三种批量删除PLSQL写法效率的比对
我们有一个重要的旧系统,最近夜维出现了一些问题,夜间执行5小时未完成,为了不影响业务,只能早上高峰期之前,DBA手工kill夜维进程。
这一个夜维程序采用了PLSQL写的存储过程,通过数据库job定时启动执行。存储过程我很少使用,借着这次机会,补习了下,这个存储过程中的逻辑比较简单,依次删除若干张业务表,每张表删除的逻辑相同,为了便于说明,模拟了下删除一张表的逻辑,示例如下,
TBL_CUSS表三个字段,第一个字段是NUMBER类型,第二个字段是VARCHAR2类型,第三个字段是DATE类型,
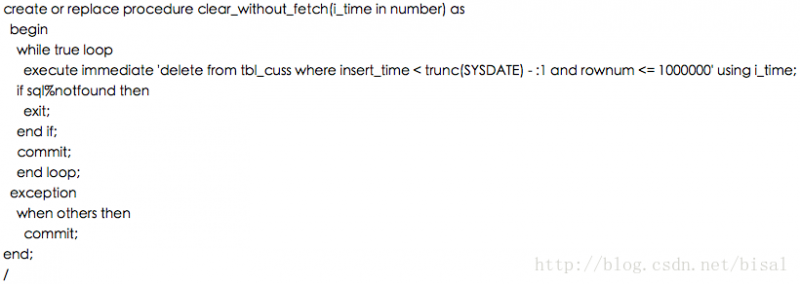
这个存储过程接受一个参数,表示删除几天前的数据,删除DELETE语句按照一个时间字段和这个参数比较得出符合条件的记录集,同时使用rownum限制每次执行DELETE-COMMIT事务的条数,循环执行,直至出现ORA-1403无记录的提示,退出此逻辑。这个存储过程最优的地方,是使用了批量提交,不是执行一次DELETE删除所有记录COMMIT,如果这么执行,可能会占用大量的UNDO回滚段,进而可能出现回滚段空间不足的报错,也可能出现ORA-1555的错误。毕竟UNDO中记录的是SQL语句的逆向,对于DELETE语句,逆向就是INSERT,即会存储删除的整条记录。
可能有朋友一眼就看出这个存储过程的逻辑有一些问题,比如对于这种批量删除,未使用游标,相当于每次要检索tbl_cuss表符合insert_time < trunc(SYSDATE)-:1条件的记录,可每次仅删除其中的rownum限制的条数,如果使用游标,检索只需要一次执行,不考虑是否有索引,执行语句次数的降低,可以带来性能的一定提升。
