CBO中基数(cardinality)、可选择率(selectivity)的计算公式
CBO中基数(cardinality)、可选择率(selectivity)的计算公式
Cardinality(基数)是Oracle预估的返回行数,即对目标SQL的某个具体执行步骤的执行结果所包含记录数的估算值。如果是针对整个目标SQL,那么此时的Cardinality就表示该SQL最终执行结果所包含记录数的估算值。例如,一张表T有1000行数据,列COL1上没有直方图,没有空值,并且不重复的值(Distinct Value)有500个。那么,在使用条件“WHERE COL1=”去访问表的时候,优化器会假设数据均匀分布,它估计出会有1000/500=2行被选出来,2就是这步操作的Cardinality。通常情况下,Cardinality越准确,生成的执行计划就会越高效。
可选择率(Selectivity)是指施加指定谓词条件后返回结果集的记录数占未施加任何谓词条件的原始结果集的记录数的比率。可选择率的取值范围显然是0~1,它的值越小,就表明可选择性越好。当可选择率为1时的可选择性是最差的。CBO就是用可选择率来估算对应结果集的Cardinality的,可选择率和Cardinality之间的关系如下所示:
cardinality=NUM_ROWS*selectivity
其中,NUM_ROWS表示表的总行数。
在Oracle数据库中,Oracle会默认认为SQL语句的WHERE条件中出现的各列彼此之间是独立的,是没有关联关系的。所以,如果目标SQL语句各列之间是以AND来组合的话,那么该SQL语句整个WHERE条件的组合可选择率就等于各个列各自施加查询条件后可选择率的乘积。在得到了SQL语句整个WHERE条件的组合可选择率后,Oracle会用它来估算整个SQL语句返回结果集的Cardinality,估算的方法就是用目标表的总记录数(NUM_ROWS)乘组合可选择率。但Oracle默认认为的各列之间是独立的、没有关联关系的前提条件并不总是正确的,在实际的应用中各列之间有关联关系的情况实际上并不罕见。在这种情况下如果还用上述计算方法来计算目标SQL语句整个WHERE条件的组合可选择率并用它来估算返回结果集的Cardinality的话,那么估算结果可能就会与实际结果有较大的偏差,进而可能导致CBO选错执行计划,所以Oracle又引入了动态采样和多列统计信息。
下表给出了一些常见的可选择率计算公式:
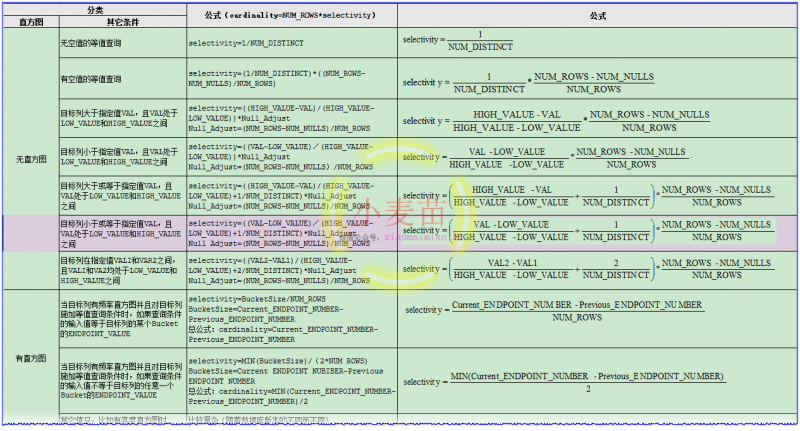
下面给出一个示例:
DROP TABLE T_ROWS_20170605_LHR;
CREATE TABLE T_ROWS_20170605_LHR AS SELECT ROWNUM ID,'NAME1' SAL FROM DUAL CONNECT BY LEVEL<=10000;
UPDATE T_ROWS_20170605_LHR T SET T.ID='' WHERE T.ID<=100;
EXEC DBMS_STATS.GATHER_TABLE_STATS(USER,'T_ROWS_20170605_LHR',CASCADE=>TRUE,METHOD_OPT=>'FOR ALL COLUMNS SIZE 1',estimate_percent => 100);
LHR@orclasm > COL LOW_VALUE FORMAT A20
LHR@orclasm > COL HIGH_VALUE FORMAT A20
LHR@orclasm > SELECT D.LOW_VALUE,D.HIGH_VALUE,UTL_RAW.CAST_TO_NUMBER(D.LOW_VALUE) LOW_VALUE2,UTL_RAW.CAST_TO_NUMBER(D.HIGH_VALUE) HIGH_VALUE2, D.NUM_DISTINCT,D.NUM_NULLS FROM DBA_TAB_COL_STATISTICS D WHERE D.TABLE_NAME = 'T_ROWS_20170605_LHR' AND D.OWNER = 'LHR' AND D.COLUMN_NAME='ID';
LOW_VALUE HIGH_VALUE LOW_VALUE2 HIGH_VALUE2 NUM_DISTINCT NUM_NULLS
-------------------- -------------------- ---------- ----------- ------------ ----------
C20202 C302 101 10000 9900 100
LHR@orclasm > SELECT MIN(T.ID),DUMP(MIN(T.ID),16) LOW_VALUE,MAX(T.ID),DUMP(MAX(T.ID),16) HIGH_VALUE FROM T_ROWS_20170605_LHR T;
MIN(T.ID) LOW_VALUE MAX(T.ID) HIGH_VALUE
---------- -------------------- ---------- --------------------
101 Typ=2 Len=3: c2,2,2 10000 Typ=2 Len=2: c3,2
下面分别执行如下4条SQL语句并获取执行计划:
SELECT COUNT(1) FROM T_ROWS_20170605_LHR T WHERE T.ID=1000;--1
SELECT COUNT(1) FROM T_ROWS_20170605_LHR T WHERE T.ID>1000; --9000
SELECT COUNT(1) FROM T_ROWS_20170605_LHR T WHERE T.ID>=1000; --9001
SELECT COUNT(1) FROM T_ROWS_20170605_LHR T WHERE T.ID BETWEEN 1000 AND 1100; --101
LHR@orclasm > set autot on exp
LHR@orclasm > SELECT COUNT(1) FROM T_ROWS_20170605_LHR T WHERE T.ID=1000;
COUNT(1)
----------
1
Execution Plan
----------------------------------------------------------
Plan hash value: 612708570
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 9 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 4 | | |
|* 2 | TABLE ACCESS FULL| T_ROWS_20170605_LHR | 1 | 4 | 9 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("T"."ID"=1000)
-- ROUND(NUM_ROWS*(1/NUM_DISTINCT)*((NUM_ROWS-NUM_NULLS)/NUM_ROWS))
LHR@orclasm > SELECT ROUND(10000*1/9900*((10000-100)/10000)) VALUE FROM DUAL;
VALUE
----------
1
LHR@orclasm > SELECT COUNT(1) FROM T_ROWS_20170605_LHR T WHERE T.ID>1000;
COUNT(1)
----------
9000
Execution Plan
----------------------------------------------------------
Plan hash value: 612708570
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 9 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 4 | | |
|* 2 | TABLE ACCESS FULL| T_ROWS_20170605_LHR | 9001 | 36004 | 9 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("T"."ID">1000)
--ROUND(NUM_ROWS*((HIGH_VALUE-VAL)/(HIGH_VALUE-LOW_VALUE))*((NUM_ROWS-NUM_NULLS)/NUM_ROWS))
LHR@orclasm > SELECT ROUND(10000*((10000-1000)/(10000-101))*((10000-100)/10000)) VALUE FROM DUAL;
VALUE
----------
9001
LHR@orclasm > SELECT COUNT(1) FROM T_ROWS_20170605_LHR T WHERE T.ID>=1000;
COUNT(1)
----------
9001
Execution Plan
----------------------------------------------------------
Plan hash value: 612708570
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 9 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 4 | | |
|* 2 | TABLE ACCESS FULL| T_ROWS_20170605_LHR | 9002 | 36008 | 9 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("T"."ID">=1000)
--ROUND(NUM_ROWS*((HIGH_VALUE-VAL)/(HIGH_VALUE-LOW_VALUE)+1/NUM_DISTINCT)*((NUM_ROWS-NUM_NULLS)/NUM_ROWS))
LHR@orclasm > SELECT ROUND(10000*((10000-1000)/(10000-101)+1/9900)*((10000-100)/10000)) VALUE FROM DUAL;
VALUE
----------
9002
LHR@orclasm > SELECT COUNT(1) FROM T_ROWS_20170605_LHR T WHERE T.ID BETWEEN 1000 AND 1100;
COUNT(1)
----------
101
Execution Plan
----------------------------------------------------------
Plan hash value: 612708570
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 9 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 4 | | |
|* 2 | TABLE ACCESS FULL| T_ROWS_20170605_LHR | 102 | 408 | 9 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("T"."ID"<=1100 AND "T"."ID">=1000)
LHR@orclasm >
--ROUND(NUM_ROWS*(((VAL2-VAL1)/(HIGH_VALUE-LOW_VALUE)+2/NUM_DISTINCT)*((NUM_ROWS-NUM_NULLS)/NUM_ROWS)))
LHR@orclasm > SELECT ROUND(10000*(((1100-1000)/(10000-101)+2/9900)*((10000-100)/10000))) VALUE FROM DUAL;
VALUE
----------
102
可见预估行数和用公式计算出来的结果相吻合。
下面再查看有频率直方图的时候基数的计算。
DROP TABLE T_ROWS_20170605_LHR;
CREATE TABLE T_ROWS_20170605_LHR AS SELECT ROWNUM ID,'NAME1' SAL FROM DUAL CONNECT BY LEVEL<=10000;
UPDATE T_ROWS_20170605_LHR T SET T.ID='' WHERE T.ID<=100;
UPDATE T_ROWS_20170605_LHR SET ID=2 WHERE ID BETWEEN 101 AND 200;
UPDATE T_ROWS_20170605_LHR SET ID=3 WHERE ID BETWEEN 200 AND 3000;
UPDATE T_ROWS_20170605_LHR SET ID=9 WHERE ID BETWEEN 3000 AND 9999;
SELECT T.ID,COUNT(*) FROM T_ROWS_20170605_LHR T GROUP BY T.ID;
查看数据分布:
LHR@orclasm > SELECT T.ID,COUNT(*) FROM T_ROWS_20170605_LHR T GROUP BY T.ID;
ID COUNT(*)
---------- ----------
100
10000 1
2 100
3 2800
9 6999
收集频率直方图:
LHR@orclasm > EXEC DBMS_STATS.GATHER_TABLE_STATS(USER,'T_ROWS_20170605_LHR',CASCADE=>TRUE,METHOD_OPT=>'FOR COLUMNS ID SIZE 6',estimate_percent => 100);
PL/SQL procedure successfully completed.
