一个执行计划异常变更的案例 - 正传
之前的几篇文章:
《一个执行计划异常变更的案例 - 前传》
《一个执行计划异常变更的案例 - 外传之绑定变量窥探》
《一个执行计划异常变更的案例 - 外传之查看绑定变量值的几种方法》
《一个执行计划异常变更的案例 - 外传之rolling invalidation》
《一个执行计划异常变更的案例 - 外传之聚簇因子(Clustering Factor)》
《一个执行计划异常变更的案例 - 外传之查询执行计划的几种方法》
《一个执行计划异常变更的案例 - 外传之AWR》
《一个执行计划异常变更的案例 - 外传之ASH》
《一个执行计划异常变更的案例 - 外传之SQL AWR》
《一个执行计划异常变更的案例 - 外传之直方图》
《一个执行计划异常变更的案例 - 外传之SQL Profile(上)》
《一个执行计划异常变更的案例 - 外传之SQL Profile(下)》
从这个系列第一篇开始,一共写了12篇小文,其中涉及的知识点都是这案例实际使用的,一路写来,也让自己对这些知识做了一次梳理,有了新认识,也要感谢罗大师,以及运行同事的分享。这篇文章会介绍下这个问题是如何定位和处理的,其中涉及的一些具体操作可以参考之前的各篇外传。
简单再来回顾下这个问题,有一个在线交易库,突然出现性能问题,DBA发现有一些delete语句执行时间骤长,消耗大量系统资源,导致应用响应时间变长进而造成应用系统积Q。辅助信息:
(1) 应用已经很久未做过更新上线了。
(2) 据开发人员反馈,从之前的应用日志看,未出现处理时间逐步变长的现象。
(3) 这是一套RAC+DG的环境,11g的版本。
(4) 这次突然出现大量执行时间超长的SQL语句,是一条删除语句,
delete from table where key1=:1 and key2=:2 and ...(省略此案例不会用到的其他条件)
应用正常的处理逻辑中都会使用这条语句,因此并发较高,使用了绑定变量,key1和key2字段不是主键,但有索引,存在直方图。
出现性能问题的SQL消耗信息和执行计划如下(生成方式可参见《一个执行计划异常变更的案例 -
外传之查询执行计划的几种方法》、《一个执行计划异常变更的案例 - 外传之AWR》、《一个执行计划异常变更的案例 -
外传之ASH》和《一个执行计划异常变更的案例 - 外传之SQL AWR》),
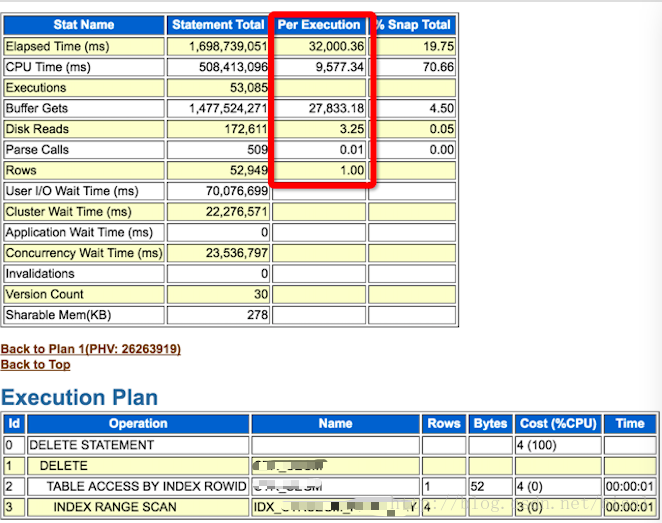
假设使用的是key1对应的索引进行索引范围扫描,平均每次执行需要32秒,消耗两万七千多次逻辑读。
查询历史执行计划,发现还有一个执行计划,
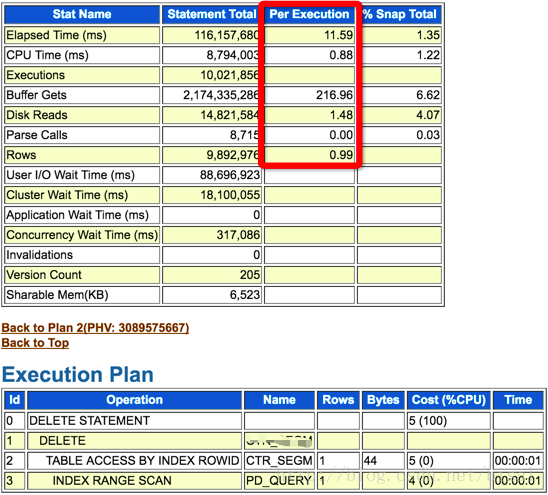
假设使用的是key2对应的索引进行索引范围扫描,平均每次执行之需要11秒,消耗216次逻辑读。
上面第一个执行计划成本值是4,第二个执行计划成本值是5,因此在CBO模式下,Oracle会选择这个成本值是4的执行计划,然而通过查询dba_tab_histograms视图(《一个执行计划异常变更的案例
- 外传之直方图》),发现key1值是0的记录数占据了绝大比重,超过一半,约1500万,
ENDPOINT_VALUE ENDPOINT_NUMBER
-------------- ---------------
0 149
16942622 150
... ...
