Oracle中的PGA监控报警分析二(r12笔记第87天)
今天又收到了一条报警的信息,看起来很常规,但是后面的故事如果你做了分析就会发现其实本身并不平常,我觉得我得出手了。
ZABBIX-监控系统:
------------------------------------
报警内容: PGA Alarm on alltest
------------------------------------
报警级别: PROBLEM
------------------------------------
监控项目: PGA:9723.2
------------------------------------
问题原因简单分析
为什么PGA会占用如此大的内存空间,根据分析是imo相关的进程,但是in memory是否正式在环境中使用了,没有,所以这个问题就变得有些诡异了,这里还要牵扯出12c里对于pga的一个新增参数pga_aggregate_limit,这个算是一个硬指标,不能超过它的值,防止一些异常的情况发生。而问题的愿意其实也很特别,是12c中的一个bug,解决方法要么就是升级到12.2要么就是打上补丁,对于线上,测试环境等都有一定的实践难度,我还是选择来干脆关掉imo,把隐患解除,俗话说重启大法好,别以为重启就是一个体力活,你来体会一下这个过程。
重启问题1
因为应用设置了自动重连,为了让这个问题处理得更平滑下,整个重启的过程本来以为会很快,但是却接二连三的碰到了不少的小问题。
首先就是一系列fork错误。我干了什么呢?
就是shutdown immediae 然后startup
这么一个操作本身有问题吗,显然没有,但是启动数据库之后,我在另外一个窗口中使用su - oracle切换的时候却抛出了下面的错误。大体是这两类:
# su - oracle
-bash: fork: retry: Resource temporarily unavailable
-bash: fork: retry: Resource temporarily unavailable
^C-bash: fork: retry: Resource temporarily unavailable
或者
# su - oracle
su: cannot set user id: Resource temporarily unavailable
而问题的原因竟然是设置的内核参数的问题,说超过了1024之后会有这类问题。我的是oracle用户,这个地方对应的就是1024
# cat /etc/security/limits.d/90-nproc.conf
# Default limit for number of user's processes to prevent
# accidental fork bombs.
# See rhbz #432903 for reasoning.
* soft nproc 1024
root soft nproc unlimited
但是数据库层面的会话数只有不到200个,为什么进程数还会超过1000,这个让我有些不解,但是解决问题为先,就先修改了内核参数之后看看是否修复了问题。
从测试来看,这个内核参数导致的su问题告一段落,看到应用层面的连接数也进来了。
重启问题2
但是紧接着就发现哪里不太对劲,就是从客户端新发起的连接都有问题,orabbix端的监控也受到了影响。错误看起来就很诡异了。
$ sqlplus pdb_mgr/xxxx@actvdb
SQL*Plus: Release 12.1.0.2.0 Production on Tue Jun 6 22:47:55 2017
Copyright (c) 1982, 2014, Oracle. All rights reserved.
ERROR:
ORA-12518: TNS:listener could not hand off client connection
所以问题还绕不过去,看来连接数有些异常,系统层面总共有1200多个进程。
$ ps -ef|wc -l
1223
ora相关的进程有近1040个。
$ ps -ef|grep ora|wc -l
1040
按照关键字oracle得到的进程又930个。
$ ps -ef|grep oracletestdb|wc -l
930
而数据库层面的会话数只有不到200个,那么这多出来的进700多个进程到底是哪里的。
而这一点也是解决这个问题的一个关键。
重启问题3
所以这个时候就碰到了第3个问题,我需要彻底的确认一下重启前后是否在系统层面有进程异常。我得把这个问题先解决清楚,使用shutdown immediate竟然卡住了,久久没有反应,后台日志也没有什么输出。
我在确认了Data Guard没有问题的情况,果然使用shutdown abort来结束了这个异常的服务,然后确认ora相关的进程数,确认没有问题之后继续启动数据库,这一次来看总算是恢复了正常。
$ ps -ef|grep oracle|wc -l
334
问题解决后的收益
这个问题在解决之后,对比PGA的使用情况,原来的问题就得到了根治。
有两个问题需要说明,到底是重启前进程数就接近1000还是重启后才达到1000的。
这个图就很明显,是一个系统层面的进程数情况,可以看到进程数是在重启之后突然升上来的,后来经过我的镇压,降下去了。证明在重启前的进程数其实是没有问题的。
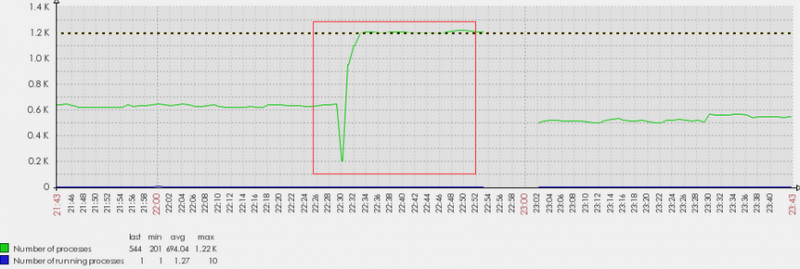
第二个问题是PGA的使用情况,是否达到了预期的结果。这是PGA的监控结果,单位是M,可以看到重启之后没有了imo的副作用,PGA的指标一下子降下来了。
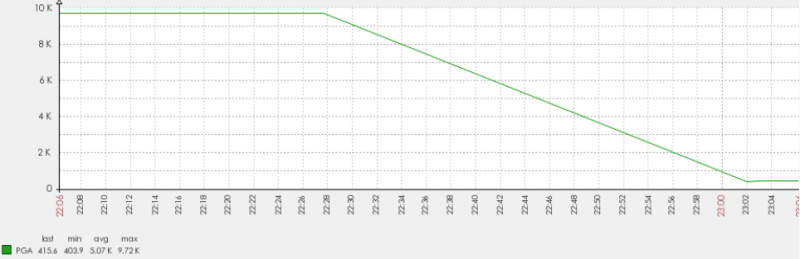
我想这个问题在很长的一段时间里都不会再出现了。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

