【体系结构】Oracle数据块详解
Oracle数据块详解
操作系统块是操作系统读写的最小操作单元,也是操作系统文件的属性之一。当创建一个Oracle数据库时,选择一个基于操作系统块的整数倍大小作为Oracle数据库块的大小。Oracle数据库读写操作则是以Oracle块为最小单位,而非操作系统块。
数据库块也称逻辑块或Oracle块,它对应磁盘上一个或多个物理块,它的大小由初始化参数DB_BLOCK_SIZE决定,可以定义数据块为2K、4K、8K、16K、32K甚至更大,默认Oracle块大小是8K。若一旦设置了Oracle数据块的大小,则在整个数据库生命期间不能被更改。使用一个合适的Oracle块大小对于数据库的调优是非常重要的。
OS在每次执行I/O的时候是以OS的块为单位;Oracle在每次执行I/O的时候是以Oracle块为单位。Oracle块具有以下特点:
① 最小的I/O单元;
② 包含一个或多个OS块;
③ 大小由参数DB_BLOCK_SIZE决定;
④ 数据库创建时设置,数据库创建后不能更改。
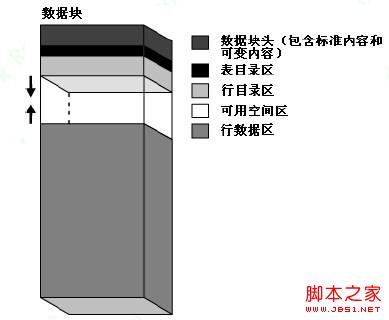
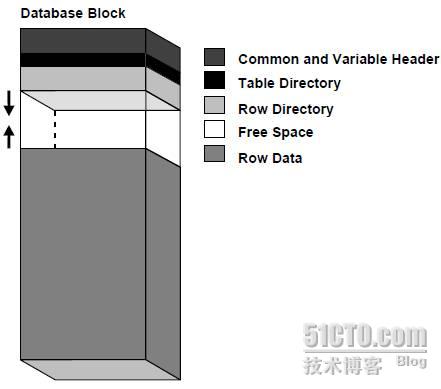
在Oracle中,不论数据块中存储的是表(TABLE)、索引(INDEX)或簇表(CLUSTER TABLE),其内部结构都是类似的。Oracle块的结构如下图所示:
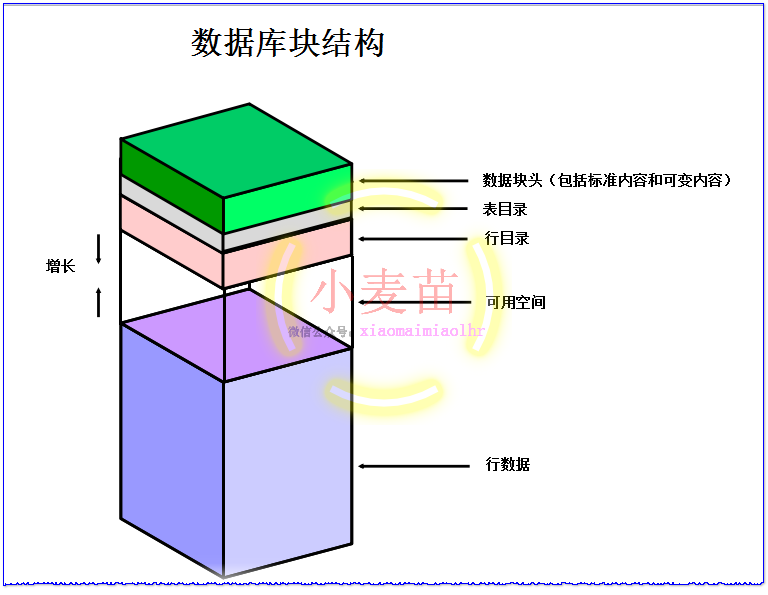
图 3-8 Oracle 块结构图
由上图可以看出,一个Oracle块大约由数据块头(包括标准内容和可变内容,Common And Variable Header)、表目录(Table Directory)、行目录(Row Directory)、可用空间(Free Space)和行数据(Row Data)这几部分组成。图中两个箭头表示一个数据块中的可用空间区的容量是可变的。
●数据块头(Block Header):主要包含有数据块地址的一些基本信息(块地址,Block Address)和段的类型(表段、索引段等)。块头自上而下进行增长。
●表目录(Table Directory):如果一个堆组织表在此数据块中储存了数据行,那么该表的信息将被记录在数据块的表目录中。多个表可以将行存储在相同的块中。
●行目录(Row Directory):此区域包含数据块中存储的数据行的信息,即每个数据行片断(Row Piece)在行数据(Row Data)中的地址。一个数据块中可能保存一个完整的数据行,也可能只保存数据行的一部分。当一个数据块(Data Block)的行目录(Row Directory)空间被使用后,即使数据行被删除(DELETE),行目录空间也不会被回收。举例来说,当一个曾经包含50条记录的数据块被清空后,其块头(Header)的行目录仍然占用100字节(Byte)的空间。仅在块中插入新行时,数据库才会重用此空间。
●可用空间(Free Space):是指可以为以后的更新和插入操作分配的空间,大小由PCTFREE和PCTUSED两个参数影响。可用空间位于块的中部,允许头和行数据空间在必要时进行增长。当插入新行或用更大的值更新现有行的列时,行数据会占用可用空间。导致块头增长的事件包括:行目录需要更多的行条目和需要的事务处理插槽数多于最初配置的数目。块中的可用空间最初是相邻的。但是,删除和更新操作可能会使块中的可用空间变成碎片。
●行数据(Row Data):数据块(Data Block)中行数据(Row Data)包含了表或索引的实际数据。一个数据行可以跨多个数据块。行数据空间自下而上进行增长。
下面介绍一下与数据块存储相关的几个概念。
1、 什么是ASSM和MSSM?
段空间有两种管理方式,分别是手动段空间管理(Manual Segment Space Management,MSSM)和自动段空间管理(Auto Segment Space Management,ASSM)。
自动段空间管理(ASSM),它首次出现在Oracle 9.2中。自由列表FREELIST被位图所取代,它是一个二进制的数组,能够迅速有效地管理存储扩展和剩余区块(Free Block),因此能够改善分段存储本质。ASSM会忽略PCTUSED参数而只使用PCTFREE参数。对于MSSM而言,可以设置FREELIST、PCTUSED和PCTFREE等参数来控制如何分配和使用段中的空间。
2、 FREELIST(自由列表)
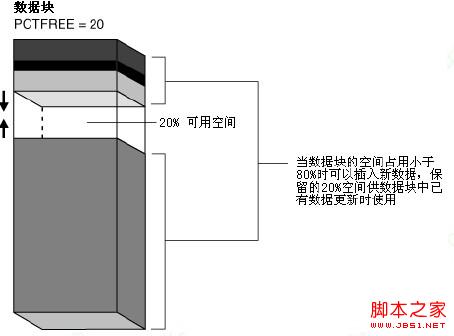
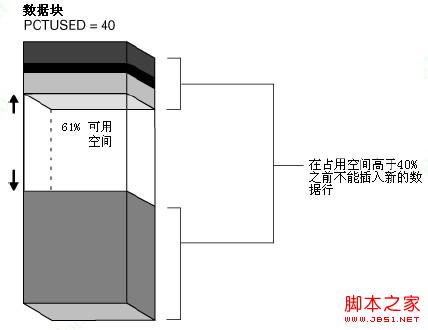
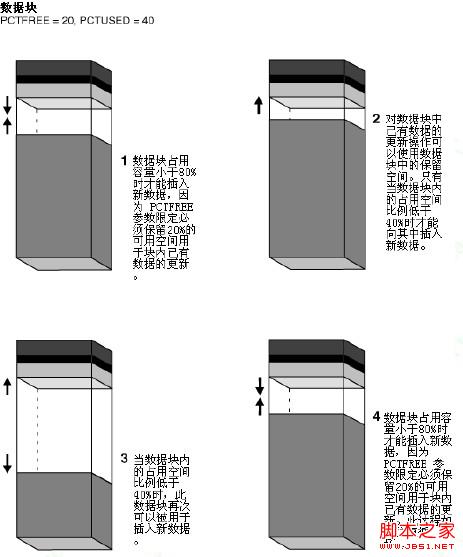
Oracle通过维护FREELIST列表来记录或更新所有可用的数据块。当执行INSERT语句时,Oracle首先在FREELIST列表上搜索可用的空闲数据块,搜索成功之后将数据插入到那个空闲块。块在FREELIST列表中的可用性由PCTFREE参数值来决定。起初一个空块在FREELIST列表上列出,并且会一直保留,直到空闲空间达到PCTFREE设定的值。当一个块被使用且达到PCTFREE设定的值之后,该块将从FREELIST列表被移除,而当数据块的可用空间低于PCTUSED值的时候,该块又会回收,即重新回到FREELIST列表。Oracle使用FREELIST方式以提高数据库性能。因此,每一个INSERT操作,Oracle仅仅需要搜索FREELIST结构,而不是搜索所有数据块。从Oracle 9i开始,引入了ASSM,它让Oracle自动管理FREELIST。在ASSM里,Oracle使用位图方式来标记数据块是否可用,这种数据块的空间管理方式比用一个列表来管理效率更高。
3、 PCTFREE(空闲率)和PCTUSED(使用率)
PCTFREE和PCTUSED这两个参数是面试中常问到的概念。它们用来优化数据块空间的使用,控制数据块是否出现在FREELIST中。当创建或者更改任何表和索引的时候,Oracle在空间控制方面使用这两个存储参数。
●PCTFREE:块中保留用于UPDATE操作的空间百分比,当数据占用的空间达到此上限时,新的数据将不能再插入到此块中。当数据块中的FREE空间小于PCTFREE设置的空间时,该数据块从FREELIST中去掉,当块由于DML操作FREE空间大于PCTUSED设置的空间时,该数据库块将被添加在FREELIST链表中。对于表和索引来说,该值默认为10%,通过查询DBA_TABLES或DBA_INDEXES视图的PCT_FREE列可以获取到该属性的值。该值适用于MSSM和ASSM。
●PCTUSED:指定块中数据使用空间的最低百分比;用于为插入一新行数据的最小空间的百分比。这个值决定了块的可用状态。可用状态的块可以执行插入操作,不可用状态的块只能执行删除和修改,可用状态的块被放在FREELIST中。该值只针对表有效,默认值为40%,通过查询DBA_TABLES视图的PCT_USED列可以获取到该属性的值。该值仅适用于MSSM。
若要修改表的PCTFREE和PCTUSED的值,可以使用ALTER语句修改。需要注意的是,修改之后只对新块起作用,若要对表中原有的块起作用,则可以使用MOVE重新组织表,SQL语句如下所示:
ALTER TABLE T_TEST_LHR PCTFREE 20;
ALTER TABLE T_TEST_LHR MOVE;
若要修改索引的PCTFREE的值,可以使用如下的SQL语句:
ALTER INDEX PK_TEST_LHR REBUILD PCTFREE 20;
下面给出一个示例:
SYS@lhrdb> CREATE TABLE TEST_BLOCK_LHR(
2 COL1 CHAR(20),
3 COL2 NUMBER) ;
Table created.