LHR@orclasm > SELECT D.COLUMN_NAME,D.NUM_DISTINCT,D.NUM_NULLS,D.NUM_BUCKETS,D.HISTOGRAM,D.DENSITY FROM Dba_Tab_Columns D WHERE D.TABLE_NAME = 'T_ROWS_20170605_LHR' AND D.COLUMN_NAME='ID';
COLUMN_NAME NUM_DISTINCT NUM_NULLS NUM_BUCKETS HISTOGRAM DENSITY
------------------------------ ------------ ---------- ----------- --------------- ----------
ID 4 100 4 FREQUENCY .000050505
LHR@orclasm > COL COLUMN_NAME FORMAT A6
LHR@orclasm > SELECT TABLE_NAME,COLUMN_NAME,ENDPOINT_NUMBER,ENDPOINT_VALUE,NVL((ENDPOINT_NUMBER-(LAG(ENDPOINT_NUMBER) OVER (ORDER BY ENDPOINT_VALUE))),ENDPOINT_NUMBER) COUNTS FROM DBA_TAB_HISTOGRAMS WHERE TABLE_NAME='T_ROWS_20170605_LHR' AND COLUMN_NAME='ID';
TABLE_NAME COLUMN ENDPOINT_NUMBER ENDPOINT_VALUE COUNTS
------------------------------ ------ --------------- -------------- ----------
T_ROWS_20170605_LHR ID 100 2 100
T_ROWS_20170605_LHR ID 2900 3 2800
T_ROWS_20170605_LHR ID 9899 9 6999
T_ROWS_20170605_LHR ID 9900 10000 1
当目标列有频率直方图并且对目标列施加等值查询条件时,如果查询条件的输入值等于目标列的某个Bucket的ENDPOINT_VALUE,那么cardinality=Current_ENDPOINT_NUMBER-Previous_ENDPOINT_NUMBER:
LHR@orclasm > SET AUTOT ON
LHR@orclasm > SELECT COUNT(1) FROM T_ROWS_20170605_LHR T WHERE T.ID=3;
COUNT(1)
----------
2800
Execution Plan
----------------------------------------------------------
Plan hash value: 612708570
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 | 9 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 3 | | |
|* 2 | TABLE ACCESS FULL| T_ROWS_20170605_LHR | 2800 | 8400 | 9 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("T"."ID"=3)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
23 consistent gets
0 physical reads
0 redo size
526 bytes sent via SQL*Net to client
519 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
可见,预估行数为2800,和直方图中存储的值吻合(2900-100)。
当目标列有频率直方图并且对目标列施加等值查询条件时,如果查询条件的输入值不等于目标列的任意一个Bucket的ENDPOINT_VALUE,那么cardinality=MIN(Current_ENDPOINT_NUMBER-Previous_ENDPOINT_NUMBER)/2:
LHR@orclasm > SELECT COUNT(1) FROM T_ROWS_20170605_LHR T WHERE T.ID=4;
COUNT(1)
----------
0
Execution Plan
----------------------------------------------------------
Plan hash value: 612708570
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 | 9 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 3 | | |
|* 2 | TABLE ACCESS FULL| T_ROWS_20170605_LHR | 1 | 3 | 9 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("T"."ID"=4)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
23 consistent gets
0 physical reads
0 redo size
525 bytes sent via SQL*Net to client
519 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
LHR@orclasm > select round(1/2) from dual;
ROUND(1/2)
----------
1
在直方图中,由于MIN(Current_ENDPOINT_NUMBER-Previous_ENDPOINT_NUMBER)=1,所以,ROUND(1/2)=1,和执行计划中的预估行数相吻合。
CBO优化器是基于对当前经过特定测试的数据集中预期的行比率估计来计算基数的。此处的行数之比是一个数值,称为选择率(selectivity)。得到选择率之后,将其与输入行数进行简单相乘既可得到基数。
在理解选择性之前,必须得对user_tab_col_statistics视图有一定了解:
[sql] view plain copy print?
- SQL> desc user_tab_col_statistics
- 名称 是否为空? 类型
- ----------------------------------------- -------- ----------------------------
- TABLE_NAME VARCHAR2(30) 表名
- COLUMN_NAME VARCHAR2(30) 列名
- NUM_DISTINCT NUMBER 列中distinct值的数目
- LOW_VALUE RAW(32) 列的最小值
- HIGH_VALUE RAW(32) 列的最大值
- DENSITY NUMBER 当对列创建了直方图,则值不再等于1/NUM_DISTINCT。
- NUM_NULLS NUMBER 列中的NULL值数目。
- NUM_BUCKETS NUMBER Number of buckets in histogram for the column
- LAST_ANALYZED DATE 最近分析时间。
- SAMPLE_SIZE NUMBER 分析样本大小。
- GLOBAL_STATS VARCHAR2(3) 对分区采样,则-NO,否则-YES。
- USER_STATS VARCHAR2(3) 统计信息由用户导入,则YES,否则-NO。
- AVG_COL_LEN NUMBER 列的平均长度(以字节为单位)
- HISTOGRAM VARCHAR2(15) Indicates existence/type of histogram: NONE、FREQUENCY、HEIGHT BALANCED
下面创建一张测试表,并收集统计信息:
[sql] view plain copy print?
- SQL> create table audience as
- 2 select
- 3 trunc(dbms_random.value(1,13)) month_no
- 4 from
- 5 all_objects
- 6 where
- 7 rownum <= 1200
- 8 ;
- 表已创建。
- SQL> begin
- 2 dbms_stats.gather_table_stats(
- 3 user,
- 4 'audience',
- 5 cascade => true,
- 6 estimate_percent => null,
- 7 );ethod_opt => 'for all columns size 1'
- method_opt => 'for all columns size 1'
- 8 );
- 9 end;
- 10 /
- PL/SQL 过程已成功完成。
先查看一下上面表和列的统计信息:
[sql] view plain copy print?
- SQL> select t.TABLE_NAME, t.NUM_ROWS, t.BLOCKS, t.SAMPLE_SIZE
- 2 from user_tables t;
- TABLE_NAME NUM_ROWS BLOCKS SAMPLE_SIZE
- ---------- ---------- ---------- -----------
- AUDIENCE 1200 5 1200
- SQL> select s.table_name,
- s.column_name,
- s.num_distinct,
- 4 s.low_value,
- s.high_value,
- s.density,
- 7 s.num_nulls,
- 8 s.sample_size,
- 9 s.avg_col_len
- 10 from user_tab_col_statistics s;
- TABLE_NAME COLUMN_NAM NUM_DISTINCT LOW_VALUE HIGH_VALUE DENSITY NUM_NULLS SAMPLE_SIZE AVG_COL_LEN
- ---------- ---------- ------------ ---------- ---------- ---------- ---------- ----------- -----------
- AUDIENCE MONTH_NO 12 C102 C10D .083333333 0 1200 3
- SQL> select rawtohex(1), rawtohex(12) from dual;
- RAWT RAWT
- ---- ----
- C102 C10D
[sql] view plain copy print?
- SQL> select dump(1,16),dump(12,16) from dual;
- DUMP(1,16) DUMP(12,16)
- ----------------- -----------------
- Typ=2 Len=2: c1,2 Typ=2 Len=2: c1,d
- SQL> select utl_raw.cast_to_number('c102'),utl_raw.cast_to_number('c10d') from dual;
- UTL_RAW.CAST_TO_NUMBER('C102') UTL_RAW.CAST_TO_NUMBER('C10D')
- ------------------------------ ------------------------------
- 1 12 --可以看见上面的LOW_VALUE和HIGH_VALUE的值分别就是1和12.
