MYSQL sync_relay_log对I/O thread的影响分析
搭建好的一套从库,发现延迟很高,一直追不上,从库的bin_log没开,flush_log_at_trx_commit设置为0,
简化的状态如下:
mysql> show slave status /G
*************************** 1. row ***************************
Slave_IO_State: Queueing master event to the relay log
Master_Log_File: mysql-bin.000533
Read_Master_Log_Pos: 101151159
Relay_Log_File: relaylog.000012
Relay_Log_Pos: 897176
Relay_Master_Log_File: mysql-bin.000533
Exec_Master_Log_Pos: 99357144
Seconds_Behind_Master: 11313
发现Master_Log_File,Read_Master_Log_Pos一直进展比较缓慢,一般来说内网的瓶颈不会在网络,那么只可能在I/O
查看服务器I/O情况如下:

发现MYSQL线程LWP号为44706 的线程I/O非常高,但是写入只有600来K,明显这种情况是不正常的,一般来说LINUX
有KERNEL BUFFER/CACHE,write只是写入到KERNEL BUFFER/CACHE就好了,例外就是以dirctor写入方式,这种方式
依赖的是用户态缓存,还有就是写入调用了大量的fsync之类的同步kernel cache/buffer到磁盘的系统调用。
然后查看这个LWP号是否为I/O thread如下,因为5.7可以非常轻松的找到MYSQL conn_id和系统LWP之间的关系如下:

确实发现这个大量I/O的确实是MYSQL从库的I/O thread,那么接下来的就是进行strace看看到底为什么这么慢,strace
片段如下:

我们发现文件描述符fd=50的文件有大量的写入而且频繁的调用fdatasync来同步磁盘,消耗时间非常可观,是MUTEX调用和write
操作的N倍
那么我们就看看文件描述符50到底是什么如下:
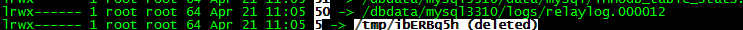
确实是我们的replay log。
那么问题就确定了,就是因为replay log的写入调用了大量的fdatasync造成的I/O THREAD非常慢,那么是哪一个参数呢?
其实参数就是sync_relay_log,这个参数用来保证relay log的安全,官方文档有如下的图:
GTID|sync_relay_log|MASTER_AUTO_POSITION|relay_log_recovery|relay_log_info_repository|Crash type|Recovery guaranteed |Relay log impact
OFF 1 Any 1 TABLE Any Yes Lost
OFF >1 Any 1 TABLE Server Yes Lost
OFF >1 Any 1 Any OS No Lost
OFF 1 Any 0 TABLE Server Yes Remains
OFF 1 Any 0 TABLE OS No Remains
ON Any ON Any Any Any Yes Lost
ON 1 OFF 0 TABLE Server Yes Remains
ON 1 OFF 0 Any OS No Remains
我们可以看到如果不设置sync_relay_log那么有可能造成relay log丢失的风险,其实上面的分析已经看到就是调用fdatasync来完成这个功能,但是
这样的代价基本是不可接受的。官方文档有如下说明:
It is important to note the impact of sync_relay_log=1, which requires a write of to the relay log
per transaction. Although this setting is the most resilient to an unexpected halt, with at most one
unwritten transaction being lost, it also has the potential to greatly increase the load on storage. Without
sync_relay_log=1, the effect of an unexpected halt depends on how the relay log is handled by the
operating system.
A value of 1 is the safest choice because in the event of a crash you lose at most one event from the
relay log. However, it is also the slowest choice (unless the disk has a battery-backed cache, which
makes synchronization very fast).
每次事物都会调用fdatasync,代价太高。所以没办法修改了sync_relay_log的设置,默认值是10000,也就是10000个事物进行一次
fdatasync。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