SYS@lhrdb> CREATE INDEX IND_COL1_LHR ON TEST_BLOCK_LHR(COL1);
Index created.
SYS@lhrdb> SELECT T.PCT_FREE,
2 T.PCT_USED,
3 T.INI_TRANS
4 FROM DBA_TABLES T
5 WHERE T.TABLE_NAME ='TEST_BLOCK_LHR';
PCT_FREE PCT_USED INI_TRANS
---------- ---------- ----------
10 40 1
SYS@lhrdb> SELECT T.PCT_FREE,
2 T.ini_trans
3 FROM DBA_INDEXES T
4 WHERE T.TABLE_NAME ='TEST_BLOCK_LHR';
PCT_FREE INI_TRANS
---------- ----------
10 2
SYS@lhrdb> ALTER TABLE TEST_BLOCK_LHR PCTFREE 20 PCTUSED 60;--修改表的PTCFREE和PCTUSED的值
Table altered.
SYS@lhrdb> SELECT T.PCT_FREE,
2 T.PCT_USED,
3 T.INI_TRANS
4 FROM DBA_TABLES T
5 WHERE T.TABLE_NAME ='TEST_BLOCK_LHR';
PCT_FREE PCT_USED INI_TRANS
---------- ---------- ----------
20 60 1
SYS@lhrdb> ALTER TABLE TEST_BLOCK_LHR MOVE;--重新组织表
Table altered.
SYS@lhrdb> ALTER INDEX IND_COL1_LHR REBUILD PCTFREE 20;--修改索引的PTCFREE值
Index altered.
下面详细介绍一下数据库块的dump结构。首先准备如下的表:
CREATE TABLE T_TESTBLOCK_20160926_LHR( ID NUMBER, NAME VARCHAR(4) ) TABLESPACE TS_TESTBLOCKLHR;
INSERT INTO T_TESTBLOCK_20160926_LHR VALUES (1, 'a');
INSERT INTO T_TESTBLOCK_20160926_LHR VALUES (2, 'b');
INSERT INTO T_TESTBLOCK_20160926_LHR VALUES (3, 'c');
COMMIT;
SYS@lhrdb> SELECT ROWID,DBMS_ROWID.ROWID_RELATIVE_FNO(ROWID) REL_FNO,DBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID) BLOCKNO FROM T_TESTBLOCK_20160926_LHR;
ROWID REL_FNO BLOCKNO
------------------ ---------- ----------
AAAXh8AAHAAAACDAAA 7 131
AAAXh8AAHAAAACDAAB 7 131
AAAXh8AAHAAAACDAAC 7 131
可以看到这3行数据都在7号数据文件的第131个块。将该数据块dump出来:
SYS@lhrdb> ALTER SYSTEM DUMP DATAFILE 7 BLOCK 131;
System altered.
SYS@lhrdb> SELECT VALUE FROM V$DIAG_INFO WHERE NAME LIKE '%Default%';
VALUE
--------------------------------------------------------------------------------
/oracle/app/oracle/diag/rdbms/lhrdb/lhrdb/trace/lhrdb_ora_12386484.trc
以下是该数据块的完整dump结果:
[LHRDB1:oracle]:/oracle/app/oracle/diag/rdbms/lhrdb/lhrdb/trace>more lhrdb_ora_12386484.trc
Trace file /oracle/app/oracle/diag/rdbms/lhrdb/lhrdb/trace/lhrdb_ora_12386484.trc
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP,
Data Mining and Real Application Testing options
ORACLE_HOME = /oracle/app/oracle/product/11.2.0/db
System name: AIX
Node name: LHRDB1
Release: 1
Version: 7
Machine: 00F63A614C00
Instance name: lhrdb
Redo thread mounted by this instance: 1
Oracle process number: 30
Unix process pid: 12386484, image: oracle@LHRDB1 (TNS V1-V3)
*** 2016-09-26 11:33:32.934
*** SESSION ID:(190.1277) 2016-09-26 11:33:32.934
*** CLIENT ID:() 2016-09-26 11:33:32.934
*** SERVICE NAME:(SYS$USERS) 2016-09-26 11:33:32.934
*** MODULE NAME:(sqlplus@LHRDB1 (TNS V1-V3)) 2016-09-26 11:33:32.934
*** ACTION NAME:() 2016-09-26 11:33:32.934
*** TRACE FILE RECREATED AFTER BEING REMOVED ***
Start dump data blocks tsn: 8 file#:7 minblk 131 maxblk 131
Block dump from cache:
Dump of buffer cache at level 4 for tsn=8 rdba=29360259
BH (0x700010023ff51d0) file#: 7 rdba: 0x01c00083 (7/131) class: 1 ba: 0x700010023ee4000
set: 19 pool: 3 bsz: 8192 bsi: 0 sflg: 1 pwc: 41,22
dbwrid: 0 obj: 96380 objn: 96380 tsn: 8 afn: 7 hint: f
hash: [0x7000100627ed2a0,0x7000100627ed2a0] lru: [0x700010023ff6640,0x700010023ff5a10]
ckptq: [NULL] fileq: [NULL] objq: [0x70001005dfd2cf0,0x70001005dfd2cf0] objaq: [0x70001005dfd2ce0,0x70001005dfd2ce0]
st: XCURRENT md: NULL fpin: 'ktspbwh2: ktspfmdb' tch: 2
flags: block_written_once redo_since_read
LRBA: [0x0.0.0] LSCN: [0x0.0] HSCN: [0xffff.ffffffff] HSUB: [1]
Block dump from disk:
buffer tsn: 8 rdba: 0x01c00083 (7/131)
scn: 0x0000.00752951 seq: 0x01 flg: 0x06 tail: 0x29510601
frmt: 0x02 chkval: 0x4235 type: 0x06=trans data
Hex dump of block: st=0, typ_found=1
Dump of memory from 0x0000000110ADCC00 to 0x0000000110ADEC00
110ADCC00 06A20000 01C00083 00752951 00000106 [.........u)Q....]
110ADCC10 42350000 01000007 0001787C 00752950 [B5........x|.u)P]
110ADCC20 00000000 00023200 01C00080 00080002 [......2.........]
110ADCC30 000009E9 00C0108B 04AC2400 20030000 [..........$. ...]
110ADCC40 00752951 00000000 00000000 00000000 [.u)Q............]
110ADCC50 00000000 00000000 00000000 00000000 [................]
110ADCC60 00000000 00010003 FFFF0018 1F801F65 [...............e]
110ADCC70 1F650000 00031F90 1F881F80 00000000 [.e..............]
110ADCC80 00000000 00000000 00000000 00000000 [................]
Repeat 501 times
110ADEBE0 00000000 2C010202 C1040163 2C010202 [....,......c,...]
110ADEBF0 C1030162 2C010202 C1020161 29510601 [...b,......a)Q..]
Block header dump: 0x01c00083
Object id on Block? Y
seg/obj: 0x1787c csc: 0x00.752950 itc: 2 flg: E typ: 1 - DATA
brn: 0 bdba: 0x1c00080 ver: 0x01 opc: 0
inc: 0 exflg: 0
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0008.002.000009e9 0x00c0108b.04ac.24 --U- 3 fsc 0x0000.00752951
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
bdba: 0x01c00083
data_block_dump,data header at 0x110adcc64
===============
tsiz: 0x1f98
hsiz: 0x18
pbl: 0x110adcc64
76543210
flag=--------
ntab=1
nrow=3
frre=-1
fsbo=0x18
fseo=0x1f80
avsp=0x1f65
tosp=0x1f65
0xe:pti[0] nrow=3 offs=0
0x12:pri[0] offs=0x1f90
0x14:pri[1] offs=0x1f88
0x16:pri[2] offs=0x1f80
block_row_dump:
tab 0, row 0, @0x1f90
tl: 8 fb: --H-FL-- lb: 0x1 cc: 2
col 0: [ 2] c1 02
col 1: [ 1] 61
tab 0, row 1, @0x1f88
tl: 8 fb: --H-FL-- lb: 0x1 cc: 2
col 0: [ 2] c1 03
col 1: [ 1] 62
tab 0, row 2, @0x1f80
tl: 8 fb: --H-FL-- lb: 0x1 cc: 2
col 0: [ 2] c1 04
col 1: [ 1] 63
end_of_block_dump
End dump data blocks tsn: 8 file#: 7 minblk 131 maxblk 131
下面对该dump内容做详细解说:
一、块头信息区
首先看头部信息区分析:
Block dump from disk:
buffer tsn: 8 rdba: 0x01c00083 (7/131)
scn: 0x0000.00752951 seq: 0x01 flg: 0x06 tail: 0x29510601
frmt: 0x02 chkval: 0x4235 type: 0x06=trans data
① buffer tsn: 8 表示该块对应的表空间号,这里是8号表空间
② rdba: 0x01c00083 (7/131) 其中,rdba(relative data block address)表示相对数据块地址,其中(7/131)表示该块为7号数据文件第131个块,用4个字节32位来表示,前10位为相对数据文件号,后22位为块号。01c00083(十六进制)=0000 0001 1100 0000 0000 0000 1000 0011(二进制),不难看出前10位(0000 0001 11)转换成十进制就是7,后22位(00 0000 0000 0000 1000 0011)转换成十进制就是131。rdba在数据块中的offset是4,即rdba存在于数据块中的第5-9字节中(offset从0开始算),数据块中的每个部分在数据块中的偏移量通过BBED可以展示出来
