python实战-Adaboost
AdaBoost
优点:泛化错误率低,易编码,可以应用在大部分分类器上,无参数调整。
缺点:对离群点敏感。
适用数据类型:数值型和标称型数据。
1.基于单层决策树构建弱分类器
单层决策树(decision stump)是一种简单的决策树,仅基于单个特征做决策。由于这棵树实际上只有一次分裂过程,因此实际上就是一个树桩。
单层决策树生成函数:
stumpClassify()函数通过阀值比较对数据进行分类。所有在阀值一边的数据会分到类别-1,而在另一边的数据分到类别1。该函数通过数组过滤来实现。
def stumpClassify(dataMatrix, dimen, threshVal, threshIneq):
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
buildStup()函数将会遍历stumpClassify()函数的所有可能输入值,并找到数据集上最佳的单层决策树。这里的”最佳”是基于数据的权重向量D来定义的。伪代码如下:
将最小错误率minError设为INF
对数据集中的每一个特征(第一层循环):
对每个步长(第二层循环):
对每个不等号(第三层循环):
建立一颗单层决策树并利用加权数据集测试
如果错误率低于minError,则将当前单层角色树设为最佳单层决策树
返回最佳单层决策树
coding:
def buildStump(dataArr, classLabels, D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m, n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClassEst = mat(zeros((m,1)))
minError = inf
for i in range(n):
rangeMin = dataMatrix[:,i].min()
rangeMax = dataMatrix[:,i].max()
stepSize = (rangeMax - rangeMin) / numSteps
for j in range(-1, int(numSteps) + 1):
for inequal in ['lt', 'gt']:
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix, i, threshVal,inequal)
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T * errArr
if weightedError < minError:
minError = weightedError
bestClassEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClassEst
基于单层决策树的AdaBoost训练
伪代码如下:
利用buildStump()函数找到最佳的单层决策树 将最佳单层决策树加入到单层决策树数组 计算alpha 计算新的权值向量D 更新累计类别估计值 如果错误率等于0.0则推出循环
coding:
def adaBoostTrainDS(dataArr, classLabels, numIt = 40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m)
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump, error, classEst = buildStump(dataArr, classLabels, D)
print "D", D.T
alpha = float(0.5 * log((1.0 - error)/max(error,1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
print "ClassEst: ", classEst.T
expon = multiply(-1 * alpha * mat(classLabels).T, classEst)
D = multiply(D, exp(expon))
D = D / D.sum()
aggClassEst += alpha * classEst
print "aggClassEst: ", aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum() / m
print "total error: ", errorRate, "/n"
if errorRate == 0.0: break
return weakClassArr, aggClassEst
AdaBoost算法的输入参数包括数据集、类别标签以及迭代次数numIt,其中numIt是整个算法中唯一需要用户指定的参数,表明了函数的最大循环次数。
分类性能度量指标
混淆矩阵:

在这个二类问题中,如果把一个正例类判定为正例,那么就可以认为产生了一个真正例(TmePositive, TP ,也称真阳);如果对一个反例正确地判为反例,则认为产生了一个反例(TrueNegative, TN ,也称真阴)。相应地,另外两种情况分别称为伪反例(FalseNegative,FN ,也称假阴)和伪正例(FalsePositive, FP ,也称假阳).
正确率(Precision)=TP/(TP + FP) ,给出的是预测为正例的样本中的真正正例的比例。
召回率(Recall)=TP/(TP+FN),给出的是预测为正例的真实正例占所有真实正例的比例。
我们可以很容易构造一个高正确率或高召回率的分类器,但是很难同时保证两者成立。如果将任何样本都判为正例,那么召回率达到百分之百而此时正确率很低。构建一个同时使正确率和召回率最大的分类器是具有挑战性的。
另一个用于度量分类中的非均衡性的工具是ROC 曲线(R O C curve ),ROC 代表接收者操作特征(receiver operating characteristic)
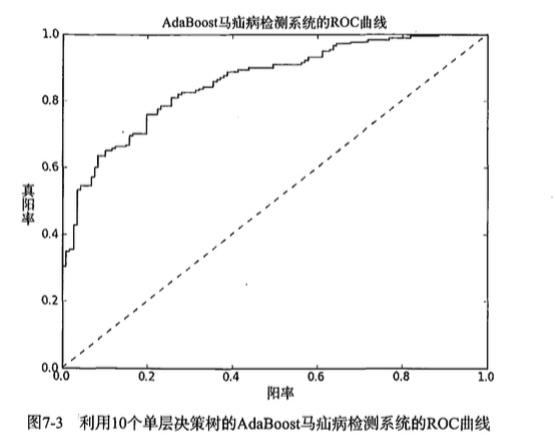
在上图的ROC曲线中,给出了两条线,一条虚线一条实线。图中的横轴是伪正例的比例(假阳率=FP/(FP+TN)),而纵轴是真正例的比例(真阳率=FP/(FP+TN))。ROC曲线给出的是当阈值变化时假阳率和真阳率的变化情况。左下角的点所对应的是将所有样例判为反例的情况,而右上角的点对应的则是将所有样例判为正例的情况。虚线给出的是随机猜测的结果曲线。
ROC 曲线不但可以用于比较分类器,还可以基于成本效益(cost-versus-benefit) 分析来做出决策。由于在不同的阈值下,不同的分类器的表现情况可能各不相同,因此以某种方式将它们组合起来或许会更有意义。如果只是简单地观察分类器的错误率,那么我们就难以得到这种更深人的洞察效果了。
在理想的情况下,最佳的分类器应该尽可能地处于左上角,这就意味着分类器在假阳率很低的同时获得了很高的真阳率。例如在垃圾邮件的过滤中,这就相当于过滤了所有的垃圾邮件,但没有将任何合法邮件误识为垃圾邮件而放入垃圾邮件的文件夹中。
对不同的ROC 曲线进行比较的一个指标是曲线下的面积(AreaUnsertheCurve, A U C )。AUC 给出的是分类器的平均性能值,当然它并不能完全代替对整条曲线的观察。一个完美分类器的AUC 为 1.0 ,而随机猜测的AUC则为0.5。
完整代码地址: https://github.com/JLUNeverMore/adaboost
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