针对此问题,写了第二个存储过程,

接受删除天数的参数,使用了游标,执行一次SELECT,读取出的则是符合insert_time < trunc(SYSDATE)-:1条件的所有结果集记录的rowid信息,遍历游标的时候使用BULK批量的方式,设置了一次性执行的条数限制MAX_ROW_SIZE,并且删除语句是根据上面游标获取的rowid为条件进行的DELETE,如果各位了解rowid,可以知道他代表了这条记录的物理位置,通过换算可以得出这条记录存储于的文件、块和行上,即可以快速定位这条记录的物理位置,在RBO模式下,他的成本优先级是最优的,高于索引。
继续写了第三个存储过程,

这和第二个存储过程,基本一致,唯一不同就是第二个存储过程中使用了for循环,第三个存储过程则用forall循环。for循环会执行其中的每条SQL语句,forall则会将其中所有SQL批量发送SQL引擎执行。当然可能有其他的写法,比如使用游标,但不使用BULK,按照rowid删除,这种写法执行SQL语句的次数和结果集数据量一致,效率可能还不如原始procedure。
从原理上说,使用BULK比单条语句执行,减少PLSQL和SQL引擎之间的切换频率,也可以减少redo和undo的产生量。针对循环内执行的DELETE,适合于使用集合,放入forall。
这篇文章的实验说明了forall的一些适用场景,
http://blog.csdn.net/renfengjun/article/details/8334733#
