MySQL案例-初步恢复: alter引起的从库无限Crash
-------------------------------------------------------------------------------------------------正文---------------------------------------------------------------------------------------------------------------
场景 :
Crash发生时的数据库版本: MySQL-5.7.17, 从库在同步到某一个alter语句的时候发生了Crash, 并且在重启进行Crash Recovery的时候不断触发同一个错误导致Crash;
结论 :
只读业务临时切换到另外一个只读实例, 且重新做一个从库给业务用;
重点! :
解决问题的办法肯定不是把库恢复起来, 而是重新做一个, 所以本文记录的操作主要目的是做实践和尝试, 生产环境上请谨慎操作;
场景:
生产环境的场景, 屏蔽一些敏感信息;
首先截取Error log中比较的重要信息:
截取出来的是第一次遇到问题, mysql重启进行Crash Recovery的日志;
可以从红色标记的地方看到, 其实第一次重启的时候, crash recovery就已经完成了, 而且mysqld进程也已经ready for connections,
但是马上就触发了同样的问题, 导致mysql又发生了Crash, 而且mysqld_safe也跟着"消失"了;
在之后的重启尝试中, 每次在Crash之前, 都有这么一行信息:
结合堆栈信息中显示出来的fsp0fsp.cc line 2108, 在源代码中找到这一行(红色标注),
结合日志中的cleanup阶段的log和阿里的mysql内核月报中对innodb的分析可以知道, alter语句在drop 索引的时候会调用到这个方法的, 用来回收数据页/返还表空间;
所以问题基本确定就是alter语句引起了这次mysql的Crash, 且每次重启的时候都在同样一个位置报错说明这个alter ... drop index的数据页并没有完成cleanup, 每次重启的时候都在尝试, 然后触发Crash;
由于触发Crash的阶段始终都处于Crash Recovery之后, 所以推断mysql可能是在处于rollback阶段, 所以设置了innodb_force_recovery = 3,
发现跳过rollback以后数据库正常的起来了~/(≧▽≦)/~
那么事情就好办了, innodb_force_recovery = 3的时候是可以对表进行操作的, 比如说.....drop.....
在第一次Crash的日志里面, 可以看到tb0和tb1的alter可能都有问题, 因为alter产生的中间结果表还在data目录下;
所以为了不再让rollback触发alter语句cleanup的问题, 最简单的办法就是......drop掉这两个表~/(≧▽≦)/~
_(:з」∠)_ 当然不能直接drop...先dump出来.....
不过实际操作之前, 先确认一下当前数据库的状态:
从库复现主库的事务, 停留在这个阶段: 8fc6463a-f9b1-11e6-b218-ce0e1b052154:1-2241902370:2241902372-2241902383;
通过查看relaylog, 找到遗漏的2241902371事务, 正好是alter语句

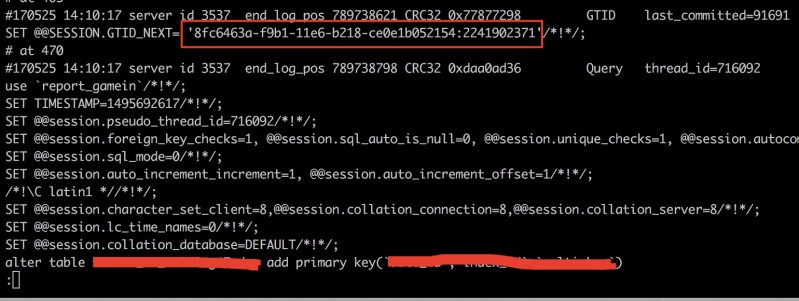
这里面有几个比较重要的信息, 除了GTID和SQL以外, 还有一个: last_committed=91691
再看看2241902383之后的事务是什么

那么就基本确认了, 当前的状态是91692的事务组中, 除了2241902371以外全部提交成功, 而下一个事务组91693还没有开始;
再查一下有问题的tb0和tb1, 确认2241902371事务对应的表结构确实是没有主键, 那么说明这个语句确实没有执行, 所以目前的库应该是处于一致的状态的(Crash Recovery成功了是大前提)
我们开始着手让mysql启动起来~
_(:з」∠)_ 先把tb0和tb1都dump出来.....
