通过SQL解读财富的分配
还是继续昨天的问题,知乎上一个蛮有意思的问题,数据分析师做了一个很有意思的解读。
题目是:房间里有100个人,每人都有100元钱,他们在玩一个游戏。每轮游戏中,每个人都要拿出一元钱随机给另一个人,最后这100个人的财富分布是怎样的?
我们用SQL来解读一下,当然还可以测试的更充分一些。
首先我们创建一个表test_money,里面是存放很简单的数据,pid就是人员编号,money就是手头的财富。
create table test_money(pid number primary key,money number);
先插入100条记录。
insert into test_money select level,1 from dual connect by level <=100;
接着我使用如下的脚本来批量模拟实验,即循环pid,从1到100,依次扣减一块,依次随机添加一块。
delete from test_money;
insert into test_money select level,1 from dual connect by level <=100;
commit;
begin
for i in 1..100 loop
update test_money set money=money-1 where pid=i;
update test_money set money=money+1 where pid=trunc(dbms_random.value(0,100)) ;
end loop;
end;
/
运行之后查看数据,第一次是这样的效果,可以看到,0,1,2的数据占比差不多是95%
MONEY COUNT(*)
---------- ----------
1 37
2 25
4 1
3 3
0 34
再来依次测试,数据有一定的变化,但是占比差别不大。
MONEY COUNT(*)
---------- ----------
1 42
2 19
4 2
3 4
0 33
我们能不能继续改进一下,这么模拟测试100次,最后得到的平均数就相对更有说服力了。
为此我们创建一个表test_money_sum,插入统计数据。
create table test_money_sum(money int,money_cnt number);
insert into test_money_sum select money,count(*)from test_money group by money;
按照这样的逻辑,我可以很轻松的模拟100遍这个实验。
使用如下的shell脚本来批量更新数据,得到最后的结果。
for i in {1..100}
do
sqlplus -s xx/xx<<EOF
@test.sql
EOF
done
sqlplus -s xx/xx<<EOF
select money,sum(money_cnt)/100 from test_money_sum group by money;
EOF
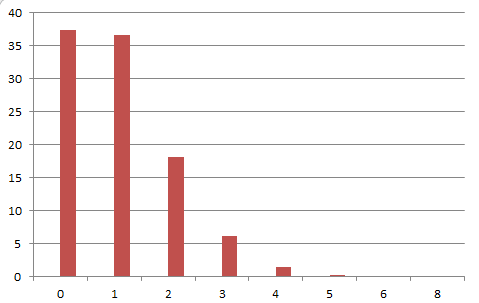
到了出数据的时候了,100次测试之后,财富的分布情况如下:
| 金钱 | 平均人数 |
| 0 | 37.36 |
| 1 | 36.57 |
| 2 | 18.12 |
| 3 | 6.16 |
| 4 | 1.43 |
| 5 | 0.28 |
| 6 | 0.07 |
| 8 | 0.01 |
如果用图表来查看会更好一些
而所占的比例用这个饼图来看更加直白。
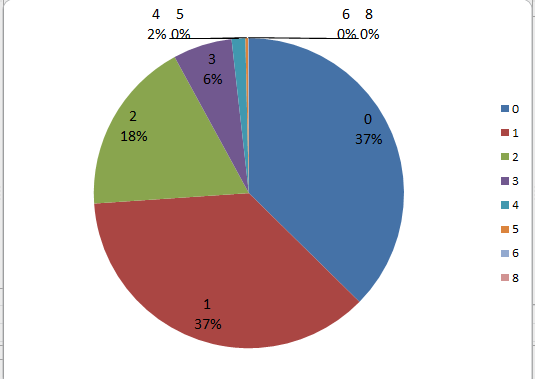
整体来看,这个实验还是很有意蕴的,想要突破现有的思维桎梏,达到一个新的高度,这个比例还是很低的,但是无论如何还是需要花很大的功夫的。
我们再想一下,如果这个样本是1000万呢。
这就涉及几个技巧,首先是初始化数据,1000万的数据初始化可以这么来做。
SQL> insert into test_money select rownum,1 from xmltable('1 to 10000000');
10000000 rows created.
Elapsed: 00:00:29.50
半分钟即可搞定,而如何批量更新呢,可以参考这个pl/sql
declare
cursor test_cur is select pid from test_money;
type rec_type is table of test_cur%rowtype index by binary_integer;
recs rec_type;
begin
open test_cur;
fetch test_cur bulk collect into recs;
close test_cur;
forall i in 1..recs.COUNT
update test_money set money=money-1 where pid=recs(i).pid;
update test_money set money=money+1 where pid=trunc(dbms_random.value(0,10000000)) ;
commit;
end;
/
数据还在运行。稍后提供。
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