delete和insert都可以从forall上面得到巨大的性能提升。但是对于update来说opcode没有相关操作,提升应该不会那么明显。
接下来我们会对这三个存储过程进行一些比对实验,通过一些数据,说明各自的适用场景,首先创建测试数据集,制造了1300万测试数据,
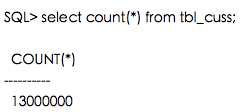
每天50万数据,一共26天,

第一个存储过程名称为clear_without_fetch。
第二个存储过程名称为clear_all_fetch。
第三个存储过程名称为clear_fetch。
实验有以下几类,(以下执行基本采用第二次执行的结果避免第一次刷缓存)
(1) 一次性删除1万条记录,insert_time不是索引,删除两天的数据(即100万),
clear_without_fetch用时01:16.31
clear_all_fetch用时00:40.50
clear_fetch用时00:21.73
clear_fetch胜出,clear_without_fetch最慢,说明TABLE ACCESS FULL下的SQL语句,一次性删除1万条记录,使用游标和BULK效率要高些,使用forall比for效率要高些。
(2) 一次性删除5万条记录,insert_time不是索引,删除两天的数据(即100万),
clear_without_fetch用时00:26.98
clear_all_fetch用时00:39.80
clear_fetch用时00:22.24
clear_fetch胜出,但一次性删除5万条记录,TABLE ACCESS FULL下的SQL语句由于执行次数减小为原来的5倍,效率上有提升,clear_all_fetch基本一致,是因为无论什么方式,其执行SQL语句的次数,和结果集一致,即100万次SQL。
