Oracle中的PGA监控报警分析(r11笔记第97天)
最近接到一个数据库报警,让我颇有些意外,这是一个PGA相关的报警。听起来感觉是应用端的资源调用出了问题。
报警内容大体如下:
报警内容: PGA Alarm on alltest
------------------------------------
报警级别: PROBLEM
------------------------------------
监控项目: PGA:6118.6 这是一个12cR1的环境,是一套测试环境,确切的说是多套环境整合后的一套大的测试环境,里面含有近8个PDB,也就是之前的多个测试环境整合而来。
所以我就简单进行了排查,首先这个报警是怎么来的,是在Orabbix配置的监控项。
在Zabbix中查看,可以看到这个报警的相关配置。
({Template_Oracle_OLTP:pga.last(0)}*100/{Template_Oracle_OLTP:pga_aggregate_target.last(0)})>95 也就意味着PGA的使用率达到了95%以上的时候就触发报警,这里涉及两个监控项pga和pga_aggregate_target。
相关的SQL如下,监控项的SQL在Orabbix中是按照 【监控项】.Query的格式展现的。
pga_aggregate_target.Query=select
to_char(decode( unit,'bytes', value/1024/1024, value),'999999999.9')
value from V$PGASTAT where name in 'aggregate PGA target parameter'
pga.Query=select
to_char(decode( unit,'bytes', value/1024/1024, value),'999999999.9')
c 对于这个问题,查看数据库参数,目前的pga设置是6GSQL> show parameter pga
NAME TYPE VALUE
----------------------- ----------- --------
pga_aggregate_limit big integer 12880M
pga_aggregate_target big integer 6440M 但是看起来好像有些不大对劲,还有一个生疏的参数pga_aggregate_limit,这个参数是干什么的,其实这是12c中引入的一个参数,对于pga_aggregate_target的补充。怎么理解容易一些呢,pga_aggregate_target是一个基线值,比如设置为6G,如果PGA使用超过了6G还是很难做到管控,就可能导致一些hang,无响应的问题,这个问题在12c中是考虑引进了参数pga_aggregate_limit来完善的,也就是这个参数的值就是一个最终的大小,绝对不能超过。这个参数输出中,目前的limit值默认给设置为了12G,而原本设置的target值为6G.
目前的报警是PGA使用超过了阈值,那什么样的应用会导致如此的PGA使用情况呢,这个让我有些疑惑。一般来说,单个进程的PGA占用量其实不大,多点也就几十MB而已。当然为了先尽快修复这个问题,我把PGA target的值改为了7G.
然后我们可以直接这样尝试定位一下问题,看看占用PGA最多的进程是哪个,依次来排除。
SQL> select max(pga_max_mem/1024/1024) from v$process;
MAX(PGA_MAX_MEM/1024/1024)
--------------------------
7989.28072 结果看到最大进程怎么消耗如此之高,尽管是一个峰值而已。
SQL> select * from
(select
spid,pga_max_mem/1024/1024,pga_alloc_mem/1024/1024,pga_used_mem/1024/1024,program
from v$process order by pga_used_mem desc) where rownum<10;
输出的数据如下:
SPID PGA_MAX_MEM PGA_ALLOC_MEM PGA_USED_MEM PROGRAM
--------- --------------------- ----------------------- -----------
941 7989. 7989.4 5061.54467 oracle@teststd.test.com (IMCO)
925 132 39.851 37.1080208 oracle@teststd.test.com (ARC0)
931 116 38.788 37.0642586 oracle@teststd.test.com (ARC3)
937 36.96 33.093 31.872448 oracle@teststd.test.com (W000)
9201 37.28 31.968 31.7101784 oracle@teststd.test.com (W00C)
1491 32.53 32.468 31.6490288 oracle@teststd.test.com (W001)
1327 33.90 31.968 31.6361275 oracle@teststd.test.com (W002)
8181 32.53 31.843 31.5896568 oracle@teststd.test.com (W009)
3510 32.78 32.093 31.5785789 oracle@teststd.test.com (W005)
这一下子让我有些懵,因为最大的进程竟然是IMCO,这是in memory选件的后台进程。
[oracle@teststd ~]$ ps -ef|grep 941
oracle 941 1 0 2016 ? 07:45:21 ora_imco_testdb这样一来问题就有些诡异了。
SQL> show sga
Total System Global Area 2.0267E+10 bytes
Fixed Size 3721272 bytes
Variable Size 1.1409E+10 bytes
Database Buffers 6643777536 bytes
Redo Buffers 63385600 bytes
In-Memory Area 2147483648 bytes通过SGA的输出可以看出,In-Memory占用了大概2G的内存空间。
而且这个参数比较让人纠结的就是无法动态修改,在实例初始化阶段才可以修改。
SQL> alter system set inmemory_size=1G;
alter system set inmemory_size=1G
*
ERROR at line 1:
ORA-02097: parameter cannot be modified because specified value is invalid
ORA-02095: specified initialization parameter cannot be modified这样一个问题,难道是因为imco的特殊性导致了PGA的占用量大步提升,也被归纳算入了。实际上in memory自启用后就没有正式启用,没有任何表的数据放在IMO里,所以也排除了IMO的一些异常情况。还有一个验证的方式就是通过Data Guard来对比补充,结果查看备库的imco进程情况,压根诶呦发现什么问题。还有一个思路那就是对比其他的12c环境,是否也存在类似的问题,还有一套近期搭建的12cR2的环境,也启用了IMO,但是IMCO进程的PGA占用量很低。这也符合了一个常规的想法,那么这个问题是怎么造成的呢,我的一个直观感受就是一个bug.
这个想法在MOS上得到了一个基本的印证,可以参考
IMCO Background Process Keeps Growing in Memory Usage over Time (Doc ID 2106806.1) 这里有一个问题需要确认,那就是IMCO的进程占用情况是逐步的增长还是一开始就很高。
这一点上完全可以通过Zabbix的监控图得到。
查看近一年的PGA变化曲线图,可发现是在逐步增长。
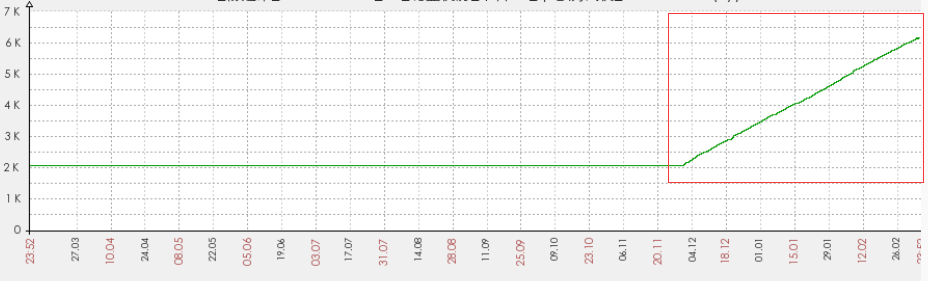
所以和MOS里面的那个bug吻合度很高。
按照官方的解释,有3个途径可以改进这个问题。
1. Upgrade to 12.2, when available.
2. Apply the 12.1.0.2.10DBBP patch (or if you apply PSUs instead of DBBPs, apply the 12.1.0.2.160119DBPSU).
3. Apply interim Patch 19159120 for your RDBMS version and OS.目前来看,步骤2已经满足,只有重启一下,或者升级到12c了。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