③ scn: 0x0000.00752951 表示数据块头部SCN,总共占用6个字节,前2个字节(0000)表示SCN Wrap,后4个字节(00752951)表示SCN Base。如果SCN Base达到了4个字节表示的最大值,SCN Wrap+1,SCN Base清0。在数据块中的offset是8。这里的SCN号为7678289
④ seq: 0x01 表示Sequence number即日志序列号。在数据块中的offset是14
⑤ flg: 0x06 flg即Flag,其中,0x01代表New block即新建块;0x02代表Delayed Logging Change advanced SCN即数据块延迟清洗推进scn和seq;0x04代表Check value即设置校验和;0x08代表Temporary block即临时块。其它值都是01、02、04、08的组合。在数据块中的offset是15
⑥ tail: 0x29510601 即tail check,存放于数据块的最后4个字节,用于数据块一致性检查。tail check的组成:SCN Base的低2个字节+type+seq。即tail:0x32d30601=32d3+06+01
⑦ frmt: 0x02 代表块格式。01表示Oracle 7,02表示Oracle 8+
⑧ chkval: 0x4235 代表块检查值。如果参数DB_BLOCK_CHECKSUM=TRUE,那么数据块在读入buffer和写回数据文件之前都要做检查计算,如果计算值和数据块中记录的计算值不匹配就会标记该块是坏块
⑨ type: 0x06=trans data 代表块类型,参考以下的表格:
|
ID |
Type |
|
01 |
Undo segment header |
|
02 |
Undo data block |
|
03 |
Save undo header |
|
04 |
Save undo data block |
|
05 |
Data segment header (temp, index, data and so on) |
|
06 |
KTB managed data block (with ITL) |
|
07 |
Temp table data block (no ITL) |
|
08 |
Sort Key |
|
09 |
Sort Run |
|
10 |
Segment free list block |
|
11 |
Data file header |
二、事务列表区
Block header dump: 0x01c00083
Object id on Block? Y
seg/obj: 0x1787c csc: 0x00.752950 itc: 2 flg: E typ: 1 - DATA
brn: 0 bdba: 0x1c00080 ver: 0x01 opc: 0
inc: 0 exflg: 0
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0008.002.000009e9 0x00c0108b.04ac.24 --U- 3 fsc 0x0000.00752951
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
①、Object id on Block? Y 表示该块是否属于某个对象
②、seg/obj: 0x1787c 表示该数据块中对象的OBJECT_ID。本示例dump的是表T_TESTBLOCK_20160926_LHR,下面来验证一下:
SYS@lhrdb> select to_number('1787c','xxxxxx') from dual;
TO_NUMBER('1787C','XXXXXX')
---------------------------
96380
SYS@lhrdb> select object_name,object_type from dba_objects where object_id=96380;
OBJECT_NAME OBJECT_TYPE
---------------------------- -------------------
T_TESTBLOCK_20160926_LHR TABLE
③、csc: 0x00.752950 表示SCN at last Block CleanOut,表示最后一次块清除(Block CleanOut)时候的SCN
④、itc: 2 块中ITL slot的数量,根据下面的ITL图可以看出的确只有2个ITL slot
⑤、flg: E 0表示此块被放置在自由列表(freelist)中,E指用的是ASSM
⑥、typ: 1 DATA 表示数据库块的类型,1表示数据,2表示索引
⑦、bdba: 0x1c00080 Block relative data block address,相对数据块的地址
接下来的内容属于ITL的范围:

图 3-9 ITL图
ITL(Interested Transaction List,事务槽)是Oracle数据块内部的一个组成部分,用来记录在该块上发生的所有事务。1个ITL可以看作是一个记录,在一个时间,可以记录一个事务(包括提交或者未提交事务)。当然,如果这个事务已经提交,那么这个ITL的位置就可以被反复使用了,因为LTL与记录非常类似,所以,有的时候也叫ITL槽位。
ITL位于数据块头(Block Header),ITL事务槽由槽位号(Itl)、Xid(Transaction ID)、Uba(Undo Block Address)、Flag、Lck和Scn/Fsc几个部分组成。Oracle的每个数据块中都有一个或者多个事务槽,每一个对数据块的并发访问事务都会占用一个事务槽。对于已经提交的事务,ITL槽位不会马上被覆盖,因为一致性读可能会用到这个信息,一致性读的时候,可能需要从这里获得回滚段的入口,并从回滚段中获得一致性读。
当发出一条SQL语句时,Oracle会记录下这个时刻的SCN,然后在Buffer Cache中查找需要的BLOCK,或者从磁盘上读。当别的会话修改了数据,或者正在修改数据时,就会在相应的块上记录ITL,此时Oracle发现ITL中记录的SCN大于SELECT时刻的SCN,那么Oracle就会根据ITL中的Uba找到Undo信息获得该BLOCK的前镜像,然后在Buffer Cache中构造出CR(consistent read)块,此时Oralce也会检查构造出来的BLOCK中ITL记录的SCN。如果SCN还大于SELECT时刻的SCN,那么一直重复构造前镜像,然后Oracle找到前镜像BLOCK中的ITL的SCN是否小于SELECT的SCN,同时检查这个事务有没有提交或者回滚。如果没有,那么继续构造前镜像,直到找到需要的BLOCK,如果在构造前镜像的过程中所需的Undo信息被覆盖了,就会报快照过旧的错误。
如果一个事务一直没有提交,那么这个事务将一直占用一个ITL槽位。如果这个事务已经提交,那么,ITL槽位中还保存的有这个事务提交时候的SCN号。
ITL的个数受参数INITRANS控制,最大ITL个数受MAXTRANS控制(Oracle 10g已废弃MAXTRANS,默认最大支持255个并发)。在一个块内部,默认分配了2个ITL的个数。如果这个块内还有空闲空间(Free Space),那么Oracle是可以利用这些空闲空间并再次分配ITL。如果没有了空闲空间,那么这个块会因为不能分配新的ITL可能发生ITL等待,即enq: TX - allocate ITL entry等待事件。
在并发量特别大的系统中,最好分配足够的ITL个数,或者设置足够的PCTFREE,保证ITL能扩展。但是,PCTFREE有可能是被行数据给消耗掉的,如UPDATE,所以,也有可能导致块内部的空间不够而导致ITL等待。对于表(数据块)来说,INITRANS这个参数的默认值是1。对于索引(索引块)来说,这个参数默认值是2。
下面详细介绍ITL的结构:
① Itl:ITL事务槽编号,ITL事务槽号的流水编号
② Xid:代表对应的事务id(transac[X]tion identified),在回滚段事务表中有一条记录和这个事务对应。Xid由3列使用十六进制编码的数字列表示,分别是:Undo Segment Number + Transaction Table Slot Number + Wrap,即由undo段号+undo槽号+undo槽号的覆盖次数三部分组成,即usn.slot.sqn,这里0x0008.002.000009e9转换为10进制为8.2.2537,从下边的查询出的结果是相对应的:
SYS@lhrdb> SELECT XIDUSN,XIDSLOT,XIDSQN,UBAFIL,UBABLK,UBASQN,UBAREC FROM V$TRANSACTION;
XIDUSN XIDSLOT XIDSQN UBAFIL UBABLK UBASQN UBAREC
---------- ---------- ---------- ------- ---------- -------- ----------
8 2 2537 3 4235 1196 36
③ Uba:即Undo Block Address,该事务对应的回滚段地址,记录了最近一次的该记录的前镜像(修改前的值)。Uba组成:Undo块地址(undo文件号和数据块号)+回滚序列号+回滚记录号。多版本一致读是Oracle保证读操作不会被事务阻塞的重要特性。当Server Process需要查询一个正在被事务修改,但是尚未提交的数据时,就根据ITL上的Uba定位到对应Undo前镜像数据位置。这里的Uba为:0x00c0108b.04ac.24,其中00c0108b(16进制)=0000 0000 1100 0000 0001 0000 1000 1011(2进制,共32位,前10位代表文件号,后22位代表数据块号)=文件号为3,块号为4235(10进制);04ac(16进制)=1196(10进制);24(16进制)=36(10进制)。Uba的值可以从V$TRANSACTION查询出来:
SELECT UBAFIL 回滚段文件号,UBABLK 数据块号,UBASQN 回滚序列号,UBAREC 回滚记录号 FROM v$transaction ; --查看UBA
④ Flag:事务标志位,即当前事务槽的状态信息。这个标志位记录了这个事务的操作状态,各个标志的含义分别是:
|
标识 |
简介 |
|
---- |
事务是活动的,未提交,或者在块清除前提交事务。 |
|
C--- |
事务已经提交,锁已经被清除(提交)。 |
|
-B-- |
包含ITL记录的UNDO数据。 |
|
--U- |
事务已经提交,但是锁还没有清除(快速提交)。 |
|
---T |
块清除的SCN被记录时,该事务仍然是活动的,块上如果有已经提交的事务,那么在clean ount的时候,块会被进行清除,但是这个块里面的事务不会被清除。 |
|
C-U- |
块被延迟清除,回滚段的信息已经改写,SCN显示为最小的SCN,需要由回滚段重新生成,例如在提交以前,数据块已经刷新到数据文件上。 |
⑤ Lck:表示这个事务所影响的行数,锁住了几行数据,对应有几个行锁。在这里,可以看到01号事务槽Lck为3,因为该事务槽中的事务Flag为U,证明该事务已经提交,但是锁还没有清除。再比如对于下边这个ITL:
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.020.00000271 0x00800205.0257.13 C--- 0 scn 0x0000.001732c4
0x02 0x0008.006.00000279 0x00800351.0278.15 ---- 1 fsc 0x0000.00000000
看到01号事务槽Lck为0,因为该事务槽中的事务Flag为C,证明该事务已经提交,锁已经被清除,该事务槽可以被重用。02号事务槽Lck为1,是因为对第一行做了一个更新操作,并且没有提交,Flag为“----”说明该事务是活动的。
⑥ Scn/Fsc:Scn表示提交时的SCN。Commit SCN或者快速提交(Fast Commit,Fsc)的SCN。Scn=SCN of commited TX;Fsc=Free space credit(bytes)。每条记录中的行级锁对应Itl条目lb,对应于Itl列表中的序号,即那个事务在该记录上产生的锁。
对于一个Oracle事务来说,可以是快速提交、也可以是延迟提交,目的都是为了提高提交的速度。提交以后,Oracle需要对ITL事务槽、每一行的锁定标记进行清除。如果是快速提交,那么在提交的时候,会将事务表和每一个数据块的ITL槽进行清除。但是锁定标记可能没有清除,等下次用到的时候再进行清除。如果是延迟提交,那么在提交的时候,只是将事务表进行清除,并没有对ITL事务槽进行清除,每一行的锁定标记也没有清除。因此,C和U的情况特别多。块清除的过程并不包括每个行的锁定标记的清除,主要指的是ITL的清除。
注意:
① 事务槽中首先记录的是XID和UBA,只有在提交以后,当对这个数据块进行CLEANOUT的时候,才会更新FLAG和SCN。因此,Oracle总是以事务表中对这个数据块的SCN以及FLAG为准。
② 一个事务开始以后,在一个数据块上得到一个事务槽,那么在这个事务提交以前,这个事务槽会一直占用,直到这个事务提交才会释放这个事务槽。
③ 只有在已经提交以后,这个ITL事务槽中的SCN才会有数值。
④ 事务是否已经提交、事务对应的SCN,这些信息都是以回滚段事务表中的为主,事务槽中的不准确。
⑤ 事务槽中的事务ID和UBA地址是准确的。
⑥ 事务槽中的事务ID和回滚段中的事务ID肯定不是一样的,不同回滚段中的事务ID也一定不一样。