(3) 一次性删除100万条记录,insert_time不是索引,删除两天的数据(即100万),
clear_without_fetch用时00:21.92
clear_all_fetch用时01:22.00
clear_fetch用时00:25.95
clear_without_fetch胜出,TABLE ACCESS FULL下的SQL语句执行一次,clear_fetch虽然仍是批量一次发送SQL,性能上的优势不很明显。
(4) 一次性删除1万条记录,insert_time是索引,删除两天的数据(即100万),
clear_without_fetch用时00:31.01
clear_all_fetch用时01:09.02
clear_fetch用时00:37.39
clear_without_fetch胜出,索引扫描执行效率提升,相比TABLE ACCESS FULL要明显一些。
(5) 一次性删除5万条记录,insert_time是索引,删除两天的数据(即100万),
clear_without_fetch用时00:35.35
clear_all_fetch用时01:03.26
clear_fetch用时00:37.40
clear_without_fetch胜出,clear_all_fetch和clear_fetch基本保持和1万一致。
(6) 一次性删除100万条记录,insert_time是索引,删除两天的数据(即100万),
clear_without_fetch用时00:23.33
clear_all_fetch用时01:27.80
clear_fetch用时00:33.68
clear_without_fetch胜出,相比1万和5万,效率提升一些,我理解主要是SQL执行次数从100次(1万)->20次(5万)->1次(100万)。
上面的实验中,数据接近的未必是绝对,和环境因素(例如机器配置、数据质量等)可能有关,因此大体方向上可以参考,不同次的实验可能会略有不同,但方向应该比较接近,毕竟原理摆着。
如下是上面六个实验,三个存储过程SQL,各自执行的10046的trace,从中可以看出一些端倪,
clear_without_fetch存储过程各场景trace,
(1) 一次性删除1万条记录,insert_time不是索引,删除两天的数据(即100万),
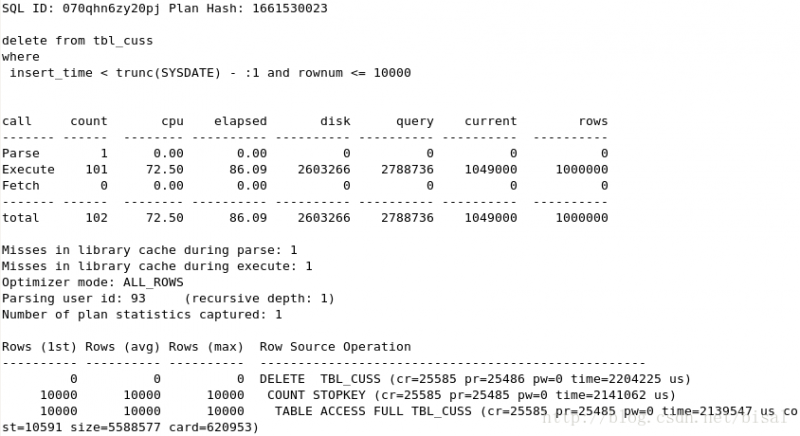
可以看出由于使用了绑定变量,解析一次,由于循环逻辑的问题,执行了100+1次。
(2) 一次性删除5万条记录,insert_time不是索引,删除两天的数据(即100万),
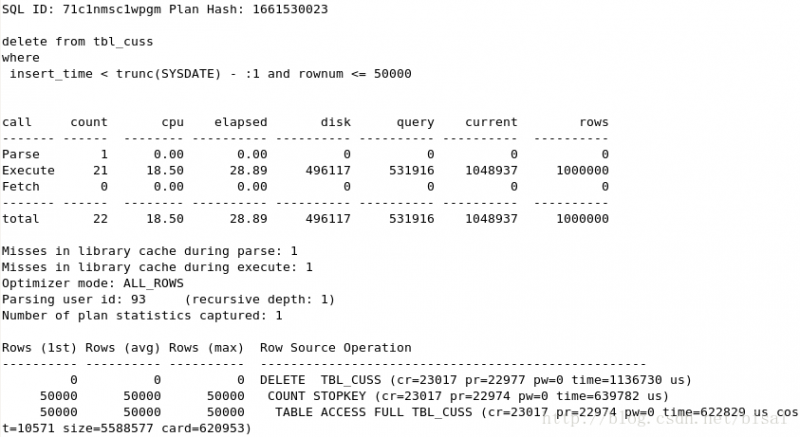
(3) 一次性删除100万条记录,insert_time不是索引,删除两天的数据(即100万),

从elapsed以及query可以比较(1)-(3)。
(4) 一次性删除1万条记录,insert_time是索引,删除两天的数据(即100万),
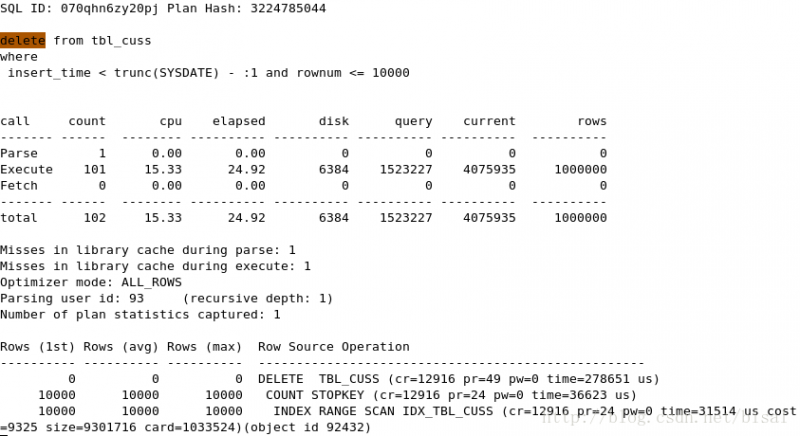
(5) 一次性删除5万条记录,insert_time是索引,删除两天的数据(即100万),
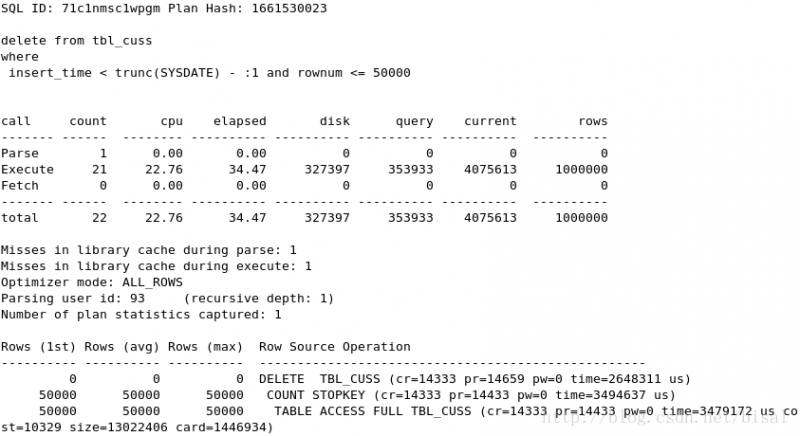
