OpenAI探讨人工智能安全:用对抗样本攻击机器学习
对抗样本是扮演攻击角色、试图用来引发模型出错的机器学习模型的输入;如同机器产生的光影幻觉。在这篇博文中,我们将为读者展示对抗样本在各种不同介质中的运作原理,还会讨论为什么系统难以防御它们。
在 OpenAI , 我们认为,对抗样本问题属于人工智能安全研究(我们正在从事)好的一面,因为它们代表着一个能在短期内加以解决的具体问题,由于解决它们比较难,因此需要进行严肃的科学研究。(尽管为了确保打造出一个安全、广为分布的人工智能系统,我们需要研究许多机器学习安全许多方面的问题。)
为了搞清楚对抗样本的庐山真面,请考虑一下这篇研究《解释并驯服对抗样本(Explaining and Harnessing Adversarial Examples)》中的例证:开始是一张熊猫图片,接着,攻击方给图片添加了小的扰乱,足以让这只熊猫被认定为一只长臂猿。
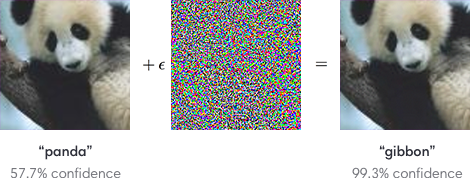
叠加在典型图片输入上的对抗输入会让分类器产生错觉,误将熊猫识别为长臂猿。
这一办法十分稳健;近期的一些研究也已经表明,在标准论文上打印出对抗样本,用一部标准像素智能手机拍下来后,这些样本仍然可以捉弄系统。

对抗样本可以在论文上打印出来,用标准像素手机拍下后,仍然可以捉弄分类器,在这个例子中,分类器将「洗衣机」识别为「保险箱」。
对抗样本具有潜在危险性。比如,攻击者可能会用贴纸或者一幅画做一个对抗式「停止(stop)」交通标志,将攻击对象瞄准自动驾驶汽车,这样,车辆就可能将这一「标志」解释为「放弃」或其他标识,进而引发危险。Practical Black-Box Attacks against Deep Learning Systems using Adversarial Examples 讨论过这个问题。
一些新近的研究,比如,伯克利,OpenAI 以及宾大联合发表的论文 Adversarial Attacks on Neural Network Policies, 内华达大学 Vulnerability of Deep Reinforcement Learning to Policy Induction Attacks ,表明强化学习智能体也能被对抗样本操控。研究表明,广为采用的强化学习算法,比如,DQN , TRPO 以及 A3C ,都经不起对抗样本的捉弄。这些对抗样本输入会降低系统性能,即使扰乱微妙地让人类也难以察觉,智能体会在应该往上移动的时候却将球拍向下移动,或者在 Seaquest 中识别敌人的能力受到干扰。
如果各位看官想玩坏自己的模型,不放试一下 cleverhans 这个开源库,它是 Ian Goodfellow 和 Nicolas Papernot 一起研发的,旨在测试面对对抗样本,你的人工智能模型有多脆弱。
在人工智能安全问题方面,对抗样本提供了一些牵引力
当你思考人工智能安全时,经常会考虑这个领域中最难的问题——我们如何能确保成熟的强化学习智能体(比人类要智能得多)能按照最初设计意图行事?
对抗样本向我们展示了这样一个事实:即使是简单的现代算法,不管是监督学习还是强化学习,都能以出乎人类意料的方式行事。
力图防卫对抗样本
让机器学习模型更加稳健的传统技术,比如权重衰减或者 dropout,通常无法切实防范对抗样本。到目前为止,仅有两个办法可以提供显著的防范措施。
对抗训练:这是一种蛮力解决方案。我们简单地生成许多对抗样本,明确训练模型不要被这些样本给骗了。cleverhans 库提供了一个开源的对抗训练实现,这个教程里有指南:
https://github.com/openai/cleverhans/blob/master/tutorials/mnist_tutorial_tf.md
Defensive distillation (https://arxiv.org/abs/1511.04508): 在这一策略中,我们训练模型生成关于输入属于不同类别的概率,而不是硬让系统决定输入到底属于哪一类。这一概率由更早一些的模型提供,该模型是针对同一任务,用比较难的类别标签训练过的。这会让我们得到一种模型——其表面在对手通常会加以利用的方向上是平滑的,这会使得对手很难发现导致错误分类的对抗输入调整。(Distilling the Knowledge in a Neural Network (https://arxiv.org/abs/1503.02531) 最初将这个办法视为一种模型压缩技术,为了节省计算资源,小模型被训练用来模拟大模型。)
然而,只要个敌方再添加些计算火力,这些专门的算法也会被轻易攻下。
失败的防御:「梯度掩模(gradient masking)」
为了给出一个关于简单防御可能如何失败的案例,让我们思考一下为什么一种叫做「梯度掩模(gradient masking)」的技术没有效果。