三、用户数据头区(data_block_dump)
行目录(Row Directory)记录了数据块里每一行相对于起点的偏移量,Oracle正是通过行目录找到所需的数据行。
bdba: 0x01c00083
data_block_dump,data header at 0x110adcc64
===============
tsiz: 0x1f98
hsiz: 0x18
pbl: 0x110adcc64
76543210
flag=--------
ntab=1
nrow=3
frre=-1
fsbo=0x18
fseo=0x1f80
avsp=0x1f65
tosp=0x1f65
0xe:pti[0] nrow=3 offs=0
0x12:pri[0] offs=0x1f90
0x14:pri[1] offs=0x1f88
0x16:pri[2] offs=0x1f80
① bdba: 0x01c00083 block dba/rdba(数据块地址),用4个字节32位来表示,前10位为相对数据文件号,后22位为块号。01c00083(十六进制)=0000 0001 1100 0000 0000 0000 1000 0011(二进制),可以看到前10位(0000 0001 11)转换成十进制就是7,后22位(00 0000 0000 0000 1000 0011)转换成十进制就是131,即7号文件131号数据块
② tsiz: 0x1f98 Total Data Area Size(数据区的大小,块的总大小),转换为10进制即8088字节
③ hsiz: 0x18 数据块头大小,转换为10进制即24字节
④ pbl: 0x110adcc64 指向这个数据块在内存中映像的指针
⑤ flag=-------- N=pcrfree hit(clusters);F=do not put on free list;K=flushable cluster keys
⑥ ntab=1 number of tables (>1 is a cluster)
⑦ nrow=3 即行数,这里表示这个表有3行数据
⑧ frre=-1 first free row index entry, -1=you have to add one(没有创建索引)
⑨ fsbo=0x18 free space begin offset(空闲空间起始位置),叫起始空间:可以存放数据空间的起始位置(即定义了数据层中空闲空间的起始offset)
⑩ fseo=0x1f80 free space end offset(空闲空间结束位置),叫结束空间:可以存放数据空间的结束位置(即定义了数据层中空闲空间的结束offset)
? avsp=0x1f65 available space in the block(可用空间),叫空闲空间:定义了数据层中空闲空间的字节数
? tosp=0x1f65 total available space when all txs commit,叫最终空闲空间:定义了ITL中事务提交后,数据层中空闲空间的字节数
? 0xe:pti[0] nrow=3 offs=0 Table directory,整个表的开始,该块有3条记录
? 0x12:pri[0] offs=0x1f5e 第1条记录在偏移量为0x1f5e的地方,下面两行以此类推
? 0x14:pri[1] offs=0x1f66
? 0x16:pri[2] offs=0x1f80
四、用户数据区(block_row_dump)
block_row_dump:
tab 0, row 0, @0x1f90
tl: 8 fb: --H-FL-- lb: 0x1 cc: 2
col 0: [ 2] c1 02
col 1: [ 1] 61
tab 0, row 1, @0x1f88
tl: 8 fb: --H-FL-- lb: 0x1 cc: 2
col 0: [ 2] c1 03
col 1: [ 1] 62
tab 0, row 2, @0x1f80
tl: 8 fb: --H-FL-- lb: 0x1 cc: 2
col 0: [ 2] c1 04
col 1: [ 1] 63
end_of_block_dump
① tab 0, row 0, @0x1f90 第一个表第一行的位置,定义了该表在行索引中的起始插槽号
② lb: 0x1 表示lock byte。锁定该行的这个事务在ITL的入口,0x1说明事务在该数据行上的锁还没清除,并且该锁指向01号事务槽。lb: 0x0说明事务在该数据行上的锁已经被清除
③ tl: 8 表示Row Size(number of bytes plus data)
④ fb Flag Byte
K- Cluster key
H- head of row piece
D- Deleted row
F- first data piece
L- last data piece
P- First column cintinues from previous row N- Last column cintinues in next piece
当DELETE一行数据的时候,数据并不是物理地被删除,而是把该行标记为删除,这个时候fb应该是--HDFL--而不是原来的--H-FL--。
⑤ cc 表示number of columns in this Row piece
关于行中的数据,可以以第一行来说明一下。由于表的第2行数据为(2,'b'),所以可以使用dump函数来验证一下。dump函数可以按指定的格式显示输入数据的内部表示,这里显示16进制:
tl: 8 fb: --H-FL-- lb: 0x1 cc: 2
col 0: [ 2] c1 03
col 1: [ 1] 62
SYS@lhrdb> select dump(2,16),dump('b',16) from dual;
DUMP(2,16) DUMP('B',16)
----------------- ----------------
Typ=2 Len=2: c1,3 Typ=96 Len=1: 62
原文地址:http://blog.csdn.net/yujin2010good/article/details/7747204
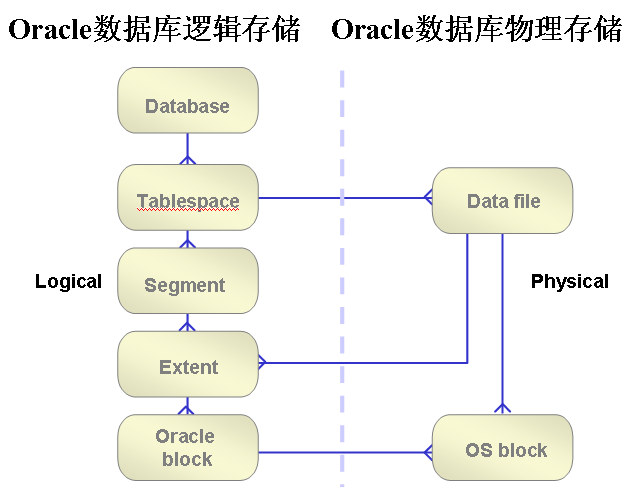
数据库的逻辑结构包括:数据块,区,段,表空间。
oracle数据块是oracle数据库存储基础,有磁盘空间的若干字节组成,数据块是oracle数据库的最小逻辑单元,可以定义数据块为2k、4k、8k、16k、32k甚至更大,默认oracle块大小是8k,通常我们称为oracle块。当然正常情况下oracle块应该是os块的整数倍,当然具有标准大小的块叫做标准块,和标准块不同的块叫做非标准块。同一个数据库中,当然指的是9i以后,支持同一个数据中同时使用标准块和非标准块。
Oracle块大小设置在初始化参数文件里面(init.ora)中的db_block_size中设置,块是处理update、insert、select数据事务的最小单位,当用户从表中选择数据时,将在oracle块上读取或是提取数据。意思就是说:os每次执行i/o时候,是以os的块为单位;oracle每次执行i/o时候,是以oracle块为单位。
总结为一下几点:
? 最小的 I/O单元
? 包含一个或多个 OS块
? DB_BLOCK_SIZE
? 数据库创建时设置,数据库创建后不能更改
Oracle数据块的大小设置意见:
1、 如果行较小且访问随机,则选择小的块尺寸
2、 如果行小且访问连续的,或者有较大的行,则选择较大尺寸的块。
就是说看我们的业务系统。
数据块结构
1、基本组成

块结构说明如下:
块头:存放一些基本信息,如物理位置,块所属的段类型(数据段、索引段、回滚段等)
表目录:如果块中存储的数据为表数据,则表目录中保存这个表的相关信息
行目录:如果块中存储的数据为表数据,则行目录中保存数据行的相关信息。
块头、表目录和行目录组成块的头部信息(overhead),这部分不存数据库中实际的数据,而是用来记录该块的逻辑结构,而且这部分占用的空间不是固定的,大约在84-107字节之间。
行记录:真正存放数据的区域,这部分空间已被使用。
空闲空间:未使用的区域,用于新行的插入或者已经存在行的更新。(这里有个概念行迁移:就是当update操作时,块中空闲的空间不够保存修改的数据,那么记录就将保存到另一个拥有足够空间的块中,而只在原块上保留一条指向新块的rowid,这就是行迁移row migration)
2、自由空间
空闲空间的使用
Insert这时候块的自由空间会减少,
update的时候块的自由空间也会减少
当使用DELETE语句删除块中的记录或者使用UPDATE语句把列的值更改成一个更小值的时候,Oracle会释放出一部分自由空间。释放出的自由空间并不一定是连续的,常情况下,Oracle不会对块中不连续的自由空间进行合并。因为合并数据块中不连续的自由空间会影响数据库的性能。只有当用户进行数据插入(INSERT)或者更新(UPDATE)操作,却找不到连续的自由空间的时候,Oracle才会合并数据块中不连续的自由空间。
3、空闲空间的管理
对于块中的自由空间,Oracle提供两种管理方式:自动管理,手动管理
行链接和行迁移(Row Chaining and Migrating)
行链接(Row Chaining):如果我们往数据库中插入(INSERT)一行数据,这行数据很大,以至于一个数据块存不下一整行,Oracle就会把一行数据分作几段存在几个数据块中,这个过程叫行链接(Row Chaining)。
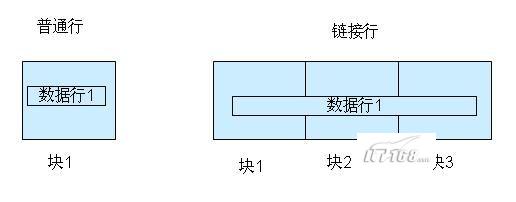
如果一行数据是普通行,这行数据能够存放在一个数据块中;如果一行数据是链接行,这行数据存放在多个数据块中。
行迁移(Row Migrating):数据块中存在一条记录,用户执行UPDATE更新这条记录,这个UPDATE操作使这条记录变长,这时候,Oracle在这个数据块中进行查找,但是找不到能够容纳下这条记录的空间,无奈之下,Oracle只能把整行数据移到一个新的数据块。原来的数据块中保留一个“指针”,这个“指针”指向新的数据块。被移动的这条记录的ROWID保持不变。行迁移的原理如下图所示:
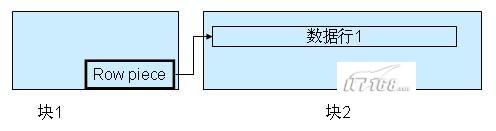
无论是行链接还是行迁移,都会影响数据库的性能。Oracle在读取这样的记录的时候,Oracle会扫描多个数据块,执行更多的I/O。而且是成倍加大i/o。
1)Oracle使用位图(bitmap)来管理和跟踪数据块,这种块的空间管理方式叫“自动管理”。自动管理有下面的好处:
◆易于使用
◆更好地利用空间
◆可以对空间进行实时调整
2)块中自由空间的手动管理(手动管理比较复杂)
用户可以通过PCTFREE, PCTUSED来调整块中空间的使用,这种管理方式叫手动管理。相对于自动管理,手动管理方式比较麻烦,不容易掌握,容易造成块中空间的浪费。
PCTFREE参数用于指定块中必须保留的最小空闲空间百分例。之所以要预留这样的空间,是因为UPDATE时,需要这些空间。如果UPDATE时,没有空余空间,Oracle就会分配一个新的块,这会产生行迁移(Row Migrating)。
PCTUSED也是用于设置一个百分比,当块中已使用的空间的比例小于这个百分比的时候,这个块才被标识为有效状态。只有有效的块才被允许插入数据。
三、基本实验
1)下面我们先来分析一下块。
下面我们来看看这个数据块
dump说明
创建表空间和测试表:
create tablespace testblock datafile '/opt/app/oracle/oradata/wolf/testblock01.dbf' size 100M;
create table testblock(
id number,
name varchar(4)
) tablespace testblock;
插入3条数据然后提交:
SQL> insert into testblock values(1,'a');
SQL> insert into testblock values(2,'b');
SQL> insert into testblock values(3,'c');
SQL> commit;
SQL> select * from testblock;
ID NAME
---------- --------
1 a
2 b
3 c
SQL> commit
SQL> desc V$datafile;
Name Null? Type
----------------------------------------- -------- ----------------------------
FILE# NUMBER
CREATION_CHANGE# NUMBER
CREATION_TIME DATE
TS# NUMBER
RFILE# NUMBER
STATUS VARCHAR2(7)
ENABLED VARCHAR2(10)
CHECKPOINT_CHANGE# NUMBER
CHECKPOINT_TIME DATE
UNRECOVERABLE_CHANGE# NUMBER
UNRECOVERABLE_TIME DATE
LAST_CHANGE# NUMBER
LAST_TIME DATE
OFFLINE_CHANGE# NUMBER
ONLINE_CHANGE# NUMBER
ONLINE_TIME DATE
BYTES NUMBER
BLOCKS NUMBER
CREATE_BYTES NUMBER
BLOCK_SIZE NUMBER
NAME VARCHAR2(513)
PLUGGED_IN NUMBER
BLOCK1_OFFSET NUMBER