[sql] view plain copy print?
- SQL> select count(a.month_no) from AUDIENCE a;
- COUNT(A.MONTH_NO)
- -----------------
- 1200 --可以看见,这里的值和NUM_ROWS是一样的。
- SQL> select count(distinct a.month_no) from AUDIENCE a;
- COUNT(DISTINCTA.MONTH_NO)
- -------------------------
- 12 --可以看见,这里的值也和NUM_DISTINCT的值是一样的。
[sql] view plain copy print?
- SQL> select 1/12 from dual;
- 1/12
- ----------
- .083333333 --这里的值和DENSITY一样的,计算公式为1/NUM_DISTINCT。
1、假如在上面创建了一张表,里面包含1200个人,如何才能确定其中有多少人的生日是在12月份。
[sql] view plain copy print?
- SQL> select count(*) from AUDIENCE where month_no=12;
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3337892515
- -------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 3 | 3 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 3 | | |
- |* 2 | TABLE ACCESS FULL| AUDIENCE | 100 | 300 | 3 (0)| 00:00:01 |
- -------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("MONTH_NO"=12)
可以看见CBO计算出1200里面,12月份生日的人是100人(在ID=2行的rows)。这和我们通常所理解的是一样的,我们知道月份只有12个,在1200人中在某一个月出生的人,算概率也是100人(CBO也是这样做得)。
计算方法为:DENSITY * NUM_ROWS = 1 / 12 * 1200 = 100。
2、现在假设有10%的人不记得自己的生日了,那么CBO会怎么计算呐?
[sql] view plain copy print?
- SQL> drop table audience purge;
- 表已删除。
- SQL> create table audience as
- 2 select
- 3 rownum id,
- 4 trunc(dbms_random.value(1,13)) month_no
- 5 from
- 6 all_objects
- 7 where
- 8 rownum <= 1200;
- 表已创建。
- SQL> update
- 2 audience
- 3 set month_no = null
- 4 where mod(id,10) = 0; --10%的用户不记得自己的生日。
- 已更新120行。
- SQL> commit;
- 提交完成。
- SQL> begin
- 2 dbms_stats.gather_table_stats(
- 3 user,
- 4 'audience',
- 5 cascade => true,
- 6 estimate_percent => null,
- 7 method_opt => 'for all columns size 1'
- 8 );
- 9 end;
- 10 /
- PL/SQL 过程已成功完成。
- SQL> select t.TABLE_NAME, t.NUM_ROWS, t.BLOCKS, t.SAMPLE_SIZE from user_tables t;
- TABLE_NAME NUM_ROWS BLOCKS SAMPLE_SIZE
- ---------- ---------- ---------- -----------
- AUDIENCE 1200 5 1200
- SQL> select s.table_name,
- 2 s.column_name,
- 3 s.num_distinct,
- 4 s.low_value,
- 5 s.high_value,
- 6 s.density,
- 7 s.num_nulls,
- 8 s.sample_size,
- 9 s.avg_col_len
- 10 from user_tab_col_statistics s;
- TABLE_NAME COLUMN_NAM NUM_DISTINCT LOW_VALUE HIGH_VALUE DENSITY NUM_NULLS SAMPLE_SIZE AVG_COL_LEN
- ---------- ---------- ------------ ---------- ---------- ---------- ---------- ----------- -----------
- AUDIENCE MONTH_NO 12 C102 C10D .083333333 120 1080 3 --这里可以看见,NUM_NULLS的值确实为120。
- AUDIENCE ID 1200 C102 C20D .000833333 0 1200 4
[sql] view plain copy print?
- SQL> select count(*) from AUDIENCE where month_no=12;
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3337892515
- -------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 3 | 3 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 3 | | |
- |* 2 | TABLE ACCESS FULL| AUDIENCE | 90 | 270 | 3 (0)| 00:00:01 |
- -------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("MONTH_NO"=12)
调整后的选择率:DENSITY * ((NUM_ROWS-NUM_NULLS)/NUM_ROWS) = 1 / 12 * ((1200 - 120) / 1200) = 0.075。
返回的记录数(ROWS):调整后的选择率 * NUM_ROWS = 0.075 * 1200 = 90行。
或者我们可以换一种方法思考,通过前面可以很容易的知道12分月有100人生日(其中这里就包含了不记得生日的人)。然后1200人中有10%的人不记得自己的生日,也就是120,那么12月份不记得自己生日的人就平摊到10个人,100-10=90。
3、现在假如我们想知道在6、7、8月份生日的人有多少呐?
[sql] view plain copy print?
- SQL> select count(*) from AUDIENCE where month_no in(6,7,8);
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3337892515
- -------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 3 | 3 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 3 | | |
- |* 2 | TABLE ACCESS FULL| AUDIENCE | 270 | 810 | 3 (0)| 00:00:01 |
- -------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("MONTH_NO"=6 OR "MONTH_NO"=7 OR "MONTH_NO"=8)
6、7、8月份的选择率:6月份选择率 + 7月份选择率 + 8月份选择率 = 0.075 * 3 = 0.225
返回的记录数(ROWS):6、7、8月份的选择率 * NUM_ROWS = 0.225 * 1200 = 270行。
4、下面来一个更复杂一点的,我们想知道不在6、7、8月份生日的人有多少呐?
[sql] view plain copy print?
- SQL> select count(*) from AUDIENCE where month_no not in(6,7,8);
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3337892515
- -------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 3 | 3 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 3 | | |
- |* 2 | TABLE ACCESS FULL| AUDIENCE | 674 | 2022 | 3 (0)| 00:00:01 |
- -------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("MONTH_NO"<>6 AND "MONTH_NO"<>7 AND "MONTH_NO"<>8)
选择率:1 - 6、7、8月份的选择率 = 1 - 0.075 * 3
返回记录数:(1-0.075*3)*1200 = 930。
month_no in{specific list} 的基数 + month_no not in{specific list} 的基数 = NUM_ROWS,这里计算出来是相等的,但是在数据库中看见的却不想等,需要注意!
5、现在我们求8月份以后出生的人,不包含8月份。
[sql] view plain copy print?
- SQL> select count(*) from AUDIENCE where month_no>8;
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3337892515
- -------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 3 | 3 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 3 | | |
- |* 2 | TABLE ACCESS FULL| AUDIENCE | 393 | 1179 | 3 (0)| 00:00:01 |
- -------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("MONTH_NO">8)
选择率:((HIGH_VALUE - LIMIT) / (HIGH_VALUE - LOW_VALUE)) * ((NUM_ROWS - NUM_NULLS) / NUM_ROWS)
返回的记录数:选择率 * NUM_ROWS = ((HIGH_VALUE - LIMIT) / (HIGH_VALUE - LOW_VALUE)) * ((NUM_ROWS - NUM_NULLS) / NUM_ROWS) * NUM_ROWS = round(((12-8)/(12-1))*((1200-120)/1200)*1200) = 393。
如果是求8月份以后出生的人,包含8月份。
[sql] view plain copy print?
- SQL> select count(*) from AUDIENCE where month_no>=8;
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3337892515
- -------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 3 | 3 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 3 | | |
- |* 2 | TABLE ACCESS FULL| AUDIENCE | 483 | 1449 | 3 (0)| 00:00:01 |
- -------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("MONTH_NO">=8)
选择率:((HIGH_VALUE - LIMIT) / (HIGH_VALUE - LOW_VALUE) + 1 / DENSITY) * ((NUM_ROWS - NUM_NULLS) / NUM_ROWS)
返回记录数:选择率 * NUM_ROWS = ((HIGH_VALUE - LIMIT) / (HIGH_VALUE - LOW_VALUE) + 1 / DENSITY) * ((NUM_ROWS - NUM_NULLS) / NUM_ROWS) * NUM_ROWS = round(((12-8)/(12-1)+1/12)*((1200-120)/1200)*1200) = 483。
如果是<8,选择率:((LIMIT - LOW_VALUE) / (HIGH_VALUE - LOW_VALUE)) * ((NUM_ROWS - NUM_NULLS) / NUM_ROWS)
如果是<=8,选择率:((LIMIT - LOW_VALUE) / (HIGH_VALUE - LOW_VALUE) + 1 / DENSITY) * ((NUM_ROWS - NUM_NULLS) / NUM_ROWS)
6、现在我们想知道6月份到8月份出生的人的数量?
[sql] view plain copy print?
- SQL> select count(*) from AUDIENCE where month_no>=6 and month_no<=8;
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3337892515
- -------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 3 | 3 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 3 | | |
- |* 2 | TABLE ACCESS FULL| AUDIENCE | 376 | 1128 | 3 (0)| 00:00:01 |
- -------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("MONTH_NO">=6 AND "MONTH_NO"<=8)
选择率:((HIGH_LIMIT - LOW_LIMIT) / (HIGH_VALUE - LOW_VALUE) + 1 / DENSITY + 1 / DENSITY) * ((NUM_ROWS - NUM_NULLS) / NUM_ROWS)
返回记录数:round(((8-6)/(12-1)+1/12+1/12)*((1200-120)/1200)*1200) = 376。
7、下面看两个谓词的情况下,CBO是怎么计算选择率的。
[sql] view plain copy print?
