使用 VirtualBox 和 iptables 模拟 JGroups 网络分区
做分布式系统的人都知道大名鼎鼎的 CAP 定理,这个定理仿佛一个巨大的枷锁,套在了每一个分布式系统的开发者身上。前些日子我也实现了一个 AP 的分布式系统,也就是说发生网络分区(P)的时候,系统会自动分裂成两部分,各自独立工作。
为了验证系统在网络分区时的行为是否符合预期,我需要做个故障模拟,在本地搭建一个 Linux 集群,然后用 iptables 丢弃指定来源的包人工制造出网络分区的效果。
从阿里云的 开源镜像站点 下载最新的 ubuntu server 镜像后,在 VirtualBox 中装机。为了让虚拟机能访问互联网,同时也能互相访问,我们需要给虚拟机配置两个网卡,NAT 用于走宿主机访问外网,Host-only 用于互相访问。
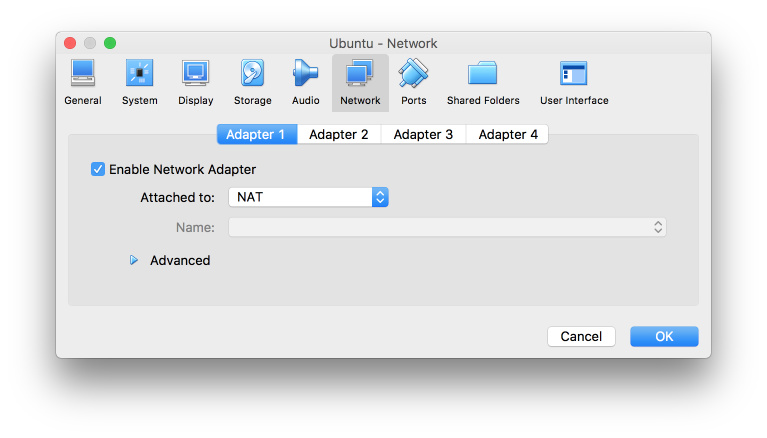
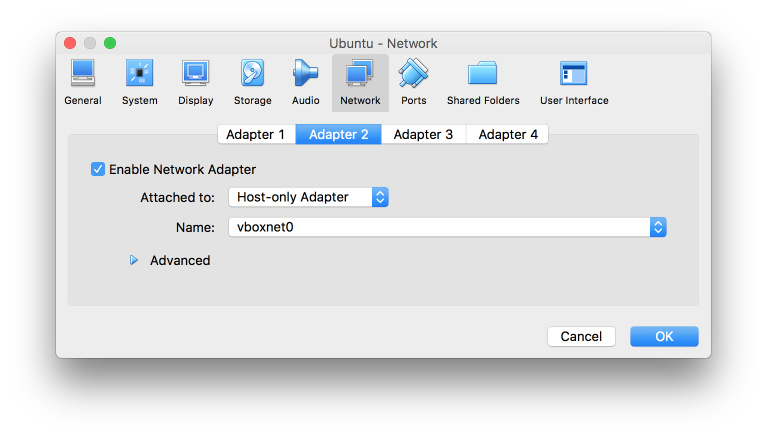
网卡搞定之后,还要在 /etc/network/interfaces 中给网卡做配置。
auto enp0s8 iface enp0s8 inet dhcp
然后就是安装 openssh-server 之类的基础软件。接下来以上面这个配置好的虚拟机为模板,克隆出三个虚拟机,然后分别启动这三个新创建的虚拟机,部署上我的 JGroups 验证程序,我们就得到了一个由三个 Linux 节点组成的互相能访问的集群。

如果想要模拟一个脑裂,比如把 A 节点变成孤岛,那么我们可以在 A 节点上配置 iptables 丢弃来自 B 和 C 的所有包。
pssh -H root@192.168.56.106 -i "iptables -A INPUT -s 192.168.56.107 -j DROP" pssh -H root@192.168.56.106 -i "iptables -A INPUT -s 192.168.56.108 -j DROP"
执行完上面的 DROP 之后,经过一个可配置的心跳周期和超时,集群 {A, B, C} 被正确地分裂成了 {A} 和 {B, C} 两个小集群,稳定运行一段时间后,恢复网络,经过一个可配置的脑裂恢复探测周期,两个集群又合并成了一个完整的集群。
其实对于这种完全脑裂的场景,现在的各种分布式算法以及他们的靠谱实现,都能够应对自如得到符合预期的结果了,对于系统设计者来说已经不是什么需要绞尽脑汁的难题,直接把这些实现拿来当作系统构件和别的代码组装在一起就可以。
真正让开发者头疼的是部分脑裂的问题,也就是说网络分区没分彻底,没有出现孤岛,在 {A, B, C} 这三个机器之间,有且仅有一对主机网络不通。许久之前和一个大神同事讨论类似问题的时候,他跟我说的意思大概是,我们设计系统的时候一般只要考虑完全脑裂的情况,部分脑裂的问题目前业界大家都默认不考虑。
pssh -H root@192.168.56.106 -i "iptables -A INPUT -s 192.168.56.107 -j DROP"
