如何打造类似数据虫巢官网系列教程之二:爬虫是怎么炼成的

文·blogchong
本文接上一篇 《如何打造类似数据虫巢官网系列教程之一:介绍已经准备工作》 ,不清楚前面剧情的童鞋可以先看看。
这篇文章重点在于解决“数据虫巢官网”的底层数据问题,即那些分析数据的原始数据的来源。
结论很明显,当然是爬过来的,所以这篇我们将重点讲讲如何进行数据爬取,并且以虫巢官网的底层数据爬取代码为例子进行讲解。
当然,其中会一些常规的防爬机制破解以及应对的话题,整体来说这篇会偏重互联网公开数据集的爬取,即爬虫。
此外,整个数据虫巢官网的站点源代码,目前已经整理到github上咯,先放上github的链接: github.com/blogchong/mite8-com 。
这是一个完整的项目,这部分代码包括以下部分:
1 整个数据虫巢数据处理后端框架。
2 前端每个页面JSP代码部分,以及涉及数据可视化渲染部分。
3 几个重点数据源的爬虫逻辑,以及定期更新爬虫数据的入口逻辑。
4 数据处理中涉及到的NLP部分,有几个侧重点,包括重构加工的分词工具,以及简单的情感分析,并且提供了分词的一个工具接口。
PS:如果感兴趣,clone之前别忘了给个star,哈哈。
爬虫框架 - Webcollector
回到主题,说到爬虫,由于我之前对于Python并不是很熟悉,而Java则是我的拿手好戏,并且目前市面上封装的爬虫工具很多,所以,我的考虑就是Java语言封装的Webcollector。
简单说一下这个框架,大伙儿感兴趣的可以去开源中国搜一下他的主页,对于Java不熟悉的朋友,其实也无所谓的,使用其他的Python框架一样是可以的,那这部分关于框架这块的就可以略过啦。
Webcollector支持各种自定义的遍历策略,这种在于路径规则不明确的时候使用是很有用的,比如我当时在爬取各大主流招聘网站的JD数据时,就通过这种模式做的,但如果是目的明确的,其实就是按照自己的业务逻辑去固定路径一次性获取数据了。
Webcollector对于Cookie、请求头之类的信息,提供了设置接口,可以很方便的伪装成浏览器,以及登录状态去爬取数据。
Webcollector集成了传统的JDBC持久化策略,可以很方便的将爬取的数据进行MySQL落地,以及MongDB落地等。
使用上也很方面,集成在Maven中,并且更新还是蛮及时的,所以需要集成到自己的Java代码中,只需要引入Jar包即可开整。
除此之外,Webcollector内部封装了selenium,对于动态加载的JS数据来说,也可以很轻松的拿到相关的数据。
其实上面基本都是它的一些特性,对于新手来说都太模糊,这个框架最好的地方在于作者提供了大量的博客实例,来解释各种特性,以及各种简单的爬虫实例可供参考,简直就是初学者的福音。
具体不再多说,想了解更多的,可以搜索然后进入进行学习。
爬取数据
不同的网站对于数据的展现以及输出方式可能都有点不同,静态的网页数据是最好获取的,比如我之前爬取一些偏传统的招聘网站的数据,直接通过入口就可以拿到数据,基本不设防。
代码例子:
CrawlDatum crawlDatum = new CrawlDatum(listUrl).putMetaData("method", "POST");
HttpRequest request = new HttpRequest(crawlDatum.getUrl());
request.setMethod(crawlDatum.getMetaData("method"));
HttpResponse httpResponse = request.getResponse();
Page page = new Page(crawlDatum, httpResponse);