AUX_NAME VARCHAR2(513)
FIRST_NONLOGGED_SCN NUMBER
FIRST_NONLOGGED_TIME DATE
SQL> select FILE#,name from v$datafile;
FILE#
----------
NAME
--------------------------------------------------------------------------------
1
/opt/app/oracle/oradata/wolf/system01.dbf
2
/opt/app/oracle/oradata/wolf/undotbs01.dbf
3
/opt/app/oracle/oradata/wolf/sysaux01.dbf
FILE#
----------
NAME
--------------------------------------------------------------------------------
4
/opt/app/oracle/oradata/wolf/users01.dbf
5
/opt/app/oracle/oradata/wolf/testblock01.dbf
SQL> select rowid,dbms_rowid.rowid_relative_fno(rowid) rel_fno,dbms_rowid.rowid_block_number(rowid)
blockno from testblock;
2
ROWID REL_FNO BLOCKNO
------------------ ---------- ----------
AAAMixAAFAAAAAMAAA 5 12
AAAMixAAFAAAAAMAAB 5 12
AAAMixAAFAAAAAMAAC 5 12
SQL> alter system dump datafile 5 block 12;
SQL> show parameter dump;
查找dumping文件位置
[root@test ~]# cd /opt/app/oracle/admin/wolf
[root@test wolf]# ls
adump bdump cdump dpdump pfile udump
[root@test wolf]# cd udump/
[root@test udump]# ls
wolf_ora_18566.trc wolf_ora_19120.trc wolf_ora_4952.trc wolf_ora_5792.trc
wolf_ora_18605.trc wolf_ora_19790.trc wolf_ora_4954.trc wolf_ora_5826.trc
wolf_ora_18608.trc wolf_ora_19818.trc wolf_ora_5721.trc wolf_ora_5833.trc
wolf_ora_19087.trc wolf_ora_19820.trc wolf_ora_5764.trc wolf_ora_5860.trc
wolf_ora_19114.trc wolf_ora_4899.trc wolf_ora_5766.trc wolf_ora_9291.trc
[root@test udump]# ls -l
total 272
-rw-r----- 1 oracle oinstal● 593 Ju● 8 05:56 wolf_ora_18566.trc
-rw-r----- 1 oracle oinstal● 650 Ju● 8 05:56 wolf_ora_18605.trc
-rw-r----- 1 oracle oinstal● 1872 Ju● 8 06:05 wolf_ora_18608.trc
-rw-r----- 1 oracle oinstal● 593 Ju● 8 04:05 wolf_ora_19087.trc
-rw-r----- 1 oracle oinstal● 650 Ju● 8 04:05 wolf_ora_19114.trc
-rw-r----- 1 oracle oinstall 196171 Ju● 8 04:21 wolf_ora_19120.trc
-rw-r----- 1 oracle oinstal● 593 Ju● 8 06:29 wolf_ora_19790.trc
-rw-r----- 1 oracle oinstal● 650 Ju● 8 06:29 wolf_ora_19818.trc
-rw-r----- 1 oracle oinstal● 3331 Ju● 8 11:08 wolf_ora_19820.trc
-rw-r----- 1 oracle oinstal● 619 Jul 14 05:25 wolf_ora_4899.trc
-rw-r----- 1 oracle oinstal● 648 Jul 14 05:25 wolf_ora_4952.trc
-rw-r----- 1 oracle oinstal● 2717 Jul 14 05:36 wolf_ora_4954.trc
-rw-r----- 1 oracle oinstal● 591 Ju● 7 10:02 wolf_ora_5721.trc
-rw-r----- 1 oracle oinstal● 907 Ju● 7 10:03 wolf_ora_5764.trc
-rw-r----- 1 oracle oinstal● 591 Ju● 7 10:03 wolf_ora_5766.trc
-rw-r----- 1 oracle oinstal● 2630 Ju● 7 10:03 wolf_ora_5792.trc
-rw-r----- 1 oracle oinstal● 776 Ju● 7 10:03 wolf_ora_5826.trc
-rw-r----- 1 oracle oinstal● 591 Ju● 7 10:03 wolf_ora_5833.trc
-rw-r----- 1 oracle oinstal● 648 Ju● 7 10:04 wolf_ora_5860.trc
-rw-r----- 1 oracle oinstal● 2045 Ju● 8 04:04 wolf_ora_9291.trc
[root@test udump]# date
Sat Jul 14 05:38:57 EDT 2012
[root@test udump]# cat wolf_ora_4954.trc | more
/opt/app/oracle/admin/wolf/udump/wolf_ora_4954.trc
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production
With the Partitioning, OLAP and Data Mining options
ORACLE_HOME = /opt/app/oracle/product/10g
System name: Linux
Node name: test
Release: 2.6.18-128.el5
Version: #1 SMP Wed Dec 17 11:42:39 EST 2008
Machine: i686
Instance name: wolf
Redo thread mounted by this instance: 1
Oracle process number: 15
Unix process pid: 4954, image: oracle@test (TNS V1-V3)
*** 2012-07-14 05:36:52.410
*** SERVICE NAME:(SYS$USERS) 2012-07-14 05:36:52.410
*** SESSION ID:(159.3) 2012-07-14 05:36:52.410
Start dump data blocks tsn: 6 file#: 5 minblk 12 maxblk 12
buffer tsn: 6 rdba: 0x0140000c (5/12)
scn: 0x0000.0007e543 seq: 0x05 flg: 0x02 tail: 0xe5430605
frmt: 0x02 chkval: 0x0000 type: 0x06=trans data
Hex dump of block: st=0, typ_found=1
Dump of memory from 0x0CEF4200 to 0x0CEF6200
CEF4200 0000A206 0140000C 0007E543 02050000 [......@.C.......]
CEF4210 00000000 00000001 0000C8B1 0007E52C [............,...]
CEF4220 00000000 00320002 01400009 00230007 [......2...@...#.]
CEF4230 000000DD 0080077F 003400CC 00002003 [..........4.. ..]
CEF4240 0007E543 00000000 00000000 00000000 [C...............]
CEF4250 00000000 00000000 00000000 00000000 [................]
CEF4260 00000000 00030100 0018FFFF 1F651F80 [..............e.]
CEF4270 00001F65 1F900003 1F801F88 00000000 [e...............]
CEF4280 00000000 00000000 00000000 00000000 [................]
Repeat 501 times
CEF61E0 00000000 0202012C 630104C1 0202012C [....,......c,...]
CEF61F0 620103C1 0202012C 610102C1 E5430605 [...b,......a..C.]
Block header dump: 0x0140000c
Object id on Block? Y
seg/obj: 0xc8b1 csc: 0x00.7e52c itc: 2 flg: E typ: 1 - DATA
brn: 0 bdba: 0x1400009 ver: 0x01 opc: 0
inc: 0 exflg: 0
It● Xid Uba Flag Lck Scn/Fsc
0x01 0x0007.023.000000dd 0x0080077f.00cc.34 --U- 3 fsc 0x0000.0007e543
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
data_block_dump,data header at 0xcef4264
===============
tsiz: 0x1f98
hsiz: 0x18
pbl: 0x0cef4264
bdba: 0x0140000c
76543210
flag=--------
ntab=1
nrow=3
frre=-1
fsbo=0x18
fseo=0x1f80
avsp=0x1f65
tosp=0x1f65
0xe:pti[0] nrow=3 offs=0
0x12:pri[0] offs=0x1f90
0x14:pri[1] offs=0x1f88
0x16:pri[2] offs=0x1f80
block_row_dump:
tab 0, row 0, @0x1f90
tl: 8 fb: --H-FL-- lb: 0x1 cc: 2
co● 0: [ 2] c1 02
co● 1: [ 1] 61
tab 0, row 1, @0x1f88
tl: 8 fb: --H-FL-- lb: 0x1 cc: 2
co● 0: [ 2] c1 03
co● 1: [ 1] 62
tab 0, row 2, @0x1f80
tl: 8 fb: --H-FL-- lb: 0x1 cc: 2
co● 0: [ 2] c1 04
co● 1: [ 1] 63
end_of_block_dump
End dump data blocks tsn: 6 file#: 5 minblk 12 maxblk 12
一些参数需要自己去了解
Oracle数据块实现原理深入解读
原文:http://www.jb51.net/article/31929.htm
Oracle对数据库数据文件(datafile)中的存储空间进行管理的单位是数据块(data block),本文将详细介绍
Oracle读取和修改数据块的过程
Oracle读取和修改数据块的过程
Oracle数据库处理SQL都会经过三个过程:解析(parse)、执行(exec)、返回结果(fetch)。为了便于理解,我们首先省略的SQL的处理过程,而直接介绍数据块的读取或修改过程。
物理读和逻辑读概念
1.对要访问的块地址做HASH
HASH(FILE#,BLOCK#) = hash_value(HV)
2.根据HV找到对应的HASH bucket
3.搜索bucket中的HASH chain链表,比对chain上的buffer_header(BH).
逻辑读
1.找到BH后,读取BH中的(buffer_address)BA
2.根据BA访问buffer_cache中的目标buffer.
物理读
1.搜遍hash_chain上的BH都没有找到目标BH
2.从DBF中加载block到buffer中.
3.并将buffer头链入对应的BUCKET中的hash chain上.