~/(≧▽≦)/~ 然后drop掉~(如果之后需要重建同步的话, 记得关掉sql_log_bin, 不要把drop语句写到binlog)
(⊙﹏⊙)再去掉配置文件的innodb_force_recovery, 重启mysql.....
done, 数据库正常起来了~
之后就简单了, 重新把这两张表导入到数据库, 再开启同步, 看看同步的状态:

可以看到缺少的2241902371事务已经重新拉取下来了, 而且2241902384和之后的事务也正常的拉取和执行了~
等到同步同步跟上的时候, 就可以验证一下数据是不是真的一致了~
PS: 由于在重启的过程中, MTR和Crash Recovery都成功了, 而且同步状态正常, GTID的事务号也保持了连续, 从个人角度来看, 更加倾向于数据是一致的~
PPS: 这个库能交付给用户继续使用么? 虽然不推荐就这么交付回去, 不过用户说能用, 那就能用~
场景 :
Crash发生时的数据库版本: MySQL-5.7.17, 从库在同步到某一个alter语句的时候发生了Crash, 并且在重启进行Crash Recovery的时候不断触发同一个错误导致Crash;
结论 :
只读业务临时切换到另外一个只读实例, 且重新做一个从库给业务用;
重点! :
解决问题的办法肯定不是把库恢复起来, 而是重新做一个, 所以本文记录的操作主要目的是做实践和尝试, 生产环境上请谨慎操作;
场景:
生产环境的场景, 屏蔽一些敏感信息;
首先截取Error log中比较的重要信息:
点击(此处)折叠或打开
- 2017-05-25 14:10:23 0x7f9b5b927700 InnoDB: Assertion failure in thread 140305232983808 in file fsp0fsp.cc line 2108
- InnoDB: Failing assertion: frag_n_used > 0
- ......
- /usr/sbin/mysqld(_Z14fseg_free_stepPhbP5mtr_t+0x36e)[0x11d073e]
- ......
- /usr/sbin/mysqld(_Z23trx_undo_insert_cleanupP14trx_undo_ptr_tb+0x16c)[0x1100b9c]
- ......
- /usr/sbin/mysqld(_Z19innobase_commit_lowP5trx_t+0x17)[0xf6a0e7]
- /usr/sbin/mysqld(_ZN15Query_log_event14do_apply_eventEPK14Relay_log_infoPKcm+0x68d)[0xdf4c1d]
- /usr/sbin/mysqld(_Z27slave_worker_exec_job_groupP12Slave_workerP14Relay_log_info+0x293)[0xe52353]
- ......
- /usr/sbin/mysqld(handle_slave_worker+0x363)[0xe34f73]
- ......
- Trying to get some variables.
- Some pointers may be invalid and cause the dump to abort.
- Query (xxxxxxxxx): alter table tb1 add primary key(`col1`,`col2`,`col3`)
- Connection ID (thread ID): 129443
- Status: NOT_KILLED
- ......
- 2017-05-25T14:10:24.858719+08:00 0 [Note] InnoDB: Ignoring data file './dbname/tb0.ibd' with space ID 375, since the redo log references ./dbname/tb0.ibd with space ID 280.
- 2017-05-25T14:10:24.860628+08:00 0 [Note] InnoDB: Ignoring data file './dbname/tb1.ibd' with space ID 374, since the redo log references ./dbname/tb1.ibd with space ID 279.
- ......
- 2017-05-25T14:10:44.635655+08:00 0 [Note] InnoDB: Ignoring data file './dbname/#sql-7b4e1_9f3a1.ibd' with space ID 375. Another data file called ./dbname/tb0.ibd exists with the same space ID.
- ......
- 2017-05-25T14:10:39.845947+08:00 0 [Note] InnoDB: Ignoring data file './dbname/#sql-7b4e1_9f3a1.ibd' with space ID 374. Another data file called ./report_gamein/t30741_hs_g47_day.ibd exists with the same space ID.
- ......
- 2017-05-25T14:11:02.972181+08:00 0 [Note] Starting crash recovery...
- 2017-05-25T14:11:02.972227+08:00 0 [Note] Crash recovery finished.
- 2017-05-25T14:11:40.547210+08:00 0 [Note] InnoDB: Rollback of trx with id 3377056858 completed
- 2017-05-25T14:11:40.554385+08:00 0 [Note] InnoDB: Rollback of non-prepared transactions completed
- ......
- 2017-05-25T14:11:03.752024+08:00 0 [Warning] Recovery from master pos 43851595 and file binlog.006933 for channel 'amaster'. Previous relay log pos and relay log file had been set to 43851818, /home/mysql/log/relaylog/relaylog-amaster_3537.020527 respectively.
- ......
- 2017-05-25T14:11:03.817050+08:00 0 [Warning] Recovery from master pos 789680988 and file binlog.027468 for channel 'bmaster'. Previous relay log pos and relay log file had been set to 789681243, /home/mysql/log/relaylog/relaylog-bmaster_3637.020768 respectively.
- ......
- 2017-05-25T14:11:04.353863+08:00 0 [Note] /usr/sbin/mysqld: ready for connections.
- Version: '5.7.17-log' socket: '/home/mysql/data/mysqld.sock' port: 3306 MySQL Community Server (GPL)
- 2017-05-25 14:11:04 0x7f10762de700 InnoDB: Assertion failure in thread 139708678924032 in file fsp0fsp.cc line 2108
InnoDB: Failing assertion: frag_n_used > 0 - ......
