机器学习算法实践之K均值聚类的实用技巧
编者按:本文作者为美国数据分析专家 Bilal Mahmood,他是用户数据分析平台 Bolt 的创始人之一。在本文中,他详细介绍了一种称为 K-Means Clustering(k均值聚类)的算法,其中包括如何衡量算法效果,以及如何确定你需要生成的数据段集数量。雷锋网 (公众号:雷锋网) 编译整理,更多AI开发技术文章,关注AI研习社(微信号:okweiwu)。
Bilal Mahmood:我们最常做的分析之一,便是在数据中提取模式。 比方说,某公司的客户可被划分入哪些细分市场? 我们如何在用户网络中找到特定群体的聚类?
通过机器学习的方式,我们可以得到这些问题的答案。 即使当我们不知道需要查找哪些特定数据段,亦或我们的数据格式是非结构化数据,我们都可以有这么一种技术手段,在算法上,分析出数据中合理的数据模式,合适的数据段和分类结果。
在本文中,我们将会详细介绍一种算法,K-Means Clustering(K均值聚类),包括如何衡量其效果,以及如何确定我们要生成的数据段集数量。
监督VS无监督学习
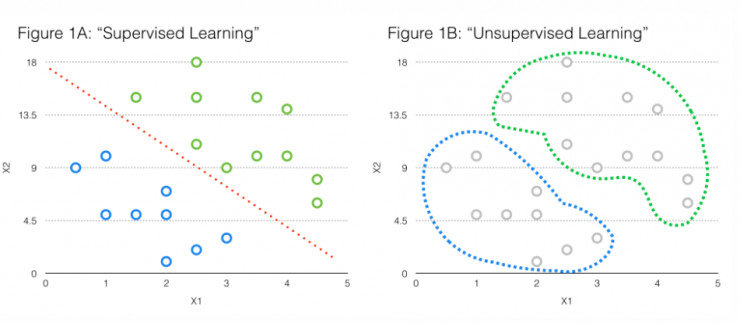
在数据分类领域里,有两种有效的机器学习方式。
通过监督学习,如果你搞清楚哪些输入能映射到哪些离散数据段,便可以对结果的分类做预测。 但在许多情况下,实际上不会有这些预定义好的标签,而只有非结构化数据——根本没有定义好的数据段。这时,您可能就需要借助无监督学习,从未标记的数据中推理出目标数据段。
为了更清楚一些,我们以分类T恤尺寸为例
如果我们拿到如图1A所示数据集,我们将有一组宽度(X1)和长度(X2)的输入,以及他们对应的T恤衫尺寸(S(蓝色)L(绿色)) 。 在这种情况下,我们就可以通过监督学习的技术,如逻辑回归,来绘制一个明确的决策边界,并分离出各类T恤。
但如果我们得到一个如图1B所示的数据集,我们得到一组宽度(X1)和长度(X2)的输入,但没有对应的T恤衫尺寸标签。 在这种情况下,我们就需要使用K均值聚类等无监督式学习技术,来找到相似的T恤衫,并将它们聚集到小(蓝色圆圈)和大(绿色圆圈)的各个类中。
在现实世界的许多应用中,你将面临如图2A所示的情况,因此搞明白如何从非结构化的数据中提取出结构,会有很大的用处。
K均值聚类 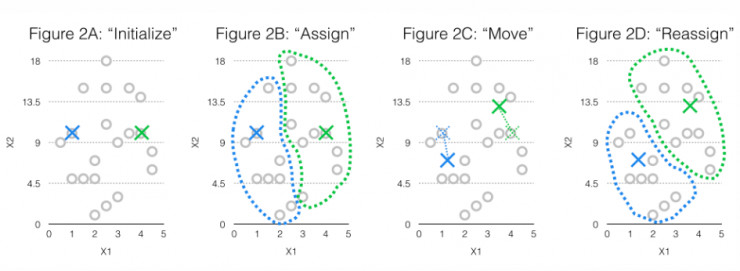
K均值聚类给无监督机器学习提供了一个非常直观的应用,在非结构化的数据中归纳出结构,
K均值聚类,正如其名,会将您的数据中相似的观察结果,分配到同组簇中。 它包括4个简单重复的步骤,迭代地评估对每个观察值有最近(平均)距离的簇。 因此,如果一组观察结果彼此接近,它们可能属于一组簇。
让我们逐步细细了解该算法。 第一步,随机初始化一组聚类中心(上面图2A中的X),或者说,是各组簇的中心。在开始之前,你可以将这些聚类中心设置在任何地方,但我们建议,在你对其初始化的时候,用与你设定的观察值相匹配的随机点。您将依次利用这些类中心,来对你的观察值进行分组,将那些与类中心平均距离最近的观察值(图2B中的蓝色和绿色圆圈)确定一个聚类归属。