- SQL> drop table audience purge;
- 表已删除。
- SQL> create table audience as
- 2 select
- 3 rownum id,
- 4 trunc(dbms_random.value(1,13))month_no,
- 5 trunc(dbms_random.value(1,16))eu_country
- 6 from
- 7 all_objects
- 8 where
- 9 rownum <= 1200;
- 表已创建。
- SQL> begin
- 2 dbms_stats.gather_table_stats(
- 3 user,
- 4 'audience',
- 5 cascade => true,
- 6 estimate_percent => null,
- 7 method_opt => 'for all columns size 1'
- 8 );
- 9 end;
- 10 /
- PL/SQL 过程已成功完成。
- SQL> select t.TABLE_NAME, t.NUM_ROWS, t.BLOCKS, t.SAMPLE_SIZE from user_tables t;
- TABLE_NAME NUM_ROWS BLOCKS SAMPLE_SIZE
- ---------- ---------- ---------- -----------
- AUDIENCE 1200 6 1200
- SQL> select s.table_name,
- 2 s.column_name,
- 3 s.num_distinct,
- 4 s.low_value,
- 5 s.high_value,
- 6 s.density,
- 7 s.num_nulls,
- 8 s.sample_size,
- 9 s.avg_col_len
- 10 from user_tab_col_statistics s;
- TABLE_NAME COLUMN_NAM NUM_DISTINCT LOW_VALUE HIGH_VALUE DENSITY NUM_NULLS SAMPLE_SIZE AVG_COL_LEN
- ---------- ---------- ------------ ---------- ---------- ---------- ---------- ----------- -----------
- AUDIENCE EU_COUNTRY 15 C102 C110 .066666667 0 1200 3
- AUDIENCE MONTH_NO 12 C102 C10D .083333333 0 1200 3
- AUDIENCE ID 1200 C102 C20D .000833333 0 1200 4
[sql] view plain copy print?
- SQL> select count(*) from audience where month_no=12 and eu_country=8;
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3337892515
- -------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 6 | 3 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 6 | | |
- |* 2 | TABLE ACCESS FULL| AUDIENCE | 7 | 42 | 3 (0)| 00:00:01 |
- -------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("EU_COUNTRY"=8 AND "MONTH_NO"=12)
选择率:month_no选择率 * eu_contry选择率 = 1/12 * 1/15
返回记录:round(1/12*1/15*1200) = 7。
[sql] view plain copy print?
- SQL> select count(*) from audience where month_no=12 or eu_country=8;
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3337892515
- -------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 6 | 3 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 6 | | |
- |* 2 | TABLE ACCESS FULL| AUDIENCE | 173 | 1038 | 3 (0)| 00:00:01 |
- -------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("MONTH_NO"=12 OR "EU_COUNTRY"=8)
选择率:month_no选择率 + eu_contry选择率 - month_no选择率 * eu_contry选择率 = 1/12+1/15-1/12*1/15
返回记录:round((1/12+1/15-1/12*1/15)*1200) = 173。
[sql] view plain copy print?
- SQL> select count(*) from audience where month_no<>12;
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3337892515
- -------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 3 | 3 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 3 | | |
- |* 2 | TABLE ACCESS FULL| AUDIENCE | 1100 | 3300 | 3 (0)| 00:00:01 |
- -------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("MONTH_NO"<>12)
选择率:1- month_no选择率 = 1- 1/12
返回记录:(1-1/12)*1200 = 1100。
8、总结:
[sql] view plain copy print?
- 单个谓词过滤:
- = 基数计算公式 :1/num_distinct*(num_rows-num_nulls),如果有直方图,基数计算公式=(num_rows-num_nulls)*density
- > 基数计算公式:(high_value-limit)/(high_value-low_value)*(num_rows-num_nulls)
- >= 基数计算公式:((high_value-limit)/(high_value-low_value)+1/num_distinct)*(num_rows-num_nulls) 因为有=,所以要加上=的选择率,=的选择率为1/num_distinct
- < 基数计算公式:(limit-low_value)/(high_value-low_value)*(num_rows-num_nulls)
- <= 基数计算公式:((limit-low_value)/(high_value-low_value)+1/num_distinct)*(num_rows-num_nulls)
- between ... and ... 的基数计算公式等价于 xxx<= high_limit ,xxxx>=low_limit
- 基数计算公式:((high_limit-low_limit)/(high_value-low_value)+2/num_distinct)*(num_rows-num_nulls)
- low_limit<xxx and</xxx xxx<high_limit 基数计算公式:(high_limit-low_limit) (high_value-low_value)*(num_rows-num_nulls)
- low_limit<=xxx and xxx<high_limit 基数计算公式:(high_limit-low_limit) (high_value-low_value)+1="" num_distinct)*(num_rows-num_nulls)
- 双谓词,多谓词:
- A AND B 选择率计算公式=A选择率*B选择率
- A OR B 选择率计算公式=A+B-(A AND B)
- NOT A 选择率计算公式=1-A选择率
oracle包含的2种代价模型:
oracle通过隐含参数“_optimizer_cost_model"控制使用哪种代价模型
1io代价模型
cost=iocost
2cpu代价模型
cost=iocost+cpucost
在代价转换的过程中,所有的代价都转换为单数据块读的单次代价
存在四种类型的io,单块读,多块读,直接数据块读和直接数据块写
iocost=上述四种io的消耗
选择率与密度,空值,唯一值,以及柱状图数据有关。过滤条件的选择率
a and b a的选择率*b的选择率
a or b a的选择率+b的选择率-a*b
not a 1-a的选择率
在未引入系统统计信息之前,oracle会假设下面的2中情况是成立的:
1 单块读的平均消耗时间和多块读的平均消耗时间相等
2全表扫的时候,根据下面的情况计算全表扫描的成本
mbdivisor=1.675*power(db_file_multiblock_read_count,0.6581)
tsc=blocks/mbdivisor
10.2中的mbdivisor大约是4.4,11.2中的改值大约是3.6
cpu cost model在开启的情况下,全表扫描的计算公式如下:
tsc cost=i/o cost+cpu cost
i/o cost =1+ceil(blocks/mbrc)*(mreadtim/sreadtim)
cpu cost=round(#cpucycles/cpuspeed/1000/sreadtim)
系统的统计信息放在了aux_stats$中
查看统计信息收集的历史
wri$_optstat_tab_history
执行计划中的记录数是数据记录数*选择率,运行时间的估算,总的单数据块读的io代价*单次数据块读时间
全表扫描的大概估计:
索引范围扫描:分支节点读取的数据块数和叶子节点数据块数决定。分支节点数据块的读取数等于索引数的分支节点层数。叶子节点的计算是叶子节点数*条件选择率
所以索引的代价大概是层数+叶结点数*选择率*optimizer_index_cost_adj
索引rowid访问表的计算:这边涉及到一个聚簇因子,它是代表了数据块的聚集性。
iocost=索引树高度+叶子数据块数量*access的选择率+聚簇因子*filter的选择率*optica/100
索引范围扫描的计算公式:
i/o cost= index access i/o cost + table access i/o cost
index access i/o cost= blevel+ceil(#leaf_block*ix_sel)
table acess i/o cost=ceil(clustering_factor*ix_sel_with_filters)
列上没有直方图,且没有null值得情况下,列的选择率=(1/num_distinct)
列上没有直方图,且有null值的情况下,列的选择率=(1/num_distinct)*((num_rows-num_nulls)/num_rows)
列上的low_value和high_value是用来评估列做范围查询时的可选择率
目标列大于指定值val,且val处于low_value与high_value之间
selectivity=((high_value-val)/(high_value-low_value)*null_adjust;
null_adjust=(num_rows-num_nulls)/num_rows
目标列小于指定val,且val处于low和high之间
selectivity=(val-low_value)/(high_value-low_value)*null_adjust;
null_adjust=(num_rows-num_nulls)/num_rows
目标列大于或等于指定值val,且val处于low和high之间
selectivity=((high-val)/(high-low)+1/num_distinct)*null_adjust
目标列小于或等于指定值val,且val处于low和high之间
selectivity=((val-low)/high-low)+1/num_distinct)*null_adjust
目标列在指定值val1和val2之间,且val1和val2都在low和high之间
selectivity=((val2-val1)/high-low)+2/num_distinct)*null_adjust
对于使用了绑定变量的sql,启动绑定变量窥探,则对于>的范围查询
Selectivity = (high_value - limit) / (high_value - low_value) limit是绑定变量的值
Cardinality = rows*selectivity
对于使用了绑定变量的sql,如果没有启用绑定变量窥探,则对于>的范围查询
selectivity=0.05
没有启用绑定变量窥探,对于between and的查询
selectivity=0.0025
--测试选择率
SQL> select count(*) from tt where object_id is null;
COUNT(*)
----------
99
SQL> select count(*) from tt;
COUNT(*)
----------
49859
exec dbms_stats.gather_table_stats(ownname => 'baixyu',tabname => 'TT',method_opt => 'for all columns size 1');
SQL> select count(*) from tt where object_id is null;
COUNT(*)
----------
99
SQL> select count(*) from tt;
COUNT(*)
----------
49859
select num_distinct,low_value,high_value,num_nulls from user_tab_col_statistics s where s.table_name='TT' and s.column_name='OBJECT_ID';
49760 C2020BC3061C2299
SQL> select * from tt where object_id=120;
执行计划
----------------------------------------------------------
Plan hash value: 264906180
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 93 | 159 (2)| 00:00:02 |
|* 1 | TABLE ACCESS FULL| TT | 1 | 93 | 159 (2)| 00:00:02 |
--------------------------------------------------------------------------
SQL> select 1/49760*((49859-99)/49859)*49859 from dual;
1/49760*((49859-99)/49859)*49859
--------------------------------
1
SQL> select * from tt where object_id>120 and object_id<200;
已选择78行。
执行计划
----------------------------------------------------------
Plan hash value: 264906180
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 76 | 7068 | 159 (2)| 00:00:02 |
|* 1 | TABLE ACCESS FULL| TT | 76 | 7068 | 159 (2)| 00:00:02 |
--------------------------------------------------------------------------
select (((200-120)/(52744-101)+2/49760)*49760/49859)*49859 from dual;
(((200-120)/(52744-101)+2/49760)*49760/49859)*49859
---------------------------------------------------
77.6187907
在列上没有直方图的情况下,统计信息中的density可以认为是1/num_distinct,在列上有等频直方图时,density的计算公式为
density=1/(2*num_rows*null_adjust)
null_adjust-(num_rows-num_nulls)/num_rows
如果查询条件的输入值等于目标列的某个bucket的endpoint_value那么 列的cardinality的计算公式是
cardinality=num_rows*selectivity
selectivity=bucketsize/num_rows
bucketsize=current_endpoint_number-previous_endpoint_number
如果查询条件的输入值不等于目标列的任意一个bucket的endpoint_value,计算公式如下
cardinality=num_rows*selectivity
selectivity=min(bucketsize)/(2*num_rows)
bucketsize=current_endpoint_number-previous_endpoint_number;
---怎么不直接设置成0?