我们拿到了HttpResponse对象,并且封装成Page对象,通过Page对象提供的Html解析方法,进行数据拆解。
其实Page底层的实现依然是Jsoup,一种很常规的Html结构解析包,我们来看一下具体的使用:
page.select("div[class=review-content clearfix]").text()
这是一个很常见的解析过程语法,在page对象中查找class名为“review-content clearfix ”的div,并且调用text方法,将内容转换为String。
静态页面,基本上会上门两招就够了,访问页面数据,然后解析数据,将非结构化的数据转换为结构化数据,当然具体怎么入库,在Java里方式就很多了。
除了静态页面之外,还有其他形式的数据获取。
比如现在很流行的一种做法,那就是前后端进行分离,即后端数据由额外的请求进行获取,再通过前端进行异步渲染。
其实这种做法也是有理由的,因为后端数据的请求跟前端其他部分渲染效率是不同,所以一般做成异步请求,这样在整个页面在后端效率不高时不会造成整个页面等待,提升用户效率。
这个时候,你单纯的看页面源码已经不行啦,你需要会使用浏览器的元素审查,把这些异步请求的链接给逮出来。
我在做雾霾影响分析报告时,基础原始数据是京东的口罩购买数据,并且是评论数据,其评论就是异步加载获取的。
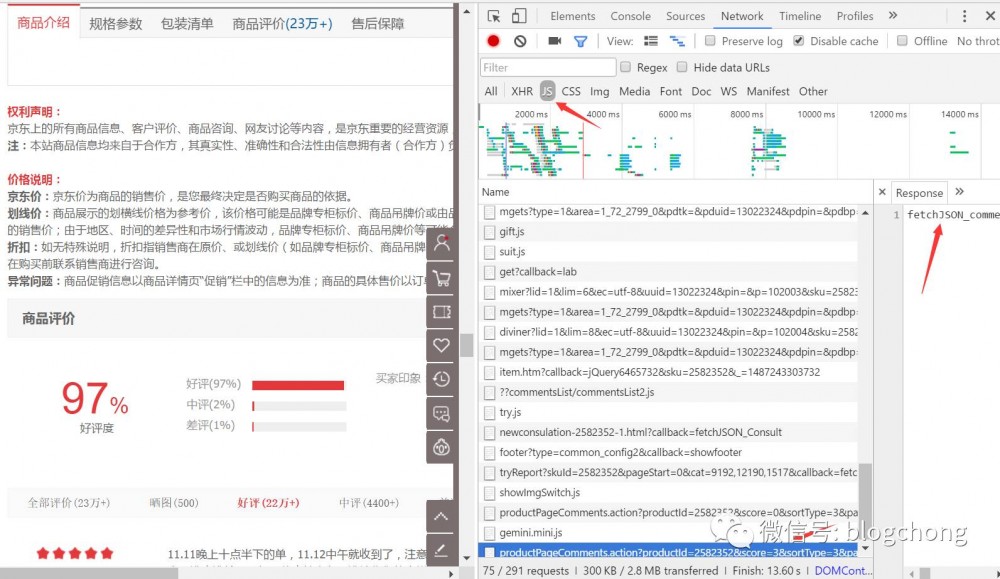
通过F12做元素审查,找到评论数据的真正调用接口,一般异步操作都是放到JS里,并且接口在命名上有一定的提示,如上图就是京东商品的评论数据接口。
大概链接长这样子:
https://sclub.jd.com/comment/productPageComments.action?productId=2582352&score=3&sortType=3&page=0&pageSize=10&isShadowSku=0&callback=fetchJSON_comment98vv47364

里头有控制翻页的参数,我们控制部分参数就可以愉快的获取到数据啦,我们再把callback参数去掉,就是实打实的JSON数据了,连清洗数据的活都省了。
除此之外,还有一个需要注意的点就是,控制访问频度,不管你是单机爬着玩也好,或者是工作大范围爬用代理池也好,频度是一个很基础的防爬机制。
具体的虫巢涉及的代码呢,我就不一一列出来了,这里列一下开源出来的代码,涉及到爬虫的部分,做个备注,有兴趣的可以去我github上clone下来,然后按下面的路径去分析分析逻辑,克隆完了记得给个star哟。
mite8-com开源项目涉及到爬虫的部分:
1 京东雾霾相关的爬虫逻辑:package com.mite8.Insight.jd_wumai;
2 电影《长城》相关的爬虫逻辑:package com.mite8.Insight.movie_great_wall;
3 政务舆情相关的爬虫逻辑:package com.mite8.jx.gz.dn.service; //service下对应的几个子目录,下面的utils,入口是OptXXX类。
防爬的一些机制,以及对应的破解之道
在这里再说一些玩爬虫时,会遇到的一些常见的防爬手段,以及对应的破解之道。
由于俺不是专业的爬虫,所以这部分这么完善的东西显然不是出自我之手,是我团队里爬虫大神在内部技术分享时总结的,俺只是个搬运工。
第一种,伪装成合法的浏览器
在一般情况下,我们会对请求头进行伪装,最重点的key就是user-agent,这部分信息就是浏览器的内核信息。
由于很多公司,甚至是大楼都是用同一个对外IP,所以单纯的使用频度进行防爬封锁,这种情况很容易造成误杀,这也是目标网站不愿意看到的情况。
但是这种情况下,一般不同的电脑其浏览器是不同的,包括内核版本等等,防爬时会分析这个user-agent是不是一样的,或者说非法的字符。
