 0, check.length + 1 ) === check + "-" :
false;
};
}, |
最后的返回结果:
- input[type=button] 属性 type 类型为 button;
- input[type!=button] 属性 type 类型不等于 button;
- input[name^=pre] 属性 name 以 pre 开头;
- input[name*=new] 属性 name 中包含 new;
- input[name$=ed] 属性 name 以 ed 结尾;
- input[name=~=new] 属性 name 有用空格分离的 new;
- input[name|=zh] 属性 name 要么等于 zh,要么以 zh 开头且后面有关连字符 -。
所以对于一个 token,即生成了一个闭包函数,该函数接收的参数为一个 DOM,用来判断该 DOM 元素是否是符合 token 的约束条件,比如 id 或 className 等等。如果将多个 token (即 tokens)都这么来处理,会得到一个专门用来判断的函数数组,这样子对于 seed 中的每一个元素,就可以用这个函数数组对其父元素或兄弟节点挨个判断,效率大大提升,即所谓的编译一次,多次使用。
compile 源码
直接贴上 compile 函数代码,这里会有 matcherFromTokens 和 matcherFromGroupMatchers 这两个函数,也一并介绍了。
var compile = function(selector, match) {
var i,setMatchers = [],elementMatchers = [],
cached = compilerCache[selector + " "];
// 判断有没有缓存,好像每个函数都会判断
if (!cached) {
if (!match) {
// 判断 match 是否生成 tokens
match = tokenize(selector);
}
i = match.length;
while (i--) {
// 这里将 tokens 交给了这个函数
cached = matcherFromTokens(match[i]);
if (cached[expando]) {
setMatchers.push(cached);
} else {
elementMatchers.push(cached);
}
}
// 放到缓存
cached = compilerCache(
selector,
// 这个函数生成最终的匹配器
matcherFromGroupMatchers(elementMatchers, setMatchers)
);
// Save selector and tokenization
cached.selector = selector;
}
return cached;
}; |
编译 compile 函数貌似很简单,来看 matcherFromTokens:
//
function matcherFromTokens(tokens) {
var checkContext,matcher,j,len = tokens.length,leadingRelative = Expr.relative[tokens[0].type],
implicitRelative = leadingRelative || Expr.relative[" "],
i = leadingRelative ? 1 : 0,
// 确保元素都能找到
// addCombinator 就是对 Expr.relative 进行判断
/*
Expr.relative = {
">": { dir: "parentNode", first: true },
" ": { dir: "parentNode" },
"+": { dir: "previousSibling", first: true },
"~": { dir: "previousSibling" }
};
*/
matchContext = addCombinator(
function(elem) {
return elem === checkContext;
},implicitRelative,true),
matchAnyContext = addCombinator(
function(elem) {
return indexOf(checkContext, elem) > -1;
},implicitRelative,true),
matchers = [
function(elem, context, xml) {
var ret = !leadingRelative && (xml || context !== outermostContext) || ((checkContext = context).nodeType ? matchContext(elem, context, xml) : matchAnyContext(elem, context, xml));
// Avoid hanging onto element (issue #299)
checkContext = null;
return ret;
}
];
for (; i < len; i++) {
// 处理 "空 > ~ +"
if (matcher = Expr.relative[tokens[i].type]) {
matchers = [addCombinator(elementMatcher(matchers), matcher)];
} else {
// 处理 ATTR CHILD CLASS ID PSEUDO TAG,filter 函数在这里
matcher = Expr.filter[tokens[i].type].apply(null, tokens[i].matches);
// Return special upon seeing a positional matcher
// 伪类会把selector分两部分
if (matcher[expando]) {
// Find the next relative operator (if any) for proper handling
j = ++i;
for (; j < len; j++) {
if (Expr.relative[tokens[j].type]) {
break;
}
}
return setMatcher(
i > 1 && elementMatcher(matchers),
i > 1 && toSelector(
// If the preceding token was a descendant combinator, insert an implicit any-element `*`
tokens
.slice(0, i - 1)
.concat({value: tokens[i - 2].type === " " ? "*" : ""})
).replace(rtrim, "$1"),
matcher,
i < j && matcherFromTokens(tokens.slice(i, j)),
j < len && matcherFromTokens(tokens = tokens.slice(j)),
j < len && toSelector(tokens)
);
}
matchers.push(matcher);
}
}
return elementMatcher(matchers);
} |
其中 addCombinator 函数用于生成 curry 函数,来解决 Expr.relative 情况:
function addCombinator(matcher, combinator, base) {
var dir = combinator.dir, skip = combinator.next, key = skip || dir, checkNonElements = base && key === "parentNode", doneName = done++;