该步骤会将数据初始化成几组簇,将你的数据中与类中心最接近的观察值聚集到一起。 但是这些第一次分配后的数据簇,可能不是十分合适的。 所以下一步,你会将你的聚类好的数据簇移动到一个更接近,更合适的位置。即在每个当前已有的各个簇中 找到它们的平均观察值,然后你的聚类中心移动到该位置来(图2C)。 然后,以新的聚类中心为基准,找到的平均距离最近的观察值,并将其分配到新的簇(图2D)
您可以重复进行此过程:簇分配-查找平均距离-移动聚类中心,直到达到收敛。 一旦你找到了一组簇,而且其中所有的观察值都能找到最接近的聚类中心,那就不需要再继续评估最近的平均距离和移动了。 那些分组在一起的观察值将被聚类,这样的话它们可以在输入中共享相似性(如由它们对同一聚类中心所表现出的接近度),你也为你的数据找到了一组合适的聚类方式。
你使用了多少组簇?
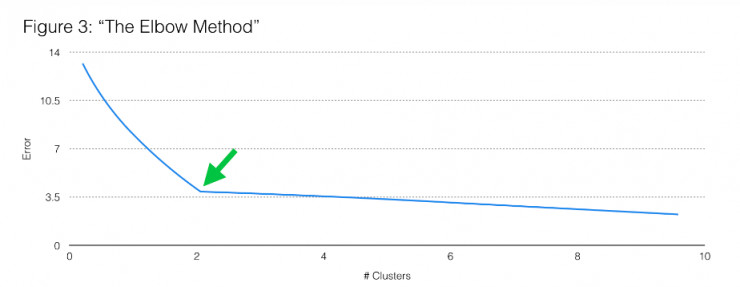
K均值聚类是一种有效的方法,可以为你的数据找到一个良好的聚类方式。 但仍然有一个问题,一开始你如何决定要使用多少组簇?
当你不清楚非结构化数据集的标签或者分类时,需要无监督学习的方式(如K均值聚类)来辅助。 因此,数据本身不会告诉你,簇的正确数量(或标签)是多少。
那么,你该如何衡量自己数据用多少组簇呢? 最简单的方法是利用测量簇的误差,具体如下:
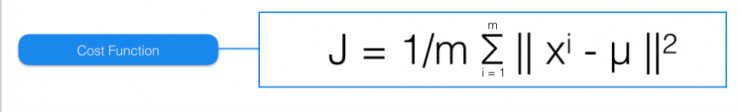
此函数通过比较观察值(X)与其指定的聚类中心(μ)之间的距离来评估簇的误差。 如果每个对应的聚类中心均呈现最低距离,或者最低总体误差最低,那么这些聚类中心就是与数据最符合的聚类结果。
回到我们T恤衫尺寸的示例,我们如何使用该误差函数来确定正确的簇的数目? 一种方法是“肘部法则”,如上图3所示。 通过绘制数据相对于你初始化的簇的数量的误差,你可以发现误差变化率最尖锐的点。 图3中似乎是在两个簇的地方,表明我们应该可能去划分为小和大两种。
雷锋网提醒,该方法需要注意:通常在你的误差曲线中没有明显的拐点。 因此,不可能总是使用肘部法则来确定合适数量的簇。
在这种情况下,建议依靠你的直觉或者待解决的问题的上下文。 例如,在T恤尺寸案例中,你可能很清楚你想将T恤分为5种尺寸 - 超小型,小型,中型,大型和超大型。但这并不是数据给你提示清楚的,但基于你的直觉,你可以初始化为五个簇数量,并得到合适的聚类。
总而言之,对于到一个聚类问题,K均值聚类提供了一种可迭代的并且有效的算法来发掘数据中的结构。
雷锋网注:这篇博文是基于吴恩达在 Coursera 机器学习课程 中教授的概念。
via kdnuggets
雷锋网版权文章,未经授权禁止转载。详情见 转载须知 。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