2180209419 253
2180643328 254
说明这字段数据出现严重倾斜,若查询条件是key1=0,则需要扫描1500万的记录,key2字段值分布不存在倾斜,查询一些历史执行SQL的记录(参见《一个执行计划异常变更的案例
- 外传之查看绑定变量值的几种方法》),发现确实key1值为0的语句是很多的,并发性较高,因此会消耗大量的系统资源,这是导致问题的直接原因。
根本原因又是什么呢?为什么消耗资源较多的执行计划会被Oracle选择?11g下默认的优化器模式是CBO,他会计算这条SQL所有可能的执行计划对应的成本值,选择成本值最低的执行计划。
从10053的trace中可以看出,这条SQL有4个索引可用,对应有索引树层级、聚簇因子(《一个执行计划异常变更的案例 - 外传之聚簇因子(Clustering Factor)》)等信息,
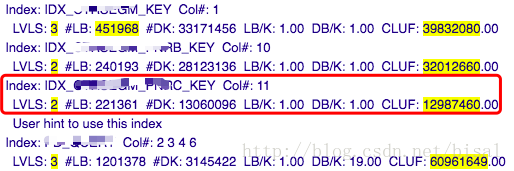
计算后第三个索引成本最低,其就是key1列对应的索引。优化器选择一个成本最低的执行计划,无可厚非。
但是,这库选择了禁止绑定变量窥探特性(更谈不上ACS,请参见《一个执行计划异常变更的案例 -
外传之绑定变量窥探》),因此当SQL带着绑定变量参数等待执行的时候,每次是无法知道具体值是什么,所以会选择默认的selectivity计算方式,千篇一律。又由于key1数据值分布严重倾斜,且并发性较高的SQL绑定变量值就是倾斜值0,因此才产生这个问题。
另外,查询dba_hist_active_sess_history视图发现Oracle选择这一个异常的执行计划时间是20161218 115136,
select to_char(min(sample_time) ,'YYYYMMDD HH24MISS')
from dba_hist_active_sess_history
where snap_id = 26273 and sql_id = 'g1xv7657qv3bt' and SQL_PLAN_HASH_VALUE = '26263919'
查询dba_indexes和dba_tables发现当日20161218 070813左右统计信息均发生了改变,
select blevel,index_name,NUM_ROWS,DISTINCT_KEYS,to_char(last_analyzed,'YYYYMMDD HH24MISS')
from dba_indexes
where table_name = 'XXX' select num_rows,to_char(last_analyzed,'YYYYMMDD HH24MISS') from dba_tables where table_name = 'XXX';
两者相差时间大约17000秒,根据《一个执行计划异常变更的案例 - 外传之rolling invalidation》可知是Oracle一个特性,为了避免对共享池的风暴冲击,Oracle随机选择了20161218 115136这个时间点重新解析SQL,由于统计信息变化,导致成本计算后,差的执行计划成本值变为了4,成为成本值最低的执行计划,高并发执行后,系统开始出现资源紧张。
根据上面的信息,第二种执行计划(成本值为5)消耗的资源要远小于第一种执行计划(成本值为4)消耗的资源,为了快速解决问题,针对这种不能立即修改应用代码,但又需要调整执行计划的场景,就可以选择SQL
Profile技术,让SQL选择成本值为5,使用key2索引的执行计划,具体操作可参见《一个执行计划异常变更的案例 - 外传之SQL
Profile(上)》和《一个执行计划异常变更的案例 - 外传之SQL Profile(下)》。
作为这问题的后续改进方法,首先需要业务上确认key1字段值为0的倾斜情况是否正常,若不正常则规避之,就不会有这个问题,若就是正常情况,则可以考虑应用判断此次执行的key1是否为0,若为0,则不使用绑定变量,直接用key1=0为条件,让Oracle根据直方图信息以及表中其他查询条件的索引,来选择正确的执行计划,若不为0,则仍旧可用key1=:1的绑定变量,即使未开启绑定变量窥探,因为key1除0值外其他值可选择度平均且较好,因此仍可以选择正确的执行计划。
总结:
性能优化是一项技术活,因为往往需要很扎实的理论基础,还有成熟的问题排查思路和解决方案,外加一些运气,实践非常重要,毕竟“纸上得来终觉浅,绝知此事要躬行”,我作为一名初学者,还处在夯实理论基础的道路上,还要需要更多的学习和实践,才能追赶大师的步伐,但至少要保证方向正确,即使路程艰辛,不放弃,会有所成,朋友们一起努力!
欢迎关注我的个人微信公众号:bisal的个人杂货铺

正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