return combinator.first ? // Check against closest ancestor/preceding element
function(elem, context, xml) {
while (elem = elem[dir]) {
if (elem.nodeType === 1 || checkNonElements) {
return matcher(elem, context, xml);
}
}
return false;
} : // Check against all ancestor/preceding elements
function(elem, context, xml) {
var oldCache, uniqueCache, outerCache, newCache = [dirruns, doneName];
// We can't set arbitrary data on XML nodes, so they don't benefit from combinator caching
if (xml) {
while (elem = elem[dir]) {
if (elem.nodeType === 1 || checkNonElements) {
if (matcher(elem, context, xml)) {
return true;
}
}
}
} else {
while (elem = elem[dir]) {
if (elem.nodeType === 1 || checkNonElements) {
outerCache = elem[expando] || (elem[expando] = {});
// Support: IE <9 only
// Defend against cloned attroperties (jQuery gh-1709)
uniqueCache = outerCache[elem.uniqueID] || (outerCache[elem.uniqueID] = {});
if (skip && skip === elem.nodeName.toLowerCase()) {
elem = elem[dir] || elem;
} else if ((oldCache = uniqueCache[key]) && oldCache[0] === dirruns && oldCache[1] === doneName) {
// Assign to newCache so results back-propagate to previous elements
return newCache[2] = oldCache[2];
} else {
// Reuse newcache so results back-propagate to previous elements
uniqueCache[key] = newCache;
// A match means we're done; a fail means we have to keep checking
if (newCache[2] = matcher(elem, context, xml)) {
return true;
}
}
}
}
}
return false;
};
} |
其中 elementMatcher 函数用于生成匹配器:
function elementMatcher(matchers) {
return matchers.length > 1 ? function(elem, context, xml) {
var i = matchers.length;
while (i--) {
if (!matchers[i](elem, context, xml)) {
return false;
}
}
return true;
} : matchers[0];
} |
matcherFromGroupMatchers 如下:
function matcherFromGroupMatchers(elementMatchers, setMatchers) {
var bySet = setMatchers.length > 0,
byElement = elementMatchers.length > 0,
superMatcher = function(seed, context, xml, results, outermost) {
var elem,j,matcher,matchedCount = 0,i = "0",unmatched = seed && [],setMatched = [],
contextBackup = outermostContext,
// We must always have either seed elements or outermost context
elems = seed || byElement && Expr.find["TAG"]("*", outermost),
// Use integer dirruns iff this is the outermost matcher
dirrunsUnique = dirruns += contextBackup == null ? 1 : Math.random() || 0.1,len = elems.length;
if (outermost) {
outermostContext = context === document || context || outermost;
}
// Add elements passing elementMatchers directly to results
// Support: IE<9, Safari
// Tolerate NodeList properties (IE: "length"; Safari: <number>) matching elements by id
for (; i !== len && (elem = elems[i]) != null; i++) {
if (byElement && elem) {
j = 0;
if (!context && elem.ownerDocument !== document) {
setDocument(elem);
xml = !documentIsHTML;
}
while (matcher = elementMatchers[j++]) {
if (matcher(elem, context || document, xml)) {
results.push(elem);
break;
}
}
if (outermost) {
dirruns = dirrunsUnique;
}
}
// Track unmatched elements for set filters
if (bySet) {
// They will have gone through all possible matchers
if (elem = !matcher && elem) {
matchedCount--;
}
// Lengthen the array for every element, matched or not
if (seed) {
unmatched.push(elem);
}
}
}
// `i` is now the count of elements visited above, and adding it to `matchedCount`
// makes the latter nonnegative.
matchedCount += i;
// Apply set filters to unmatched elements
// NOTE: This can be skipped if there are no unmatched elements (i.e., `matchedCount`
// equals `i`), unless we didn't visit _any_ elements in the above loop because we have
// no element matchers and no seed.
