百度开源OLAP引擎Palo,高可用的MPP数据仓库

百度昨日正式开源 Palo ,这是一个百度自研的基于 MPP 的交互式 SQL 数据仓库,主要用于解决报表和多维分析。
Palo 主要集成了 Google Mesa 和 Cloudera Impala 技术。和其他流行的 SQL-on-Hadoop 系统不同的是,Palo 设计为单一紧密耦合系统,不依赖其他系统。
Palo 不仅提供高并发低延迟的查询性能,而且提供了高吞吐量的 ad-hoc 分析查询。它还提供批量数据加载,以及近乎实时的小批量数据加载。
Palo 具有高可用性、可靠性、容错性和可扩展性,其主要特点是简单(开发、部署和使用)和满足单一系统中的许多数据服务需求。
Palo 的实现包括两个守护进程:前端(FE)和后端(BE)。下图给出了架构和用法的概述:
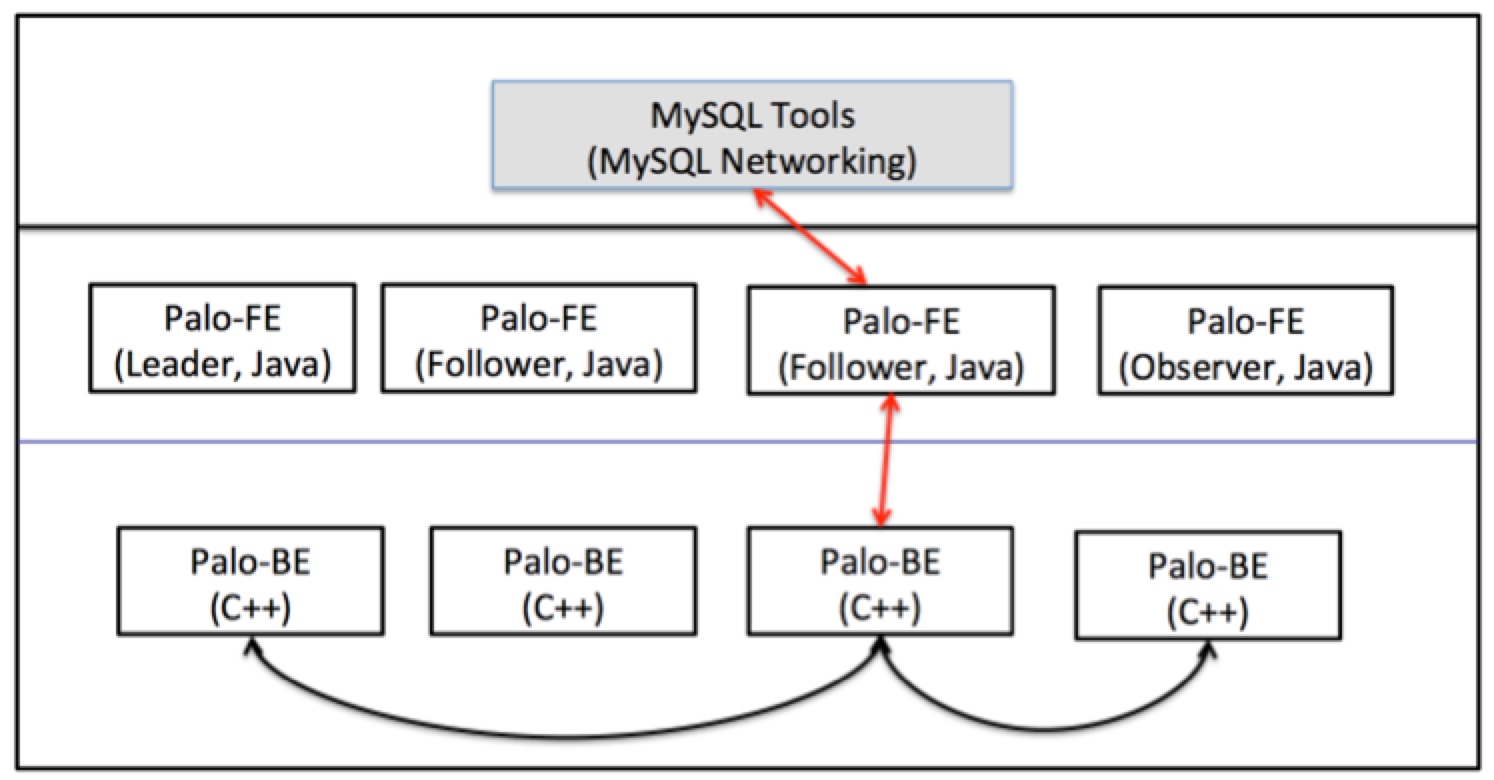
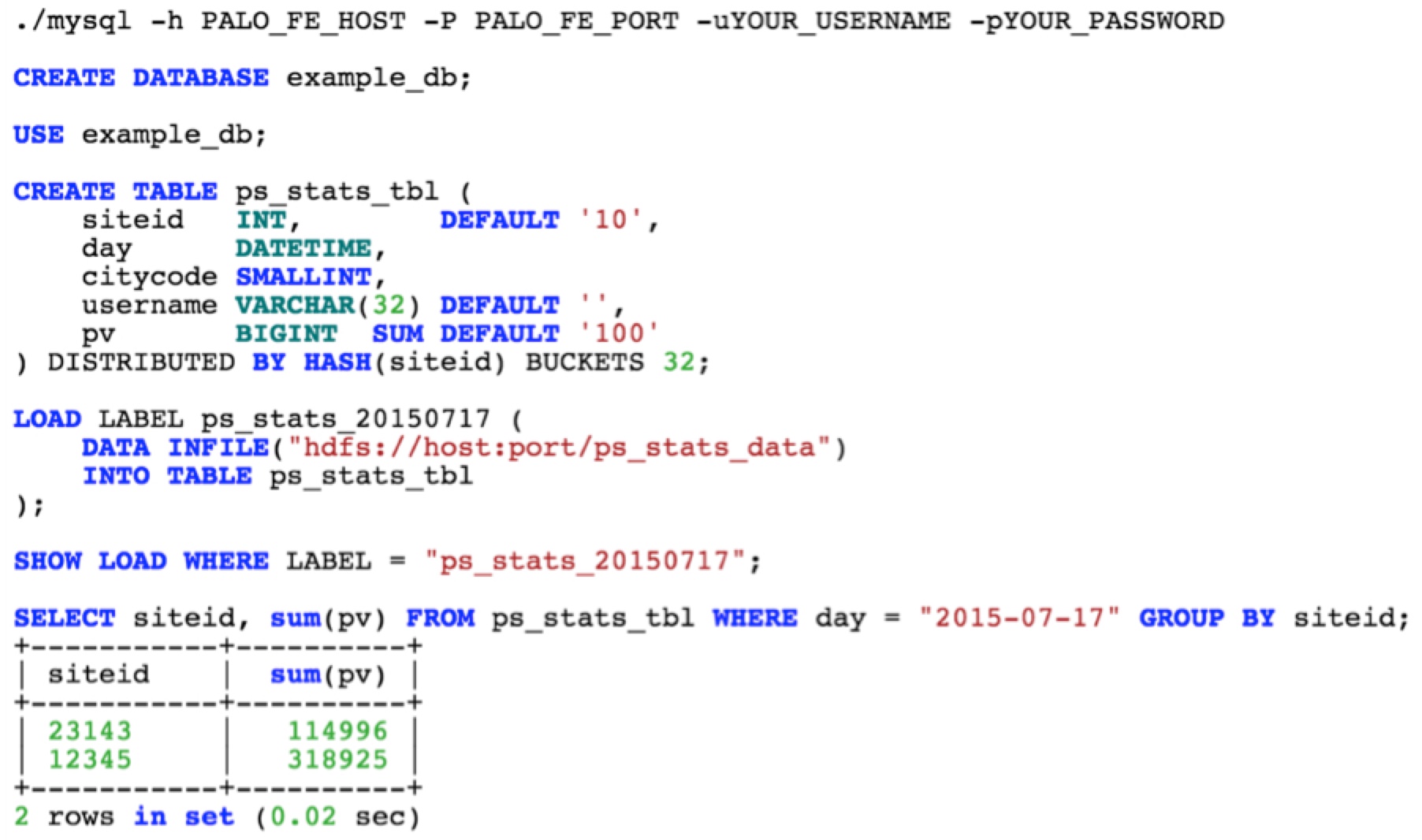
Palo 的名字正好是 OLAP 倒过来写,意思是“玩转 OLAP ”,目前在百度内部有着广泛应用,如百度凤巢、百度统计、百度糯米等。
扩展阅读
盘点大数据开源软件Google Trends指数在MySQL和PostgreSQL之外,为何阿里要研发HybridDB数据库?
Apache Kylin在百度地图的实践
解读2015之大数据篇:大数据的黄金时代
迷雾重重:XcodeGhost究竟是恶意病毒还是“无害的实验”?
为您推荐
AlloyTeam:致我们终将组件化的 Web (多图)20个你应该知道的有用HTML5代码段
50个值得收藏的实用CSS代码片段
Java处理PDF文件的类库,PDFBox 2.0.0 RC2 发布
Web开发者不可不知的15条编码原则
更多
Palo百度
开源
开源软件
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