(6) 一次性删除100万条记录,insert_time是索引,删除两天的数据(即100万),
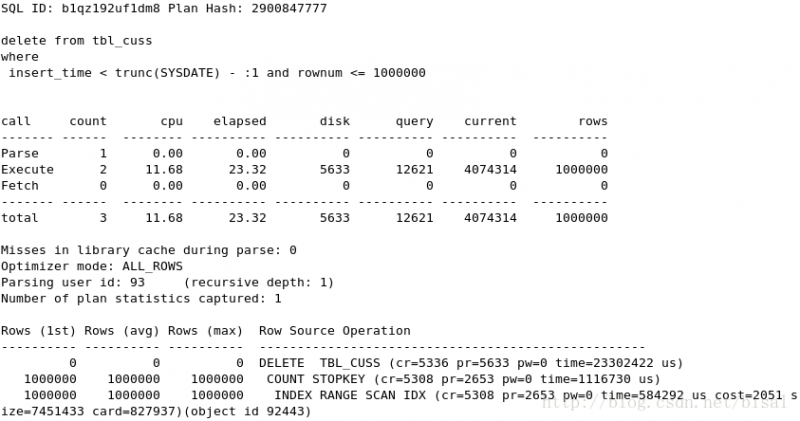
由于需要维护索引,相比TABLE ACCESS FULL,会有些消耗。
clear_all_fetch存储过程各场景trace,
(1) 一次性删除1万条记录,insert_time不是索引,删除两天的数据(即100万),
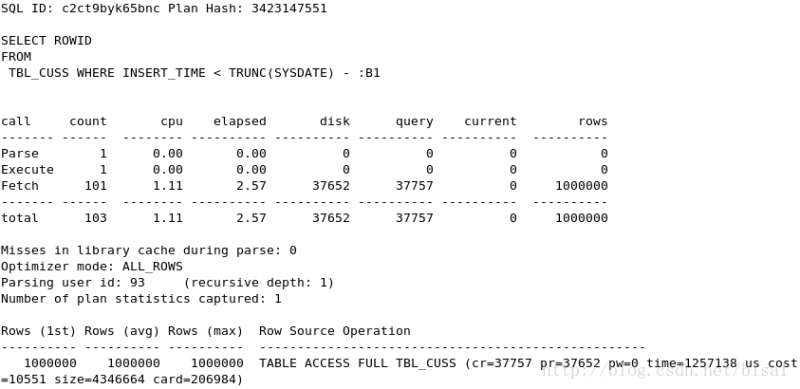
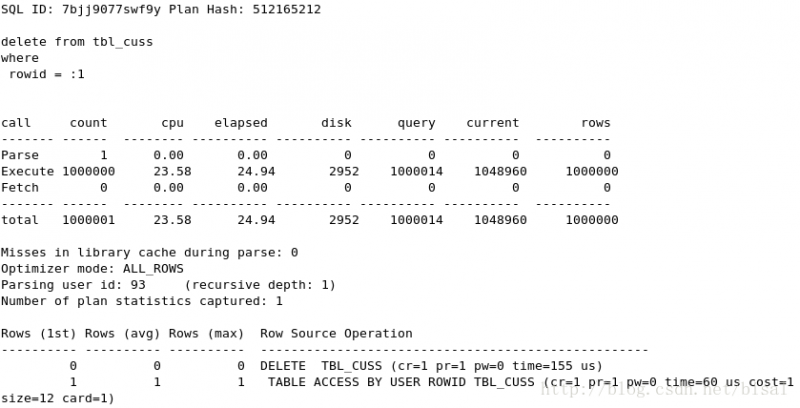
(2) 一次性删除5万条记录,insert_time不是索引,删除两天的数据(即100万),

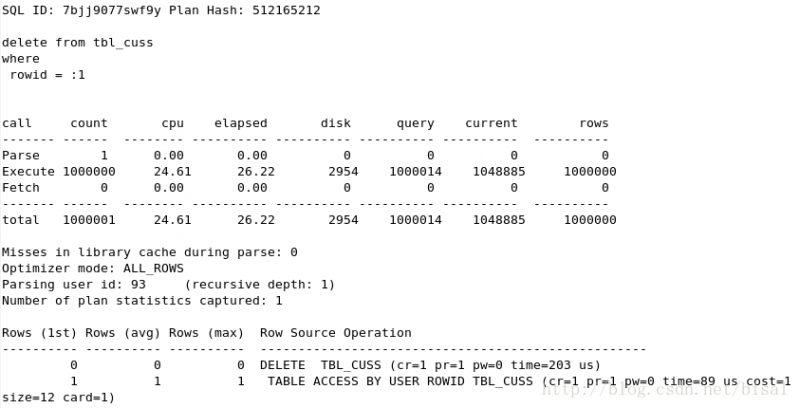
(3) 一次性删除100万条记录,insert_time不是索引,删除两天的数据(即100万),

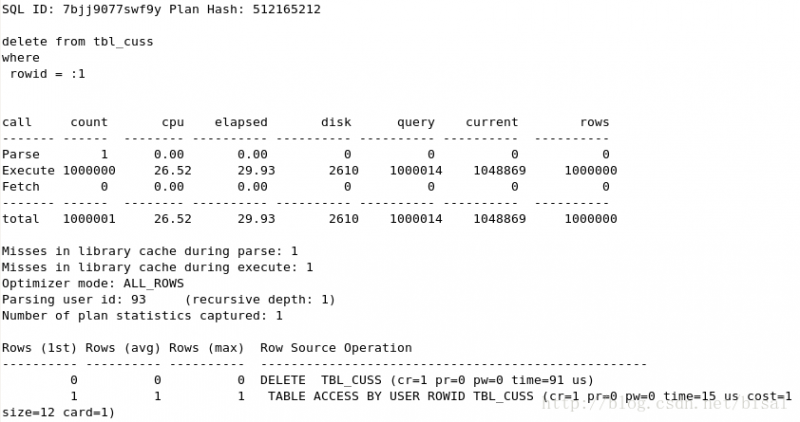
无论(1)、(2)、(3),DELETE语句均执行了100万次,唯一的区别就是SELECT语句和执行的次数。
(4) 一次性删除1万条记录,insert_time是索引,删除两天的数据(即100万),
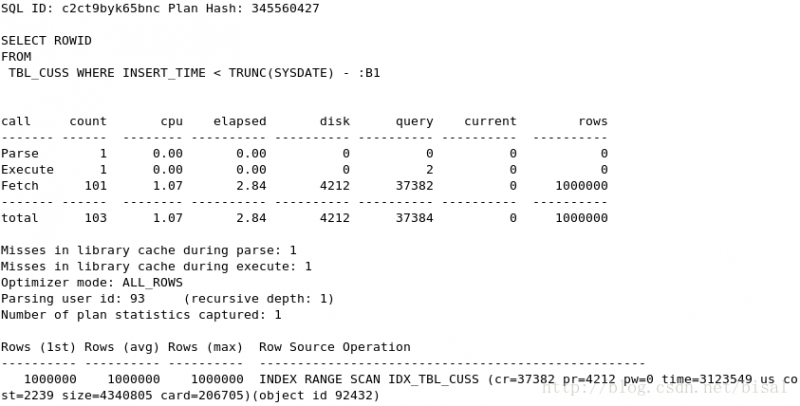
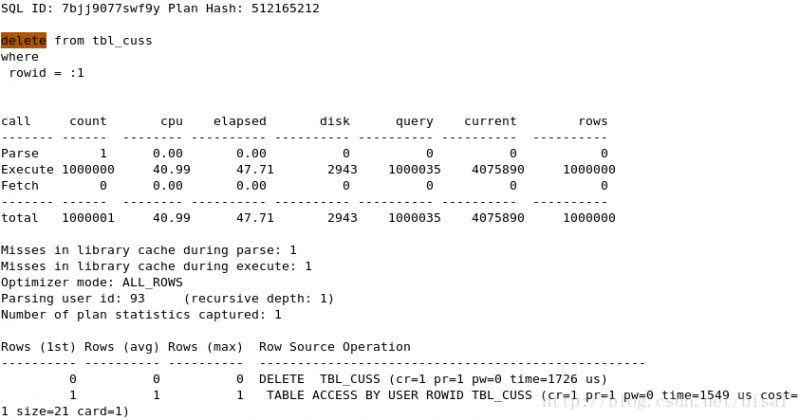
(5) 一次性删除5万条记录,insert_time是索引,删除两天的数据(即100万),