// Incrementing an initially-string "0" `i` allows `i` to remain a string only in that
// case, which will result in a "00" `matchedCount` that differs from `i` but is also
// numerically zero.
if (bySet && i !== matchedCount) {
j = 0;
while (matcher = setMatchers[j++]) {
matcher(unmatched, setMatched, context, xml);
}
if (seed) {
// Reintegrate element matches to eliminate the need for sorting
if (matchedCount > 0) {
while (i--) {
if (!(unmatched[i] || setMatched[i])) {
setMatched[i] = pop.call(results);
}
}
}
// Discard index placeholder values to get only actual matches
setMatched = condense(setMatched);
}
// Add matches to results
push.apply(results, setMatched);
// Seedless set matches succeeding multiple successful matchers stipulate sorting
if (outermost && !seed && setMatched.length > 0 && matchedCount + setMatchers.length > 1) {
Sizzle.uniqueSort(results);
}
}
// Override manipulation of globals by nested matchers
if (outermost) {
dirruns = dirrunsUnique;
outermostContext = contextBackup;
}
return unmatched;
};
return bySet ? markFunction(superMatcher) : superMatcher;
} |
这个过程太复杂了,请原谅我无法耐心的看完。。。
先留名,以后分析。。。
到此,其实已经可以结束了,但我本着负责的心态,我们再来理一下 Sizzle 整个过程。
Sizzle 虽然独立出去,单独成一个项目,不过在 jQuery 中的代表就是 jQuery.find 函数,这两个函数其实就是同一个,完全等价的。然后介绍 tokensize 函数,这个函数的被称为词法分析,作用就是将 selector 划分成 tokens 数组,数组每个元素都有 value 和 type 值。然后是 select 函数,这个函数的功能起着优化作用,去头去尾,并 Expr.find 函数生成 seed 种子数组。
后面的介绍就马马虎虎了,我本身看的也不少很懂。compile 函数进行预编译,就是对去掉 seed 后剩下的 selector 生成闭包函数,又把闭包函数生成一个大的 superMatcher 函数,这个时候就可用这个 superMatcher(seed) 来处理 seed 并得到最终的结果。
那么 superMatcher 是什么?
superMatcher
前面就已经说过,这才是 compile()() 函数的正确使用方法,而 compile() 的返回值即 superMatcher,无论是介绍 matcherFromTokens 还说介绍 matcherFromGroupMatchers,其结果都是为了生成超级匹配,然后处理 seed,这是一个考验的时刻,只有经得住筛选才会留下来。
总结
下面是别人总结的一个流程图:
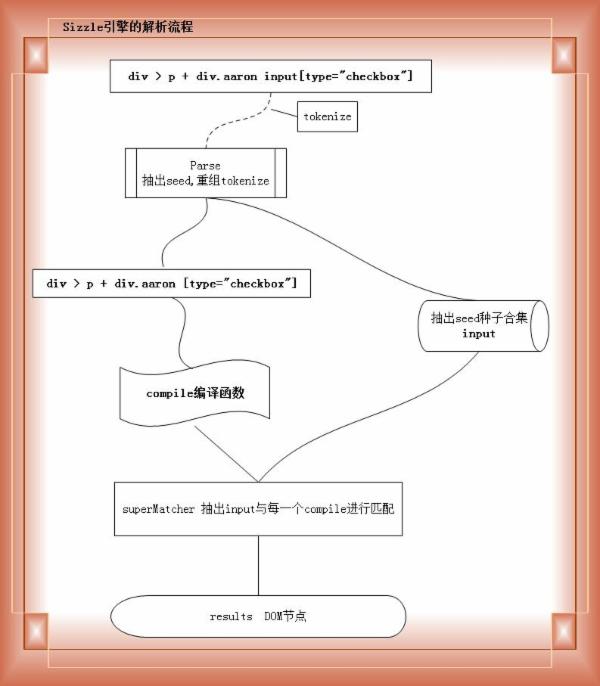
第一步
| 1 |
div > p + div.aaron input[type="checkbox"] |
从最右边先通过 Expr.find 获得 seed 数组,在这里的 input 是 TAG,所以通过 getElementsByTagName() 函数。
第二步
重组 selector,此时除去 input 之后的 selector:
| 1 |
div > p + div.aaron [type="checkbox"] |
第三步
此时通过 Expr.relative 将 tokens 根据关系分成紧密关系和非紧密关系,比如 [“>”, “+”] 就是紧密关系,其 first = true。而对于 [“ “, “~”] 就是非紧密关系。紧密关系在筛选时可以快速判断。
matcherFromTokens 根据关系编译闭包函数,为四组:
div > p + div.aaron input[type="checkbox"] |
编译函数主要借助 Expr.filter 和 Expr.relative。
第四步
将所有的编译闭包函数放到一起,生成 superMatcher 函数。
function( elem, context, xml ) {
var i = matchers.length;
while ( i-- ) {
if ( !matchers[i]( elem, context, xml ) ) {
return false;
}
}
return true;
} |
从右向左,处理 seed 集合,如果有一个不匹配,则返回 false。如果成功匹配,则说明该 seed 元素是符合筛选条件的,返回给 results。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

