【REDO】关于Redo log And archive log 二三事
Oracle数据库运行过程中,难免会遇到调整redo log大小或者增加日志组的情况,当然,还有一些归档日志比redo log小很多的情况,那么我们怎么判断或者怎么计算redo log 的大小呢? Oracle推荐15分钟(20-30分钟也可)就是这样了?
我们先来简单看下两个进程:
LGWR(日志写进程):触发一下条件,LGWR将会把缓冲区内容写入到redo log中
1.用户进程提交一个事务(Commit)
2.日志缓冲区达到1/3范围,或者包含了1MB的缓存重做日志数据
3.要求LGWR切换日志文件
4.出现超时(3秒钟内未活动,则进行一次写操作。)
5.DBWR需要写入的数据的SCN号大于LGWR 记录的SCN号,DBWR 触发LGWR写入
ARCn(归档进程):负责在重做日志文件切换后将已经写满的重做日志文件复制到归档日志文件中,以防止循环写入重做日志文件时将其覆盖。当归档进程没完成工作是,LGWR进程也无法将数据写入到redo log中。
也就是说,一般情况下,增加日志组,可以起到缓解的作用,尽量让归档进程减少对日志写进程的影响, 当然更有效的办法是增加redo log大小,那么这个大小怎么算呢? 例如繁忙阶段每小时生成30个,我们要讲数据库改为每小时生成4个,那么redo log大小理论上是原redo log大小的(30/4)倍,假如原来100M,那么现在需要750M,那么空闲时段也许一小时能够生成一个归档日志就不错,我们会考虑数据库数据的安全性吗?假如有DG、OGG呢?
下面是Oracle给出的一个建议:
意思就是redo log大小100M-几个G不等,大概的建议是20分钟切换一次。
假如使用了一下参数(10g+)
fast_start_mttr_target 实例的恢复时间, 该值默认为0(测试数据库11.0.2.0.4) 目前测试数据库中fast_start_mttr_target=20,redo log 200M,此时请看下面一个视图
其中OPTIMAL_LOGFILE_SIZE 为推荐值,该视图中推荐值为160M,当然该推荐值更多目的是为了实例的恢复时间
关于归档日志的大小比在线日志小问题简单描述:(此处转自:http://www.linuxidc.com/Linux/2015-12/126783.htm)
== 也就是 高 CPU_COUNT和低workload(实际上数据库不一定不繁忙,只是在产生redo的进程很少的情况下)会导致 Archive Log比redo log小很多,而且日志频繁切换。
综上所述, 关于redo log大小,我们根据业务情况、客户需求、系统环境评估一个相对合理的值,个人建议是500M-1G之间(太小切换频繁影响性能,太大对于恢复有影响), 当然,为了节约空间,具体值大小可根据cpu_count /lob_buffer等算出。
ARCn(归档进程):负责在重做日志文件切换后将已经写满的重做日志文件复制到归档日志文件中,以防止循环写入重做日志文件时将其覆盖。当归档进程没完成工作是,LGWR进程也无法将数据写入到redo log中。
也就是说,一般情况下,增加日志组,可以起到缓解的作用,尽量让归档进程减少对日志写进程的影响, 当然更有效的办法是增加redo log大小,那么这个大小怎么算呢? 例如繁忙阶段每小时生成30个,我们要讲数据库改为每小时生成4个,那么redo log大小理论上是原redo log大小的(30/4)倍,假如原来100M,那么现在需要750M,那么空闲时段也许一小时能够生成一个归档日志就不错,我们会考虑数据库数据的安全性吗?假如有DG、OGG呢?