4.访问buffer.
latch和pin
buffer_cache中的buffer对每个server_process而已都是公有资源谁都可以读,谁都可以改,为保证这些链不被并发修改导致破坏。oracle采用latch和buffer_pin锁来控制对内存结构体使用时的并发。
CBC latch
某个服务器进程在chain上搜索BH时,另一个进程要做入链出链的操作,对于一个buffer,两个进程同时都要去做出入链,内存则没有安全保证。为保证这些链不被并发修改导致破坏
例如:我在搜索链表上的buffer_header时,你不能更改链表,我在更改链表时,你不能遍历链表
oracle对hash_chain必须加以保护。 oracle采取的保护方式就是latch(闩锁),确切的说是:cache buffer chain latch,简称为: CBC latch。
buffer pin
当在hash_chain上找到目标BH时,根据访问方式要对BH加锁.才能根据(buffer_address)BA访问buffer。这把上在buffer_header上的锁称之为buffer pin
共享与独占
无论是CBC latch还是buffer pin都有锁的保持模式。他们都有共享和独占模式,对公有资源而言,有独占就有争用。
CBC latch何时共享持有:
1.读非唯一索引的根块+分支块
注意:读非唯一索引的叶子块是排他.
2.通过唯一索引访问时,索引的根块+分支块+叶子块+表块
原因:因为根块和分支块的访问频度高,而且很少改动。
CBC latch何时独占持有:
1.所有涉及改的操作。
2.以及上面列出的共享持有以外的所有读操作.
通过上面的比较是否更深入的理解 INDEX UNIQUE SCAN 和 INDEX RANGE SCAN建索引能唯一就唯一,绝对不会错。
获取CBC latch的目的是什么?
1.在hash chain上的双向链表搜索BH
2.在BH中修改buffer pin锁的状态
buffer pin何时共享持有:通过BH中的BA读buffer
buffer pin何时独占持有:通过BH中的BA写buffer
buffer pin何时无需持有:
1.所有不涉及索引的根块+分支块改动的读(分裂)
2.唯一索引叶子块+表块
BH上的队列:
users list对buffer操作的进程列表,兼容模式操作
waiter list因访问模式不兼容,等待队列中的用户

再给大家进一步介绍Hash Latches、HashBucket 、buffer Header及Buffer cache之间的关系图。

Oracle读取或修改数据块的流程:
一.(读操作)非唯一索引方式,非索引根块和分支块
1. 对要访问的块地址做HASH
HASH(FILE#,BLOCK#) = hash_value(HV)
2. 根据HV找到对应的HASH bucket
3. 以独占方式申请管辖此bucket的CBC latch
4. 搜索bucket中的HASH chain链表,比对chain上的buffer_header(BH),找到目标BH
5. 修改BH中的buffer pin锁为S(share)模式(之前为0,无锁)
6. 释放CBC latch.
7. 根据BH中的BA指针找到buffer
8. 读取buffer中的数据到PGA中.
9. 以独占方式申请管辖此bucket的CBC latch
10.修改BH中的buffer pin锁为0(无锁)模式
11.释放CBC latch
二.(读操作)唯一索引方式所有块,非唯一索引根块和分支块
1. 对要访问的块地址做HASH
HASH(FILE#,BLOCK#) = hash_value(HV)
2. 根据HV找到对应的HASH bucket
3. 以共享方式申请管辖此bucket的CBC latch
4. 搜索bucket中的HASH chain链表,比对chain上的buffer_header(BH),找到目标BH
5. 根据BH中的BA指针找到buffer
6. 读取buffer中的数据到PGA中
7. 释放CBC latch
三.(写操作)
1. 对要访问的块地址做HASH
HASH(FILE#,BLOCK#) = hash_value(HV)
2. 根据HV找到对应的HASH bucket
3. 以独占方式申请管辖此bucket的CBC latch
4. 搜索bucket中的HASH chain链表,比对chain上的buffer_header(BH),找到目标BH
. 5. 修改BH中的buffer pin锁为X(exclusive)模式(之前为0,无锁)
6. 释放CBC latch
7. 根据BH中的BA指针找到buffer
8. 产生redo数据
8. 修改buffer中的数据.
9. 以独占方式申请管辖此bucket的CBC latch.
10.修改BH中的buffer pin锁为0模式
11.释放CBC latch.
Oracle 存储数据的最小单位是数据块。Oracle 管理 数据库 数据文件的存储空间被称为数据块,一个数据块是数据库使用的最小数据单位。对应的操作系统层面上,所有数据都是以字节形式存储的。每一种操作系统都有自己的块大小。Oracle 对数据的请求是Oracle 数据块的倍数,而非操作系统块。
标准的块大小是通过初始化参数DB_BLOCK_SIZE 指定的,Oracle 允许指定最多5 种非标准块。为了避免不必要的I/O 开销,数据块大小应当是操作系统块大小的整数倍。
关于数据块的几个概念
磁盘扇区 大小 512bytes sector size ,操作系统空间分配块大小, OS space allocation block size
簇字节数 也就是 I/O chunk size ,通常所说的操作系统块大小
Oracle 数据块 即 DB_BLOCK_SIZE , DB_BLOCK_SIZE 应当是操作系统块大小的整数倍数 ,可以有效地避免不必要的 I/O ,这里的操作系统块指的是簇字节数 (I/O chunk size) ,事实上 Oracle 的 DB_BLOCK_SIZE 大小可以小于簇字节数 (I/O chunk size) ,所以 Oracle 官方文档写的是应当或者建议值。
The standard block size is specified by the initialization parameter DB_BLOCK_SIZE . In addition, you can specify of up to five nonstandard block sizes. The data block sizes should be a multiple of the operating system’s block size within the maximum limit to avoid unnecessary I/O. Oracle data blocks are the smallest units of storage that Oracle can use or allocate. (来自于 Oracle Concept )
Oracle 日志写入使用 512bytes 的 chunk 大小,因此最好把日志放到裸设备和相关硬件上,从而忽略文件系统。 ( 该观点来自于 itpub Yong Huang ,但是原文出处不可考证 ) , Oracle 日志和数据文件写入机制的不同,印证了 redo 文件最好与其它数据文件进行物理分离。
Since Oracle redo writing uses chunk size of 512 bytes (or 1k on HPUX and a few other OS'es), it's always better to place redo logfiles on raw partitions or equivalent (Veritas Quick I/O, Oracle ASM etc), bypassing filesystems.
正常情况下,可以认为服务器进程读取相应的 Oracle 块时,会调用 Oracle I/O 引擎,然后 Oracle I/O 引擎向操作系统发出请求,操作系统在通过内核进行相应的系统调用接口读取操作系统块;然后文件系统调用相应的块设备进行扇区数据读写。 ( 裸设备暂时无法理解其原理 )
参见《 关于 oracle 数据块和操作系统块的关系》
http://www.itpub.net/viewthread.php?tid=1081114&highlight=%CA%FD%BE%DD%BF%E9
chkdsk 可以查看操作系统的块大小 (windows 平台 )
fsutil fsinfo ntfsinfo c: 命令也可查看操作系统的块大小 (windows 平台 )
/sbin/tune2fs -l /dev/sda1 | grep Block 可以查看操作系统的块大小 (Linux 平台 )
show parameter db_block_size 显示 Oracle 缺省数据块大小
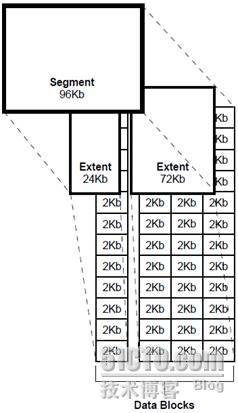
区间是一系列用来存储特定信息的连续的数据块
数据块格式
Oracle 数据块的格式无论是表、索引还是cluster 数据,格式都是很类似的,见图
块头( 公共和变量)
头部包含了通用块信息,例如块的地址和段的类型 ( 例如表或者索引 )
表目录
这部分信息包含了在这个块中该表或该索引的相关信息。
行目录
这部分包含了数据块中的实际行的信息 ( 包括行数据区域中每行的地址 ) ,一旦数据块头部的这个行目录的空间被分配了,那么即使该行删除了,这段空间仍然不能回收。
因此一个当前为空的数据块
此区域包含数据块中存储的数据行的信息(每个数据行片断( row piece ) 在行数据区( row data area )中的地址)。 [ 一个数据块中可能保存一个完整的数据行,也可能只保存数据行的一部分 ,所以文中使用 row piece] 。只有在数据块中插入( insert )新数据时,行目录区空间才会被重新利用。
头部信息区(Overhead )
块头( header/Common and Variable ),表目录( Table Directory ),行目录( Row Directory )这三部分合称为头部信息区( Overhead )。头部信息区不存放数据,它存放的整个块的信息。头部信息区的大小是可变的。一般来说,头部信息区的大小介于 84 字节( bytes )到 107 字节( bytes )之间
可用空间(Free Space )
可用空间是一个块中未使用的区域,这片区域用于新行的插入和已经存在的行的更新。可用空间也包含事务条目,当每一次 insert 、 update 、 delete 、 select ..for update 语句访问块中一行或多行数据,将会请求一条事务条目,事务条目的请求空间与操作系统相关,在多数操作系统中大约所需 23 个字节。
行数据
这部数据块包含了表或索引的数据,行也可能跨数据块,这也就是行迁移现象。
具体参见: oracle 数据文件内部 BLOCK 结构详解,初始原文已不可考
http://www.sosdb.com/article/datafile_block.htm
可用空间管理(Free Space Management)
可用空间可能是自动或人工管理。
可用空间是由 Oracle 内部的段自动管理的,段内的可用 / 已用空间用位图来跟踪。自动段空间管理提供了以下好处:
● 使用便捷
● 更好的空间利用率,特别是那些行大小变化很大的对象
● 并发访问的动态调整
● 性能 / 空间的平衡
数据块可用空间的利用和压缩
Delete 和 update( 把原值变小 ) 可增加数据块的可用空间。在以下情况下 insert 语句才能有效地利用已释放的空间。
假如 insert 语句在同一个事务中,而 insert 前面的语句刚好释放了相应的空间,这时候 insert 语句可以利用该空间
假如 insert 语句与释放空间的语句不在同一个事务中,那么只有当其他事务提交后并且刚好需要空间的时候, insert 语句才能利用该空间。
释放的空间也可能不是连续的,只有当 1 一个 insert 或 update 语句试图使用足够空间创建新行的时候,并且 2 自由空间是分散的以至于不能插入毗邻空间的时候, Oracl 才会合并和压缩数据块的可用空间。
行链接和行迁移(Row Chaining and Migrating )
行链接( Row Chaining ):如果我们往数据库中插入( INSERT )一行数据,这行数据很大,以至于一个数据块存不下一整行, Oracle 就会把一行数据分作几段存在几个数据块中,这个过程叫行链接( Row Chaining )。
如果一行数据是普通行,这行数据能够存放在一个数据块中;如果一行数据是链接行,这行数据存放在多个数据块中。
行迁移 (Row Migrating) :数据块中存在一条记录,用户执行 UPDATE 更新这条记录,这个 UPDATE 操作使这条记录变长,这时候, Oracle 在这个数据块中进行查找,但是找不到能够容纳下这条记录的空间,无奈之下, Oracle 只能把整行数据移到一个新的数据块。原来的数据块中保留一个“指针”,这个“ 指针”指向新的数据块。被移动的这条记录的 ROWID 保持不变。
PCTFREE 参数用于指定块中必须保留的最小空闲空间百分例。之所以要预留这样的空间,是因为 UPDATE 时,需要这些空间。如果 UPDATE 时,没有空余空间, Oracle 就会分配一个新的块,这会产生行迁移( Row Migrating )。
PCTUSED 也是用于设置一个百分比,当块中已使用的空间的比例小于这个百分比的时候,这个块才被标识为有效状态。只有有效的块才被允许插入数据
创建数据表
create table TEST
(
tablespace
pctfree 10 --初始化保留的最小10%的空闲空间比例,低于90%是,均可插入 pctused 40 --当已使用空间比例小于这个百分比时,重新允许插入数据 initrans 1
maxtrans 255
storage
(
initial 64K
minextents 1
maxextents
);
--插入测试 数据,并观察其相应的rowid
insert into test values('1');
insert into test values('2');
insert into test values('3');
commit;
select t.*,t.rowid from test t;
update test set name=lpad(name,4000,'1') where name='1';
update test set name=lpad(name,4000,'2') where name='2';update test set name=lpad(name,4000,'3') where name='3';commit;
select t.*,t.rowid from test t;/