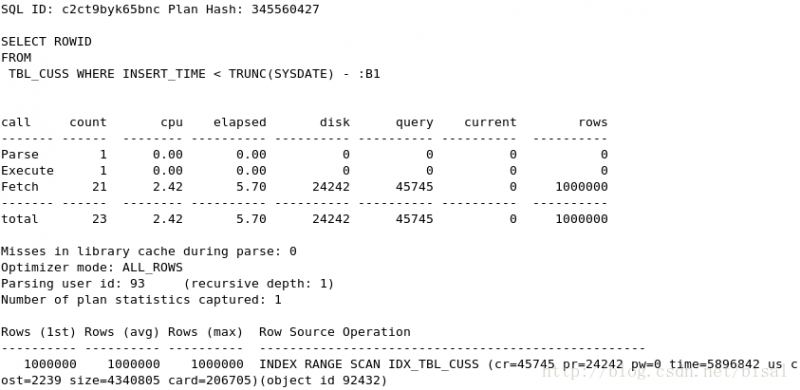
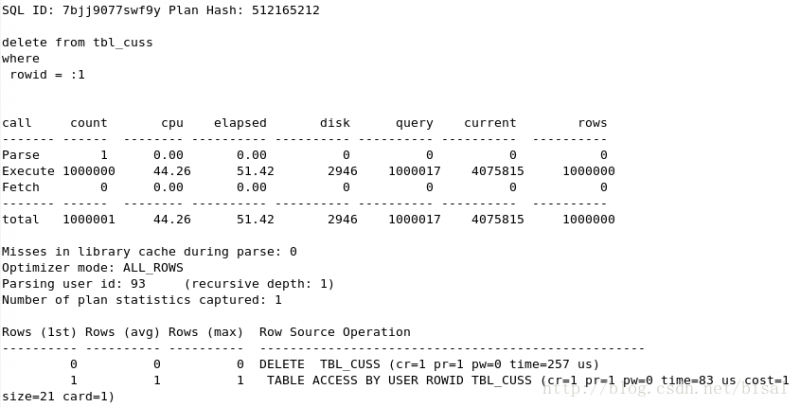
(6) 一次性删除100万条记录,insert_time是索引,删除两天的数据(即100万),
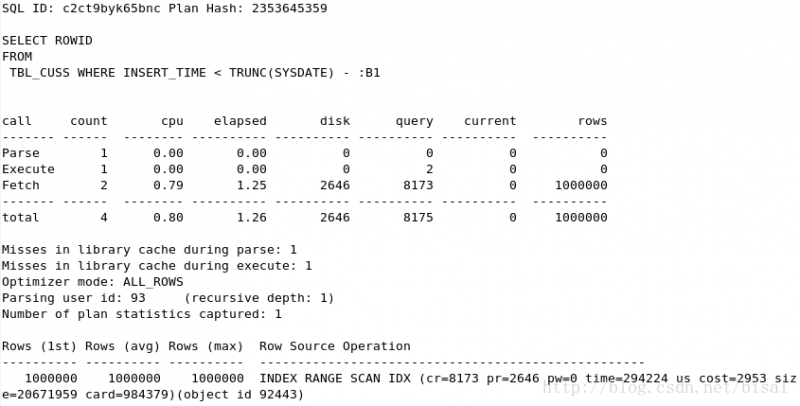
有索引和无索引相比,有一些需要维护索引的消耗。
clear_fetch存储过程各场景trace,
(SELECT和clear_all_fetch存储过程相近,此处忽略)
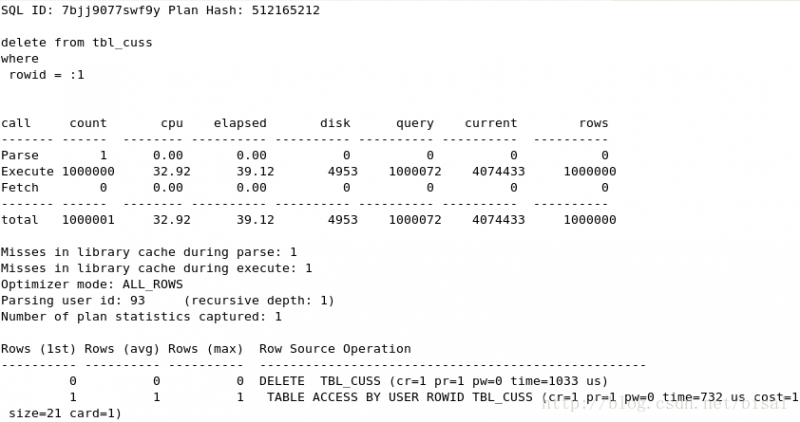
(1) 一次性删除1万条记录,insert_time不是索引,删除两天的数据(即100万),
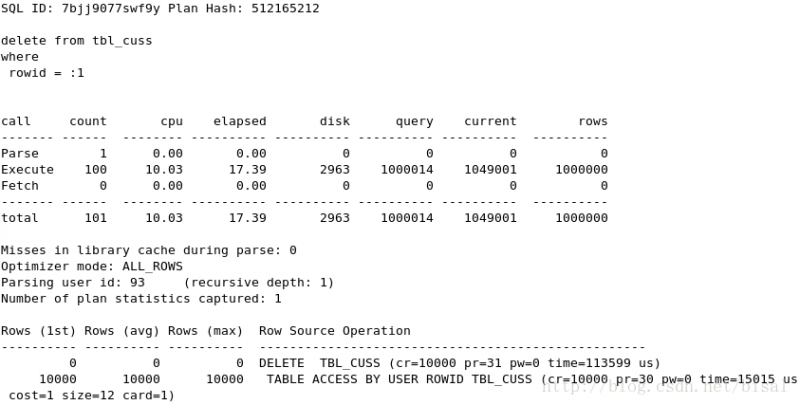
(2) 一次性删除5万条记录,insert_time不是索引,删除两天的数据(即100万),
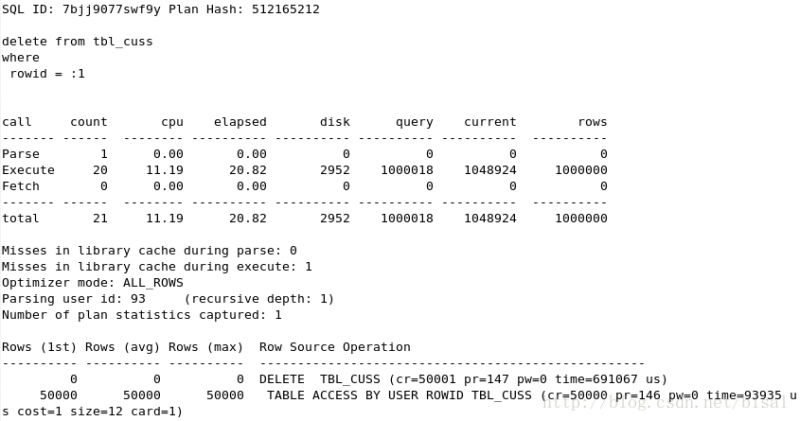
(3) 一次性删除100万条记录,insert_time不是索引,删除两天的数据(即100万),
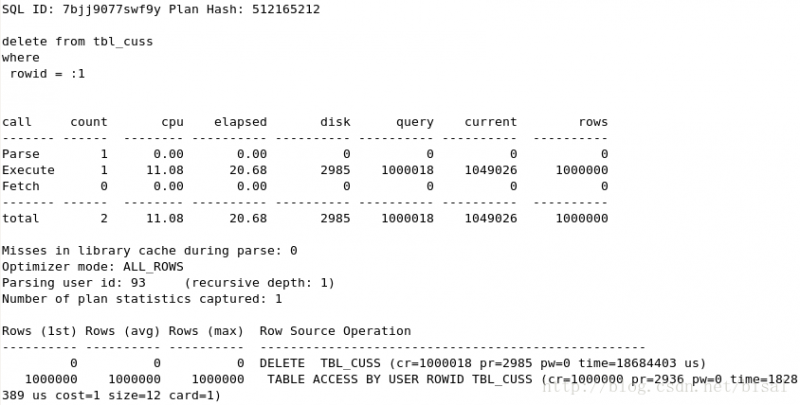
(4) 一次性删除1万条记录,insert_time是索引,删除两天的数据(即100万),
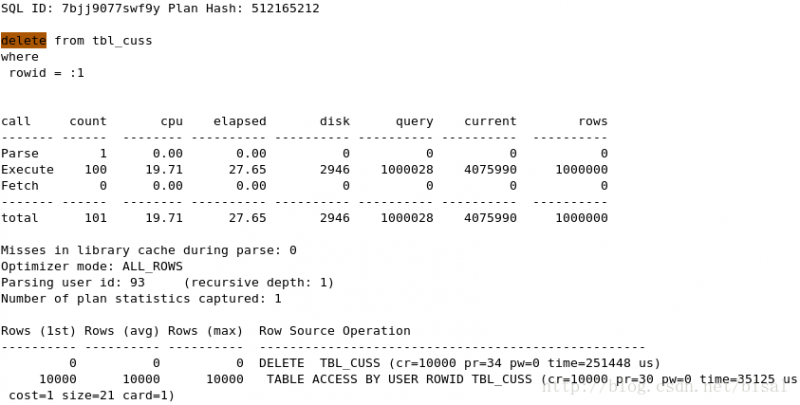
(5) 一次性删除5万条记录,insert_time是索引,删除两天的数据(即100万),
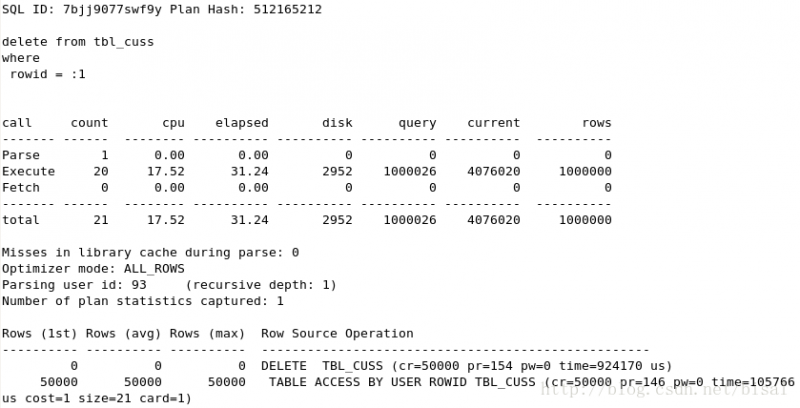