因为很多爬虫框架,或者进程方位URL时会有默认的标志,通过分析这个频度可以明显知道是不是机器在访问页面。
所以,我们通常会获取一批正常的user-agent做随机封装,去获取数据,这种措施会导致上面说的那种防爬机制时效。
第二种,IP频度封锁
在一个IP过于频繁的访问页面时,网站根据一定的判定策略,会判断这个IP是非法的机器,进行IP封锁,导致这个IP无法访问目标页面。
这个时候,我们可以控制访问频度避免被封,但很多时候我们爬取的量很大,控制频度很难完成任务,那么我们就需要使用代理池来做了。
通过代理池的IP,进行IP伪装,这样就破解了频度的控制。
通常代理池分免费与收费,一般免费的代理池都是被人用烂了的,里头的IP都是在各大主流网站的黑名单里。
最后,至于说每个网站的频度是什么样子的,以及控制力度(禁封几分钟,或者是一天等等),就需要自己多测试尝试了。
第三种,用户验证机制
用户验证,这是个很常见的东西,很多页面只有用户登录之后可以访问。
一般通常的做法都是cookie验证,所以,关键是我们如何获取这个cookie。
一次性爬取比较容易,直接把cookie帖进去,做访问即可,但是遇到自动化的时候,我们就需要研究用户登录的过程了,使用POST做表单提交,获取cookie,后面的流程就通啦。
第四种,验证码
很多操作是需要验证码才能下一步操作的,这个时候除了破解验证码无法可破。
不错对于简单的验证码,或者说自己技术犀利的话,写个图像识别的东东,做图像识别,识别验证码也行,但是,目前验证码设计的都很变态,详情参考12306,所以这个方法打折的厉害。
还有一种手段,购买付费的打码平台服务,直接完破之,就是费钱而已。
第五种,动态页面
所谓动态页面,即很多时候数据是通过js动态加载出来的,或者JS加密的,这个时候,直接访问是拿不到数据。
也有破解之道,使用JS引擎做JS解析,目前不管是Python的还是Java的,有不少这种引擎可以供调用。
最后一种方法,使用浏览器内核去访问这个链接,就跟真正的浏览器访问页面没有什么差别啦,Java中经典的selenium就是其中一种。
据闻,技术高端点的公司还有更变态的,通过机器学习来学习真实用户的访问轨迹,通过算法来判断这种访问轨迹是否是机器造成的,然后再做判断是否做禁封。
好吧,玩高深的爬虫,其实就一部防爬与反爬的斗争史,其乐无穷。
下一篇,接着话题,我们讲讲述云平台搭建,服务器部署,环境配置相关的东西: 《如何打造类似数据虫巢官网系列教程之三:服务器》 。
最后,再贴一遍,数据虫巢官网(www.mite8.com)的开源代码地址(可以随意fork、star 哈哈): github.com/blogchong/mite8-com。
相关阅读:
《如何打造类似数据虫巢官网系列教程之一:介绍已经准备工作》
广告Time:
要不要一起探讨大数据的相关的话题,是不是想要跨界大数据,进一步了解、讨论mite-com的开源代码,欢迎加入 “数据虫巢读者私密群” ,=>>戳此进入。
正文到此结束
- 本文标签: 长城 配置 初学者 key src Action java 自动化 tar sql CTO json 开源 免费 目录 db 京东 代码 实例 总结 招聘 云 源码 js 网站 GitHub Select 锁 文章 mysql 测试 互联网 大数据 遍历 参数 python 服务器 https 进程 开源项目 解析 快的 博客 id 站点 git 广告 数据 jsoup 12306 http IO web ip 雾霾 UI HTML list core Service ssh maven
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