当列上的直方图信息是等高直方图的时候,等值查询的估算是
1如果查询条件输入值是popular value
cardinality=num_rows*selectivity
selectivity=(buckets_this_popular_value/buckets_totoal)*null_adjust
null_adjust=(num_rows-num_nulls)/num_rows
2如果是unpopular value
分成三种情况。。。。
本章将讨论采用标准的选择率计算方式却产生不合适结果的一些最常见原因。
1、前导零
创建一个包含2000000行数据的表,它有一个id列,采用序号并利用0来进行填充其他位。因此典型的存储值将是A00000000000000001,系统中绝大部分使用这种策略的查询,类似于where id={string constant}的形式;但是,如果它们使用了基于区间的谓词,可能将出现一些奇怪的性能问题。
[sql] view plain copy print?
- SQL> create table t1
- 2 nologging
- 3 pctfree 0
- 4 as
- 5 with generator as (
- 6 select
- 7 rownum id
- 8 from all_objects
- 9 where rownum <= 2000
- 10 )
- 11 select
- 12 /*+ ordered use_nl(v2) */
- 13 trunc((rownum-1)/10000) grp_id,
- 14 'A' || lpad(rownum, 17, '0') id
- 15 from
- 16 generator v1,
- 17 generator v2
- 18 where
- 19 rownum <= 2000000
- 20 ;
- 表已创建。
- SQL> begin
- 2 dbms_stats.gather_table_stats(
- 3 ownname=> user,
- 4 tabname=> 't1',
- 5 cascade=> true,
- 6 estimate_percent=> null,
- 7 method_opt=>'for all columns size 1'
- 8 );
- 9 end;
- 10 /
- PL/SQL 过程已成功完成。
[sql] view plain copy print?
- SQL> set autotrace traceonly;
- SQL> select * from t1 where id between 'A00000000000060000' and 'A00000000000070000';
- 已选择10001行。
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3617692013
- --------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- --------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 17 | 374 | 1190 (3)| 00:00:15 |
- |* 1 | TABLE ACCESS FULL| T1 | 17 | 374 | 1190 (3)| 00:00:15 |
- --------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 1 - filter("ID"<='A00000000000070000' AND "ID">='A00000000000060000')
- 统计信息
- ----------------------------------------------------------
- 1 recursive calls
- 0 db block gets
- 7520 consistent gets
- 6849 physical reads
- 0 redo size
- 325111 bytes sent via SQL*Net to client
- 7741 bytes received via SQL*Net from client
- 668 SQL*Net roundtrips to/from client
- 0 sorts (memory)
- 0 sorts (disk)
- 10001 rows processed
针对该查询得到的基数是非常低的(17),但是很明显却返回了10001行。下面重新创建直方图,直方图的默认值为75个桶。
[sql] view plain copy print?
- SQL> set autotrace off;
- SQL> begin
- 2 dbms_stats.gather_table_stats(
- 3 ownname=> user,
- 4 tabname=> 't1',
- 5 cascade=> true,
- 6 estimate_percent=> null,
- 7 method_opt=>'for all columns size 75'
- 8 );
- 9 end;
- 10 /
- PL/SQL 过程已成功完成。
- SQL> set autotrace traceonly;
- SQL> select * from t1 where id between 'A00000000000060000' and 'A00000000000070000';
- 已选择10001行。
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3617692013
- --------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- --------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 8924 | 191K| 1190 (3)| 00:00:15 |
- |* 1 | TABLE ACCESS FULL| T1 | 8924 | 191K| 1190 (3)| 00:00:15 |
- --------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 1 - filter("ID"<='A00000000000070000' AND "ID">='A00000000000060000')
- 统计信息
- ----------------------------------------------------------
- 0 recursive calls
- 0 db block gets
- 7520 consistent gets
- 6849 physical reads
- 0 redo size
- 325111 bytes sent via SQL*Net to client
- 7741 bytes received via SQL*Net from client
- 668 SQL*Net roundtrips to/from client
- 0 sorts (memory)
- 0 sorts (disk)
- 10001 rows processed
直方图的默认值为75个桶,执行计划显示估计的基数为8924——这个结果至少大体上是正确的。创建直方图是一种方法,如果id列的值没有字符,是可以转换为数字的字符串(00000000000000001),那么在id列上面创建一个函数索引也是一种办法:create index t1_i1 on t1(grp_id, to_number(id));
2、致命的默认值
即时是数据库应用程序正确的使用了日期类型,也仍然需要避免null值。为了不让任何列为null,每个可空的列都有一个默认值。因此,大部分独立于数据库的开发人员会选择一个什么样的值来表示null日期呢?如果表示很久以后的日期呢?比如4000年12月31日。
[sql] view plain copy print?
- SQL> create table t1
- 2 as
- 3 with generator as (
- 4 select
- 5 rownum id
- 6 from all_objects
- 7 where rownum <= 2000
- 8 )
- 9 select
- 10 /*+ ordered use_nl(v2) */
- 11 decode(
- 12 mod(rownum - 1,1000),
- 13 0,to_date('4000-12-31','yyyy-mm-dd'),
- 14 to_date('2000-01-01','yyyy-mm-dd') + trunc((rownum - 1)/100)
- 15 ) date_closed
- 16 from
- 17 generator v1,
- 18 generator v2
- 19 where rownum <= 1827 * 100;
- 表已创建。
- SQL> begin
- 2 dbms_stats.gather_table_stats(
- 3 ownname=> user,
- 4 tabname=> 't1',
- 5 cascade=> true,
- 6 estimate_percent=> null,
- 7 method_opt=>'for all columns size 1' --直方图的默认值为1桶。
- 8 );
- 9 end;
- 10 /
- PL/SQL 过程已成功完成。
- SQL> set autotrace traceonly;
- SQL> select *
- 2 from t1
- 3 where date_closed between to_date('2003-01-01', 'yyyy-mm-dd') and
- 4 to_date('2003-12-31', 'yyyy-mm-dd');
- 已选择36463行。
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3617692013
- --------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- --------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 291 | 2328 | 61 (4)| 00:00:01 |
- |* 1 | TABLE ACCESS FULL| T1 | 291 | 2328 | 61 (4)| 00:00:01 |
- --------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 1 - filter("DATE_CLOSED"<=TO_DATE(' 2003-12-31 00:00:00',
- 'syyyy-mm-dd hh24:mi:ss') AND "DATE_CLOSED">=TO_DATE(' 2003-01-01
- 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
- 统计信息
- ----------------------------------------------------------
- 1 recursive calls
- 0 db block gets
- 2759 consistent gets
- 0 physical reads
- 0 redo size
- 494301 bytes sent via SQL*Net to client
- 27145 bytes received via SQL*Net from client
- 2432 SQL*Net roundtrips to/from client
- 0 sorts (memory)
- 0 sorts (disk)
- 36463 rows processed --这里实际放回了36463行记录,但是oracle却计算错误了(291)。
- SQL> set autotrace off;
- SQL> begin
- 2 dbms_stats.gather_table_stats(
- 3 ownname=> user,
- 4 tabname=> 't1',
- 5 cascade=> true,
- 6 estimate_percent=> null,
- 7 method_opt=>'for all columns size 11' --直方图的默认值为11桶。
- 8 );
- 9 end;
- 10 /
- PL/SQL 过程已成功完成。
- SQL> set autotrace traceonly;
- SQL> select *
- 2 from t1
- 3 where date_closed between to_date('2003-01-01', 'yyyy-mm-dd') and
- 4 to_date('2003-12-31', 'yyyy-mm-dd');
- 已选择36463行。
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3617692013
- --------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- --------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 36320 | 283K| 61 (4)| 00:00:01 |
- |* 1 | TABLE ACCESS FULL| T1 | 36320 | 283K| 61 (4)| 00:00:01 |
- --------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 1 - filter("DATE_CLOSED">=TO_DATE(' 2003-01-01 00:00:00',
- 'syyyy-mm-dd hh24:mi:ss') AND "DATE_CLOSED"<=TO_DATE(' 2003-12-31
- 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
- 统计信息
- ----------------------------------------------------------
- 0 recursive calls
- 0 db block gets
- 2759 consistent gets
- 0 physical reads
- 0 redo size
- 494301 bytes sent via SQL*Net to client
- 27145 bytes received via SQL*Net from client
- 2432 SQL*Net roundtrips to/from client
- 0 sorts (memory)
- 0 sorts (disk)
- 36463 rows processed --36463:36320这次oracle计算得比较准确了。
可以看见加大了直方图的桶数之后,CBO估算的行数就比较接近真实值了,那我们再加大直方图的桶数试一下呐!