「梯度掩模」是一个由 2016 年的论文《使用对抗样本对深度学习系统进行实际的黑盒攻击(Practical Black-Box Attacks against Deep Learning Systems using Adversarial Examples)》引入的术语,其描述了一整类试图通过拒绝攻击者对有用梯度(useful gradient)的访问权限而进行防御的失败方法。
大多数对抗样本构建技术都使用了模型的梯度来进行攻击。打个比方,它们查看了一张飞机图片,它们测试在图片空间中哪个方向会使「猫」类别的概率增加,然后它们在那个方向上给予一点推动(换句话说,它们干扰输入)。这样,新的修改过的图像就会被认为是一只猫。
但如果其中并没有梯度呢——如果图片上一个无穷小的修改不会给模型的输出造成任何改变呢?这似乎就能够提供一定程度的防御,因为攻击者无法获悉向哪个方向「推动」图像。
我们可以轻松地想象出一些非常简单的避免梯度的方式。比如,大部分图像分类模型都可归于两种模式:一是它们仅输出识别出的最有可能的类别,二是它们输出概率。如果一个模型的输出是「99.9% 的概率是飞机,0.1% 的概率是猫」,那么对输入的一点微小改变也会给输出带来一点微小的改变,而梯度就会告诉我们哪些改变会增加属于「猫」类的概率。如果我们运行的模型的模式是仅仅输出「飞机」而没有概率,那么一点微小的改变就不会对输出产生任何影响,梯度也不会让我们了解任何东西。
下面让我们进行一个思想实验,看我们的模型在处于「最有可能类别」模式而非「概率模式」类别时,可以如何防御对抗样本。攻击者不再需要寻找将被分类为「猫」的输入,所以我们可能已经有了一些防御。不幸的是,之前被分类为「猫」的图像现在仍然还是被分类为「猫」。如果攻击者可以猜测哪些点是对抗样本,那么这些点仍然可被错误地分类。所以这种方法不能让该模型更稳健;只是让攻击者在寻找模型防御的漏洞时没有那么多的线索罢了。
更不幸的是,事实证明攻击者在猜测防御漏洞时具有非常好的策略。攻击者可以训练一个他们自己的模型——一个有梯度的平滑的模型,并为他们的模型制作对抗样本,然后只需要部署这些对抗样本和我们的非平滑模型进行对抗即可。很多时候,我们的模型也会错误分类这些样本。最后,我们的思想实验表明:隐藏梯度不会给我们带来任何好处。
执行「梯度掩模」的防御策略通常会导致得到一个在特定方向上和训练点的附近非常平滑的模型,这会使得对手更难以找到指示了好的候选方向的梯度,从而更难以以破坏性的方式干扰该模型的输入。但是,对手可以训练一个「替代(substitute)」模型:一个模仿被保护的模型的副本——这可以通过观察被保护模型分配给对手仔细选择的输入的标签而实现。
这篇黑盒攻击论文介绍了一种用于执行这种模型提取攻击(model extraction attack)的方法。然后对手可以使用这种替代模型的梯度来寻找被被保护模型错误分类的对抗样本。在上图(该图来自论文《关于机器学习中的安全和隐私的科学(Towards the Science of Security and Privacy in Machine Learning)》中关于梯度掩模的讨论)中,我们给出了这种攻击策略在一个一维机器学习问题上的应用。该梯度掩模现象(gradient masking phenomenon)在更高维的问题上会加剧,但这是难以描述的。
我们发现对抗训练和 defensive distillation 都会偶尔执行一定类型的梯度掩模。这两种算法明显都不是为梯度掩模而设计的,但当机器学习算法要进行保护自己的训练而未被给出明确的方法指令时,梯度掩模显然是该机器学习算法能相对轻松地发明的一种防御。如果我们将对抗样本从一个模型迁移到另一个也经过对抗训练或 defensive distillation 训练过的模型,那么这个攻击通常会成功——即使当对第二个模型的直接进攻会失败时。这表明这两种模型做得更多的是展平模型和移除梯度,而不是确保其正确分类更多的点。
为什么防御(defend)对抗样本很难?
对抗样本难以防御是因为很难构造对抗样本处理过程的理论模型。对抗样本是许多机器学习模型非线性、非凸性优化问题的解决方案,包括神经网络在内。因为我们没有好的理论工具来描述这些复杂的优化问题的解决方案,所以也很难作出理论性争辩说一种防御能够排除一系列的对抗样本。
对抗样本难以防御也因为它们需要机器学习模型为每个可能的输入生成好的输出。大部分时间,机器学习模型做的很好,但只有在小量的可能输入的情况下它们可能会碰头。
目前为止我们测试的每个策略都失败了是因为它不够自适应(adaptive):它能够限制一种攻击,但对知道该防御手段的攻击者(attacker)而言,它有其它弱点。设计一种能够防御强大的、会自适应的攻击者的手段,这是一个重要的研究领域。
结论
对抗样本表明能以惊人的方式打破许多现代机器学习算法。机器学习上的这些失败证明即使是简单的算法也能表现出与设计初衷相差甚远的行为。我们鼓励机器学习研究人员参与进来,设计提防对抗样本的方法,从而缩短设计者初衷与算法表现之间的差距。
原文 http://www.jiqizhixin.com/article/2302正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