上面这个命令制造了仅有 A 和 B 之间存在网络故障的场景,这个就复杂得多了,需要结合 JGroups 的实现细节一起分析。
如果 JGroups 的 协调者 角色在 C 上,也就是集群视图是 {C, A, B} 或者 {C, B, A} ,那么 A 和 B 之间网络故障不会造成集群分裂,因为 A 和 B 互相认为对面挂了,会分别广播一个对面挂了的 SUSPECT 报文,协调者 C 收到 SUSPECT 之后会 double check 一下,发现 A 是好的 B 也是好的,然后就把 A 和 B 互相干架这个事情压下去了,表面一片祥和。
如果协调者在 A 或者在 B,复杂的状况就来了。只看协调者是 A 的情况,协调者是 B 的情况是对称的。
如果 A 先发现 B 挂了,A 会先广播出 SUSPECT B,然后 A 收到自己发出的 SUSPECT,然后再来一个 double check,肯定还是挂的,然后 A 广播一个新的 View {A, C} ,试图把 B 踢出集群;但是差不多在同一时间,B 也会发现 A 挂了,B 也会广播 SUSPECT A,在集群视图 {A, B, C} 下,如果集群里有关于A 挂的 SUSPECT 报文在广播,B 就会承担起对 A 做 double check 的职责,因为 B 是协调者的第一顺位继承人。这时候 B 肯定认为 A 是挂的,就会广播一个新的 View {B, C} ,试图把 A 踢出集群。那么这时候就是看谁的报文先被 C 处理了,谁先谁后都有可能的,可能 A 和 C 都持有 {A, C} ,B 持有 {B, C} ,也可能 B 和 C 都持有 {B, C} ,A 持有 {A, C} ,甚至有可能在 C 上,先是和 A 一起,过一会发现 B 其实是好的,又把 A 踢了和 B 一起。
但是无论如何,当网络恢复之后,整个集群又会聚在一起,但是协调者是谁就难说了。上面这种情况还是能继续工作的,因为无论是 {A, C} 还是 {B, C} ,两个小集群里的节点和小集群里的协调者都是能通信的,能通信就能协作,就有无限可能。
如果集群视图是 {A, C, B} 会发生什么呢?A 会广播 View {A, C} ,B 会广播 SUSPECT A,但是由于 B 和 C 都不是协调者或者协调者的继承人,B 所有的大声疾呼都如同泥牛入海,B 只能不停地持有 View {A, B, C} 然后在每个心跳检查周期契而不舍地广播 SUSPECT A,但是只要 C 不成为协调者,B 的 SUSPECT 是没人理会的。最后的稳定局面是 A 和 C 都持有 {A, C} ,B 持有 {A, B, C} 。
如果真的发生上面这种极端的部分脑裂情况,也许真的是无法让程序自愈了,B 依旧认为 A 是协调者,但是 B 已经无法和 A 通信了,也许只能在 B 连续发出多个 SUSPECT A 却没有回应之后让系统自杀或者降级,等待人工介入,比如换一台没有网络故障的机器重新拉起一个进程什么的。
部分脑裂的处理真是太麻烦了~
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