[sql] view plain copy print?
- SQL> set autotrace off;
- SQL> begin
- 2 dbms_stats.gather_table_stats(
- 3 ownname=> user,
- 4 tabname=> 't1',
- 5 cascade=> true,
- 6 estimate_percent=> null,
- 7 method_opt=>'for all columns size 75'
- 8 );
- 9 end;
- 10 /
- PL/SQL 过程已成功完成。
- SQL> set autotrace trace;
- SQL> select *
- 2 from t1
- 3 where date_closed between to_date('2003-01-01', 'yyyy-mm-dd') and
- 4 to_date('2003-12-31', 'yyyy-mm-dd');
- 已选择36463行。
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3617692013
- --------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- --------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 36345 | 283K| 61 (4)| 00:00:01 |
- |* 1 | TABLE ACCESS FULL| T1 | 36345 | 283K| 61 (4)| 00:00:01 |
- --------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 1 - filter("DATE_CLOSED">=TO_DATE(' 2003-01-01 00:00:00',
- 'syyyy-mm-dd hh24:mi:ss') AND "DATE_CLOSED"<=TO_DATE(' 2003-12-31
- 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
- 统计信息
- ----------------------------------------------------------
- 0 recursive calls
- 0 db block gets
- 2759 consistent gets
- 0 physical reads
- 0 redo size
- 494301 bytes sent via SQL*Net to client
- 27145 bytes received via SQL*Net from client
- 2432 SQL*Net roundtrips to/from client
- 0 sorts (memory)
- 0 sorts (disk)
- 36463 rows processed --36463:36345 加大了直方图的桶数之后,CBO估算返回的行数误差更小了。
3、离散数据的风险
考虑一个包含period列的计数系统——存储1~12月的数据,并额外再加一个月,其对应的数值为99(同时包含了第二种选择,即这个特殊的月给定的值为13)。
[sql] view plain copy print?
- SQL> create table t1
- 2 as
- 3 with generator as (
- 4 select
- 5 rownum id
- 6 from all_objects
- 7 where rownum <= 1000
- 8 )
- 9 select
- 10 /*+ ordered use_nl(v2) */
- 11 mod(rownum-1,13) period_01,
- 12 mod(rownum-1,13) period_02
- 13 from
- 14 generator v1,
- 15 generator v2
- 16 where
- 17 rownum <= 13000
- 18 ;
- 表已创建。
- SQL> update t1 set
- 2 period_01 = 99,
- 3 period_02 = 13
- 4 where
- 5 period_01 = 0;
- 已更新1000行。
- SQL> commit;
- 提交完成。
- SQL> begin
- 2 dbms_stats.gather_table_stats(
- 3 user,
- 4 't1',
- 5 cascade => true,
- 6 estimate_percent => null,
- 7 method_opt => 'for all columns size 1'
- 8 );
- 9 end;
- 10 /
- PL/SQL 过程已成功完成。
- SQL> set autotrace on exp;
- SQL> select count(*) from t1 where period_01 between 4 and 6;
- COUNT(*)
- ----------
- 3000 --这里实际有3000行,但是oracle估算的是1663行,不准确!
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3724264953
- ---------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- ---------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 3 | 6 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 3 | | |
- |* 2 | TABLE ACCESS FULL| T1 | 1663 | 4989 | 6 (0)| 00:00:01 |
- ---------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("PERIOD_01"<=6 AND "PERIOD_01">=4)
- SQL> select count(*) from t1 where period_02 between 4 and 6;
- COUNT(*)
- ----------
- 3000 --这里实际有3000行,但是oracle估算的是4167行,不准确!
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3724264953
- ---------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- ---------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 3 | 6 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 3 | | |
- |* 2 | TABLE ACCESS FULL| T1 | 4167 | 12501 | 6 (0)| 00:00:01 |
- ---------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("PERIOD_02"<=6 AND "PERIOD_02">=4)
- SQL> set autotrace off;
- SQL> begin
- 2 dbms_stats.gather_table_stats(
- 3 user,
- 4 't1',
- 5 cascade => true,
- 6 estimate_percent => null,
- 7 method_opt => 'for all columns size 254' --重新收集直方图。
- 8 );
- 9 end;
- 10 /
- PL/SQL 过程已成功完成。
- SQL> set autotrace on exp;
- SQL> select count(*) from t1 where period_01 between 4 and 6;
- COUNT(*)
- ----------
- 3000
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3724264953
- ---------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- ---------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 3 | 6 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 3 | | |
- |* 2 | TABLE ACCESS FULL| T1 | 3000 | 9000 | 6 (0)| 00:00:01 |
- ---------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("PERIOD_01"<=6 AND "PERIOD_01">=4)
- SQL> select count(*) from t1 where period_02 between 4 and 6;
- COUNT(*)
- ----------
- 3000
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3724264953
- ---------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- ---------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 3 | 6 (0)| 00:00:01 |
- | 1 | SORT AGGREGATE | | 1 | 3 | | |
- |* 2 | TABLE ACCESS FULL| T1 | 3000 | 9000 | 6 (0)| 00:00:01 |
- ---------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - filter("PERIOD_02"<=6 AND "PERIOD_02">=4)
4、函数索引
[sql] view plain copy print?
- SQL> create index idx_t1_PERIOD_01 on t1(upper(PERIOD_01));
- 索引已创建。
- SQL> select i.index_name,i.index_type from user_indexes i;
- INDEX_NAME INDEX_TYPE
- ------------------------------ ---------------------------
- IDX_T1_PERIOD_01 FUNCTION-BASED NORMAL
- SQL> select c.TABLE_NAME,c.COLUMN_NAME from user_tab_cols c;
- TABLE_NAME COLUMN_NAME
- ------------------------------ ------------------------------
- T1 PERIOD_01
- T1 PERIOD_02
- T1 SYS_NC00003$
需要牢记的是,如果创建了一个基于函数的索引,那么实际上是在虚拟列上创建了索引,当收集关于该表及其索引的统计信息时,同时也就收集了虚拟列上的统计信息。这在类似情况下,诸如upper(PERIOD_01)='xxx'的谓词将被优化为:SYS_NC00003$='xxx'。
5、相互关联的列
如果在谓词中使用相互依赖(相关)的列容易将问题复杂化,前提是这些相关联的列同时出现在where子句中。
[sql] view plain copy print?
- SQL> create table t1
- 2 nologging
- 3 as
- 4 select
- 5 trunc(dbms_random.value(0,25))n1,
- 6 rpad('x',40)ind_pad,
- 7 trunc(dbms_random.value(0,20))n2,
- 8 lpad(rownum,10,'0')small_vc,
- 9 rpad('x',200)padding
- 10 from
- 11 all_objects
- 12 where
- 13 rownum <= 10000
- 14 ;
- 表已创建。
- SQL> update t1 set n2 = n1;
- 已更新10000行。
- SQL> commit;
- 提交完成。
- SQL> begin
- 2 dbms_stats.gather_table_stats(
- 3 ownname => user,
- 4 tabname=> 'T1',
- 5 cascade=> true,
- 6 estimate_percent => null,
- 7 method_opt => 'for all columns size 1'
- 8 );
- 9 end;
- 10 /
- PL/SQL 过程已成功完成。
- SQL> set autotrace traceonly;
- SQL> select small_vc
- 2 from t1
- 3 where n1 = 2
- 4 and n2 = 2;
- 已选择420行。
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3617692013
- --------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- --------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 16 | 272 | 66 (0)| 00:00:01 |
- |* 1 | TABLE ACCESS FULL| T1 | 16 | 272 | 66 (0)| 00:00:01 |
- --------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 1 - filter("N1"=2 AND "N2"=2)
- 统计信息
- ----------------------------------------------------------
- 1 recursive calls
- 0 db block gets
- 401 consistent gets
- 0 physical reads
- 0 redo size
- 9059 bytes sent via SQL*Net to client
- 712 bytes received via SQL*Net from client
- 29 SQL*Net roundtrips to/from client
- 0 sorts (memory)
- 0 sorts (disk)
- 420 rows processed
根据以上执行计划,CBO估算将会返回16行数据,实际确实返回了420行,如果这个表要与多表关联,基数一旦算错,必然导致整个SQL的执行计划全部出错,从而导致SQL性能下降。
接下来再次在相关列上执行查询,不过sql语句中包含了dynamic_sampling提示。
[sql] view plain copy print?