@F:/OracleForVista/product/10.2.0/db_1/RDBMS/ADMIN/utlchain.sql;
--分析相关表
ANALYZE TABLE test LIST CHAINED ROWS;
--查询链接行或迁移行
SELECT * FROM CHAINED_ROWS where table_name='TEST';
select t.*,t.rowid from test t;
行迁移解决办法:其实没有太好的办法,只能是行迁移数据删除后,重新插入回来间Create table new_table as select * from old_table;
Drop table old_table;
Rename new_table to old_table;
--分析相关表
ANALYZE TABLE test LIST CHAINED ROWS;
--查询链接行或迁移行
SELECT * FROM CHAINED_ROWS where table_name='TEST';
select t.*,t.rowid from test t;
行迁移解决办法:其实没有太好的办法,只能是行迁移数据删除后,重新插入回来间Create table new_table as select * from old_table;
Drop table old_table;
Rename new_table to old_table;
在Oracle中,数据块block上存在记录事务信息的ITL(Interest Transaction List)。当一个数据库事务涉及到数据块对应的数据时,就会在当前数据块块头(block head)后面的ITL中记录上相应的信息。
本篇从数据块逻辑结构角度入手,分析ITL中所包括的内容和与事务对应的信息。
1、 环境准备
在这里,我们准备一个简单的数据表作为实验对象。
SQL> select * from v$version;
BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Prod
PL/SQL Release 10.2.0.1.0 - Production
CORE 10.2.0.1.0 Production
TNS for 32-bit Windows: Version 10.2.0.1.0 - Production
NLSRTL Version 10.2.0.1.0 - Production
SQL> create table t (id number, vname varchar2(10));
Table created
SQL> insert into t values (1, 'id');
1 row inserted
SQL> insert into t values (2, 'iddf');
1 row inserted
SQL> commit;
Commit complete
此时,对应的数据段信息如下:
SQL> select HEADER_FILE, HEADER_BLOCK, BYTES, BLOCKS, EXTENTS from dba_segments where wner='SYS' and segment_name='T';
HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
----------- ------------ ---------- ---------- ----------
1 65265 65536 8 1
从数据字典信息看,Oracle为该数据段T分配了一个extents分区,其中包括8个数据块。
2、无事务状态下的ITL事务槽
首先,我们需要知道各个数据行对应的物理位置。我们可以使用dbms_rowid的包方法解析数据行rowid信息。Rowid中实际包括几个组成部分:相对文件编号、对象编号、数据块号和行slot号。
SQL> select id, dbms_rowid.rowid_relative_fno(rowid) fno, dbms_rowid.rowid_block_number(rowid) bno, dbms_rowid.rowid_row_number(rowid) row_num from t;
ID FNO BNO ROW_NUM
---------- ---------- ---------- ----------
1 1 65266 0
2 1 65266 1
两个数据行均在文件1的65266数据块上。我们接下来使用dump数据块的方法,将该块的逻辑结构dump到当前会话对应的跟踪文件中。
SQL> alter system dump datafile 1 block 65266;
System altered
--获取trace跟踪文件位置名称
SQL> select f_get_trace_name from dual;
F_GET_TRACE_NAME
------------------------------------------------------
C:/TOOL/ORACLE/ORACLE/PRODUCT/10.2.0/ADMIN/OTS/UDUMP/ots_ora_5488.trc
我们打开跟踪文件,可以找到对应的itl信息片段。
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0007.02a.000085d4 0x00800ca8.35fc.09 --U- 2 fsc 0x0000.7f2ddad3
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
对每一个数据块,都是包括ITL列表,用于描述当前数据块上进行的事务信息。在创建数据段对象的时候,包括initrans参数(默认值为1),就是表示该数据表对象的数据块创建时候初始ITL事务槽的个数。
Initrans参数在10g之后,基本上就失去了其效果的场景。Oracle对数据块,初始都是创建两个事务槽对象。当并发事务操作较多的时候,会进行自动的拓展,拓展到最大值255。
从上面的片段,我们可以看到该数据块中,有两个itl事务槽。Itl列表示连接的事务槽编号。
Xid是由三列使用十六进制编码的数字列表示,该列表示对应的事务编号。在Oracle中,标识一个事务是通过usn.slot.sqn表示。事务槽起作用的时候,每一个事务槽都与一个事务相关联。
Uba应当为undo block address的缩写。多版本一致读是Oracle保证读操作不会被事务阻塞的重要特性。当Server Process需要查询一个正在被事务修改,但是尚未提交的数据时,就根据ITL上的uba定位到对应Undo前镜像数据位置。
Flag对应的是当前事务槽的状态信息,标志着不同的事务状态(下表信息引自网络资料)。
|
Flag取值 |
含义 |
|
----- |
事务是活动的,或者在块清除前提交事务 |
|
C--- |
事务已经提交并且清除了行锁定 |
|
-B-- |
this undo record contains the undo for this ITL entry |
|
--U- |
事务已经提交(SCN已经是最大值),但是锁定还没有清除(快速清除) |
|
---T |
当块清除的SCN被记录时,该事务仍然是活动的,块上如果有已经提交的事务,那么在clean ount的时候,块会被进行清除,但是这个块里面的事务不会被清除。 |
|
|
|
Lck表示该事务槽涉及到的记录数目。Scn/Fsc:表示快速提交和已经提交的SCN编号。
从上面的ITL片段表示两条记录对应的事务已经提交,并且对应最大的SCN取值。
3、启动单会话事务
我们首先观察一下,当启动一个会话事务的时候,ITL状态情况。
SQL> select sid from v$mystat where rownum<2;
SID
----------
139
SQL> update t set vname='d' where id=1;
1 row updated
此时,对应事务信息为。
SQL> select * from v$transaction;
ADDR XIDUSN XIDSLOT XIDSQN
-------- ---------- ---------- ----------
27FB6AAC 9 25 34274
这时候,我们尝试dump出数据块,ITL链情况如下:
It● Xid Uba Flag Lck Scn/Fsc
0x01 0x0007.02a.000085d4 0x00800ca8.35fc.09 C--- 0 scn 0x078c.7f2ddad3
0x02 0x0009.019.000085e2 0x00800c4e.306a.2c ---- 1 fsc 0x0000.00000000
第二行事务槽,锁定影响记录数量为1。对应的xid为0x0009.019.000085e2。分析下转换为十进制后分别为:9,25和34274。与v$transaction中对应的事务标识一致。说明0x02事务槽对应的是我们会话事务。
4、启动第二个会话事务
当我们启动第二个会话事务时,观察情况。
SQL> select sid from v$mystat where rownum<2;
SID
----------
147
SQL> update t set vname='fk' where id=2;
1 row updated
事务信息和锁信息如下:
SQL> select * from v$transaction;
ADDR XIDUSN XIDSLOT XIDSQN
-------- ---------- ---------- ----------
27FB6AAC 9 25 34274
27FB6FE0 3 23 34283
SQL> select addr, kaddr, sid, type, id1, id2, lmode from v$lock where sid=147 or sid=139 order by sid;
ADDR KADDR SID TYPE ID1 ID2 LMODE
-------- -------- ---------- ---- ---------- ---------- ----------
27FB6AAC 27FB6BC8 139 TX 589849 34274 6
27F3F1D8 27F3F1F0 139 TM 112888 0 3
27FB6FE0 27FB70FC 147 TX 196631 34283 6
27F3F29C 27F3F2B4 147 TM 112888 0 3
两个事务同时作用在相同的数据块上。我们dump出数据块查看ITL。
It● Xid Uba Flag Lck Scn/Fsc
0x01 0x0003.017.000085eb 0x008005d6.351e.11 ---- 1 fsc 0x0002.00000000
0x02 0x0009.019.000085e2 0x00800c4e.306a.2c ---- 1 fsc 0x0000.00000000
两条ITL被占据。
5、第三个会话事务开启
当我们启动第三个会话事务,情况如何呢?
SQL> select sid from v$mystat where rownum<2;
SID
----------
137
SQL> insert into t values (3,'kl');
1 row inserted
锁定情况如下:
SQL> select addr, kaddr, sid, type, id1, id2, lmode from v$lock where sid=147 or sid=139 or sid=137 order by sid;
ADDR KADDR SID TYPE ID1 ID2 LMODE
-------- -------- ---------- ---- ---------- ---------- ----------
27F3F360 27F3F378 137 TM 112888 0 3
27F87B2C 27F87C48 137 TX 131080 34302 6
27FB6AAC 27FB6BC8 139 TX 589849 34274 6
27F3F1D8 27F3F1F0 139 TM 112888 0 3
27FB6FE0 27FB70FC 147 TX 196631 34283 6
27F3F29C 27F3F2B4 147 TM 112888 0 3
6 rows selected
--对应v$transaction情况;
ADDR XIDUSN XIDSLOT XIDSQN
-------- ---------- ---------- ---------- -
27F87B2C 2 8 34302
27FB6AAC 9 25 34274
27FB6FE0 3 23 34283
事务开启,新插入的数据依然在当前研究数据块中。
SQL> select id, dbms_rowid.rowid_relative_fno(rowid) fno, dbms_rowid.rowid_block_number(rowid) bno, dbms_rowid.rowid_row_number(rowid) row_num from t;
ID FNO BNO ROW_NUM
---------- ---------- ---------- ----------
1 1 65266 0
2 1 65266 1
3 1 65266 2
事务槽dump结果。
It● Xid Uba Flag Lck Scn/Fsc
0x01 0x0003.017.000085eb 0x008005d6.351e.11 ---- 1 fsc 0x0002.00000000
0x02 0x0009.019.000085e2 0x00800c4e.306a.2c ---- 1 fsc 0x0000.00000000
0x03 0x0002.008.000085fe 0x00800166.3192.0b ---- 1 fsc 0x0000.00000000
当当前准备的事务槽个数小于数据块进行的事务个数时,会进行事务槽自动拓展。
6、事务清理
当事务结束,事务槽清理。
SQL> alter system dump datafile 1 block 65266;
System altered
It● Xid Uba Flag Lck Scn/Fsc
0x01 0x0007.02a.000085d4 0x00800ca8.35fc.09 C--- 0 scn 0x078c.7f2ddad3
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
7、结论
在Oracle数据块上,ITL是一个重要的部分。它与会话、事务、多版本一致度等特性密切相关
About Me
...............................................................................................................................