截取出来的是第一次遇到问题, mysql重启进行Crash Recovery的日志;
可以从红色标记的地方看到, 其实第一次重启的时候, crash recovery就已经完成了, 而且mysqld进程也已经ready for connections,
但是马上就触发了同样的问题, 导致mysql又发生了Crash, 而且mysqld_safe也跟着"消失"了;
在之后的重启尝试中, 每次在Crash之前, 都有这么一行信息:
点击(此处)折叠或打开
- 2017-05-25T15:25:33.025244+08:00 0 [Note] InnoDB: Cleaning up trx with id 3377057419
结合堆栈信息中显示出来的fsp0fsp.cc line 2108, 在源代码中找到这一行(红色标注),
点击(此处)折叠或打开
- fsp_free_page(
const page_id_t& page_id,
const page_size_t& page_size,
mtr_t* mtr)
- ......
- if (state == XDES_FULL_FRAG) {
- /* The fragment was full: move it to another list */
- flst_remove(header + FSP_FULL_FRAG, descr + XDES_FLST_NODE,
- mtr);
- xdes_set_state(descr, XDES_FREE_FRAG, mtr);
- flst_add_last(header + FSP_FREE_FRAG, descr + XDES_FLST_NODE,
- mtr);
- mlog_write_ulint(header + FSP_FRAG_N_USED,
- frag_n_used + FSP_EXTENT_SIZE - 1,
- MLOG_4BYTES, mtr);
- } else {
- ut_a(frag_n_used > 0);
- mlog_write_ulint(header + FSP_FRAG_N_USED, frag_n_used - 1,
- MLOG_4BYTES, mtr);
- }
结合日志中的cleanup阶段的log和阿里的mysql内核月报中对innodb的分析可以知道, alter语句在drop 索引的时候会调用到这个方法的, 用来回收数据页/返还表空间;
所以问题基本确定就是alter语句引起了这次mysql的Crash, 且每次重启的时候都在同样一个位置报错说明这个alter ... drop index的数据页并没有完成cleanup, 每次重启的时候都在尝试, 然后触发Crash;
由于触发Crash的阶段始终都处于Crash Recovery之后, 所以推断mysql可能是在处于rollback阶段, 所以设置了innodb_force_recovery = 3,
发现跳过rollback以后数据库正常的起来了~/(≧▽≦)/~
那么事情就好办了, innodb_force_recovery = 3的时候是可以对表进行操作的, 比如说.....drop.....
在第一次Crash的日志里面, 可以看到tb0和tb1的alter可能都有问题, 因为alter产生的中间结果表还在data目录下;
所以为了不再让rollback触发alter语句cleanup的问题, 最简单的办法就是......drop掉这两个表~/(≧▽≦)/~
_(:з」∠)_ 当然不能直接drop...先dump出来.....
不过实际操作之前, 先确认一下当前数据库的状态:
从库复现主库的事务, 停留在这个阶段: 8fc6463a-f9b1-11e6-b218-ce0e1b052154:1-2241902370:2241902372-2241902383;
通过查看relaylog, 找到遗漏的2241902371事务, 正好是alter语句
这里面有几个比较重要的信息, 除了GTID和SQL以外, 还有一个: last_committed=91691
再看看2241902383之后的事务是什么
那么就基本确认了, 当前的状态是91692的事务组中, 除了2241902371以外全部提交成功, 而下一个事务组91693还没有开始;
再查一下有问题的tb0和tb1, 确认2241902371事务对应的表结构确实是没有主键, 那么说明这个语句确实没有执行, 所以目前的库应该是处于一致的状态的(Crash Recovery成功了是大前提)
我们开始着手让mysql启动起来~
_(:з」∠)_ 先把tb0和tb1都dump出来.....
~/(≧▽≦)/~ 然后drop掉~(如果之后需要重建同步的话, 记得关掉sql_log_bin, 不要把drop语句写到binlog)
(⊙﹏⊙)再去掉配置文件的innodb_force_recovery, 重启mysql.....
done, 数据库正常起来了~
之后就简单了, 重新把这两张表导入到数据库, 再开启同步, 看看同步的状态:
可以看到缺少的2241902371事务已经重新拉取下来了, 而且2241902384和之后的事务也正常的拉取和执行了~
等到同步同步跟上的时候, 就可以验证一下数据是不是真的一致了~
PS: 由于在重启的过程中, MTR和Crash Recovery都成功了, 而且同步状态正常, GTID的事务号也保持了连续, 从个人角度来看, 更加倾向于数据是一致的~
PPS: 这个库能交付给用户继续使用么? 虽然不推荐就这么交付回去, 不过用户说能用, 那就能用~
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