- SQL> select /*+ dynamic_sampling(t1 1) */
- 2 small_vc
- 3 from t1
- 4 where n1 = 2
- 5 and n2 = 2;
- 已选择420行。
- 执行计划
- ----------------------------------------------------------
- Plan hash value: 3617692013
- --------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- --------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 370 | 6290 | 66 (0)| 00:00:01 |
- |* 1 | TABLE ACCESS FULL| T1 | 370 | 6290 | 66 (0)| 00:00:01 |
- --------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 1 - filter("N1"=2 AND "N2"=2)
- Note
- -----
- - dynamic sampling used for this statement (level=2)
- 统计信息
- ----------------------------------------------------------
- 0 recursive calls
- 0 db block gets
- 401 consistent gets
- 0 physical reads
- 0 redo size
- 9059 bytes sent via SQL*Net to client
- 712 bytes received via SQL*Net from client
- 29 SQL*Net roundtrips to/from client
- 0 sorts (memory)
- 0 sorts (disk)
- 420 rows processed
没有直方图的执行计划预估结果集行数计算公式
公式摘抄于《催华-基于ORACLE的SQL优化》
转载请注明链接地址:http://blog.csdn.net/launch_225/article/details/25432661
[html] view plain copy print?
- SQL> select * from t1;
- N1 V1
- ---------- --------
- 1 a
- 2 b
- 2 c
- 4 c
- 5 d
- 6 e
- 6 f
- 6 f
- 9 g
- 10 h
- 11 i
- N1 V1
- ---------- --------
- 12 i
- 12 i
- 14 j
- 15 k
- 16 l
- 16 m
- 18 n
- 18 rows selected.
create index idx_t1_n1 on t1(n1);
[html] view plain copy print?
- 1. ====>没有直方图的预估结果集行数
- SQL> select count(1) from t1;
- COUNT(1)
- ----------
- 18
- SQL> select count(distinct n1) from t1;
- COUNT(DISTINCTN1)
- -----------------
- 13
- SQL> select min(n1),max(n1) from t1;
- MIN(N1) MAX(N1)
- ---------- ----------
- 1 18
- TABLE_NAME COLUMN_NAME DENSITY NUM_BUCKETS HISTOGRAM
- 1 T1 N1 0.0769230769230769 1 NONE
- 2 T1 V1 0.0714285714285714 1 NONE
- 1.1=>范围查询
- ------------------------------------------------------------------------------
- (1)目标列大于指定的val,且位于low_value and high_value之间
- selectivity=((HIGH_VALUE-VAL)/(HIGH_VALUE-LOW_VALUE))* NULL_ADJUST
- NULL_ADJUST=(NUM_ROWS-NUM_NULLS)/NUM_ROWS
- SQL> select ((18-5)/(18-1))*1*18 from dual;
- ((18-5)/(18-1))*1*18
- --------------------
- 13.7647059
- 1* select * from t1 where n1>5
- SQL> /
- Execution Plan
- ----------------------------------------------------------
- Plan hash value: 1577308413
- -----------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -----------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 14 | 70 | 2 (0)| 00:00:01 |
- | 1 | TABLE ACCESS BY INDEX ROWID| T1 | 14 | 70 | 2 (0)| 00:00:01 |
- |* 2 | INDEX RANGE SCAN | IDX_T1_N1 | 14 | | 1 (0)| 00:00:01 |
- -----------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("N1">5)
- (2)目标列小于指定的val,且位于low_value and high_value之间
- selectivity=((VAL-LOW_VALUE)/(HIGH_VALUE-LOW_VALUE))* NULL_ADJUST
- NULL_ADJUST=(NUM_ROWS-NUM_NULLS)/NUM_ROWS
- SQL> select ((5-1)/(18-1))*1*18 from dual;
- ((5-1)/(18-1))*1*18
- -------------------
- 4.23529412
- SQL> select * from t1 where n1<5
- 2 /
- Execution Plan
- ----------------------------------------------------------
- Plan hash value: 1577308413
- -----------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -----------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 4 | 20 | 2 (0)| 00:00:01 |
- | 1 | TABLE ACCESS BY INDEX ROWID| T1 | 4 | 20 | 2 (0)| 00:00:01 |
- |* 2 | INDEX RANGE SCAN | IDX_T1_N1 | 4 | | 1 (0)| 00:00:01 |
- -----------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("N1"<5)
- (3)目标列>=指定的val,且位于low_value and high_value之间
- selectivity=((HIGH_VALUE-VAL)/(HIGH_VALUE-LOW_VALUE)+1/NUM_DISTINCT)* NULL_ADJUST
- NULL_ADJUST=(NUM_ROWS-NUM_NULLS)/NUM_ROWS
- SQL> select ((18-5)/(18-1)+1/13)*1*18 from dual;
- ((18-5)/(18-1)+1/13)*1*18
- -------------------------
- 15.1493213
- SQL> select * from t1 where n1>=5;
- Execution Plan
- ----------------------------------------------------------
- Plan hash value: 1577308413
- -----------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -----------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 15 | 75 | 2 (0)| 00:00:01 |
- | 1 | TABLE ACCESS BY INDEX ROWID| T1 | 15 | 75 | 2 (0)| 00:00:01 |
- |* 2 | INDEX RANGE SCAN | IDX_T1_N1 | 15 | | 1 (0)| 00:00:01 |
- -----------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("N1">=5)
- (4)目标列<=指定的val,且位于low_value and high_value之间
- selectivity=((VAL-LOW_VALUE)/(HIGH_VALUE-LOW_VALUE)+1/NUM_DISTINCT)* NULL_ADJUST
- NULL_ADJUST=(NUM_ROWS-NUM_NULLS)/NUM_ROWS
- SQL> select ((5-1)/(18-1)+1/13)*1*18 from dual;
- ((5-1)/(18-1)+1/13)*1*18
- ------------------------
- 5.6199095
- SQL> select * from t1 where n1<=5;
- Execution Plan
- ----------------------------------------------------------
- Plan hash value: 1577308413
- -----------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -----------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 6 | 30 | 2 (0)| 00:00:01 |
- | 1 | TABLE ACCESS BY INDEX ROWID| T1 | 6 | 30 | 2 (0)| 00:00:01 |
- |* 2 | INDEX RANGE SCAN | IDX_T1_N1 | 6 | | 1 (0)| 00:00:01 |
- -----------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("N1"<=5)
- (5)列位于指定值VAL1和VAL2之间,且VAL1和VAL2在LOW_VALUE和HIGH_VALUE范围
- selectivity=((val2-val1)/(HIGH_VALUE-LOW_VALUE)+2/NUM_DISTINCT)* NULL_ADJUST
- NULL_ADJUST=(NUM_ROWS-NUM_NULLS)/NUM_ROWS
- SQL> select ((10-5)/(18-1)+2/13)*1*18 from dual;
- ((10-5)/(18-1)+2/13)*1*18
- -------------------------
- 8.06334842
- SQL> select * from t1 where n1 between 5 and 10;
- Execution Plan
- ----------------------------------------------------------
- Plan hash value: 1577308413
- -----------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -----------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 8 | 40 | 2 (0)| 00:00:01 |
- | 1 | TABLE ACCESS BY INDEX ROWID| T1 | 8 | 40 | 2 (0)| 00:00:01 |
- |* 2 | INDEX RANGE SCAN | IDX_T1_N1 | 8 | | 1 (0)| 00:00:01 |
- -----------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("N1">=5 AND "N1"<=10)
- ------------------------------------------------------------------------------
- 1.2 =》等值查询
- (1) 等值查询且列上没有NULL值没有直方图的计算公式
- selectivity_without_null=(1/num_distinct)
- SQL> select 1/13*18 from dual;
- 1/13*18
- ----------
- 1.38461538
- SQL> select * from t1 where n1=8;
- Execution Plan
- ----------------------------------------------------------
- Plan hash value: 1577308413
- -----------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -----------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 5 | 2 (0)| 00:00:01 |
- | 1 | TABLE ACCESS BY INDEX ROWID| T1 | 1 | 5 | 2 (0)| 00:00:01 |
- |* 2 | INDEX RANGE SCAN | IDX_T1_N1 | 1 | | 1 (0)| 00:00:01 |
- -----------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("N1"=8)
- (2)目标列没有直方图且有NULL值(通用于没有直方图时列的选择率的计算)
- selectivity_with_null=(1/num_distinct) * ((num_rows-num_nulls)/num_rows)
- SQL> select 1/13*((18-0)/18)*18 from dual;
- 1/13*((18-0)/18)*18
- -------------------
- 1.38461538
- --不存在空值也通用
- SQL> select * from t1 where n1=8;
- Execution Plan
- ----------------------------------------------------------
- Plan hash value: 1577308413
- -----------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -----------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 5 | 2 (0)| 00:00:01 |
- | 1 | TABLE ACCESS BY INDEX ROWID| T1 | 1 | 5 | 2 (0)| 00:00:01 |
- |* 2 | INDEX RANGE SCAN | IDX_T1_N1 | 1 | | 1 (0)| 00:00:01 |
- -----------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("N1"=8)
等频直方图预估结果集行计算公式
公式:摘自《催华-基于ORACLE的SQL优化》
链接地址:http://blog.csdn.net/launch_225/article/details/25472129
等频:唯一值《=桶数
[html] view plain copy print?