● 本文作者:小麦苗,只专注于数据库的技术,更注重技术的运用
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-07-01 09:00 ~ 2017-07-31 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。




在Oracle中,数据块block上存在记录事务信息的ITL(Interest Transaction List)。当一个数据库事务涉及到数据块对应的数据时,就会在当前数据块块头(block head)后面的ITL中记录上相应的信息。
本篇从数据块逻辑结构角度入手,分析ITL中所包括的内容和与事务对应的信息。
1、 环境准备
在这里,我们准备一个简单的数据表作为实验对象。
SQL> select * from v$version;
BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Prod
PL/SQL Release 10.2.0.1.0 - Production
CORE 10.2.0.1.0 Production
TNS for 32-bit Windows: Version 10.2.0.1.0 - Production
NLSRTL Version 10.2.0.1.0 - Production
SQL> create table t (id number, vname varchar2(10));
Table created
SQL> insert into t values (1, 'id');
1 row inserted
SQL> insert into t values (2, 'iddf');
1 row inserted
SQL> commit;
Commit complete
此时,对应的数据段信息如下:
SQL> select HEADER_FILE, HEADER_BLOCK, BYTES, BLOCKS, EXTENTS from dba_segments where wner='SYS' and segment_name='T';
HEADER_FILE HEADER_BLOCK BYTES BLOCKS EXTENTS
----------- ------------ ---------- ---------- ----------
1 65265 65536 8 1
从数据字典信息看,Oracle为该数据段T分配了一个extents分区,其中包括8个数据块。
2、无事务状态下的ITL事务槽
首先,我们需要知道各个数据行对应的物理位置。我们可以使用dbms_rowid的包方法解析数据行rowid信息。Rowid中实际包括几个组成部分:相对文件编号、对象编号、数据块号和行slot号。
SQL> select id, dbms_rowid.rowid_relative_fno(rowid) fno, dbms_rowid.rowid_block_number(rowid) bno, dbms_rowid.rowid_row_number(rowid) row_num from t;
ID FNO BNO ROW_NUM
---------- ---------- ---------- ----------
1 1 65266 0
2 1 65266 1
两个数据行均在文件1的65266数据块上。我们接下来使用dump数据块的方法,将该块的逻辑结构dump到当前会话对应的跟踪文件中。
SQL> alter system dump datafile 1 block 65266;
System altered
--获取trace跟踪文件位置名称
SQL> select f_get_trace_name from dual;
F_GET_TRACE_NAME
------------------------------------------------------
C:/TOOL/ORACLE/ORACLE/PRODUCT/10.2.0/ADMIN/OTS/UDUMP/ots_ora_5488.trc
我们打开跟踪文件,可以找到对应的itl信息片段。
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0007.02a.000085d4 0x00800ca8.35fc.09 --U- 2 fsc 0x0000.7f2ddad3
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
对每一个数据块,都是包括ITL列表,用于描述当前数据块上进行的事务信息。在创建数据段对象的时候,包括initrans参数(默认值为1),就是表示该数据表对象的数据块创建时候初始ITL事务槽的个数。
Initrans参数在10g之后,基本上就失去了其效果的场景。Oracle对数据块,初始都是创建两个事务槽对象。当并发事务操作较多的时候,会进行自动的拓展,拓展到最大值255。
从上面的片段,我们可以看到该数据块中,有两个itl事务槽。Itl列表示连接的事务槽编号。
Xid是由三列使用十六进制编码的数字列表示,该列表示对应的事务编号。在Oracle中,标识一个事务是通过usn.slot.sqn表示。事务槽起作用的时候,每一个事务槽都与一个事务相关联。
Uba应当为undo block address的缩写。多版本一致读是Oracle保证读操作不会被事务阻塞的重要特性。当Server Process需要查询一个正在被事务修改,但是尚未提交的数据时,就根据ITL上的uba定位到对应Undo前镜像数据位置。
Flag对应的是当前事务槽的状态信息,标志着不同的事务状态(下表信息引自网络资料)。
|
Flag取值 |
含义 |
|
----- |
事务是活动的,或者在块清除前提交事务 |
|
C--- |
事务已经提交并且清除了行锁定 |
|
-B-- |
this undo record contains the undo for this ITL entry |
|
--U- |
事务已经提交(SCN已经是最大值),但是锁定还没有清除(快速清除) |
|
---T |
当块清除的SCN被记录时,该事务仍然是活动的,块上如果有已经提交的事务,那么在clean ount的时候,块会被进行清除,但是这个块里面的事务不会被清除。 |
|
|
|
Lck表示该事务槽涉及到的记录数目。Scn/Fsc:表示快速提交和已经提交的SCN编号。
从上面的ITL片段表示两条记录对应的事务已经提交,并且对应最大的SCN取值。
3、启动单会话事务
我们首先观察一下,当启动一个会话事务的时候,ITL状态情况。
SQL> select sid from v$mystat where rownum<2;
SID
----------
139
SQL> update t set vname='d' where id=1;
1 row updated
此时,对应事务信息为。
SQL> select * from v$transaction;
ADDR XIDUSN XIDSLOT XIDSQN
-------- ---------- ---------- ----------
27FB6AAC 9 25 34274
这时候,我们尝试dump出数据块,ITL链情况如下:
It● Xid Uba Flag Lck Scn/Fsc
0x01 0x0007.02a.000085d4 0x00800ca8.35fc.09 C--- 0 scn 0x078c.7f2ddad3
0x02 0x0009.019.000085e2 0x00800c4e.306a.2c ---- 1 fsc 0x0000.00000000
第二行事务槽,锁定影响记录数量为1。对应的xid为0x0009.019.000085e2。分析下转换为十进制后分别为:9,25和34274。与v$transaction中对应的事务标识一致。说明0x02事务槽对应的是我们会话事务。
4、启动第二个会话事务
当我们启动第二个会话事务时,观察情况。
SQL> select sid from v$mystat where rownum<2;
SID
----------
147
SQL> update t set vname='fk' where id=2;
1 row updated
事务信息和锁信息如下:
SQL> select * from v$transaction;
ADDR XIDUSN XIDSLOT XIDSQN
-------- ---------- ---------- ----------
27FB6AAC 9 25 34274
27FB6FE0 3 23 34283
SQL> select addr, kaddr, sid, type, id1, id2, lmode from v$lock where sid=147 or sid=139 order by sid;
ADDR KADDR SID TYPE ID1 ID2 LMODE
-------- -------- ---------- ---- ---------- ---------- ----------
27FB6AAC 27FB6BC8 139 TX 589849 34274 6
27F3F1D8 27F3F1F0 139 TM 112888 0 3
27FB6FE0 27FB70FC 147 TX 196631 34283 6
27F3F29C 27F3F2B4 147 TM 112888 0 3
两个事务同时作用在相同的数据块上。我们dump出数据块查看ITL。
It● Xid Uba Flag Lck Scn/Fsc
0x01 0x0003.017.000085eb 0x008005d6.351e.11 ---- 1 fsc 0x0002.00000000
0x02 0x0009.019.000085e2 0x00800c4e.306a.2c ---- 1 fsc 0x0000.00000000
两条ITL被占据。
5、第三个会话事务开启
当我们启动第三个会话事务,情况如何呢?
SQL> select sid from v$mystat where rownum<2;
SID
----------
137
SQL> insert into t values (3,'kl');
1 row inserted
锁定情况如下:
SQL> select addr, kaddr, sid, type, id1, id2, lmode from v$lock where sid=147 or sid=139 or sid=137 order by sid;
ADDR KADDR SID TYPE ID1 ID2 LMODE
-------- -------- ---------- ---- ---------- ---------- ----------
27F3F360 27F3F378 137 TM 112888 0 3
27F87B2C 27F87C48 137 TX 131080 34302 6
27FB6AAC 27FB6BC8 139 TX 589849 34274 6
27F3F1D8 27F3F1F0 139 TM 112888 0 3
27FB6FE0 27FB70FC 147 TX 196631 34283 6
27F3F29C 27F3F2B4 147 TM 112888 0 3
6 rows selected
--对应v$transaction情况;
ADDR XIDUSN XIDSLOT XIDSQN
-------- ---------- ---------- ---------- -
27F87B2C 2 8 34302
27FB6AAC 9 25 34274
27FB6FE0 3 23 34283
事务开启,新插入的数据依然在当前研究数据块中。
SQL> select id, dbms_rowid.rowid_relative_fno(rowid) fno, dbms_rowid.rowid_block_number(rowid) bno, dbms_rowid.rowid_row_number(rowid) row_num from t;
ID FNO BNO ROW_NUM
---------- ---------- ---------- ----------
1 1 65266 0
2 1 65266 1
3 1 65266 2
事务槽dump结果。
It● Xid Uba Flag Lck Scn/Fsc
0x01 0x0003.017.000085eb 0x008005d6.351e.11 ---- 1 fsc 0x0002.00000000
0x02 0x0009.019.000085e2 0x00800c4e.306a.2c ---- 1 fsc 0x0000.00000000
0x03 0x0002.008.000085fe 0x00800166.3192.0b ---- 1 fsc 0x0000.00000000
当当前准备的事务槽个数小于数据块进行的事务个数时,会进行事务槽自动拓展。
6、事务清理
当事务结束,事务槽清理。
SQL> alter system dump datafile 1 block 65266;
System altered
It● Xid Uba Flag Lck Scn/Fsc
0x01 0x0007.02a.000085d4 0x00800ca8.35fc.09 C--- 0 scn 0x078c.7f2ddad3
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
7、结论
在Oracle数据块上,ITL是一个重要的部分。它与会话、事务、多版本一致度等特性密切相关
正文到此结束
- 本文标签: MQ Ipo apr CSS 时间 HTML list 同步 DDL vps 生命 服务器 IOS windows Action ip AOP tar 本质 cat IDE NFV App value 总结 core 云 博客 root JPA cmd PL/SQL SVN IO bug O2O 数据 SDN operating system key 锁 src linux 删除 PHP kk IBM JMS mail 图片 CDN ELK 进程 UI API CTO Select 操作系统 lib http web 文章 tab 微信公众号 占用空间 cache DNS 专注 数据库 配置 SOA CEO DOM 参数 client W3C update Enterprise aix FAQ pom ORM js 一致性 Oracle map 管理 空间 parse REST build ECS ssh ACE unix Logging db git id grep sql NSA UDP 遍历 二维码 ftp ask rmi Word 测试 WMS node ioc 文件系统 nfs 安全 Menu TCP 解析 组织 QQ群 VPN 目录 mmm ssl CRM cvs Service awk
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