(6) 一次性删除100万条记录,insert_time是索引,删除两天的数据(即100万),
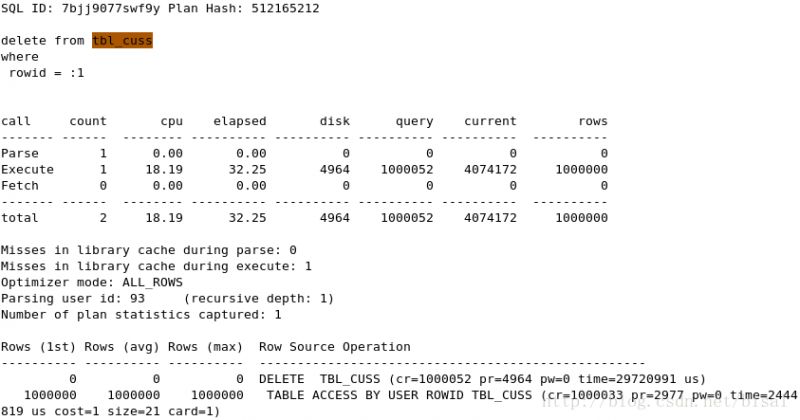
可以看见clear_fetch和clear_all_fetch唯一区别就是DELETE语句执行次数,clear_fetch中执行次数和循环次数一样,说明是批量发送的,单条DELETE相同,但执行次数的不同,影响了资源消耗和执行时间。
从实验中可以得出的结论,
(1) SQL使用TABLE ACCESS FULL的执行计划,若SQL执行次数较多时,则BULK+forall的方式,效率较高;若SQL执行次数较少时,很可能使用TABLE ACCESS FULL的执行计划的SQL,效率和BULK+forall接近,甚至有更优的可能。
(2) SQL使用INDEX RANGE SCAN的执行计划,效率会比BULK+forall略高,若SQL执行次数较少时,使用INDEX RANGE SCAN的执行计划的SQL,效率较高;SQL执行次数对于BULK+forall的方式基本一致。
(3) 无论是否用索引,BULK+forall的方式均优于BULK+for。可以使用索引,则用游标和不用游标,效率比较接近,从实验上看,不用游标反而可能略高一些,这和使用游标需要一些解析类的消耗可能有关,但游标可以带来便捷性,比如方便控制结果集,可以更灵活地编辑逻辑,既然效率比较接近,若时间均是可接受范围内,可以根据实际来考虑,选择什么方式。无论什么方式,大表数据的批量删除,这是首要原则。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