- =>等频(频率)直方图
- -->density计算
- density=1/(2*num_rows*null_adjust)
- null_adjust=(num_rows-num_nulls)/num_rows
- -->等值查询,val在low_value and high_value之间,值等于某个endpoint_value
- cardinality=num_rows * selectivity
- selectivity=bucketsize/num_rows
- bucketsize=current_endpoint_number-previous_endpoint_number
- TABLE_NAME COLUMN_NAME NUM_BUCKETS LOW_VALUE HIGH_VALUE HISTOGRAM
- 1 T1 N1 13 C102 C113 FREQUENCY
- -->density计算
- density=1/(2*num_rows*null_adjust)
- SQL> select 1/(2*18*1) from dual;
- 1/(2*18*1)
- ----------
- .027777778
- OWNER TABLE_NAME NUM_DISTINCT DENSITY COLUMN_NAME
- 1 AIKI T1 13 0.0277777777777778 N1
- -->等值查询,val在low_value and high_value之间,值等于某个endpoint_value
- cardinality=num_rows * selectivity
- selectivity=bucketsize/num_rows
- bucketsize=current_endpoint_number-previous_endpoint_number
- 1* select * from t1 where n1=6
- SQL> /
- Execution Plan
- ----------------------------------------------------------
- Plan hash value: 1577308413
- -----------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -----------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 3 | 15 | 2 (0)| 00:00:01 |
- | 1 | TABLE ACCESS BY INDEX ROWID| T1 | 3 | 15 | 2 (0)| 00:00:01 |
- |* 2 | INDEX RANGE SCAN | IDX_T1_N1 | 3 | | 1 (0)| 00:00:01 |
- -----------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("N1"=6)
- OWNER TABLE_NAME COLUMN_NAME ENDPOINT_NUMBER ENDPOINT_VALUE
- AIKI T1 N1 1 1
- AIKI T1 N1 3 2
- AIKI T1 N1 4 4
- AIKI T1 N1 5 5 --previous_endpoint_number
- AIKI T1 N1 8 6 --current_endpoint_number
- AIKI T1 N1 9 9
- AIKI T1 N1 10 10
- AIKI T1 N1 11 11
- AIKI T1 N1 13 12
- AIKI T1 N1 14 14
- AIKI T1 N1 15 15
- AIKI T1 N1 17 16
- AIKI T1 N1 18 18
- bucketsize=8-5=3;
- selectivity=3/18
- cardinality=18*(3/18)=3;
等高直方图预估结果集行计算公式
摘自《催华-基于ORACLE的SQL优化》
链接地址:http://blog.csdn.net/launch_225/article/details/25474427
[html] view plain copy print?
- SQL> desc t1
- Name Null? Type
- ----------------------------------------- -------- ----------------------------
- N1 NUMBER
- V1 VARCHAR2(8)
- SQL> select * from t1;
- N1 V1
- ---------- --------
- 1 a
- 2 b
- 2 c
- 4 c
- 5 d
- 6 e
- 6 f
- 6 f
- 9 g
- 10 h
- 11 i
- 12 i
- 12 i
- 14 j
- 15 k
- 16 l
- 16 m
- 18 n
- 18 rows selected.
- TABLE_NAME COLUMN_NAME NUM_BUCKETS LOW_VALUE HIGH_VALUE HISTOGRAM
- 1 T1 N1 10 C102 C113 HEIGHT BALANCED
- OWNER TABLE_NAME COLUMN_NAME ENDPOINT_NUMBER ENDPOINT_VALUE
- 1 AIKI T1 N1 0 1
- 2 AIKI T1 N1 1 2
- 3 AIKI T1 N1 2 4
- 4 AIKI T1 N1 4 6
- 5 AIKI T1 N1 5 10
- 6 AIKI T1 N1 6 12
- 7 AIKI T1 N1 7 14
- 8 AIKI T1 N1 8 15
- 9 AIKI T1 N1 9 16
- 10 AIKI T1 N1 10 18
- 1.查询值为popular value:
- cardinality=num_rows * SELECTIVITY
- SELECTIVITY=(BUCKETS_THIS_POPULAR_VALUE/BUCKETS_TOTAL)* NULL_ADJUST
- NULL_ADJUST=(NUM_ROWS-NUM_NULLS)/NUM_ROWS
- BUCKETS_THIS_POPULAR_VALUE:POPULAR VALUE所点的bucket的数量,buckets_total:bucket的总数
- select * from t1 where n1=6;
- SELECTIVITY=(2/10)*1
- SQL> select (2/10)*1*18 from dual;
- (2/10)*1*18
- -----------
- 3.6
- SQL> select * from t1 where n1=6;
- Execution Plan
- ----------------------------------------------------------
- Plan hash value: 1577308413
- -----------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -----------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 4 | 20 | 2 (0)| 00:00:01 |
- | 1 | TABLE ACCESS BY INDEX ROWID| T1 | 4 | 20 | 2 (0)| 00:00:01 |
- |* 2 | INDEX RANGE SCAN | IDX_T1_N1 | 4 | | 1 (0)| 00:00:01 |
- -----------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("N1"=6)
- --2.非popular value
- --(>=10.2.0.4版本)
- selectivity=newdensity * null_adjust
- null_adjust=(num_rows-num_nulls)/num_rows
- newdensity=(buckets_total-buckets_all_popular_values)/buckets_total/(ndv-popular_value.count)
- olddensity=sum(np.count(i) * np.count(i))/((num_rows-num_nulls)* sum(np.count(i)))
- ndv=num_distinct
- olddensity存储在dba_***_col_statistics的density中
- buckets_all_popular_values:所有的pupular value所占的bucket的数量,buckets_total:bucket的总数
- popular_values.count:pupular value的个数,NP.count(i):每个nopopular value在目标表中的记录数
- newdensity=(10-(4-2))/10/(13-1)
- selectivity=(10-(4-2))/10/(13-1)
- cardinality=(10-(4-2))/10/(13-1)*18
- SQL> select (10-(4-2))/10/(13-1)*18 from dual;
- (10-(4-2))/10/(13-1)*18
- -----------------------
- 1.2
- SQL> select * from t1 where n1=12; --12为非popular value
- Execution Plan
- ----------------------------------------------------------
- Plan hash value: 1577308413
- -----------------------------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
- -----------------------------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 1 | 5 | 2 (0)| 00:00:01 |
- | 1 | TABLE ACCESS BY INDEX ROWID| T1 | 1 | 5 | 2 (0)| 00:00:01 |
- |* 2 | INDEX RANGE SCAN | IDX_T1_N1 | 1 | | 1 (0)| 00:00:01 |
- -----------------------------------------------------------------------------------------
- Predicate Information (identified by operation id):
- ---------------------------------------------------
- 2 - access("N1"=12)
- --2.1.版本10.2.0.4(不含10.2.0.4,10.2.0.1)以上版本
- selectivity=olddensity * null_adjust
- null_adjust=(num_rows-num_nulls)/num_rows
- olddensity=sum(np.count(i)* np.count(i))/((num_rows-num_nulls)*sum(np.count(i)))
- olddensity存储在dba_***_col_statistics的density中
- NP.count(i):每个nopopular value在目标表中的记录数
- --2.1版本10.2.0.1
- selectivity=olddensity * null_adjust
- null_adjust=(num_rows-num_nulls)/num_rows
- olddensity=sum(dv.count(i) * dv.count(i))/((num_rows-num_nulls)* sum(dv.count(i)))
- olddensity用于实际计算可选择率和结果集的Cardinality
- olddensity也会存储在数据字典DBA_TAB_COL_STATISTICS,DBA_PART_COL_STATISTICS和DBA_SUBPART_COL_STATISTICS中的DENSITY中
- DV.count(i)表示的是目标列的每个DISTINCT值在目标表中的记录数
About Me
...............................................................................................................................
● 本文作者:小麦苗,只专注于数据库的技术,更注重技术的运用
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-06-02 09:00 ~ 2017-06-30 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。




正文到此结束
- 本文标签: ioc tab 数据库 时间 list client Word constant aix Oracle SDN value QQ群 博客 PL/SQL 专注 测试 tar Menu key 同步 删除 Clustering 模型 update IDE Select 性能问题 http 微信公众号 id 云 CDN 数据 DOM 总结 DDL Logging IO ip UI HTML 开发 统计 图片 mail sql CTO 参数 src 文章 ORM db cat CEO 二维码 dist ACE
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