下面是Oracle给出的一个建议:
点击(此处)折叠或打开
- It may not always be possible to provide a specific size recommendation for redo log files, but redo log files in the range of 100 MB to a few gigabytes are considered reasonable. Size online redo log files according to the amount of redo your system generates. A rough guide is to switch log files at most once every 20 minutes
假如使用了一下参数(10g+)
fast_start_mttr_target 实例的恢复时间, 该值默认为0(测试数据库11.0.2.0.4) 目前测试数据库中fast_start_mttr_target=20,redo log 200M,此时请看下面一个视图
其中OPTIMAL_LOGFILE_SIZE 为推荐值,该视图中推荐值为160M,当然该推荐值更多目的是为了实例的恢复时间
点击(此处)折叠或打开
- SQL> select ACTUAL_REDO_BLKS,TARGET_REDO_BLKS,CKPT_BLOCK_WRITES,ESTIMATED_MTTR,OPTIMAL_LOGFILE_SIZE,TARGET_MTTR from v$instance_recovery;
-
- ACTUAL_REDO_BLKS TARGET_REDO_BLKS CKPT_BLOCK_WRITES ESTIMATED_MTTR OPTIMAL_LOGFILE_SIZE TARGET_MTTR
- ---------------- ---------------- ----------------- -------------- -------------------- -----------
- 25 818 1351 9 160 20
关于归档日志的大小比在线日志小问题简单描述:(此处转自:http://www.linuxidc.com/Linux/2015-12/126783.htm)
归档日志的大小是真实的在线日志文件的使用量,也就是在线日志文件切换前其中写入的内容的大小。
但是为了更好的并行减少冲突,Oracle会按每16个CPU分一股(strand),每一股独立从redo buffer以及redo log中分配一块空间,当这一块redo buffer用完,会写入redo log并且继续从redo log中分配相同大小的空间,如果无法分配空闲空间就会进行日志切换,而不管其他strand是否写完。
下面举例子来说明这个算法:
比如CPU的个数是64个,则会有64/16=4个strand
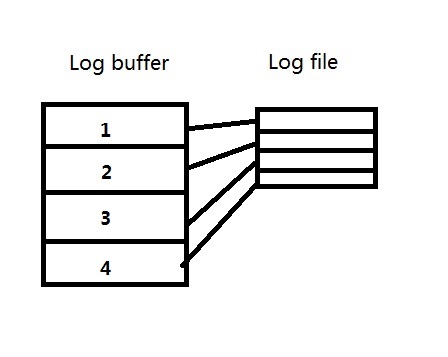
例1)当log buffer的大小和redo log file的大小都是256M的时候,则每个strand都是256M/4=64M。
每一个redo log file被启用时,会预先将redo log file中的大小分配出4个64M与log buffer对应,如图:
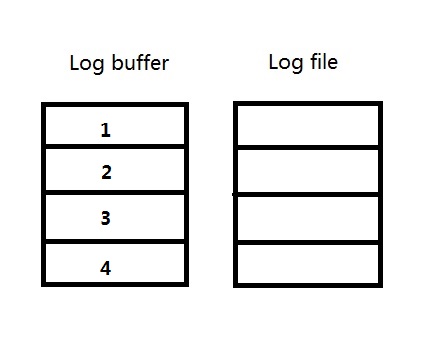
因为log buffer的大小和redo log file的大小都是256M,则redo log file没有剩余的未分配的空间了。
每个进程产生的redo会分配到log buffer上的1,2,3,4其中的某一个strand上,单个进程只能对应一个strand,
这样当数据库中只有某些进程(比如极端的情况,只有某一个进程)产生的redo很多的时候,其中一个strand会快速写满,比如图中的strand 1:
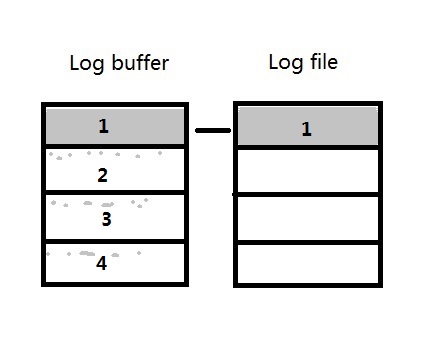
写满之后LGWR会将log buffer中strand 1的内容写入到redo log file中,并且试图从redo log file中分配一个新的64M空间,发现没有了,则将所有strand中的内容写入日志,并作日志切换。
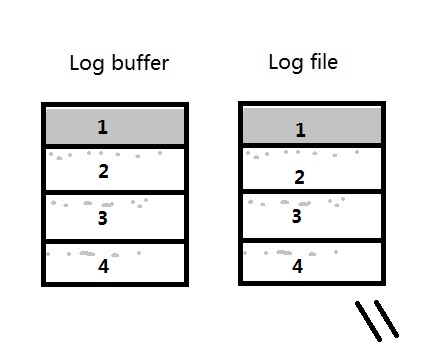
这样,可能会导致redo log file只写入了一个strand的内容,其他部分几乎是空的,则产生的archive log会只接近64M,而不是256M。
当CPU_COUNT很大时,这个差值会更大。
例2)当log buffer的大小是256M,而redo log file的大小是1G的时候,每个strand还是256M/4=64M。
每一个redo log file被启用时,会预先将redo log file中的大小分配出4个64M与log buffer对应,如图:
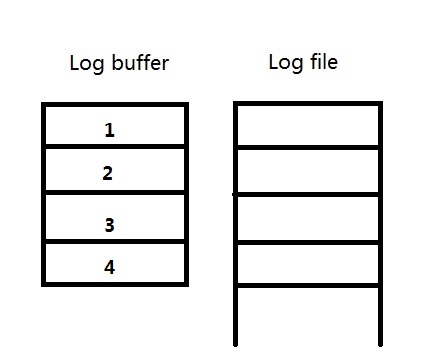
这时,redo log file中还有1G-256M=768M剩余的未分配的空间。
如果strand 1写满之后,LGWR会将log buffer中strand 1的内容写入到redo log file中,并且试图从redo log file中分配一个新的64M空间,然后不断往下写。
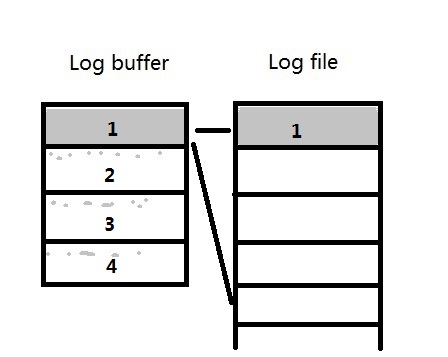
直到redo log file中再没有可分配空间了,则将所有strand中的内容写入日志,并作日志切换。
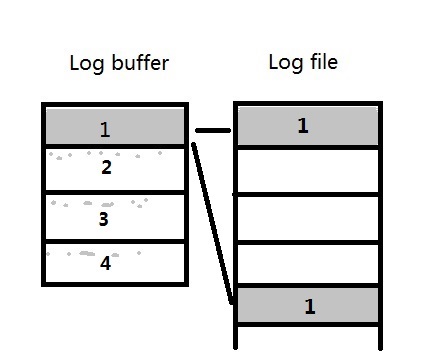
例3)当log buffer的大小是256M,而redo log file的大小是100M的时候,每个strand还是256M/4=64M。
但是redo log file中的空间会按strand的个数平均分配,也就是每块100M/4=25M。
这样,当每个strand中的内容写到25M的时候,就会日志切换,而不是64M。相当于log buffer中的一部分空间被浪费了。
== 也就是 高 CPU_COUNT和低workload(实际上数据库不一定不繁忙,只是在产生redo的进程很少的情况下)会导致 Archive Log比redo log小很多,而且日志频繁切换。
综上所述, 关于redo log大小,我们根据业务情况、客户需求、系统环境评估一个相对合理的值,个人建议是500M-1G之间(太小切换频繁影响性能,太大对于恢复有影响), 当然,为了节约空间,具体值大小可根据cpu_count /lob_buffer等算出。
如有不同建议,还望指出, 技术问题,欢迎拍砖,一起进步
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

